

2017*****7038
于晨
作業(yè)上傳已上傳碼云:https://gitee.com/baobaoyuchen/word_frequency/branches
-
程序分析,對(duì)程序中的四個(gè)函數(shù)做簡(jiǎn)要說(shuō)明。要求附上每一段代碼及對(duì)應(yīng)的說(shuō)明。
from string import punctuation
def process_file(dst): # 讀文件到緩沖區(qū)
try: # 打開(kāi)文件
f1 = open(dst,"r")except IOError (s):
print (s)
return None
try: # 讀文件到緩沖區(qū)
bvffer=f1.read()
except:
print ("Read File Error!")
return None
f1.close()
return bvffer
第一段代碼是讀取文件
def process_buffer(bvffer):
if bvffer:
word_freq = {}
# 下面添加處理緩沖區(qū) bvffer代碼,統(tǒng)計(jì)每個(gè)單詞的頻率,存放在字典word_freq
bvffer=bvffer.lower()
for x in '~!@#$%^&()_+/-+][':
bvffer=bvffer.replace(x, " ")
words=bvffer.strip().split()
for word in words:
word_freq[word]=word_freq.get(word,0)+1
return word_freq
第二段代碼計(jì)算了單詞的個(gè)數(shù) 并保存單詞的個(gè)數(shù)
def output_result(word_freq):
if word_freq:
sorted_word_freq = sorted(word_freq.items(), key=lambda v: v[1], reverse=True)
for item in sorted_word_freq[:10]: # 輸出 Top 10 的單詞
print(item)
第三段代碼輸出了最多單詞的個(gè)數(shù)
def main():
dst = "Gone_with_the_wind.txt"
bvffer = process_file(dst)
word_freq = process_buffer(bvffer)
output_result(word_freq)
if name == "main":
import cProfile
import pstats
cProfile.run("main()", "result")
# 直接把分析結(jié)果打印到控制臺(tái)
p = pstats.Stats("result")
p.strip_dirs().sort_stats("call").print_stats()
p.strip_dirs().sort_stats("cumulative").print_stats()
第四段代碼是一個(gè)main函數(shù) 并把結(jié)果打印到了控制臺(tái)
執(zhí)行結(jié)果
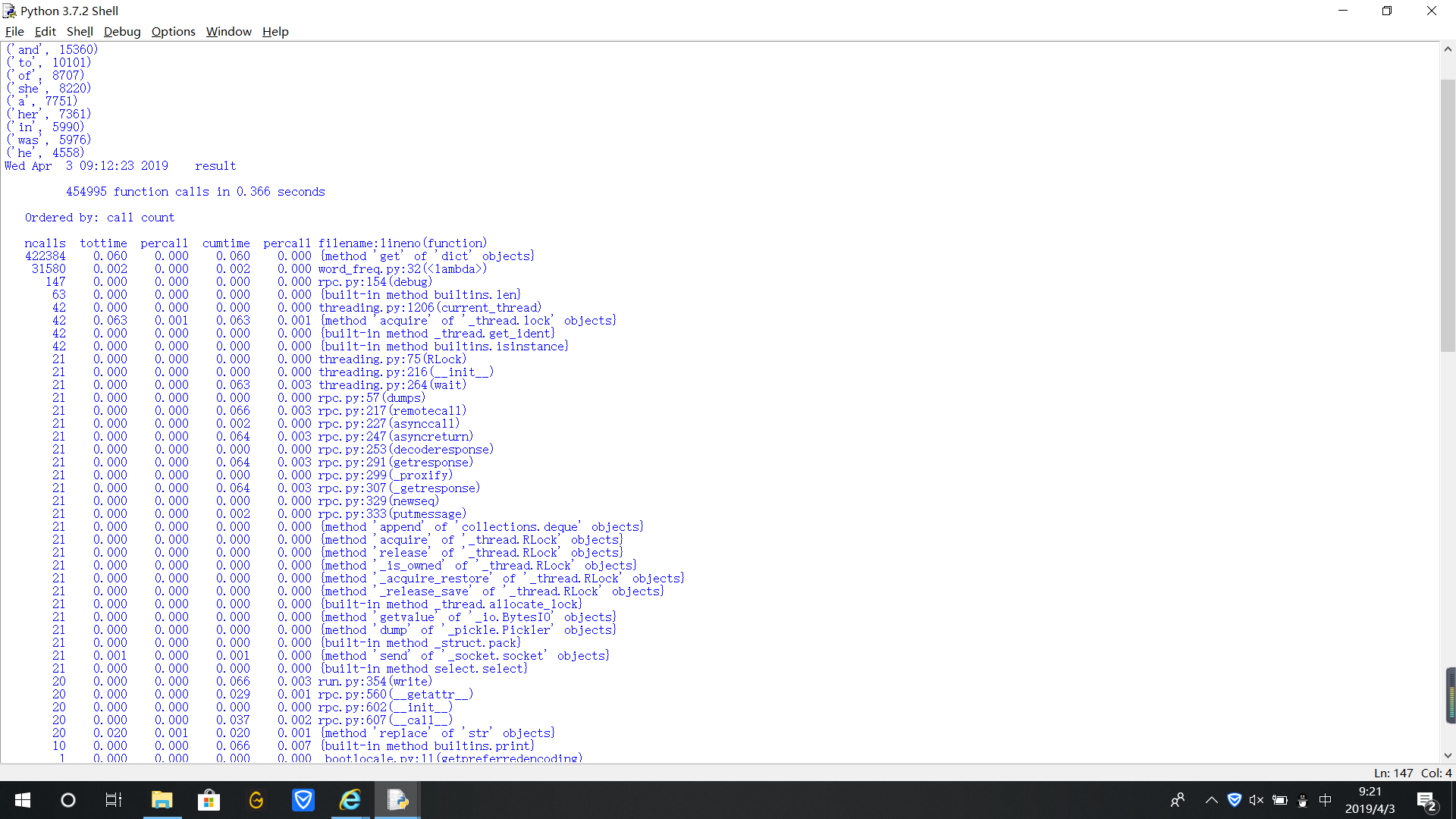
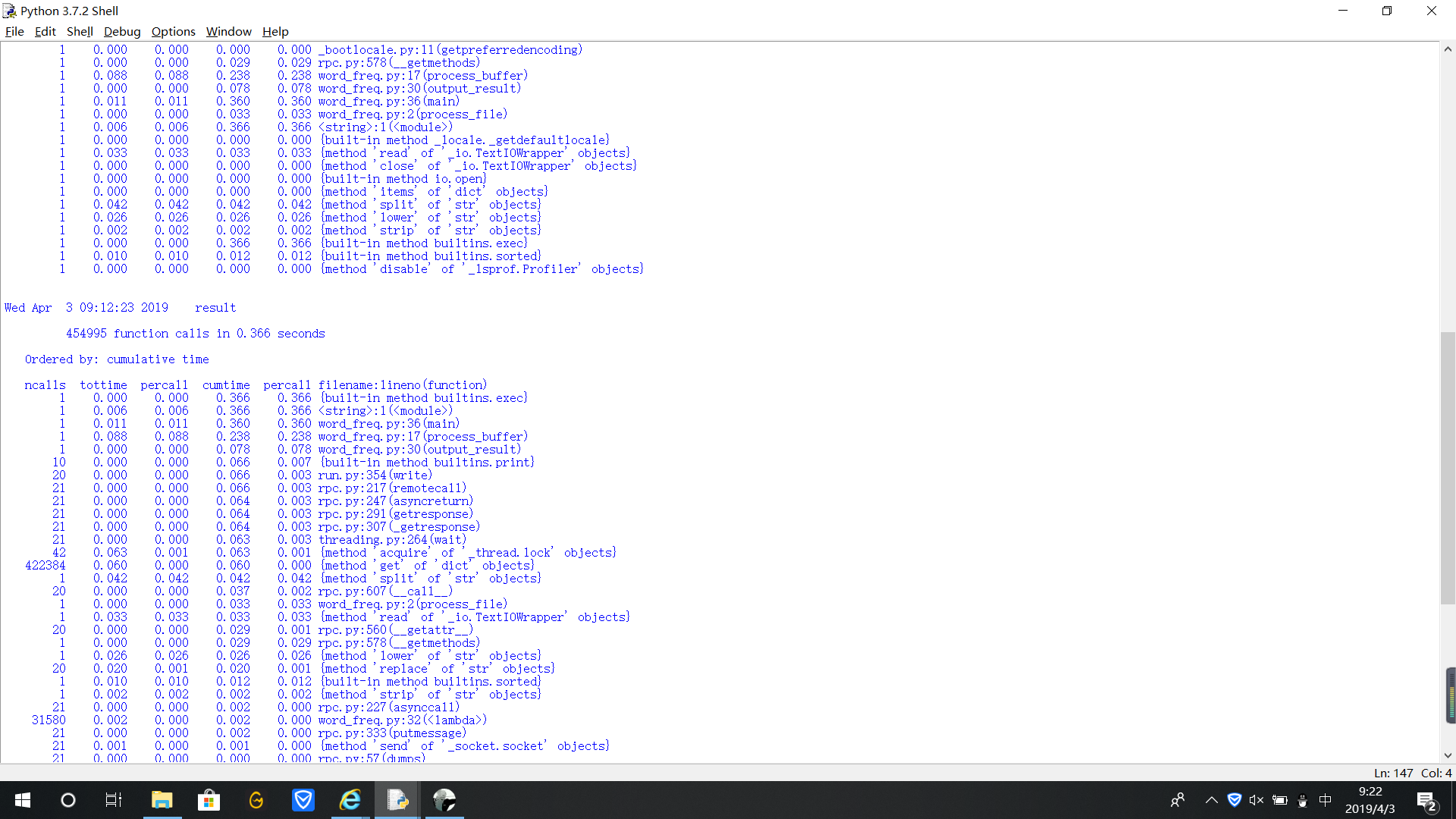
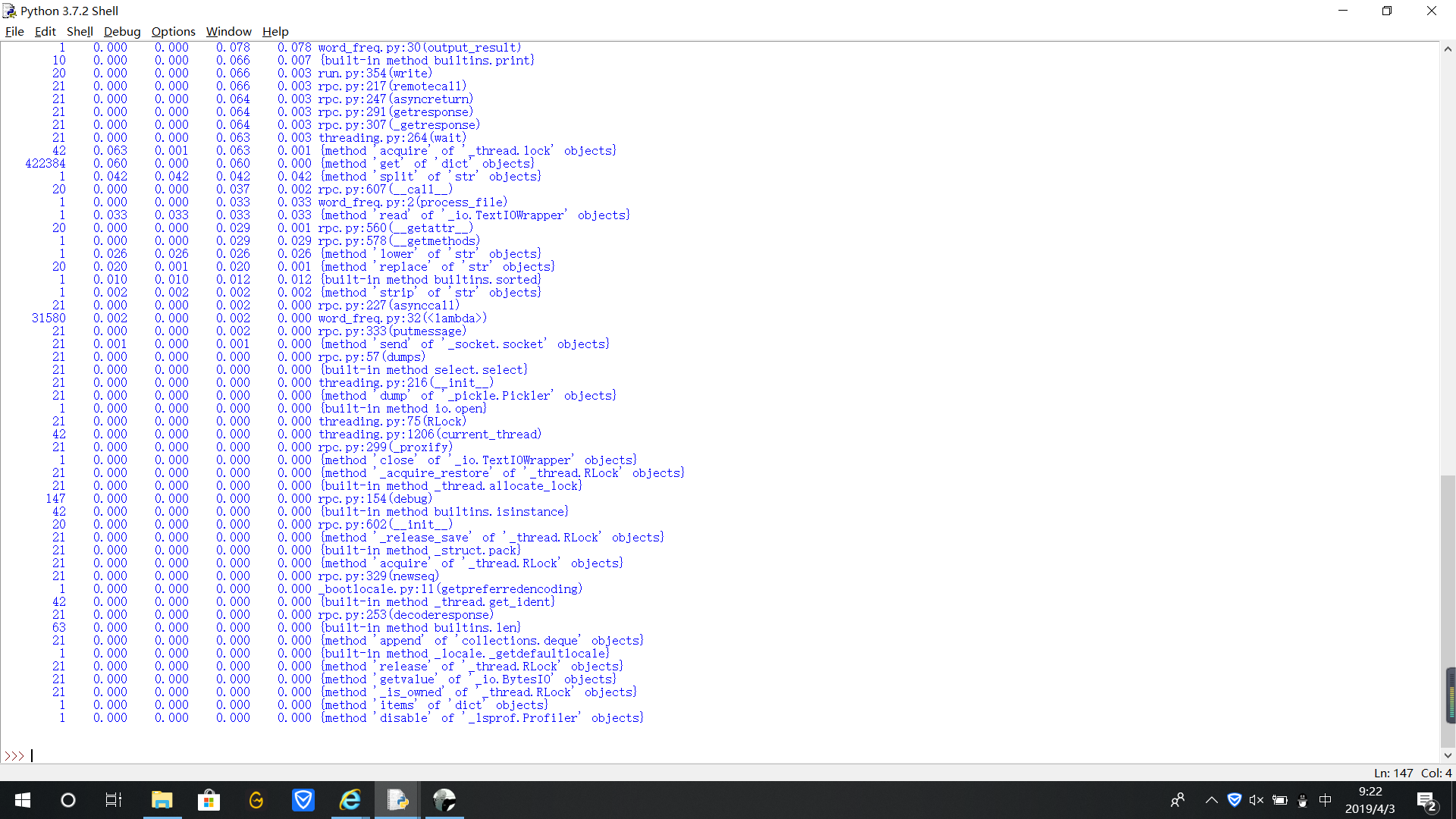

單詞出現(xiàn)的次數(shù)

執(zhí)行次數(shù)最多的代碼

執(zhí)行時(shí)間最長(zhǎng)的代碼
總結(jié):掌握了簡(jiǎn)單的詞頻統(tǒng)計(jì)的操作,運(yùn)用的還是不夠熟練 ,反思:加快運(yùn)行詞頻統(tǒng)計(jì)的操作

 浙公網(wǎng)安備 33010602011771號(hào)
浙公網(wǎng)安備 33010602011771號(hào)