

多標(biāo)簽圖像分類(lèi)總結(jié)
目錄
1.簡(jiǎn)介
2.現(xiàn)有數(shù)據(jù)集和評(píng)價(jià)指標(biāo)
3.學(xué)習(xí)算法
4.總結(jié)(現(xiàn)在存在的問(wèn)題,研究發(fā)展的方向)
簡(jiǎn)介
傳統(tǒng)監(jiān)督學(xué)習(xí)主要是單標(biāo)簽學(xué)習(xí),而現(xiàn)實(shí)生活中目標(biāo)樣本往往比較復(fù)雜,具有多個(gè)語(yǔ)義,含有多個(gè)標(biāo)簽。
 荷蘭城市圖片
荷蘭城市圖片
(1)傳統(tǒng)單標(biāo)簽分類(lèi)
city(person)
(2)多標(biāo)簽分類(lèi)
city , river, person, European style
(3)人的認(rèn)知
兩個(gè)人在河道邊走路
歐洲式建筑,可猜測(cè)他們?cè)诼糜?/span>
天很藍(lán),應(yīng)該是晴天但不是很曬
相比較而言,單標(biāo)簽分類(lèi)需要得到的信息量最少,人的認(rèn)知得到的信息量最多,多標(biāo)簽分類(lèi)在它們兩者之間
問(wèn)題描述:
X=Rd表示d維的輸入空間,Y={y1,y2,...,yq}表示帶有q個(gè)可能的標(biāo)簽的標(biāo)簽空間
訓(xùn)練集D={(xi,yi)|1≤ i ≤ m},m表示訓(xùn)練集的大小,上標(biāo)表示樣本序數(shù)
xi∈ X,是一個(gè)d維向量。yi?Y,是Y的一個(gè)標(biāo)簽子集
任務(wù)就是學(xué)習(xí)要學(xué)習(xí)一個(gè)多標(biāo)簽集的分類(lèi)器h(x),預(yù)測(cè)h(x)?Y作為x的正確標(biāo)簽集。
常見(jiàn)的做法是學(xué)習(xí)一個(gè)衡量x和y相關(guān)性的函數(shù)f(x,yj),希望f(x,yj1)>(x,yj2),其中yj1∈y,yj2?y。
現(xiàn)有數(shù)據(jù)集和評(píng)價(jià)指標(biāo)
1.現(xiàn)有數(shù)據(jù)集
NUS-WIDE 是一個(gè)帶有網(wǎng)絡(luò)標(biāo)簽標(biāo)注的圖像數(shù)據(jù),包含來(lái)自網(wǎng)站的 269648張 圖像,5018類(lèi) 不同的標(biāo)簽。
從這些圖像中提取的六種低級(jí)特征,包括64-D顏色直方圖,144-D顏色相關(guān)圖,73-D邊緣方向直方圖,128-D小波紋理,225-D塊顏色矩和500-D 基于SIFT描述的詞袋。
網(wǎng)址:http://lms.comp.nus.edu.sg/research/NUS-WIDE.htm
MS-COCO 數(shù)據(jù)集包括91類(lèi)目標(biāo),328,000影像和2,500,000個(gè)label。
所有的物體實(shí)例都用詳細(xì)的分割mask進(jìn)行了標(biāo)注,共標(biāo)注了超過(guò) 500,000 個(gè)物體實(shí)體.
網(wǎng)址:http://cocodataset.org/
PASCAL VOC數(shù)據(jù)集該挑戰(zhàn)的主要目標(biāo)是在真實(shí)場(chǎng)景中識(shí)別來(lái)自多個(gè)視覺(jué)對(duì)象類(lèi)的對(duì)象。 它基本上是監(jiān)督學(xué)習(xí)學(xué)習(xí)問(wèn)題,因?yàn)樘峁┝藰?biāo)記圖像的訓(xùn)練集。 已選擇的20個(gè)對(duì)象類(lèi)是:
人:人
動(dòng)物:鳥(niǎo),貓,牛,狗,馬,羊
車(chē)輛:飛機(jī),自行車(chē),船,公共汽車(chē),汽車(chē),摩托車(chē),火車(chē)
室內(nèi):瓶子,椅子,餐桌,盆栽,沙發(fā),電視/顯示器
train/val數(shù)據(jù)有11,530張圖像,包含27,450個(gè)ROI注釋對(duì)象和6,929個(gè)segmentation。
網(wǎng)址:http://host.robots.ox.ac.uk/pascal/VOC/voc2012/index.html#devkit
騰訊 AI Lab 此次開(kāi)源的 ML-Images 數(shù)據(jù)集包括 1800 萬(wàn)訓(xùn)練圖像和 1.1 萬(wàn)多常見(jiàn)物體類(lèi)別.
2.評(píng)價(jià)指標(biāo)
可分為三類(lèi)
- 基于樣本的評(píng)價(jià)指標(biāo)(先考慮單個(gè)樣本在所有標(biāo)簽上的表現(xiàn),然后對(duì)多個(gè)樣本取平均,不常用)
- 所有樣本的評(píng)價(jià)指標(biāo)(直接將所有標(biāo)簽的在所有樣本上的表現(xiàn))
- 基于標(biāo)簽的評(píng)價(jià)指標(biāo)(先考慮單個(gè)標(biāo)簽在所有樣本上的表現(xiàn),然后對(duì)多個(gè)標(biāo)簽取平均)
所有樣本的評(píng)價(jià)指標(biāo)
Precision, Recall, F值(單標(biāo)簽學(xué)習(xí)中精準(zhǔn)率,召回率,F(xiàn)值的天然拓展)
Niq :第i個(gè)標(biāo)簽預(yù)測(cè)正確的圖片個(gè)數(shù),Nip:第i個(gè)標(biāo)簽預(yù)測(cè)的圖片的個(gè)數(shù),Nig:第i個(gè)標(biāo)簽正確的圖片的個(gè)數(shù),
基于標(biāo)簽的評(píng)價(jià)指標(biāo)
Precision, Recall, F值(單標(biāo)簽學(xué)習(xí)中精準(zhǔn)率,召回率,F(xiàn)值的天然拓展)
mAP(mean Average Precision)
P:precision,精確率的擴(kuò)展(是由單個(gè)樣本的標(biāo)簽相關(guān)度排序決定的,與上面三個(gè)精確率含義都不同)|{yj2|rankf(xi,yj2)≤rankf(xi,yj1),yj2∈ X}|
AP:average precision,每一類(lèi)別P值的平均值
MAP:mean average precision,對(duì)所有類(lèi)別的AP取均值
其中rankf(xi,yj)表示f(.,.)對(duì)Y中所有標(biāo)簽進(jìn)行)進(jìn)行降序排序,給個(gè)排名,最后返回的是yj標(biāo)簽在這個(gè)列表中的一個(gè)排名,排名越大,相關(guān)性越小。
學(xué)習(xí)算法
1.三種策略(基于標(biāo)簽之間的關(guān)系)
多標(biāo)簽學(xué)習(xí)的主要難點(diǎn)在于輸出空間的爆炸增長(zhǎng),比如20個(gè)標(biāo)簽,輸出空間就有2^20,為了應(yīng)對(duì)指數(shù)復(fù)雜度的標(biāo)簽空間,需要挖掘標(biāo)簽之間的相關(guān)性。比方說(shuō),一個(gè)圖像被標(biāo)注的標(biāo)簽有熱帶雨林和足球,那么它具有巴西標(biāo)簽的可能性就很高。一個(gè)文檔被標(biāo)注為娛樂(lè)標(biāo)簽,它就不太可能和政治相關(guān)。有效的挖掘標(biāo)簽之間的相關(guān)性,是多標(biāo)簽學(xué)習(xí)成功的關(guān)鍵。根據(jù)對(duì)相關(guān)性挖掘的強(qiáng)弱,可以把多標(biāo)簽算法分為三類(lèi)。
- 一階策略:忽略和其它標(biāo)簽的相關(guān)性,比如把多標(biāo)簽分解成多個(gè)獨(dú)立的二分類(lèi)問(wèn)題(簡(jiǎn)單高效)。
- 二階策略:考慮標(biāo)簽之間的成對(duì)關(guān)聯(lián),比如為相關(guān)標(biāo)簽和不相關(guān)標(biāo)簽排序。
- 高階策略:考慮多個(gè)標(biāo)簽之間的關(guān)聯(lián),比如對(duì)每個(gè)標(biāo)簽考慮所有其它標(biāo)簽的影響(效果最優(yōu))。
2.兩種方法(基于如何將多標(biāo)簽分類(lèi)與當(dāng)前算法結(jié)合起來(lái))
-
- 改造數(shù)據(jù)適應(yīng)算法:常用的比如將多個(gè)類(lèi)別合并成單個(gè)類(lèi)別,這樣會(huì)導(dǎo)致類(lèi)別數(shù)量過(guò)
-
- 改造算法適應(yīng)數(shù)據(jù):常用比如正常輸出q維數(shù)據(jù),將其中softmax回歸改為sigmoid函數(shù),最終將f(.)大于閾值的結(jié)果輸出出來(lái)。
3.Multi-label CNN(VGG,ResNet101)
這是標(biāo)準(zhǔn)的CNN模型,不考慮任何標(biāo)簽依賴性,屬于一階策略,以下都屬于高階策略。
4.label embedding
label embedding不是一整個(gè)網(wǎng)絡(luò),而是網(wǎng)絡(luò)中用于處理標(biāo)簽之間聯(lián)系的網(wǎng)絡(luò)一部分。
 (a)
(a)  (b)
(b)
(a) one hot encoding (b)embedding
神經(jīng)網(wǎng)絡(luò)分析
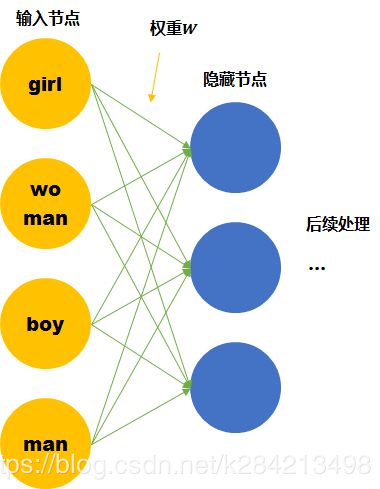
假設(shè)我們的詞匯只有4個(gè),girl, woman, boy, man,下面就思考用兩種不同的表達(dá)方式會(huì)有什么區(qū)別。
One hot representation
盡管我們知道他們彼此的關(guān)系,但是計(jì)算機(jī)并不知道。在神經(jīng)網(wǎng)絡(luò)的輸入層中,每個(gè)單詞都會(huì)被看作一個(gè)節(jié)點(diǎn)。 而我們知道訓(xùn)練神經(jīng)網(wǎng)絡(luò)就是要學(xué)習(xí)每個(gè)連接線的 權(quán)重。如果只看第一層的權(quán)重,下面的情況需要確定43個(gè)連接線的關(guān)系,因?yàn)槊總€(gè)維度都彼此獨(dú)立,girl的數(shù)據(jù)不會(huì)對(duì)其他單詞的訓(xùn)練產(chǎn)生任何幫助,訓(xùn)練所需要的數(shù)據(jù)量,基本就固定在那里了。
我們這里手動(dòng)的尋找這四個(gè)單詞之間的關(guān)系 f 。可以用兩個(gè)節(jié)點(diǎn)去表示四個(gè)單詞。每個(gè)節(jié)點(diǎn)取不同值時(shí)的意義如下表。 那么girl就可以被編碼成向量[0,1],man可以被編碼成[1,1](第一個(gè)維度是gender,第二個(gè)維度是age)。

那么這時(shí)再來(lái)看神經(jīng)網(wǎng)絡(luò)需要學(xué)習(xí)的連接線的權(quán)重就縮小到了23。同時(shí),當(dāng)送入girl為輸入的訓(xùn)練數(shù)據(jù)時(shí),因?yàn)樗怯蓛蓚€(gè)節(jié)點(diǎn)編碼的。那么與girl共享相同連接的其他輸入例子也可以被訓(xùn)練到(如可以幫助到與其共享female的woman,和child的boy的訓(xùn)練)。
總得來(lái)說(shuō),label embedding也就是要達(dá)到第二個(gè)神經(jīng)網(wǎng)絡(luò)所表示的結(jié)果,降低訓(xùn)練所需要的數(shù)據(jù)量。
label embedding就是要從數(shù)據(jù)中自動(dòng)學(xué)習(xí)到輸入空間到Distributed representation空間的 映射f 。
5.CNN+RNN(CNN-LSTM)
網(wǎng)絡(luò)框架主要分為cnn和rnn兩個(gè)部分,cnn負(fù)責(zé)提取圖片中的語(yǔ)義信息,rnn負(fù)責(zé)建立image/label關(guān)系和label dependency的模型。
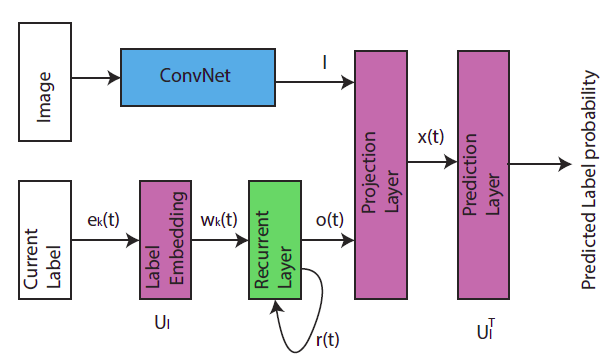 網(wǎng)絡(luò)模型
網(wǎng)絡(luò)模型
另外,在識(shí)別不同的object的時(shí)候,RNN會(huì)將attention轉(zhuǎn)移到不同的地方,如下圖:

本文兩個(gè)類(lèi)別,“zebra” and “elephant”,在預(yù)測(cè)zebra時(shí),我們發(fā)現(xiàn)網(wǎng)絡(luò)將attention集中到zebra那塊。
這是一個(gè)考慮全局級(jí)別的標(biāo)簽依賴性,屬于高階策略。
6.RLSD
RLSD 在CNN-RNN的基礎(chǔ)上,加入了區(qū)域潛在語(yǔ)義依賴關(guān)系,考慮到圖像的位置信息和標(biāo)簽之間的相關(guān)性,對(duì)算法進(jìn)行進(jìn)一步優(yōu)化。
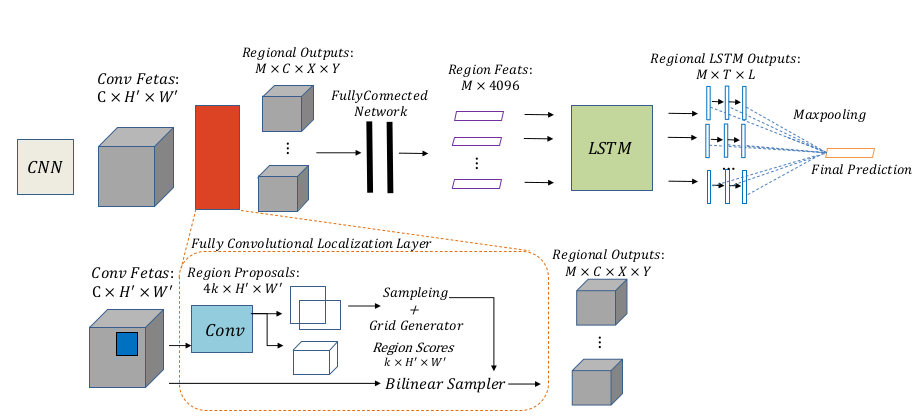 RLSD神經(jīng)網(wǎng)絡(luò)
RLSD神經(jīng)網(wǎng)絡(luò)
6.HCP
HCP的基本思想是,首先提取圖像中的候選區(qū)域(基本上是上百個(gè)),然后對(duì)每個(gè)候選區(qū)域進(jìn)行分類(lèi),最后使用 cross-hypothesis max-pooling 將圖像中所有的候選區(qū)域分類(lèi)結(jié)果進(jìn)行融合,得到整個(gè)圖像的多類(lèi)別標(biāo)簽,其中也利用到了attention機(jī)制,如下圖:
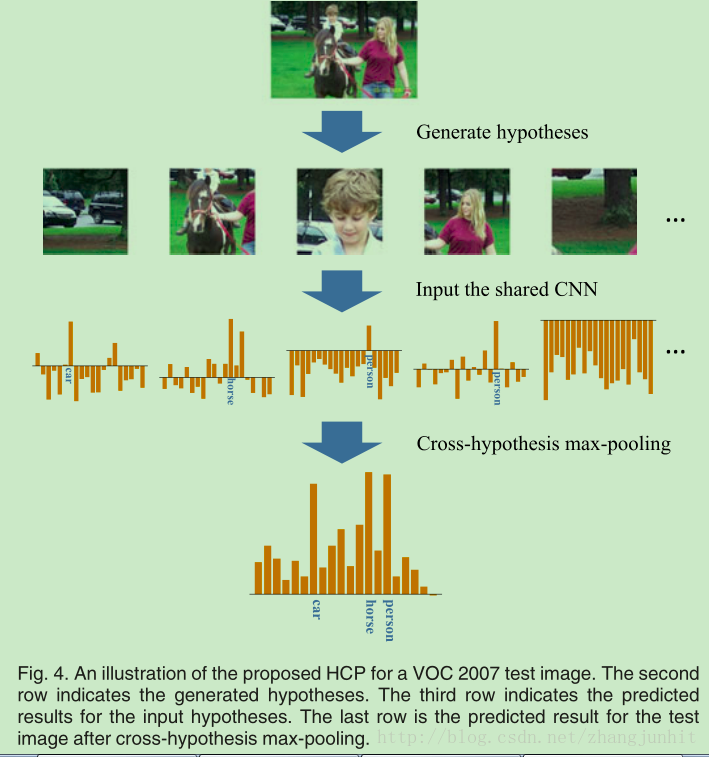
attention機(jī)制:像car,person,horse權(quán)重大,注意力比較高。這樣做的好處是我們?cè)谟?xùn)練圖片時(shí)不需要加入位置信息,該算發(fā)會(huì)框出很多個(gè)框,自動(dòng)調(diào)節(jié)相關(guān)標(biāo)簽的框權(quán)值更大,達(dá)到減弱噪音的目的。
總結(jié)
1.目前存在的問(wèn)題
目前多標(biāo)簽分類(lèi)依然存在單標(biāo)簽分類(lèi),目標(biāo)檢測(cè)的問(wèn)題,如遮擋,小物體識(shí)別
另外由于標(biāo)簽相對(duì)多存在的問(wèn)題有要分類(lèi)的可能性隨類(lèi)別呈指數(shù)性增長(zhǎng),rank,樣本分布不均
2.應(yīng)用領(lǐng)域
圖像搜索,圖像和視頻的語(yǔ)義標(biāo)注
2.研究發(fā)展方向
從整體上來(lái)看,multi-label classification 由于涉及到多個(gè)標(biāo)簽,所以需要對(duì)圖片和標(biāo)簽了解的信息量更多,意味著要分類(lèi)的可能性呈指數(shù)型增長(zhǎng)。
為了減少這種分類(lèi)的可能性,需要考慮標(biāo)簽與標(biāo)簽,標(biāo)簽與圖片之間的聯(lián)系來(lái)降低信息量。
-
- 第一 涉及到標(biāo)簽與標(biāo)簽之間的關(guān)系,也就是NLP里詞語(yǔ)與詞語(yǔ)之間的聯(lián)系,這個(gè)是語(yǔ)義層次上的
- 第二 涉及到標(biāo)簽與圖片之間的關(guān)系 ,就是標(biāo)簽與圖片特征之間的聯(lián)系,常用的是attention機(jī)制

 浙公網(wǎng)安備 33010602011771號(hào)
浙公網(wǎng)安備 33010602011771號(hào)