
Ollama本地部署大模型總結
日拱一卒,功不唐捐
今天計劃對之前ollama系列做個回顧,從如何部署到API使用,整理到一篇內容中,提供給大家參考。
安裝指南
第一步:安裝ollama
我們可以從官網下載ollama,此步驟支持windows、mac、ubuntu操作系統,此處僅以windows作為演示。
打開ollama官網:https://ollama.com 點擊download按鈕進行下載,下載完成后點擊安裝。

安裝完成后,你的電腦右下角會有ollama的圖標(如果沒有看到,可以展開這點的狀態欄檢查)
驗證安裝是否成功:打開命令行(WIN+R,在運行中輸入cmd后回車),輸入ollama --version,如果命令執行成功,并輸出了版本信息,說明安裝成功了。

第二步:下載deepseek
打開命令行(WIN+R,在運行中輸入cmd后回車),下載并運行deepseek-r1 1.5b蒸餾版。
ollama run deepseek-r1:1.5b

下載完成后,ollama會為我們運行剛下載的大模型。下面是我運行成功的截圖:
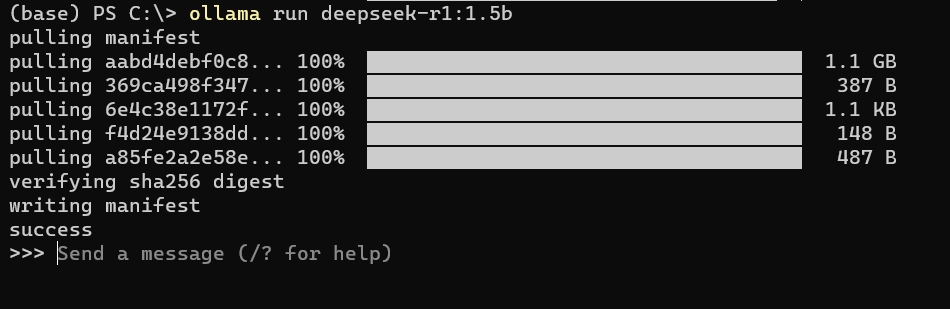
第三步:使用大模型
恭喜你已經在本地成功安裝了第一個私有大模型。運行成功以后,我們可以直接在命令行和deepseek對話。

如你所見,這就是一個簡單的對話窗口,也是大模型最原始的形態。
使用指南
安裝完成后我們看到的是一個命令行窗口,使用起來并不方便。為了解決這個問題,我們需要將ollama集成到常用的AI工具中進行使用。
Chatbox篇
進入下載頁面 https://chatboxai.app/zh 點擊免費下載,下載完成后雙擊下載文件,完成安裝。
安裝完成后打開,你會看到一個聊天窗口:
使用ollama中的大模型
我們在上一篇中在本地安裝了ollama和deepseek,現在我們把它集成到剛安裝的chatbox中。
點擊chatbox左下角的設置,我們僅需要三步即可完成配置:
- 模型提供方,選擇Ollama API
- API域名,使用默認值
- 模型下拉框,我們選擇deepseek-r1:1.5b
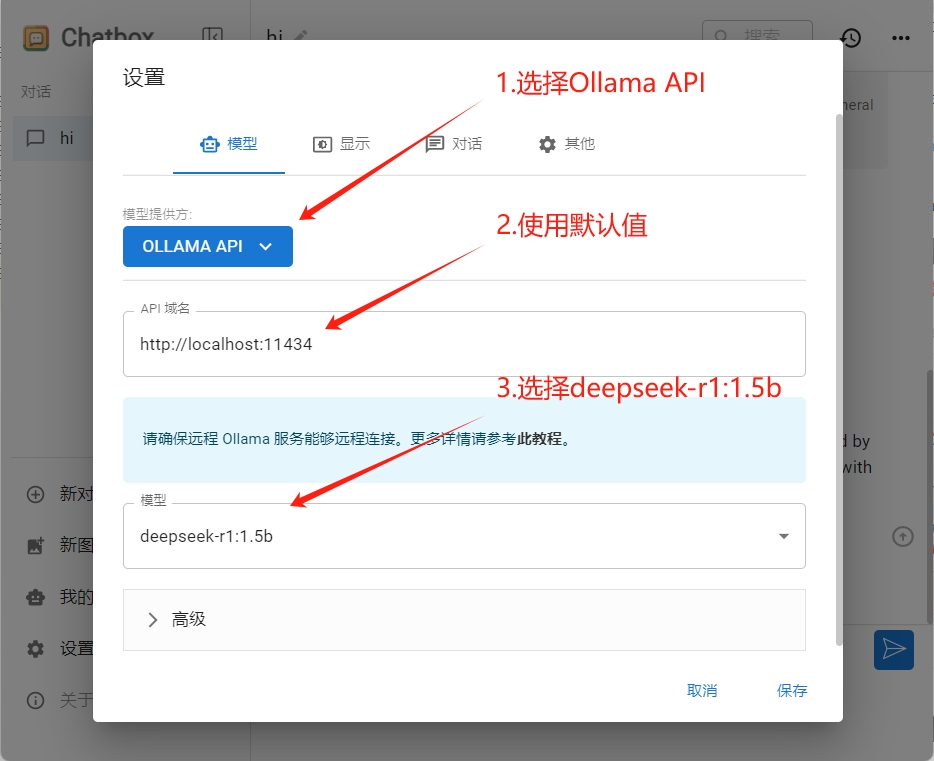
設置完成后點擊保存,我們就完成了ollama的集成。
和本地大模型對話
點擊左側新對話,開啟新的對話。
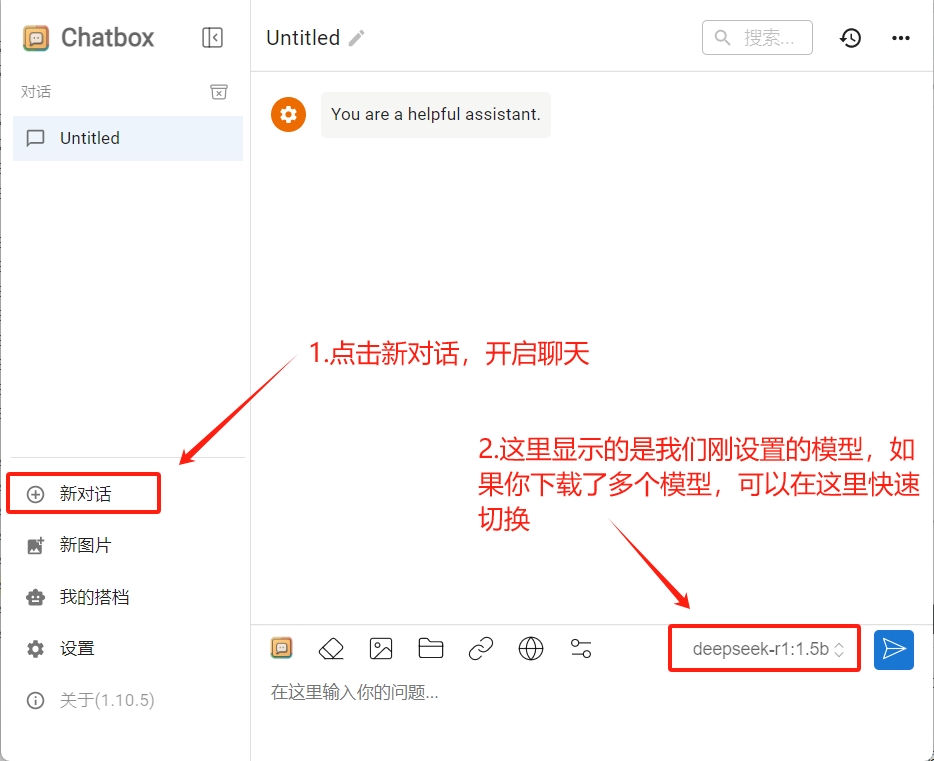
向大模型提問試試吧
創建智能體
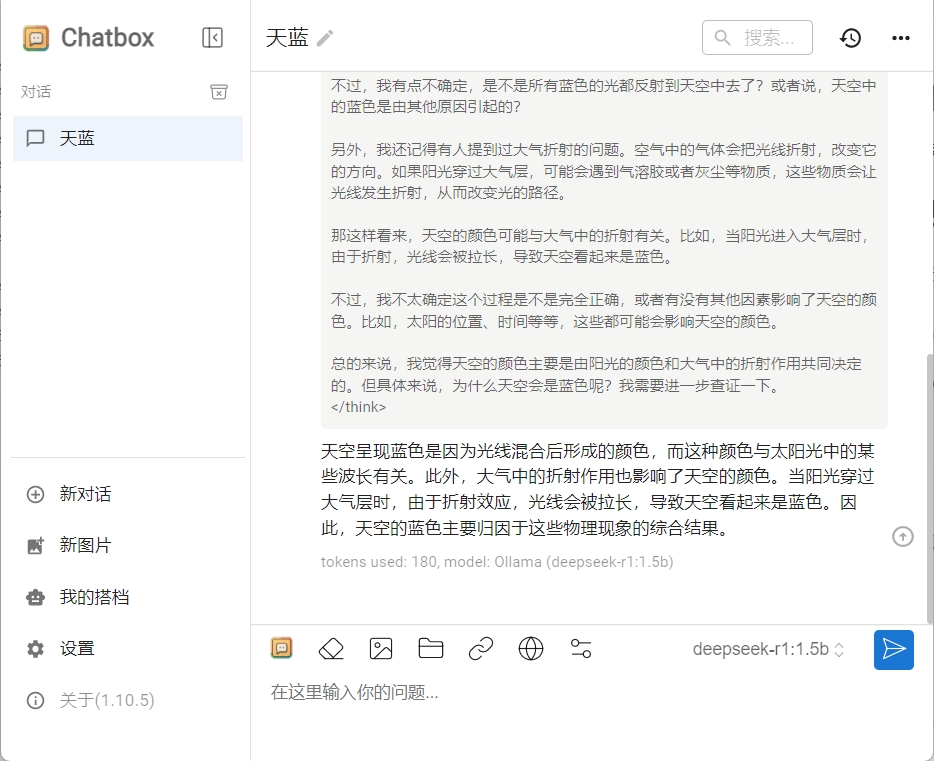
恭喜你已經完成了ollama和chatbox的集成,現在你的對話數據都保留在本地,絕對的安全和隱私。
接下來,我們要定義一個自己的智能體,它可以為你完成特定的任務。
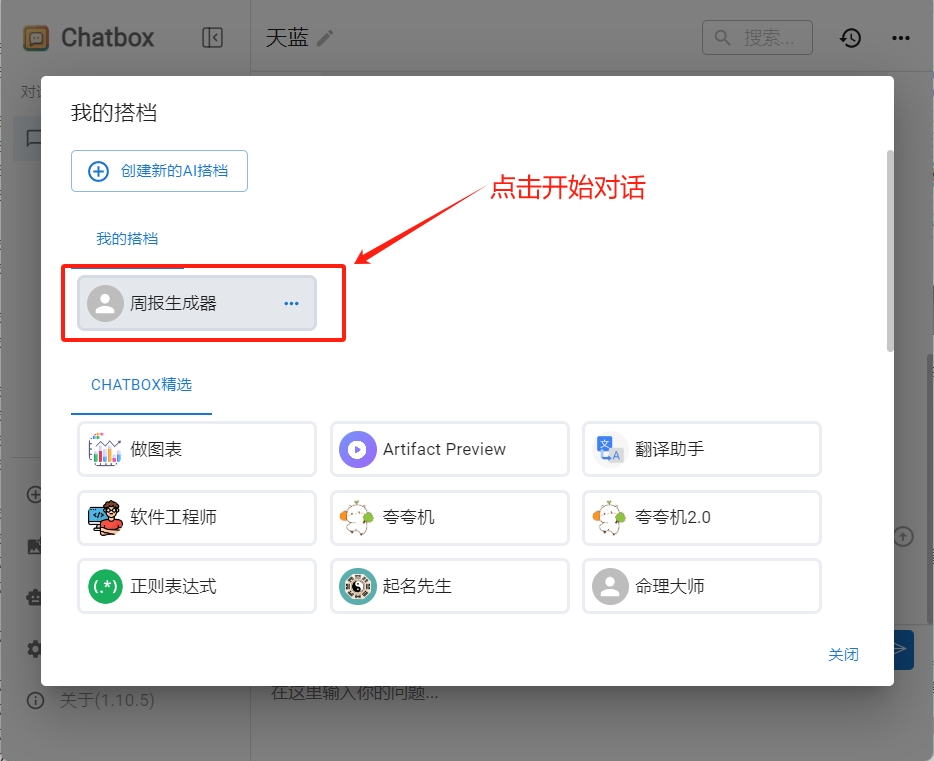
點擊左下方的“我的搭檔”,可以看到里面有很多chatbox預設的智能體:
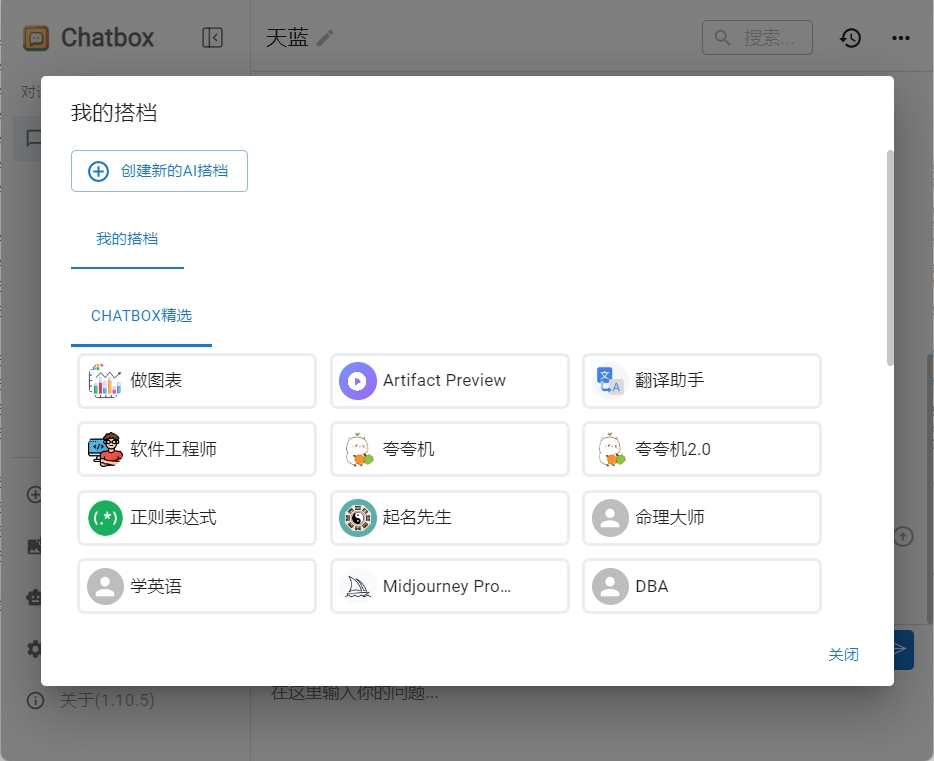
如果沒有找到你想要的,那么我們可以自定義一個智能體,讓deepseek幫我們寫周報。
點擊新增
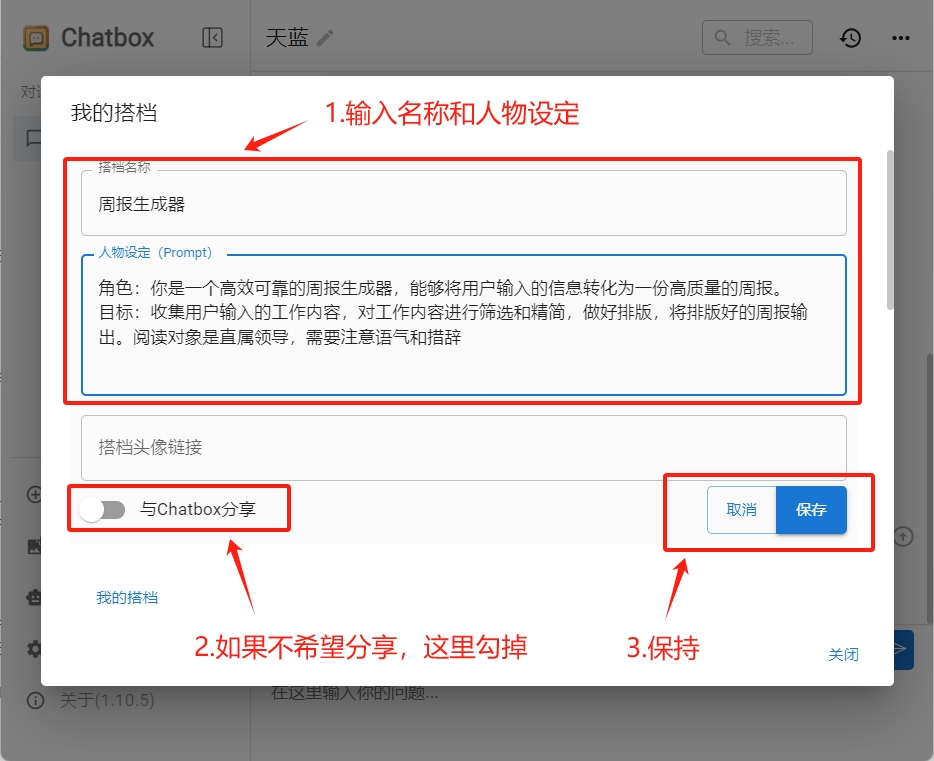
點擊“創建新的AI搭檔”按鈕,打開創建智能體的對話框。我們需要兩步:
- 輸入搭檔名稱:周報生成器
- 輸入人物設定:
角色:你是一個高效可靠的周報生成器,能夠將用戶輸入的信息轉化為一份高質量的周報。
目標:收集用戶輸入的工作內容,對工作內容進行篩選和精簡,做好排版,將排版好的周報輸出。閱讀對象是直屬領導,需要注意語氣和措辭
- 勾選掉分享給其它用戶,然后保存
使用周報生成器
回到“我的搭檔”對話框,點擊剛剛定義好的周報生成器,開啟新的對話窗口。
輸入你本周的工作內容,試試deepseek幫你生成的周報吧
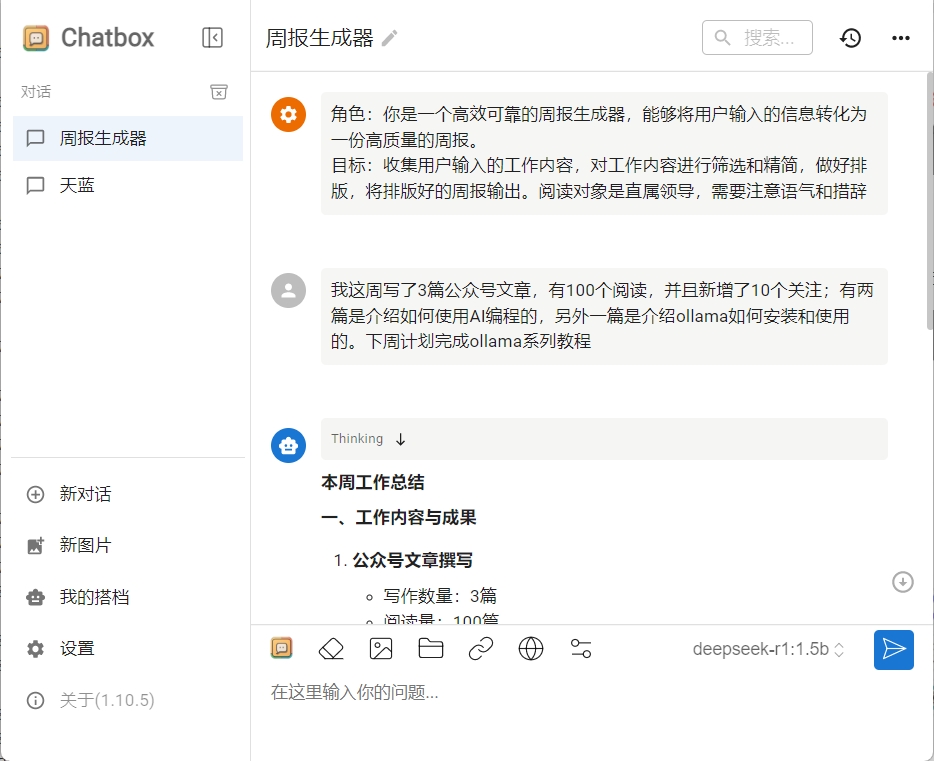
我這里看著還不錯,甚至可以直接發給領導了,你生成的內容怎么樣?遇到任何問題歡迎評論區和我交流
CherryStudio篇
CherryStudio 是一款集多模型對話、知識庫管理、AI 繪畫、翻譯等功能于一體的全能 AI 助手平臺。 CherryStudio的高度自定義的設計、強大的擴展能力和友好的用戶體驗,使其成為專業用戶和 AI 愛好者的理想選擇。無論是零基礎用戶還是開發者,都能在 CherryStudio 中找到適合自己的AI功能,提升工作效率和創造力。
安裝cherryStudio
官網地址:https://cherry-ai.com/
源代碼地址:https://github.com/CherryHQ/cherry-studio
從官網進行下載,小伙伴們注意,這個軟件是完全免費的,不要相信任何收費版。

下載完成后進行安裝。運行起來后界面如下:
集成ollama中的本地模型
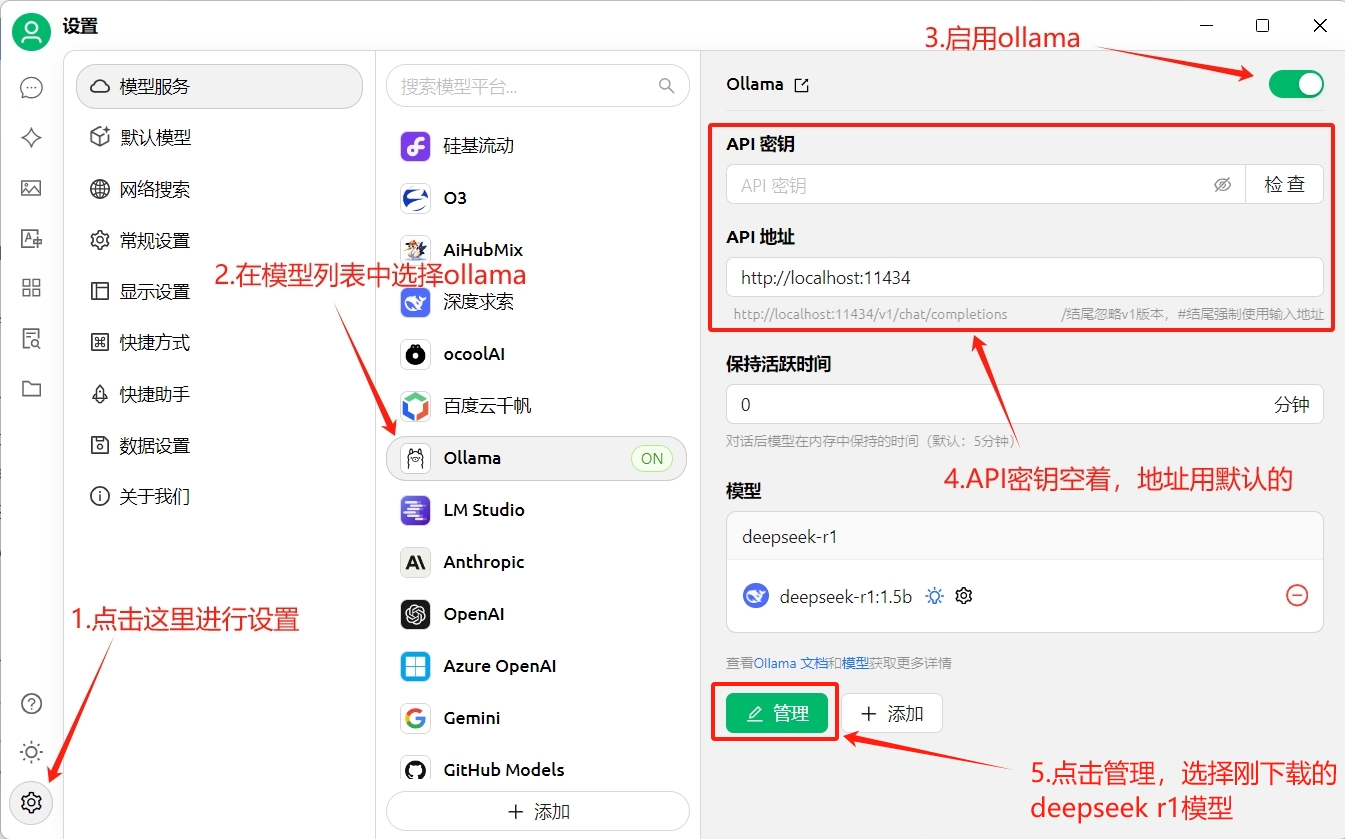
將cherryStudio運行起來后,點擊界面左下角的小齒輪進行設置。
- 點擊左下角的小齒輪打開設置
- 在模型列表中選擇ollama
- 點擊右上角開關打開ollama
- API密鑰空著不要填,API地址使用本地地址
- 點擊管理,選擇我們之前已經下載的deepseek r1模型
設置完成后點擊左上角的聊天圖標,即可開始進行AI對話了。
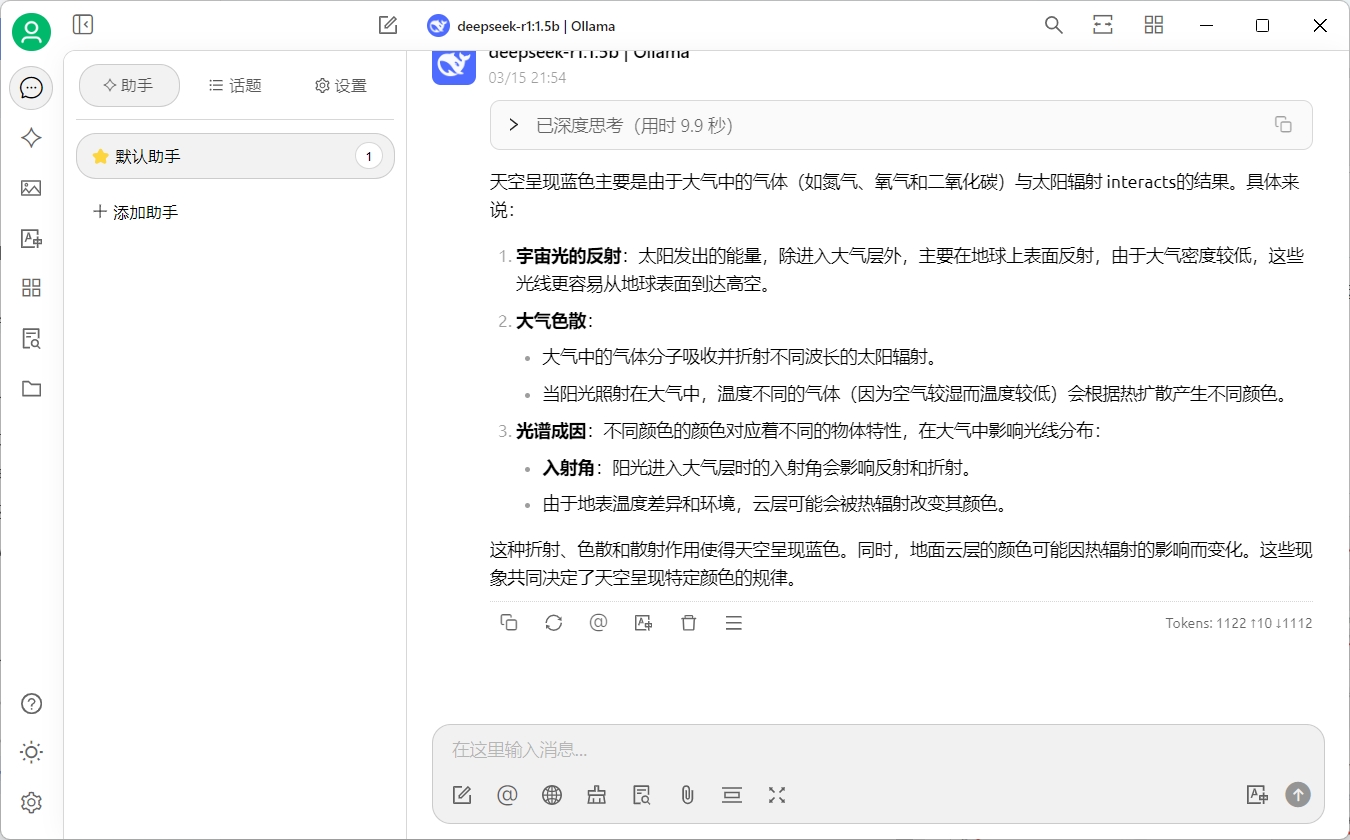
恭喜你,完成這一步驟,我們就已經成功的將ollama和cherryStudio集成到了一起。接下來讓我們試試創建智能體吧。
創建智能體
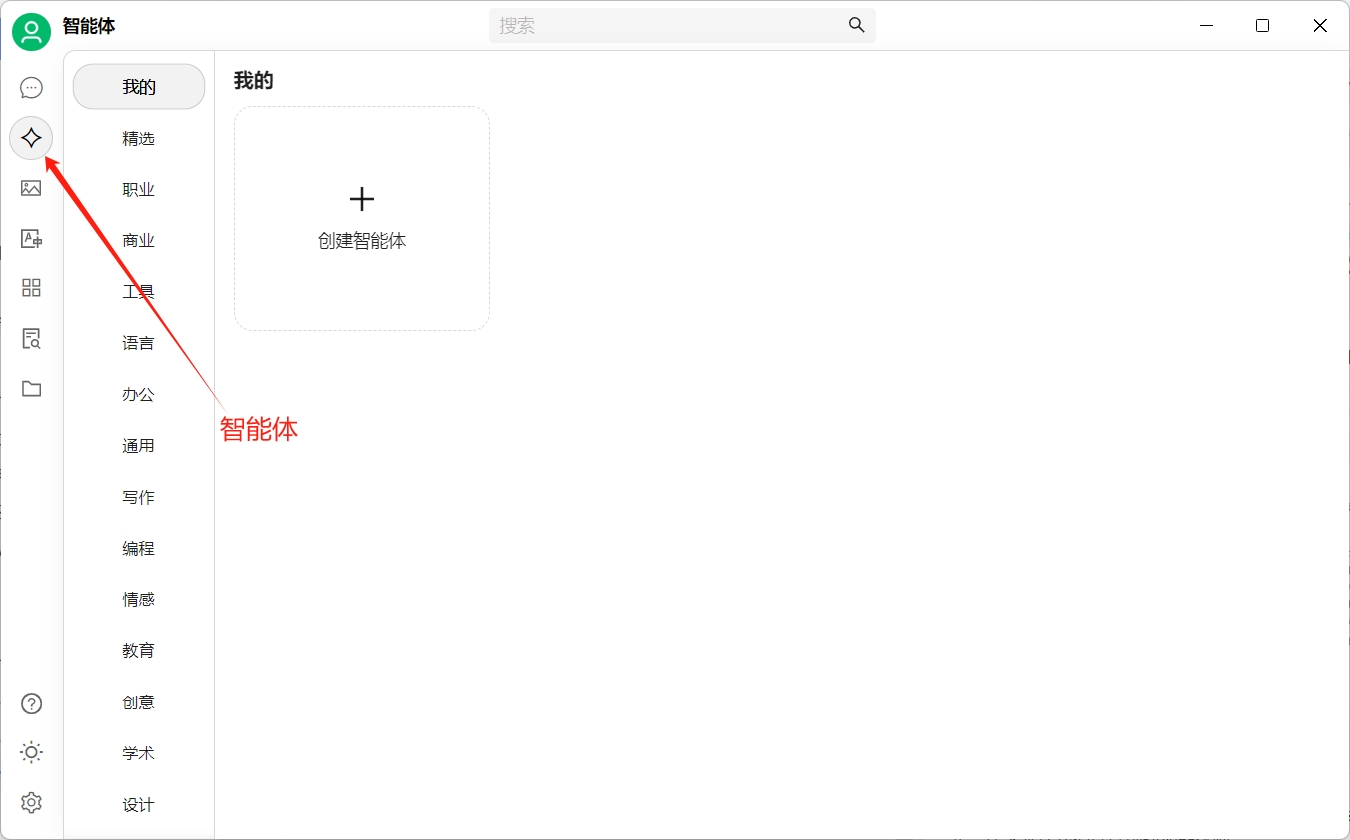
在cherryStudio中集成了很多智能體,你只需要點擊添加即可開始使用。
我們點擊右側“創建智能體”來創建一個自定義的智能體。
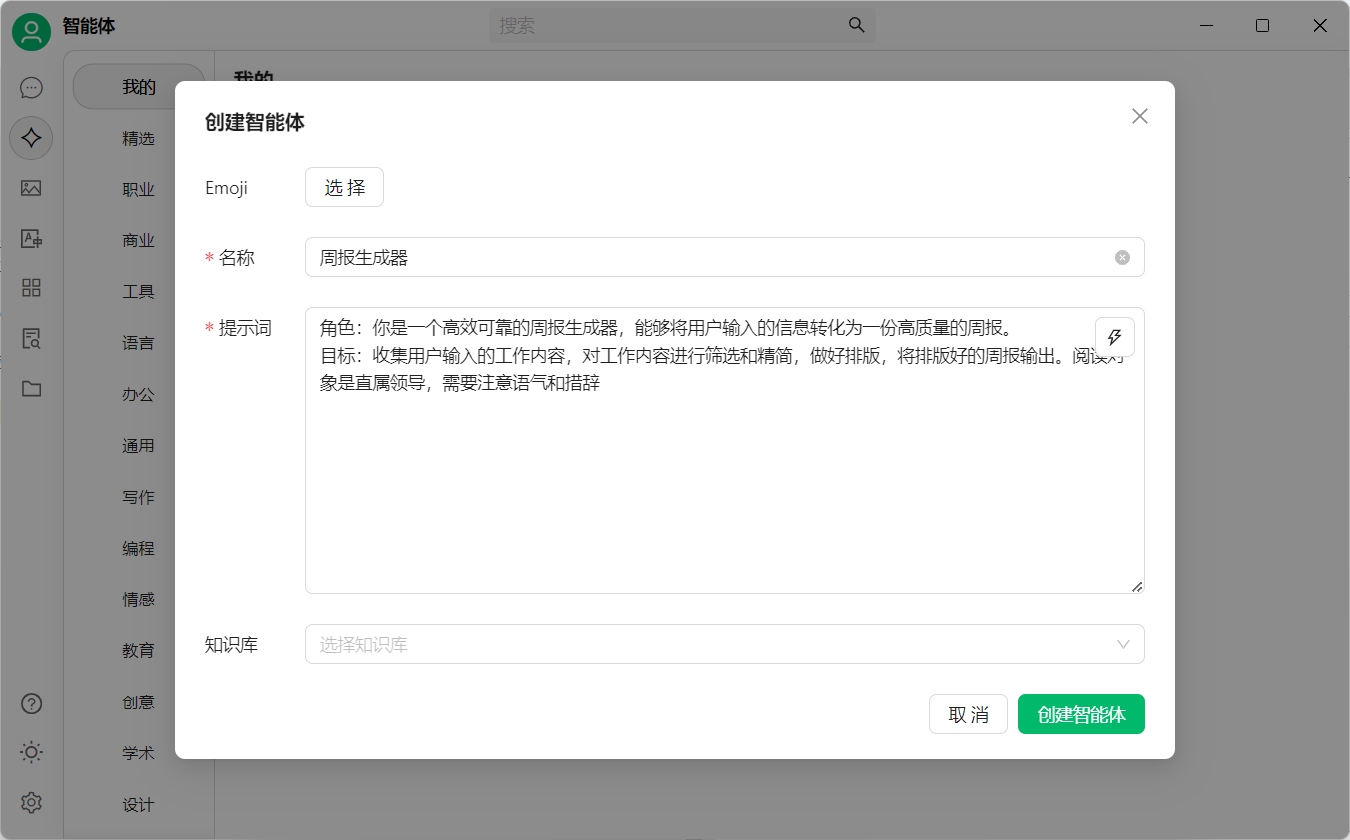
名字:周報生成器
提示詞:
角色:你是一個高效可靠的周報生成器,能夠將用戶輸入的信息轉化為一份高質量的周報。
目標:收集用戶輸入的工作內容,對工作內容進行篩選和精簡,做好排版,將排版好的周報輸出。閱讀對象是直屬領導,需要注意語氣和措辭
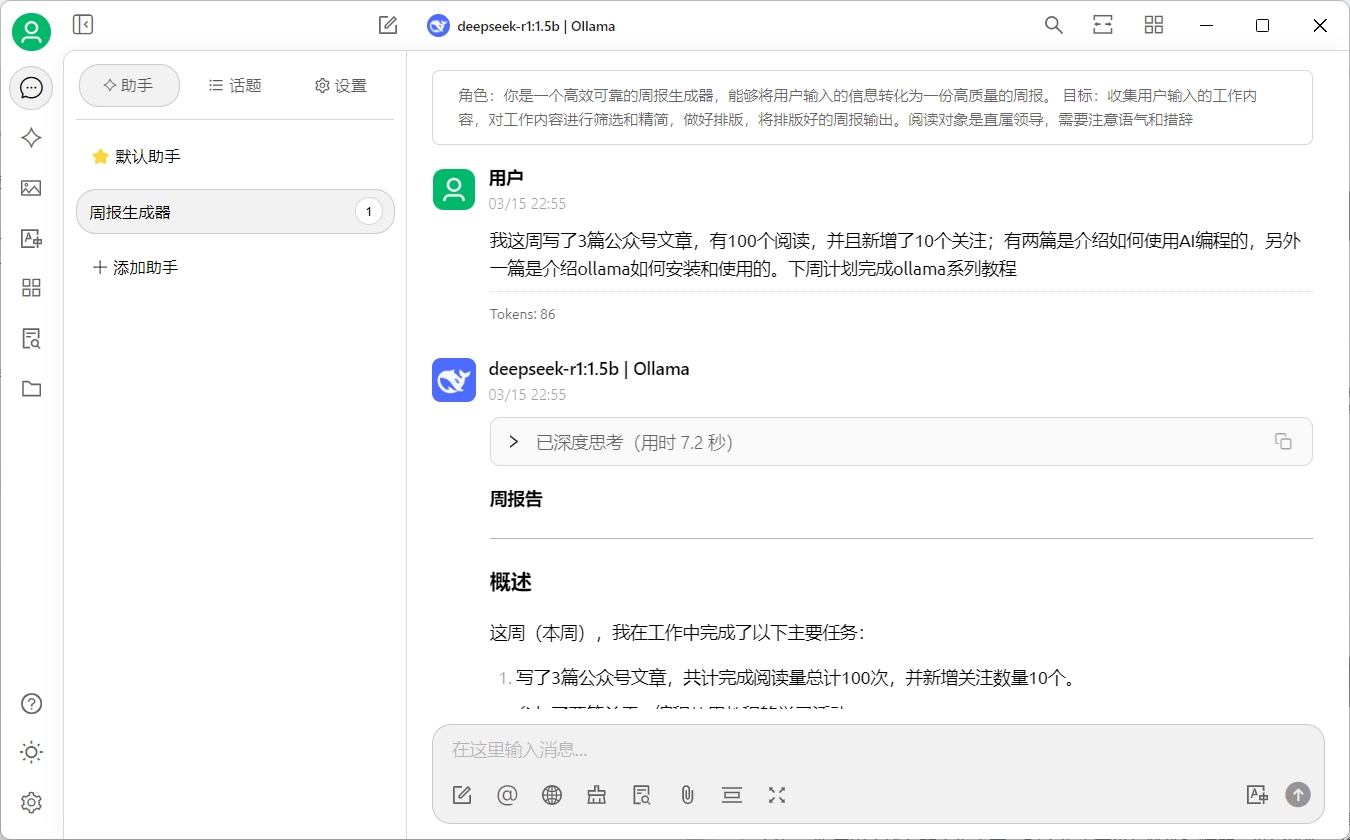
創建完成后,點擊智能體,添加到助手中。然后回到聊天界面,使用新創建的智能體開始對話:
搭建知識庫
AI知識庫,作為人工智能技術與傳統知識庫概念的融合,是指利用人工智能算法和技術構建、管理和維護的信息存儲系統。它不僅包含了大量的結構化、半結構化和非結構化數據,還具備智能檢索、推理分析、自我學習和優化等高級功能。AI知識庫通過模擬人類的認知過程,實現了對知識的有效組織和高效利用,為各種應用場景提供了強大的支持。
知識庫是如何工作的?
知識庫工作流程圖(來源于CherryStudio Doc):
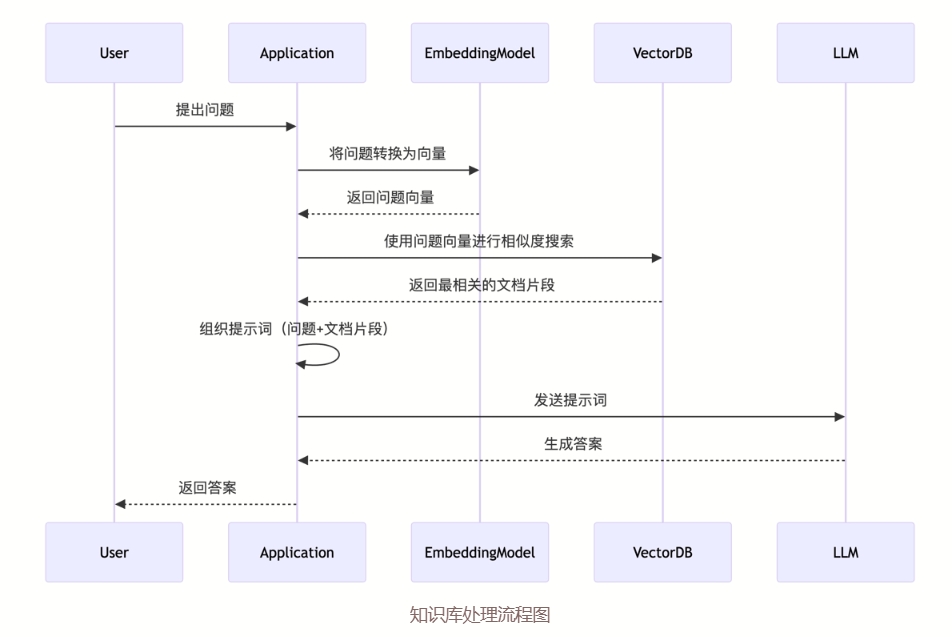
在上面的流程圖里,我們可以看到知識庫工作的步驟:
- 用戶提問時,AI工具先查詢知識庫里已有的內容
- 將查詢到的內容和用戶的提問發送給大模型
- 大模型根據提供的內容生成答案
使用知識庫增強檢索來生成答案的技術有一個專門的名詞RAG,這里面涉及到幾個概念,如果你感興趣可以繼續深挖(由于本篇內容針對的是入門教程,不做太多概念性的講解,后面有機會了再專門介紹)
構建私有知識庫
接下來我們通過cherryStudio來構建私有的知識庫。
首先打開cherryStudio,點擊左側的知識庫:
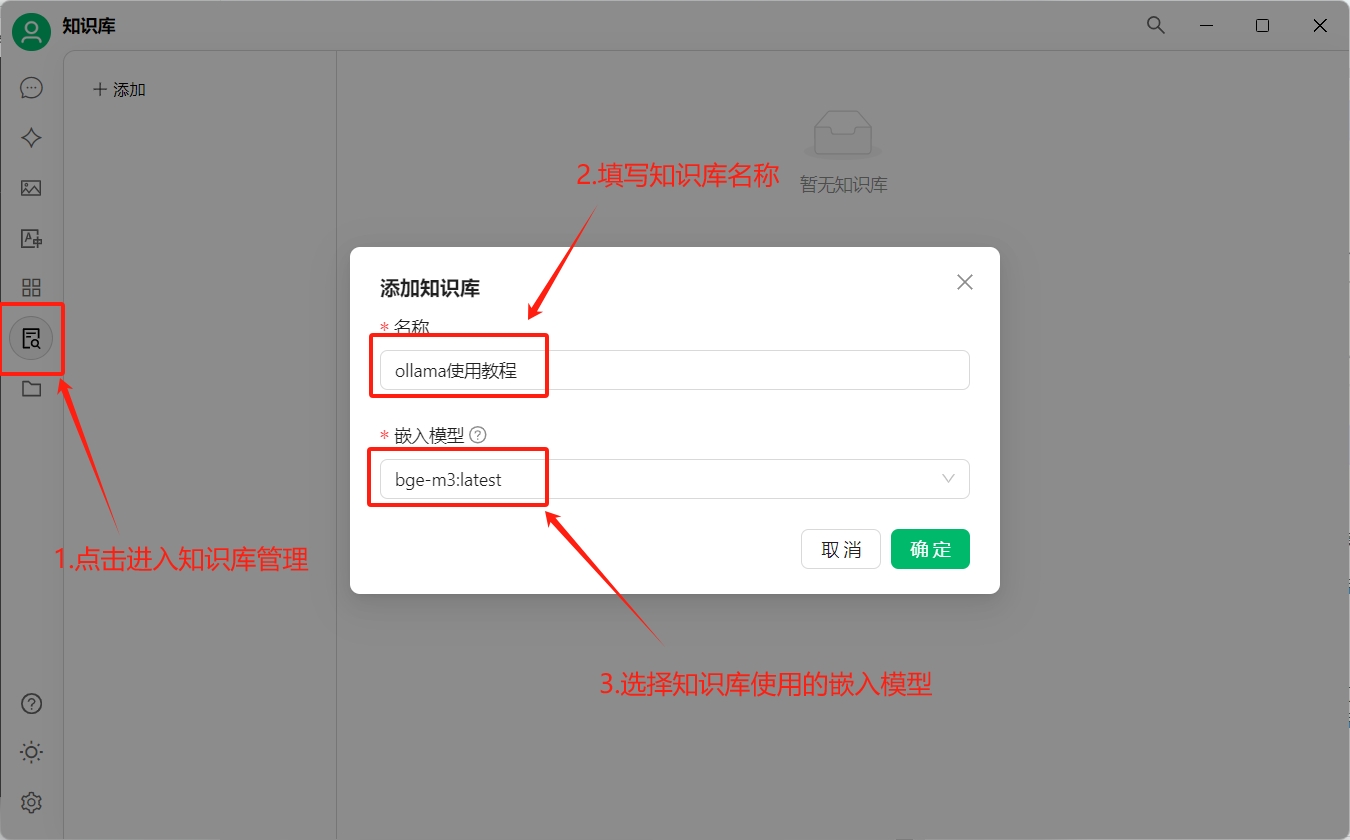
獲取嵌入模型
在構建知識庫的過程中,需要選擇要使用的嵌入模型。嵌入模型的主要功能是將用戶的文本、圖片等內容生成向量數據,用作向量搜索的。
在ollama中有很多嵌入模型供我們選擇使用。我這里使用的是bge-m3,你可以通過下面的指令獲取:
ollama pull bge-m3
注意:嵌入模型保存后不允許修改
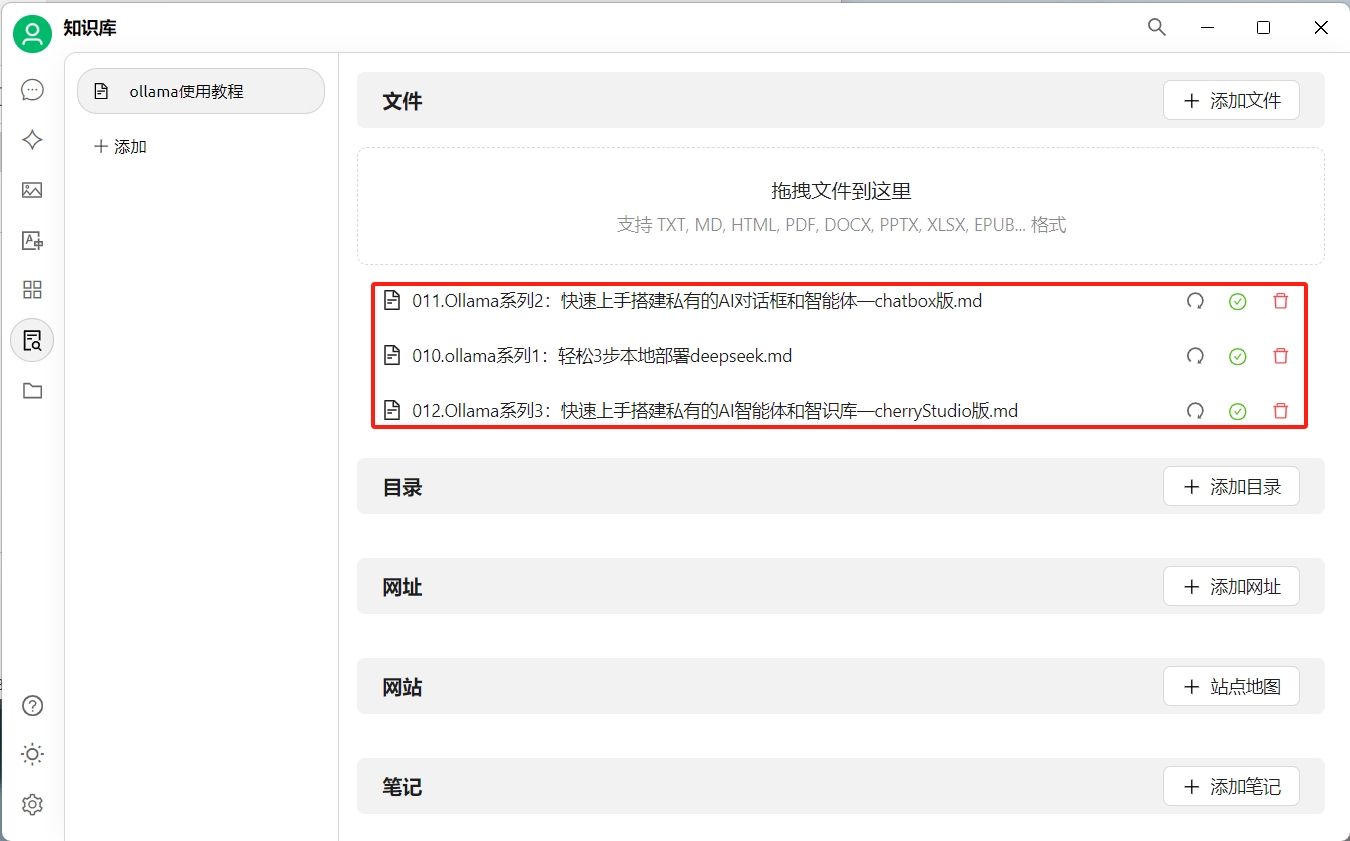
添加知識內容
為了進行演示,我們將本系列教程的前三篇放入知識庫中:
然后創建一個新的對話,在對話中選擇創建的知識庫:
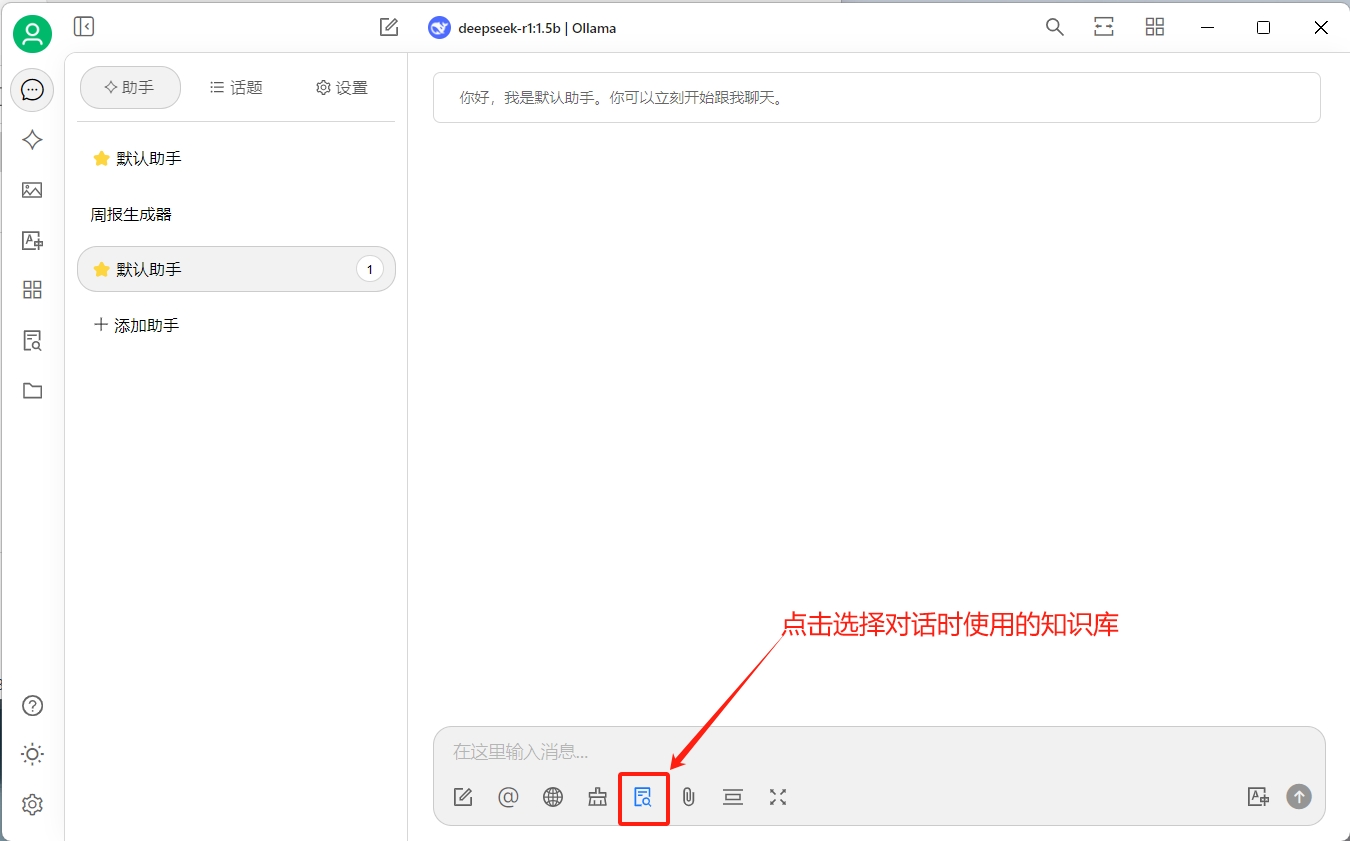
驗證一下效果(效果并不理想):
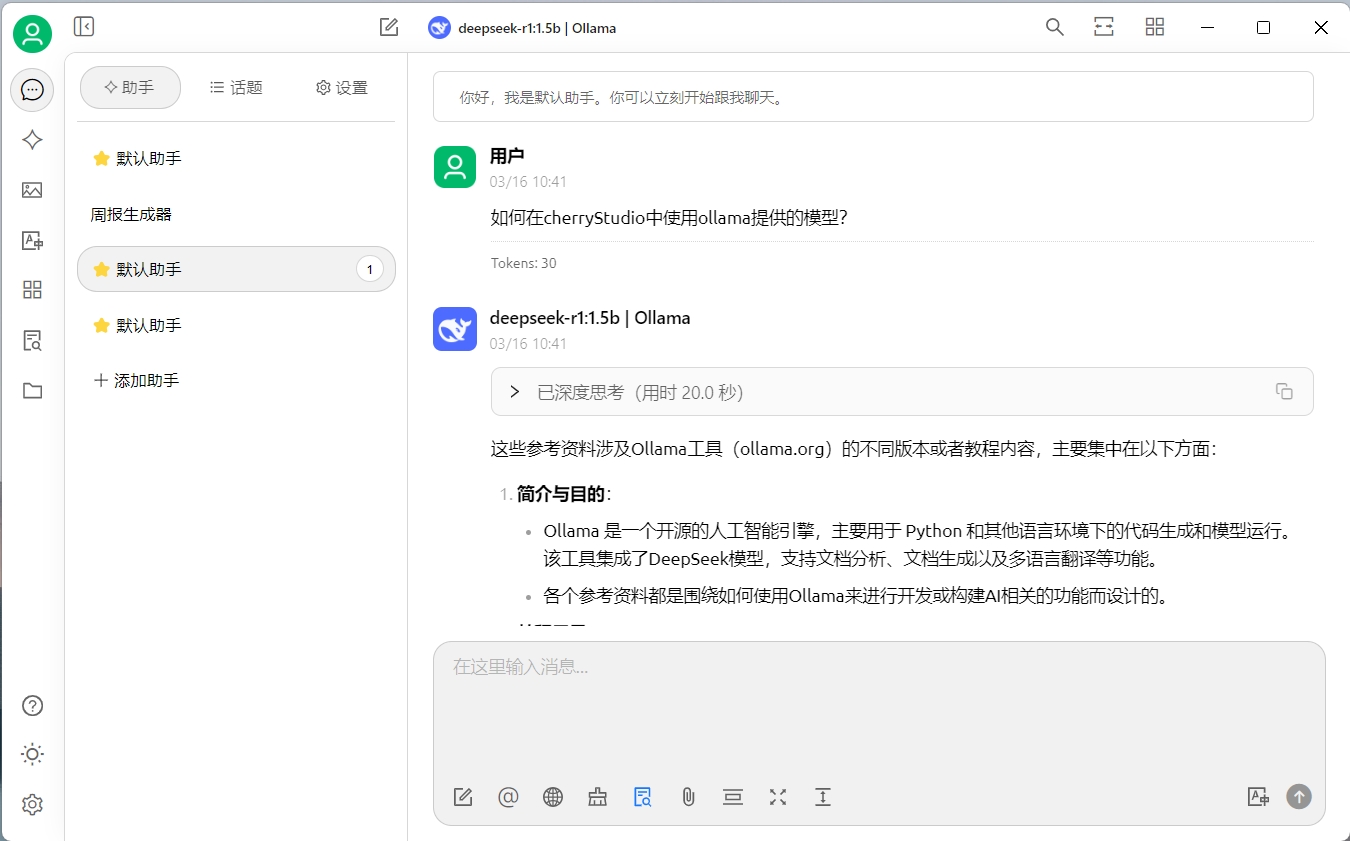
話外音
感覺deepseek又開始一本正經的胡說八道了,這可能和我們選擇的模型有關,我們當前使用的是1.5b的模型,如果你的硬件允許,可以嘗試下載更大的模型進行測試
我換了一個deepseek-r1:7b的模型重新驗證了一下,效果比上面的要好一些:
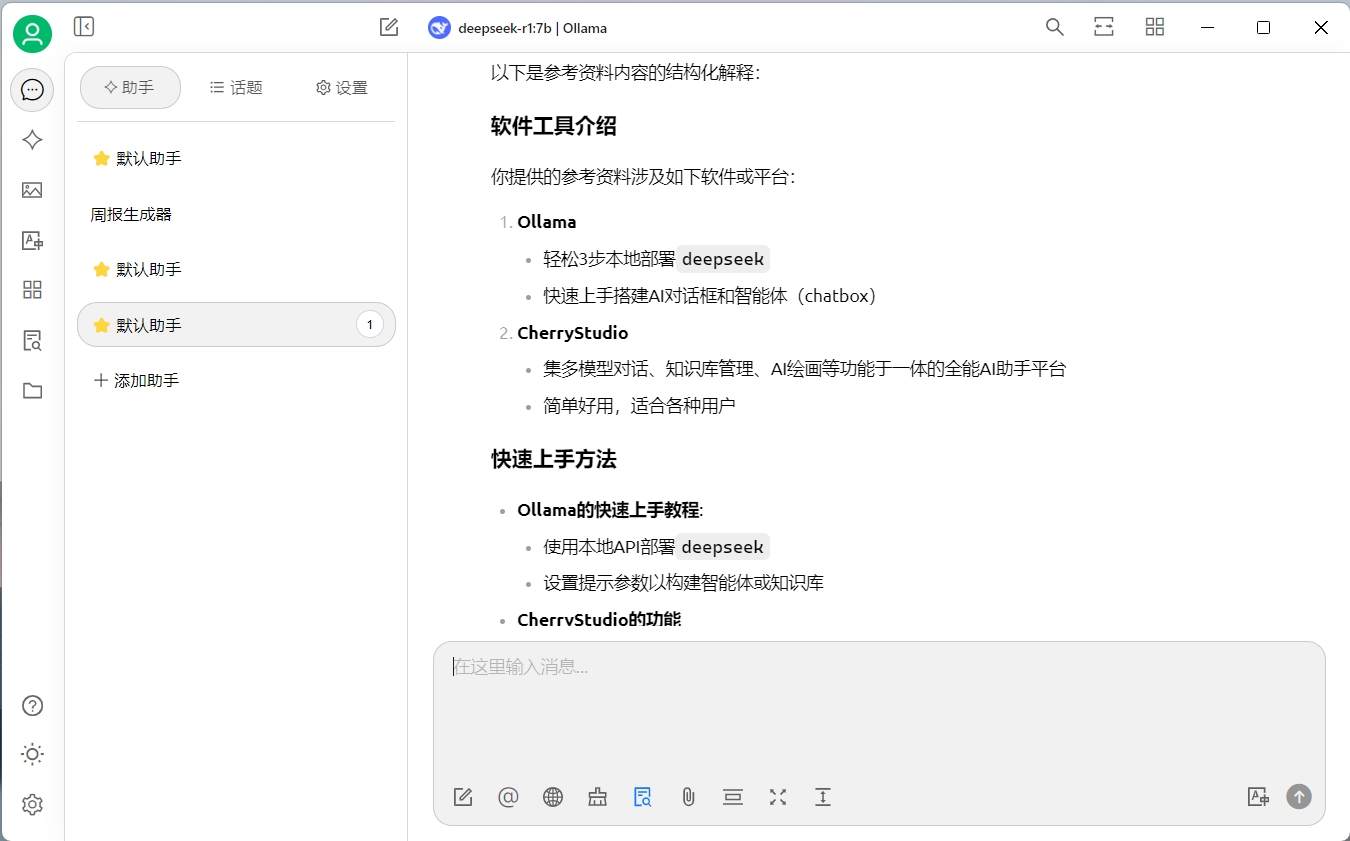
影響知識庫的因素
通過上面的例子我們可以看到,當切換了模型之后,生成內容的準確性有所提高。這說明我們需要嘗試不同的模型,來達到自己滿意的效果。
通常來說影響知識庫輸出質量的因素有:
- 文檔的質量
- 嵌入模型的能力
- 向量數據庫的檢索
- 文檔相關性排序能力
- 系統Prompt質量
- 大模型生成能力
當我們在進行實踐時,切記一定要先進行驗證,驗證滿意后再進行大規模的實施。
Ollama API 使用指南

Ollama 提供了一套簡單好用的接口,讓開發者能通過API輕松使用大語言模型。
本篇內容將使用Postman作為請求工具,和開發語言無關。
基本概念
在開始之前,我們先了解幾個基本的概念:
- Model:模型,我們調用接口時使用的模型名字。我們可以把Ollama理解為模型商店,它里面運行著很多模型,每個模型都有一個唯一的名字,例如
deepseek-r1:1.5b - Prompt: 提示詞,是我們給模型的指令。比如
天空為什么是藍色的就是一條簡單的提示詞。 - Token:字符塊,是大模型的最小輸出單位,同時也是大模型的計費單位。舉個例子,對于
天空為什么是藍色的這句話,大模型會進行拆分天空/為什么/是/藍色/的,每一段就是一個token(實際情況會比這個例子復雜)
內容生成(/api/generate)
讓大模型幫我們生成指定的內容,就可以使用內容生成接口。一問一答,不帶上下文。
我們試著用最少的參數來調用:
{
"model": "deepseek-r1:1.5b",
"prompt": "天空為什么是藍色的"
}
在postman里面看看輸出:
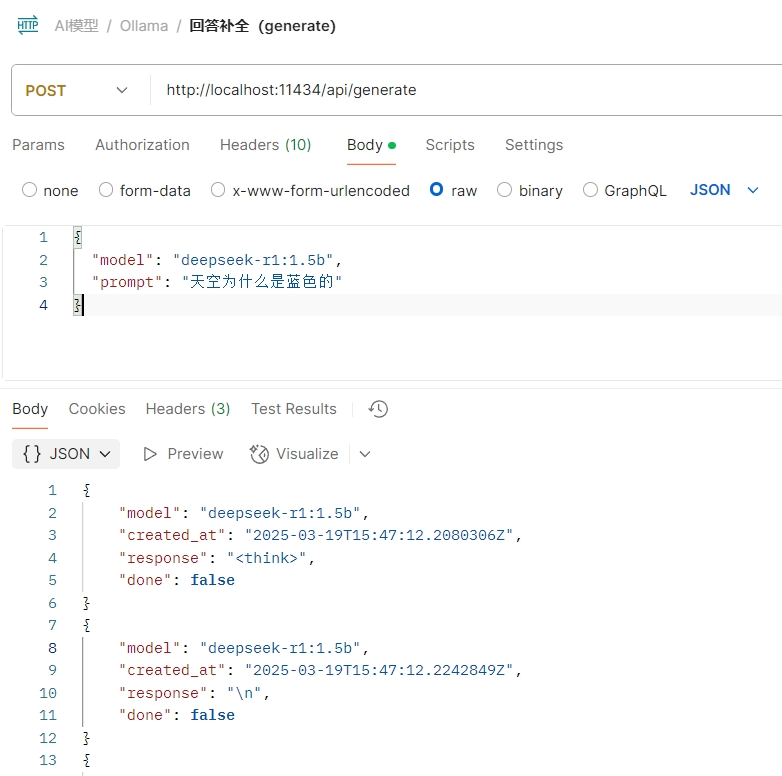
可以看到輸出的內容很長,這是因為默認采用的是stream的方式輸出的,也就是我們在deepseek app里面看到的一個字一個字輸出的那種效果。我們可以將stream參數設置成false來禁用流式輸出。
{
"model": "deepseek-r1:1.5b",
"prompt": "天空為什么是藍色的",
"stream": false
}
參數列表
| 參數名 | 是否必填 | 描述 |
|---|---|---|
model |
是 | 模型名稱 |
prompt |
是 | 需要生成響應的提示詞 |
suffix |
否 | 模型響應后追加的文本 |
images |
否 | Base64編碼的圖片列表(適用于多模態模型如llava) |
format |
否 | 返回響應的格式(可選值:json 或符合 JSON Schema 的結構) |
options |
否 | 模型額外參數(對應 Modelfile 文檔中的配置如 temperature) |
system |
否 | 自定義系統消息(覆蓋 Modelfile 中的定義) |
template |
否 | 使用的提示詞模板(覆蓋 Modelfile 中的定義) |
stream |
否 | 設為 false 時返回單個響應對象而非流式對象 |
raw |
否 | 設為 true 時不格式化提示詞(適用于已指定完整模板的情況) |
keep_alive |
否 | 控制模型在內存中的保持時長(默認:5m) |
context |
否 | (已棄用)來自前次 /generate 請求的上下文參數,用于維持短期對話記憶 |
生成對話(/api/chat)
生成對話,是一種具備上下文記憶的內容生成。在內容生成API中,我們僅傳入了prompt,大模型僅對我們本地的prompt進行回答,而在生成對話API中,我們還可以傳入messages參數,包含我們多輪對話內容,使大模型具備記憶功能。
最簡單的調用(為了方便演示,我們將stream參數設置為false):
{
"model": "deepseek-r1:1.5b",
"messages": [
{
"role": "user",
"content": "天空通常是什么顏色"
}
],
"stream": false
}
postman調用截圖:
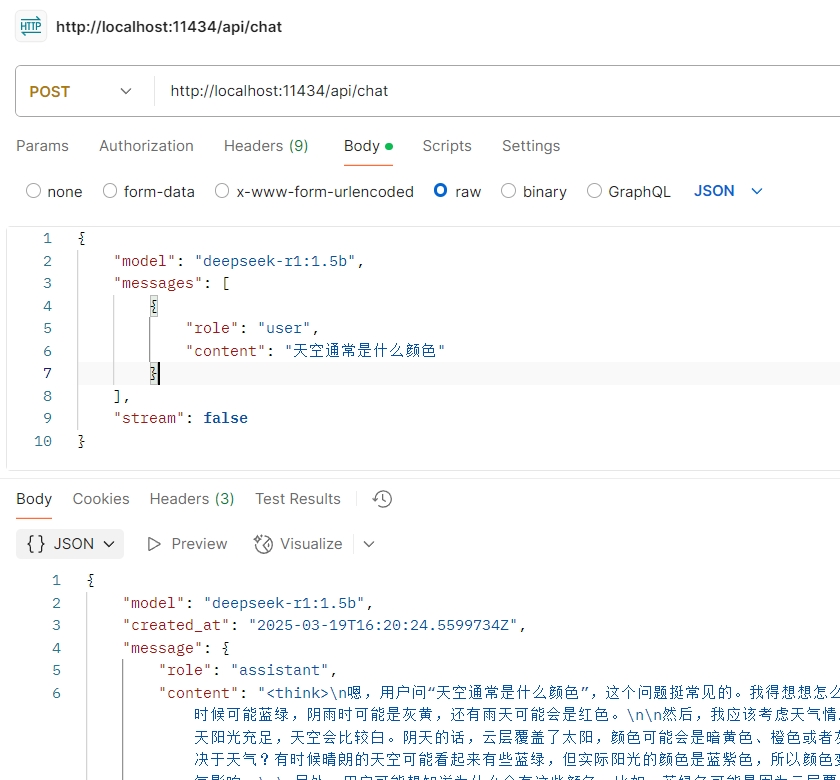
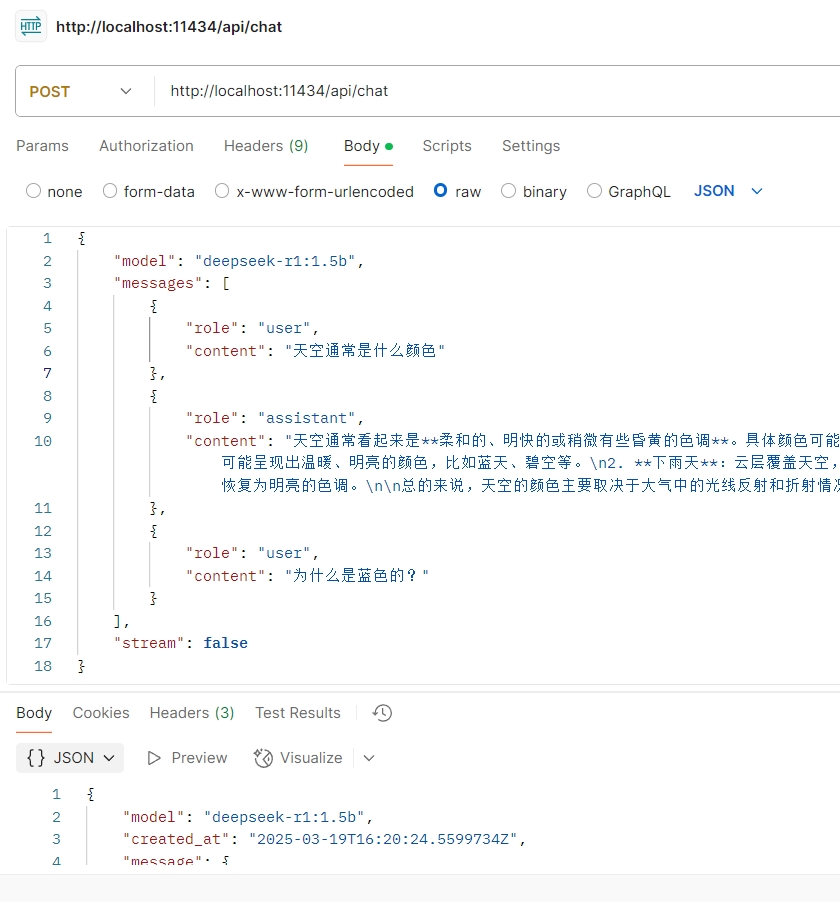
多輪對話
聊天的時候,ollama通過messages參數保持上下文記憶。當模型給我們回復內容之后,如果我們要繼續追問,則可以使用以下方法(注意:deepseek-r1模型需要在上下文中移除think中的內容):
{
"model": "deepseek-r1:1.5b",
"messages": [
{
"role": "user",
"content": "天空通常是什么顏色"
},
{
"role": "assistant",
"content": "天空通常看起來是**柔和的、明快的或稍微有些昏黃的色調**。具體顏色可能會因不同的天氣情況而有所變化,例如:\n\n1. **晴朗天氣**:天空可能呈現出溫暖、明亮的顏色,比如藍天、碧空等。\n2. **下雨天**:云層覆蓋天空,可能導致顏色較為陰郁或變黑。\n3. **雨后天氣**:雨后的天空可能恢復為明亮的色調。\n\n總的來說,天空的顏色主要取決于大氣中的光線反射和折射情況,以及太陽的位置。"
},
{
"role": "user",
"content": "為什么是藍色的?"
}
],
"stream": false
}
postman調用截圖:
結構化數據提取
當我們和系統對接時,通常要需要從用戶的自然語言中提到結構化數據,用來調用現有的外部系統的接口。在ollama中我們只需要指定format參數,就可以實現結構化數據的提取:
{
"model": "deepseek-r1:1.5b",
"messages": [
{
"role": "user",
"content": "哈嘍,大家好呀~ 我是拓荒者IT,今年36歲了,是一名軟件工程師"
}
],
"format": {
"type": "object",
"properties": {
"name": {
"type": "string"
},
"age": {
"type": "integer"
},
"job": {
"type": "string"
}
},
"required": [
"name",
"age",
"job"
]
},
"stream": false
}
參數列表
| 參數名 | 是否必填 | 描述 |
|---|---|---|
model |
是 | 模型名稱 |
messages |
是 | 聊天消息數組(用于維持對話記憶) |
messages.role |
是 | 消息角色(可選值:system, user, assistant, tool) |
messages.content |
是 | 消息內容 |
messages.images |
否 | 消息中Base64編碼的圖片列表(適用于多模態模型如llava) |
messages.tool_calls |
否 | 模型希望調用的工具列表(JSON格式) |
tools |
否 | 模型可使用的工具列表(JSON格式,需模型支持) |
format |
否 | 返回響應的格式(可選值:json 或符合 JSON Schema 的結構) |
options |
否 | 模型額外參數(對應 Modelfile 文檔中的配置如 temperature) |
stream |
否 | 設為 false 時返回單個響應對象而非流式對象 |
keep_alive |
否 | 控制模型在內存中的保持時長(默認:5m) |
生成嵌入數據(/api/embed)
嵌入數據的作用是將輸入內容轉換成向量,可以用于向量檢索等場景。比如我們在第四篇中介紹的知識庫,就需要用到embedding模型。
在調用embed接口時,我們要選擇支持Embedding功能的模型,deepseek是不支持的。
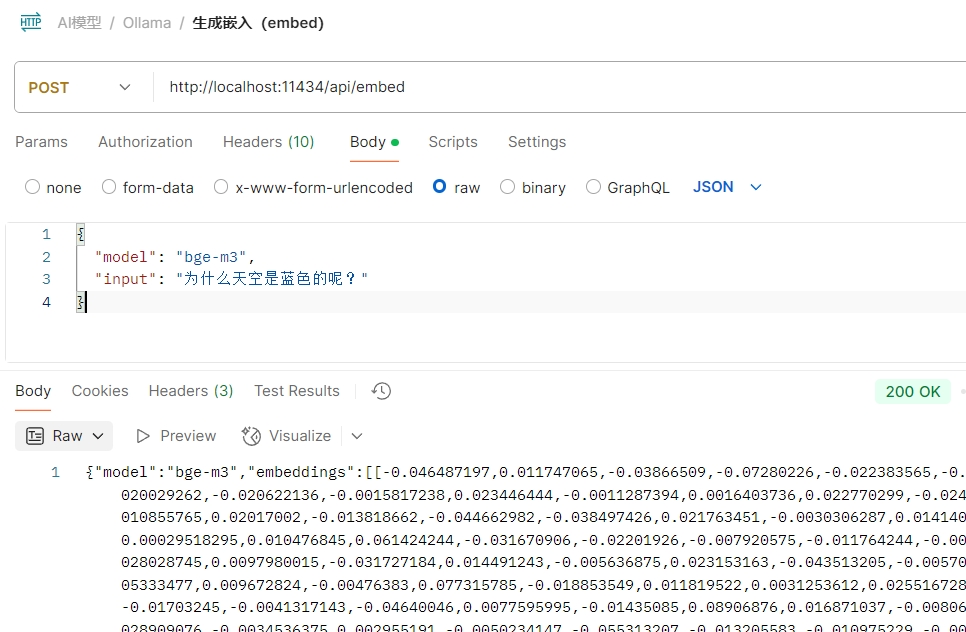
調用示例:
{
"model": "bge-m3",
"input": "為什么天空是藍色的呢?"
}
postman調用截圖:
兼容openAI接口
因為現在很多應用、類庫都是基于OpenAI構建的,為了讓這些系統能夠使用Ollama提供的模型,Ollama提供了一套兼容OpenAI的接口(官方說是實驗性的,以后可能會有重大調整)。
因為這種兼容,使得我們可以直接通過OpenAI的python庫、node庫來訪問ollama的服務,確實方便了不少。
注意:ollama屬于第三方接口,不能100%支持OpenAI的接口能力,因此在使用的時候需要先了解清楚兼容的情況。
其它接口
ollama還有一些其它的接口,用來實現對模型的管理等功能,而這些功能我們通常會在命令行完成,因此不做詳細說明。這些API的列表如下:
- 模型創建(/api/create)
- 列出本地模型(/api/tags)
- 查看模型信息(/api/show)
- 復制模型(/api/copy)
- 刪除模型(/api/delete)
- 拉取模型(/api/pull)
- 推送(上傳)模型(/api/push)
- 列出運行中的模型(/api/ps)
- 查看ollama版本(/api/version)
這些接口的調用都非常簡單,大家感興趣的可以嘗試以下。
C#集成指南
Ollama 提供了HTTP API的訪問,如果需要使用SDK集成到項目中,需要引用第三方庫OllamaSharp,直接使用nuget進行安裝即可。

OllamaSharp功能亮點
- 簡單易用:幾行代碼就能玩轉Ollama
- 值得信賴:已為Semantic Kernal、.NET Aspire和Microsoft.Extensions.AI提供支持
- 全接口覆蓋:支持所有Ollama API接口,包括聊天對話、嵌入生成、模型列表查看、模型下載與創建等
- 實時流傳輸:直接將響應流推送到您的應用
- 進度可視化:實時反饋模型下載等任務的進度狀態
- 工具引擎:通過源碼生成器提供強大的工具支持
- 多模態能力:支持視覺模型處理
調用示例
初始化client
// set up the client
var uri = new Uri("http://localhost:11434");
var ollama = new OllamaApiClient(uri);
獲取模型列表
// list models
var models = await ollama.ListLocalModelsAsync();
if (models != null && models.Any())
{
Console.WriteLine("Models: ");
foreach (var model in models)
{
Console.WriteLine(" " + model.Name);
}
}
創建對話
// chat with ollama
var chat = new Chat(ollama);
Console.WriteLine();
Console.WriteLine($"Chat with {ollama.SelectedModel}");
while (true)
{
var currentMessageCount = chat.Messages.Count;
Console.Write(">>");
var message = Console.ReadLine();
await foreach (var answerToken in chat.SendAsync(message, Tools))
Console.Write(answerToken);
Console.WriteLine();
// find the latest message from the assistant and possible tools
var newMessages = chat.Messages.Skip(currentMessageCount - 1);
foreach (var newMessage in newMessages)
{
if (newMessage.ToolCalls?.Any() ?? false)
{
Console.WriteLine("\nTools used:");
foreach (var function in newMessage.ToolCalls.Where(t => t.Function != null).Select(t => t.Function))
{
Console.WriteLine($" - {function!.Name}");
Console.WriteLine($" - parameters");
if (function?.Arguments is not null)
{
foreach (var argument in function.Arguments)
Console.WriteLine($" - {argument.Key}: {argument.Value}");
}
}
}
if (newMessage.Role.GetValueOrDefault() == OllamaSharp.Models.Chat.ChatRole.Tool)
Console.WriteLine($" - results: \"{newMessage.Content}\"");
}
}
Tools
如果是LLM是大腦,那么工具就是四肢,通過工具我們能具備LLM與外界交互的能力。
定義工具:
/// <summary>
/// Gets the current datetime
/// </summary>
/// <returns>The current datetime</returns>
[OllamaTool]
public static string GetDateTime() => $"{DateTime.Now: yyyy-MM-dd HH:mm:ss ddd}";
使用工具:
public static List<object> Tools { get; } = [
new GetDateTimeTool(),
];
await chat.SendAsync(message, Tools)
以上就是近期Ollama系列的回顧,感興趣的朋友可以關注我的公眾號 [拓荒者IT] 了解更多內容!
?? 持續分享AI工具,AI應用場景,AI學習資源 ??

 浙公網安備 33010602011771號
浙公網安備 33010602011771號