
一,#本機(jī)環(huán)境檢查
執(zhí)行nvidia-smi,查看右上角。驗(yàn)證顯卡驅(qū)動已安裝最高支持的版本。
nvidia-smi
#在調(diào)試時(shí),為了實(shí)時(shí)觀察GPU利用率,一般新開一個命令窗口,執(zhí)行以下命令,一秒刷新一次。
watch -n 1 nvidia-smi
執(zhí)行nvcc -V驗(yàn)證cuda
nvcc -V
執(zhí)行conda --version驗(yàn)證conda版本
conda --version
#列出所有已創(chuàng)建的Conda 環(huán)境??:
conda env list 或 conda info --envs
#若存在,先刪除已存在環(huán)境
conda env remove -n conda_qwen_image
#創(chuàng)建新環(huán)境
conda create -n conda_qwen_image python=3.10
#激活環(huán)境
conda activate conda_qwen_image
二,依賴庫安裝
根據(jù)CUDA版本安裝PyTorch??:
??CUDA 12.1??:
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
??CUDA 12.2??:
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu122
#驗(yàn)證PyTorch是否能正確識別GPU
python3 -c "import torch; print('PyTorch版本:', torch.__version__); print('CUDA可用:', torch.cuda.is_available()); print('CUDA版本:', torch.version.cuda); print('GPU設(shè)備:', torch.cuda.get_device_name(0) if torch.cuda.is_available() else 'None'); print('GPU數(shù)量:', torch.cuda.device_count());"
#魔搭modelscope庫安裝
pip3 install modelscope
#相關(guān)庫
pip3 install --upgrade transformers peft diffusers fastapi uvicorn
#新建man.py文件,加入代碼
運(yùn)行服務(wù)端API。 CUDA_VISIBLE_DEVICES 指定顯卡編號
CUDA_VISIBLE_DEVICES=0,1 python3 main.py
測試調(diào)用
curl -X POST http://localhost:8800/v1/images/generations -H "Content-Type: application/json" -d '{"prompt": "a lovely cat"}' | grep -q '"data"' && echo "API 工作正常" || echo "API 出現(xiàn)問題"
調(diào)用時(shí)控制臺截圖:
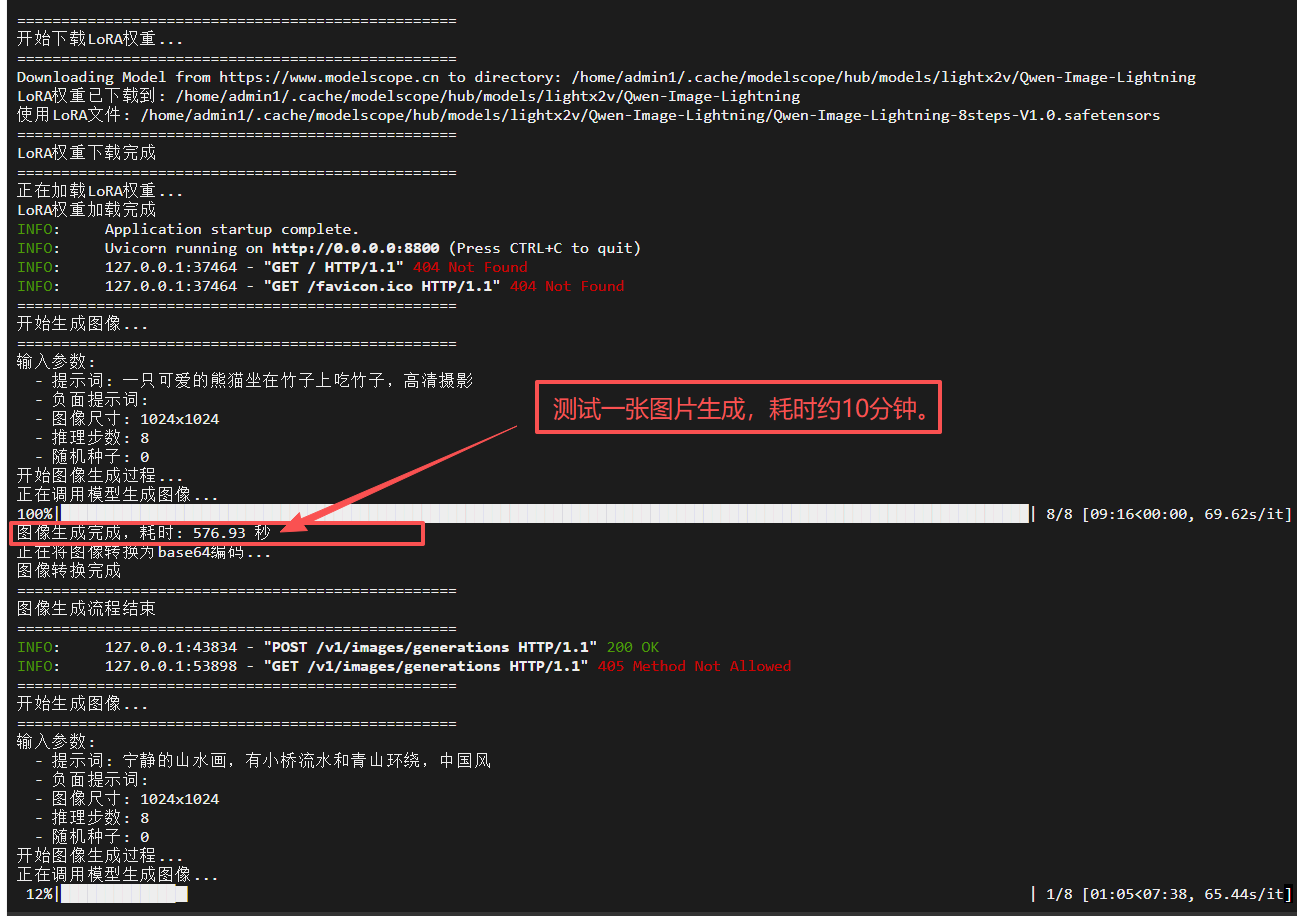
#安裝低代碼gradio庫
pip3 install gradio
#新建app.py 使用低代碼,創(chuàng)建文生圖用戶端。
import gradio as gr import requests import json import base64 from io import BytesIO from PIL import Image import traceback # 本地API配置 API_URL = "http://localhost:8800/v1/images/generations" # 示例提示詞 EXAMPLE_PROMPTS = [ "一只可愛的熊貓坐在竹子上吃竹子,高清攝影", "未來城市的夜景,有飛行汽車和霓虹燈,賽博朋克風(fēng)格", "寧靜的山水畫,有小橋流水和青山環(huán)繞,中國風(fēng)" ] def generate_image(prompt, negative_prompt="", width=1024, height=1024, steps=8, seed=0): """ 調(diào)用本地API生成圖片 Args: prompt (str): 正向提示詞 negative_prompt (str): 負(fù)向提示詞 width (int): 圖片寬度 height (int): 圖片高度 steps (int): 推理步數(shù) seed (int): 隨機(jī)種子 Returns: tuple: (生成的圖片, 狀態(tài)信息) """ if not prompt or prompt.strip() == "": return None, "請輸入提示詞" try: # 準(zhǔn)備請求數(shù)據(jù) payload = { "prompt": prompt, "negative_prompt": negative_prompt, "width": width, "height": height, "num_inference_steps": steps, "seed": seed } # 調(diào)用本地API print(f"正在調(diào)用本地API: {API_URL}") response = requests.post(API_URL, json=payload, timeout=1800) # 30分鐘超時(shí) if response.status_code == 200: result = response.json() # 解析返回的base64圖片數(shù)據(jù) if "data" in result and len(result["data"]) > 0: image_data = result["data"][0]["b64_json"] # 解碼base64圖片數(shù)據(jù) image_bytes = base64.b64decode(image_data) image = Image.open(BytesIO(image_bytes)) return image, "圖片生成成功" else: return None, "API返回?cái)?shù)據(jù)格式錯誤" else: return None, f"API調(diào)用失敗,狀態(tài)碼: {response.status_code},響應(yīng): {response.text}" except requests.exceptions.ConnectionError: return None, "連接API失敗,請確保本地API服務(wù)已啟動" except requests.exceptions.Timeout: return None, "API調(diào)用超時(shí),請稍后重試" except Exception as e: error_msg = f"生成圖片時(shí)出錯: {str(e)}" print(error_msg) traceback.print_exc() return None, error_msg # 創(chuàng)建Gradio界面 with gr.Blocks(title="文生圖應(yīng)用") as demo: gr.Markdown("# 文生圖應(yīng)用") gr.Markdown("輸入提示詞,調(diào)用本地API生成對應(yīng)的圖片") with gr.Row(): with gr.Column(): prompt_input = gr.Textbox( label="提示詞", placeholder="請輸入圖片描述...", lines=3 ) negative_prompt_input = gr.Textbox( label="負(fù)向提示詞", placeholder="請輸入不希望出現(xiàn)在圖片中的內(nèi)容(可選)...", lines=2 ) with gr.Accordion("高級參數(shù)", open=False): width_input = gr.Slider( minimum=256, maximum=2048, value=1024, step=64, label="圖片寬度" ) height_input = gr.Slider( minimum=256, maximum=2048, value=1024, step=64, label="圖片高度" ) steps_input = gr.Slider( minimum=1, maximum=50, value=8, step=1, label="推理步數(shù)" ) seed_input = gr.Number( label="隨機(jī)種子 (0表示隨機(jī))", value=0, precision=0 ) # 添加示例提示詞按鈕 gr.Markdown("### 示例提示詞") for i, example in enumerate(EXAMPLE_PROMPTS, 1): btn = gr.Button(f"示例 {i}: {example[:30]}..." if len(example) > 30 else f"示例 {i}: {example}") btn.click( fn=lambda ex=example: ex, outputs=prompt_input ) generate_btn = gr.Button("生成圖片", variant="primary") with gr.Column(): image_output = gr.Image(label="生成的圖片") status_output = gr.Textbox(label="狀態(tài)信息", max_lines=3) # 綁定生成按鈕事件 generate_btn.click( fn=generate_image, inputs=[ prompt_input, negative_prompt_input, width_input, height_input, steps_input, seed_input ], outputs=[image_output, status_output] ) if __name__ == "__main__": print("啟動文生圖Gradio界面...") print(f"請確保本地API服務(wù)已在 {API_URL} 啟動") demo.launch(server_name="0.0.0.0", server_port=7860, share=False)
#運(yùn)行應(yīng)用
python3 app.py
#使用效果圖

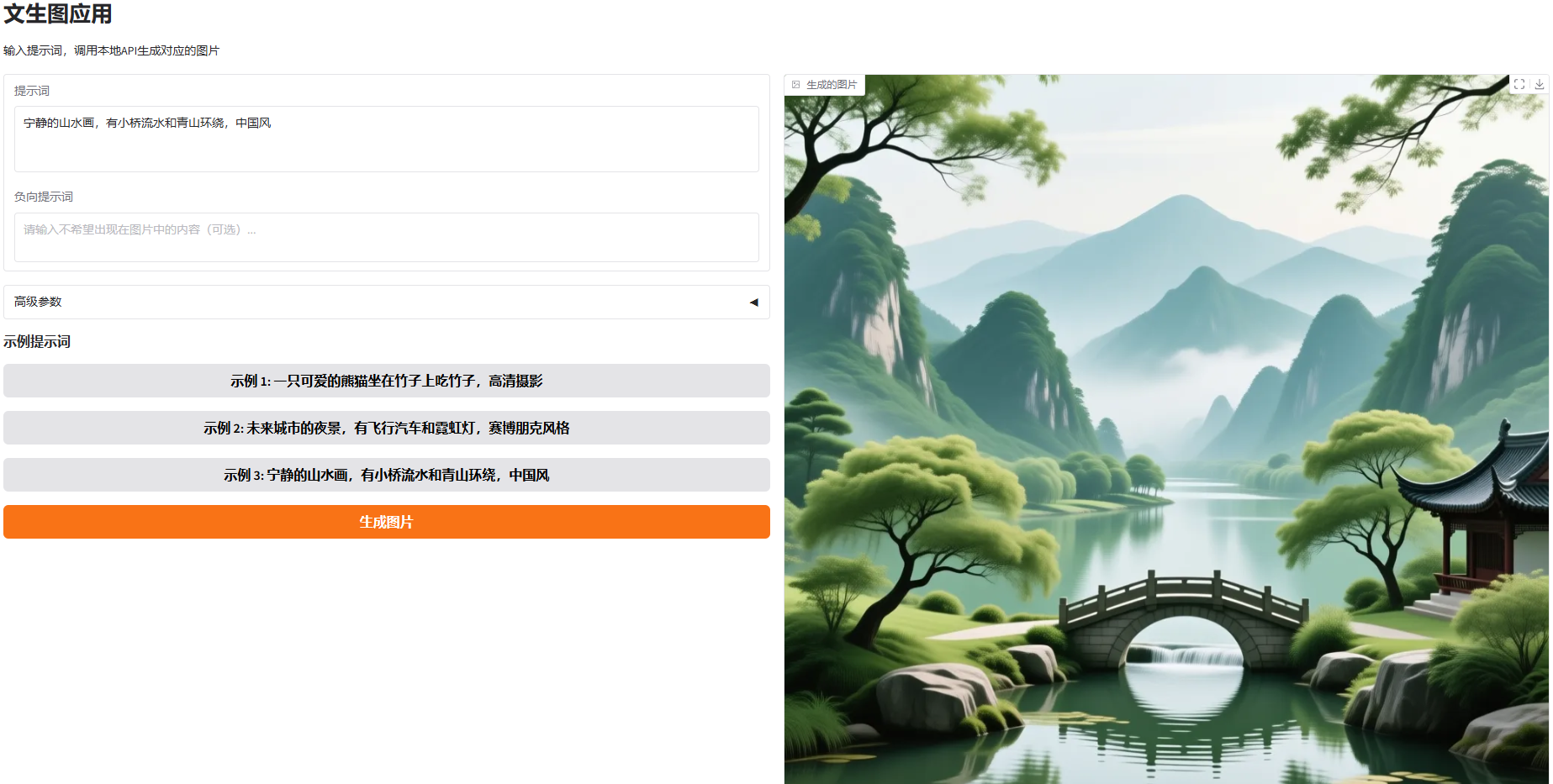



 浙公網(wǎng)安備 33010602011771號
浙公網(wǎng)安備 33010602011771號