
Pandas學(xué)習(xí)指南
基礎(chǔ)部分
Pandas簡(jiǎn)介
入門結(jié)合參考:http://www.rzrgm.cn/yigehulu/p/18081033
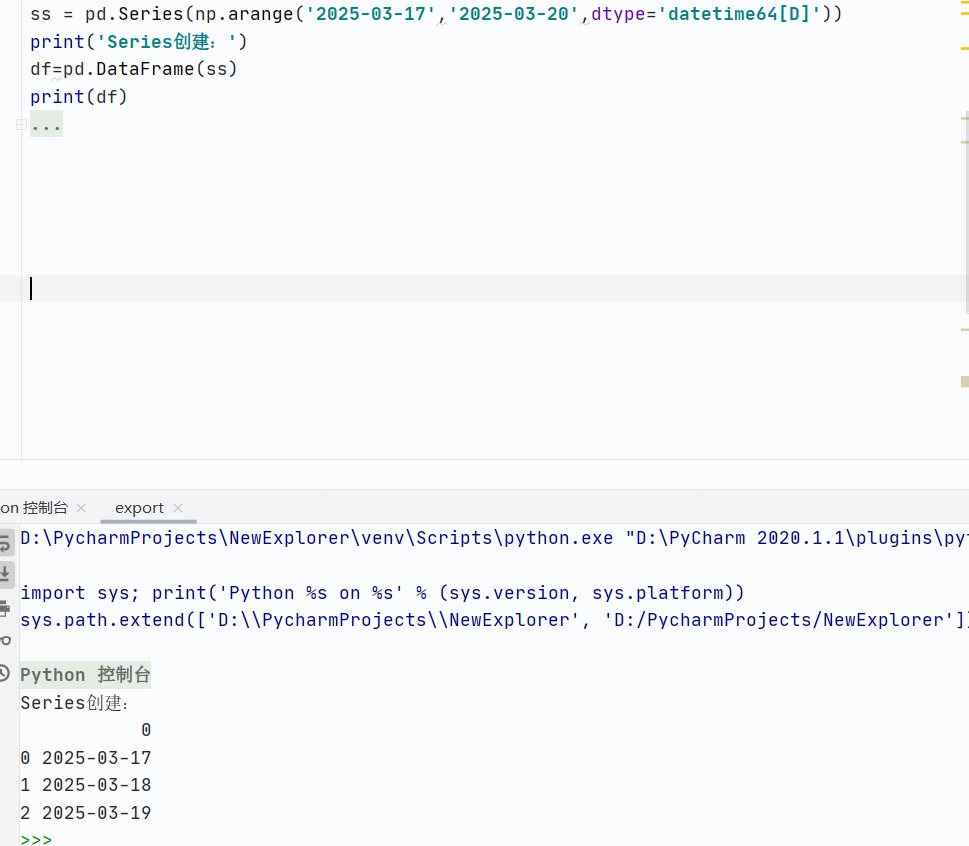
Series:一維帶標(biāo)簽的數(shù)組
創(chuàng)建Series
-
使用列表創(chuàng)建
![]()
-
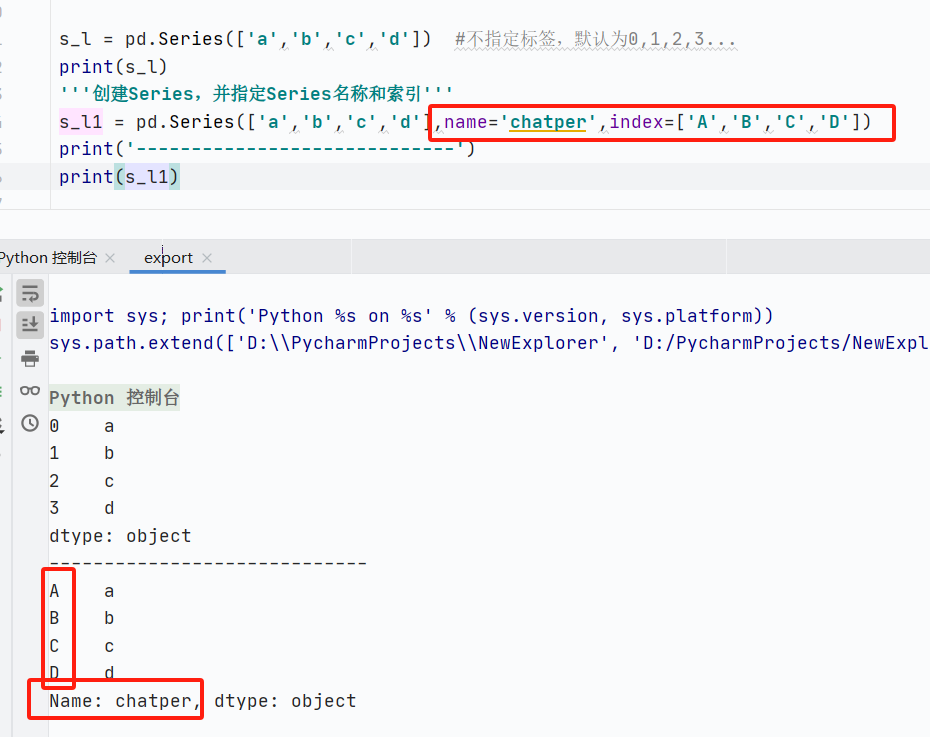
使用字典創(chuàng)建
![]()
-
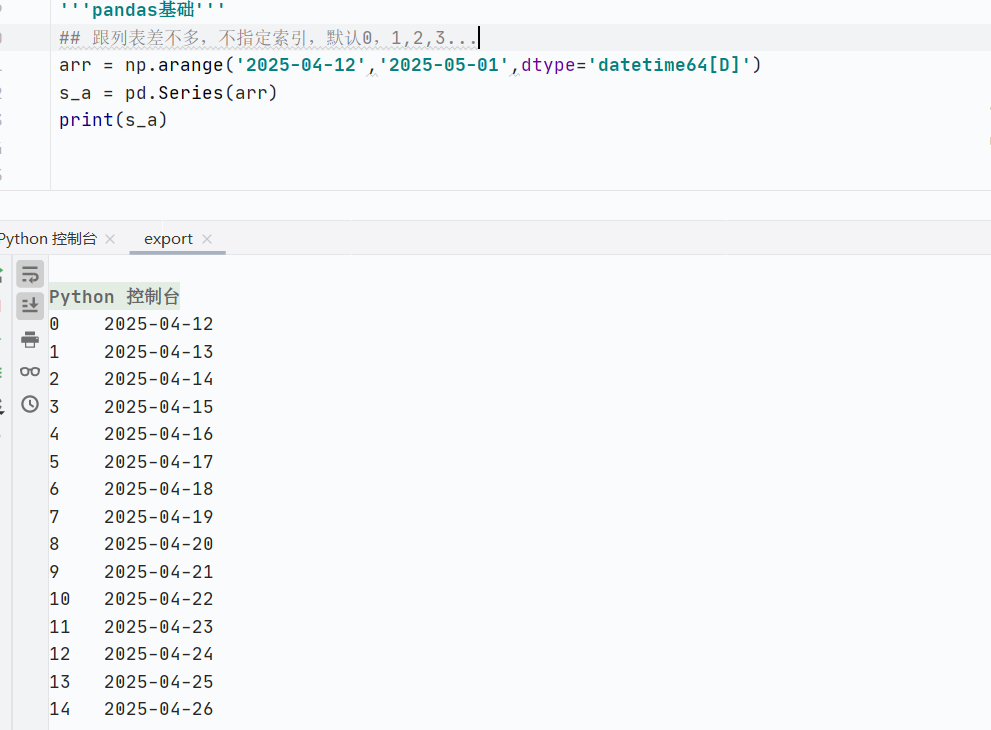
使用numpy創(chuàng)建
![]()
-
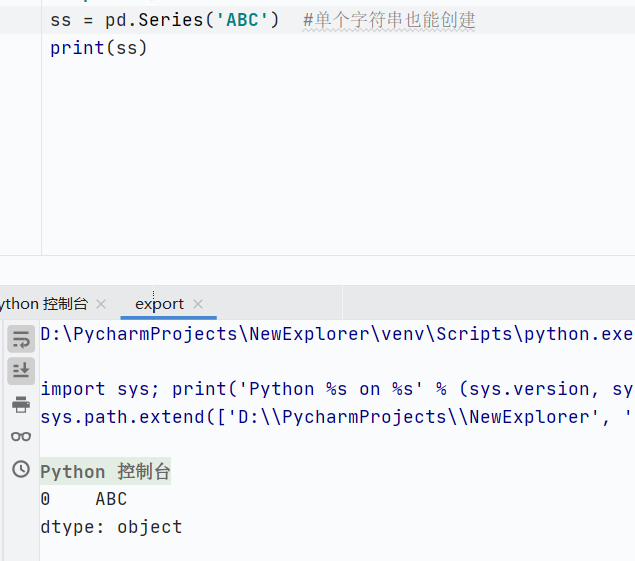
單個(gè)字符串也能創(chuàng)建
![]()
-
創(chuàng)建空Series
![]()
-
創(chuàng)建等值Series
![]()


基本操作
-
數(shù)據(jù)訪問(wèn)
-
通過(guò)位置索引
![]()
-
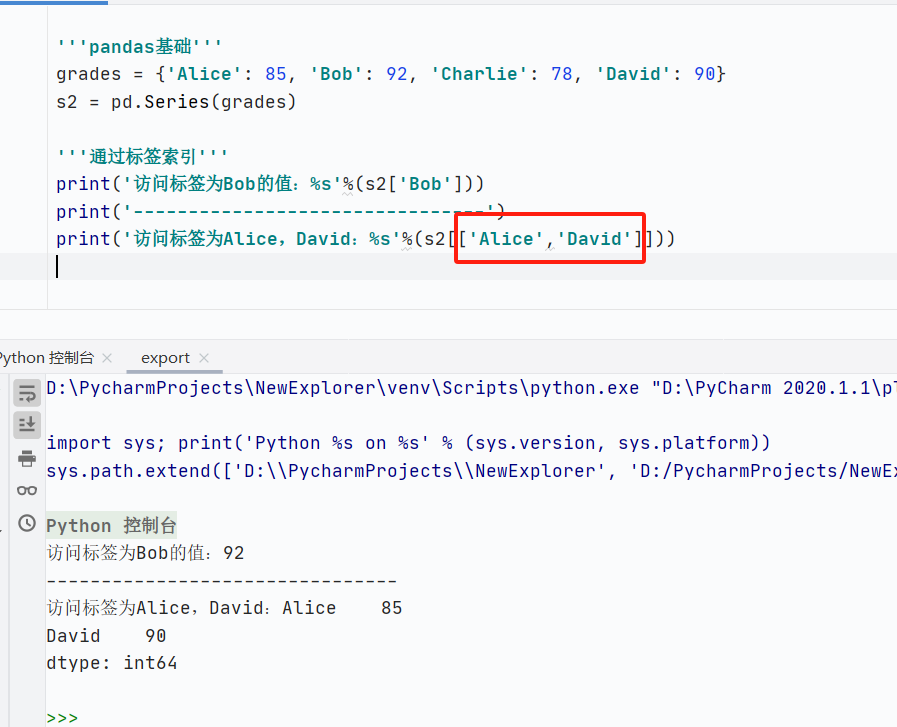
通過(guò)標(biāo)簽索引
![]()
-
-
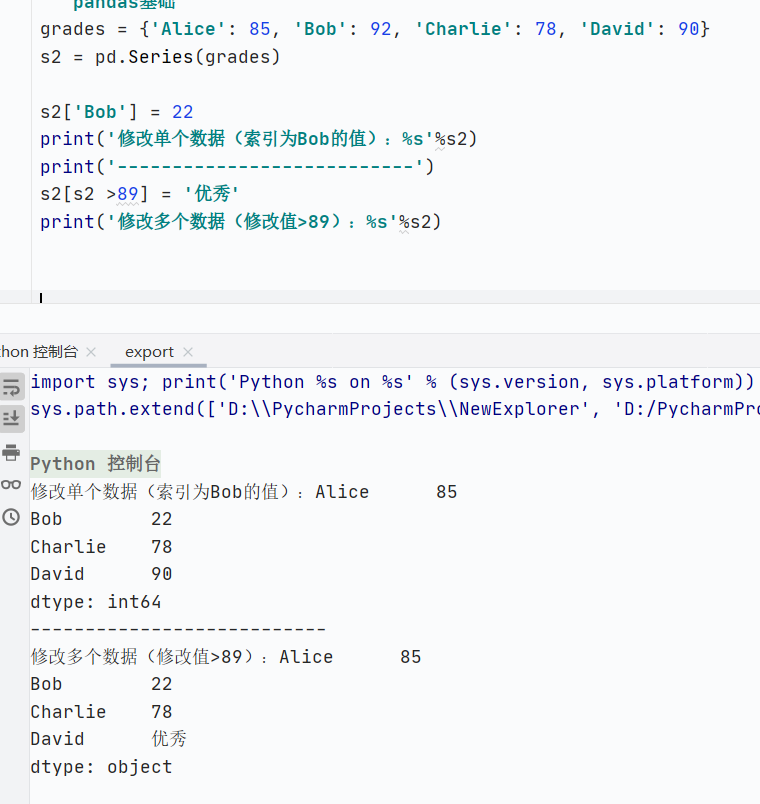
數(shù)據(jù)修改
![]()

索引切片
-
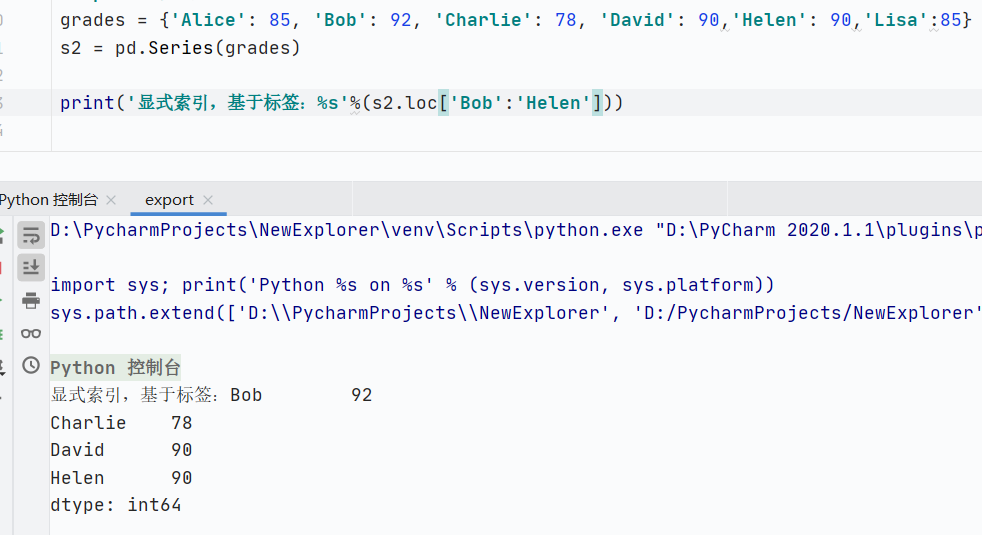
loc:顯式索引切片,基于標(biāo)簽
![]()
-
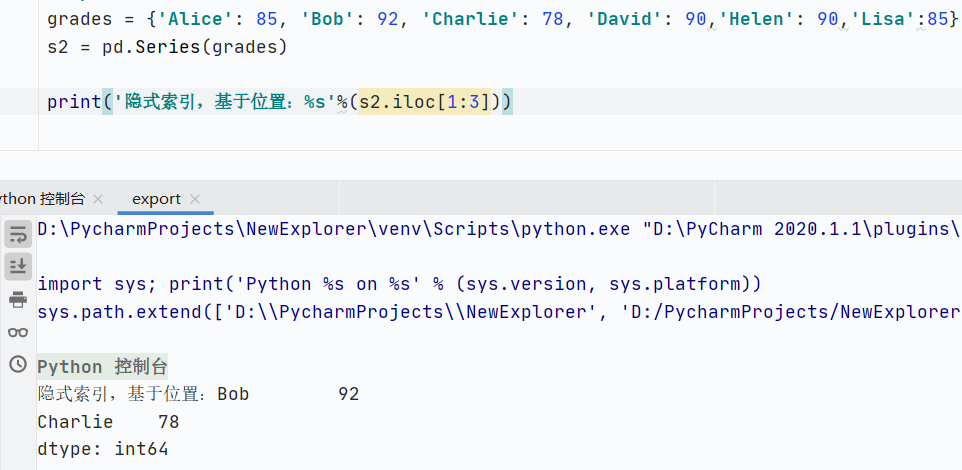
iloc:隱式索引切片,基于位置
![]()
-
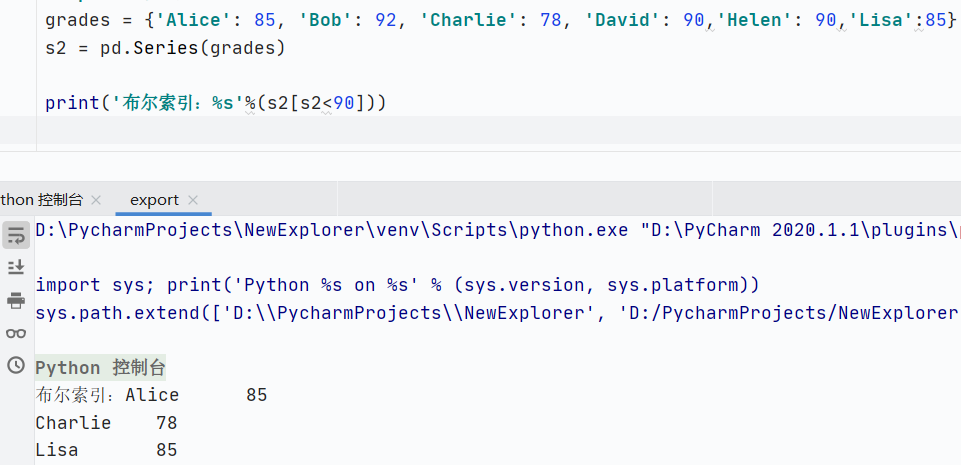
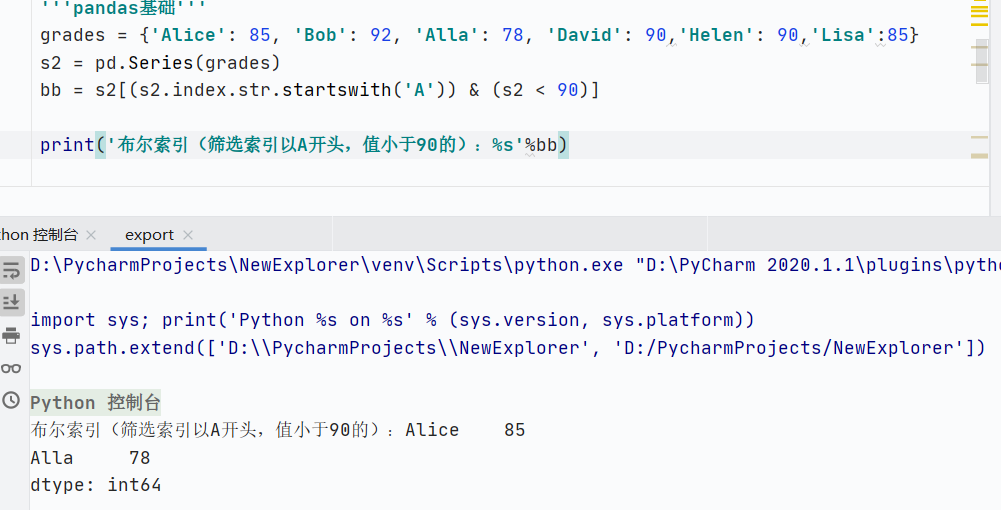
布爾索引切片
![]()
DataFrame:二維表格型數(shù)據(jù)結(jié)構(gòu)
創(chuàng)建DataFrame
-
使用列表創(chuàng)建
-
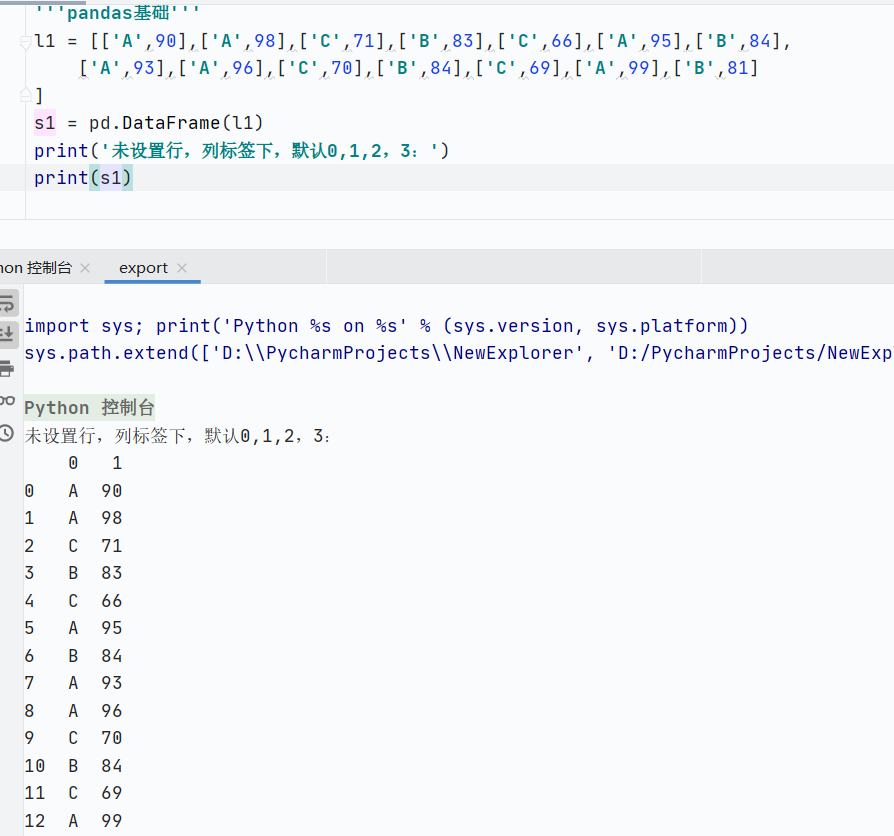
默認(rèn)不設(shè)置行列標(biāo)簽
![]()
-
設(shè)置列標(biāo)簽
![]()
-
-
使用數(shù)組創(chuàng)建
![]()
-
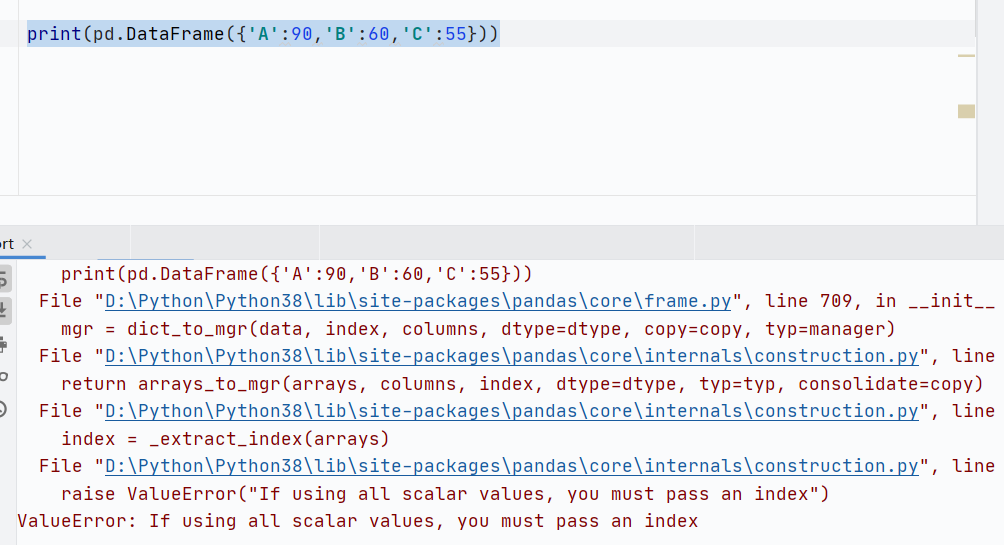
使用字典創(chuàng)建報(bào)錯(cuò)
![]()
- DataFrame通常由字典構(gòu)成,其中鍵是列名,值可以是列表、數(shù)組或Series
- 由字典創(chuàng)建時(shí),默認(rèn)key是columns,但是字典的value不可以是非標(biāo)量值
- 在 Pandas 中,標(biāo)量(Scalar) 指的是單個(gè)的、不可再分的值(如一個(gè)數(shù)字、字符串或布爾值),非標(biāo)量有長(zhǎng)度,Pandas會(huì)創(chuàng)建默認(rèn)列

列操作
-
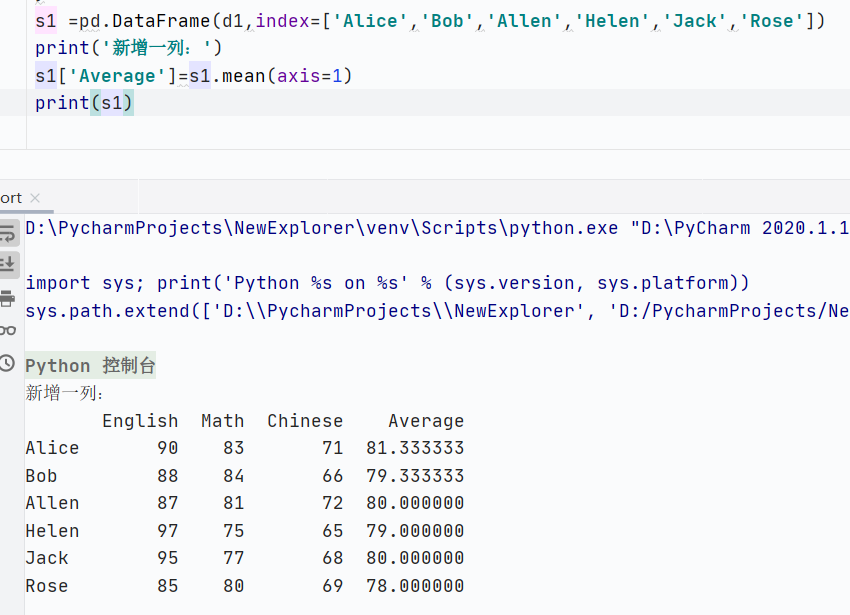
增
![]()
-
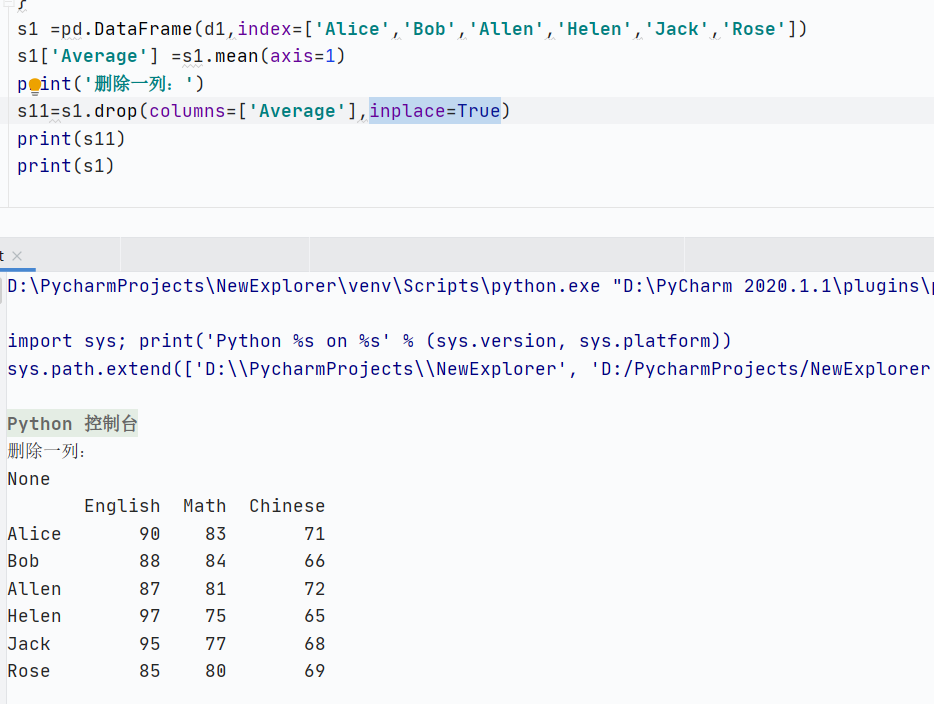
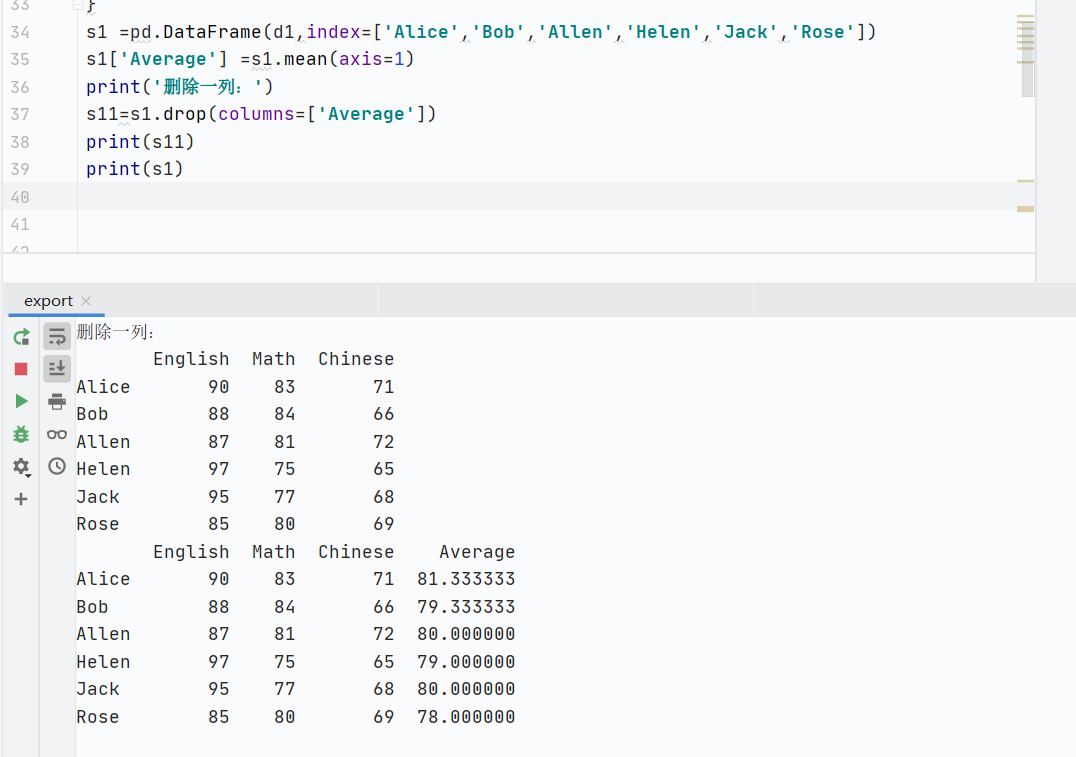
刪
-
inplace=True不返回新的DataFrame,直接修改原DataFrame
![]()
-
默認(rèn)False,返回修改后數(shù)組
![]()
-
-
改
默認(rèn)inplace=False
![]()
-
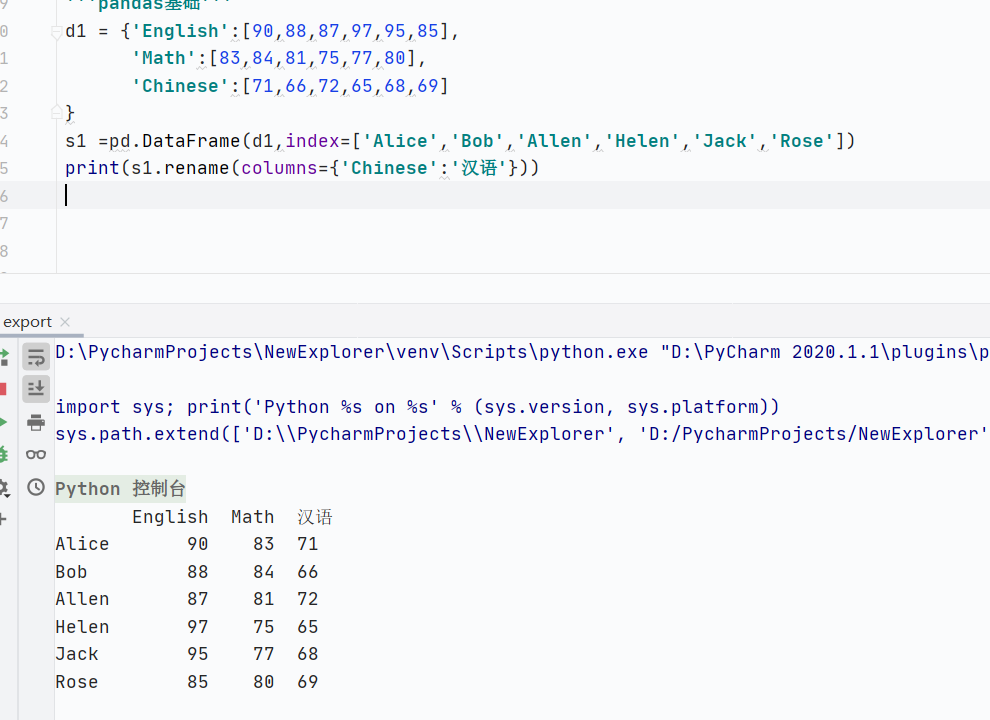
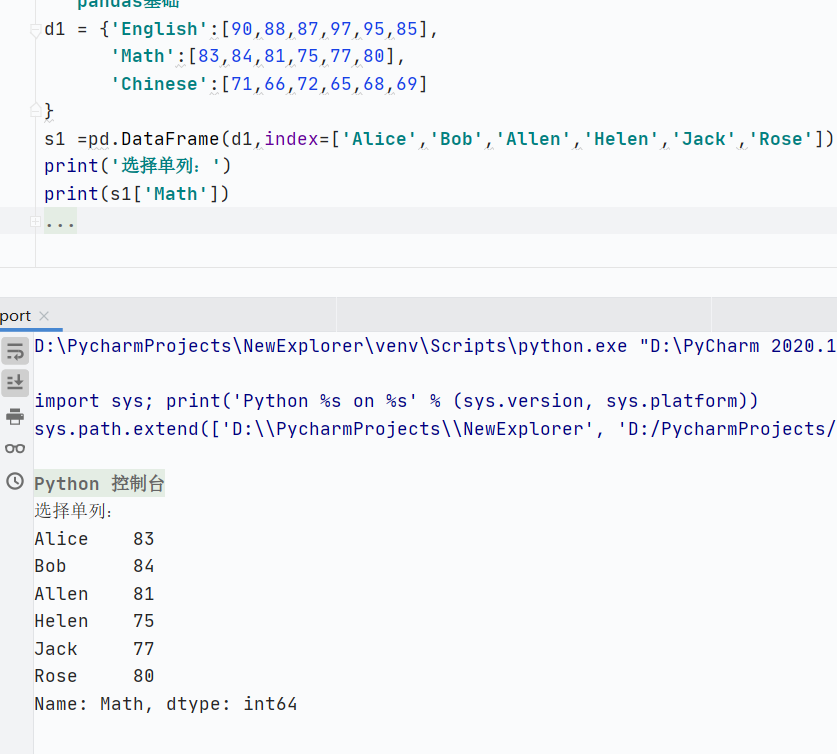
查
-
選擇單列,返回Series
![]()
-
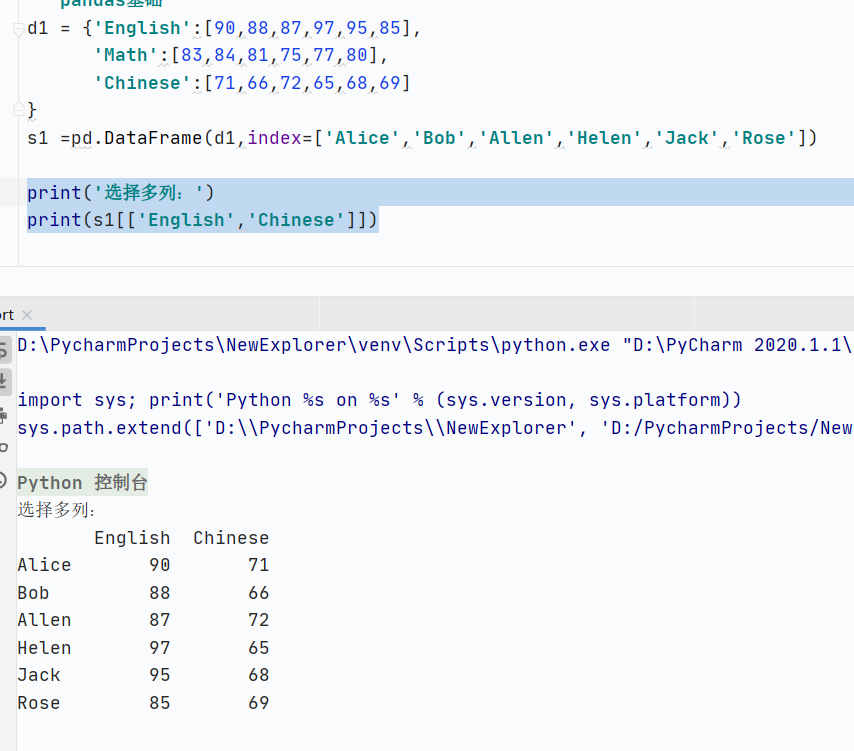
選擇多列
![]()
-
行操作
-
增
數(shù)組,字典,列表新增都沒(méi)有問(wèn)題
![]()
-
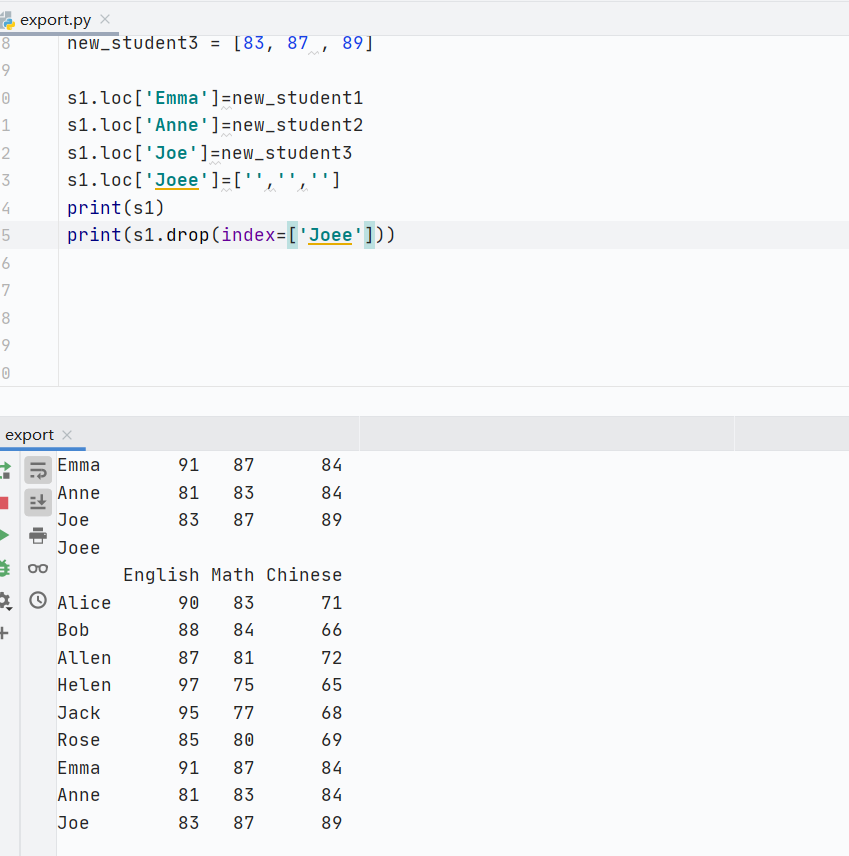
刪
![]()
-
改
![]()
-
查
-
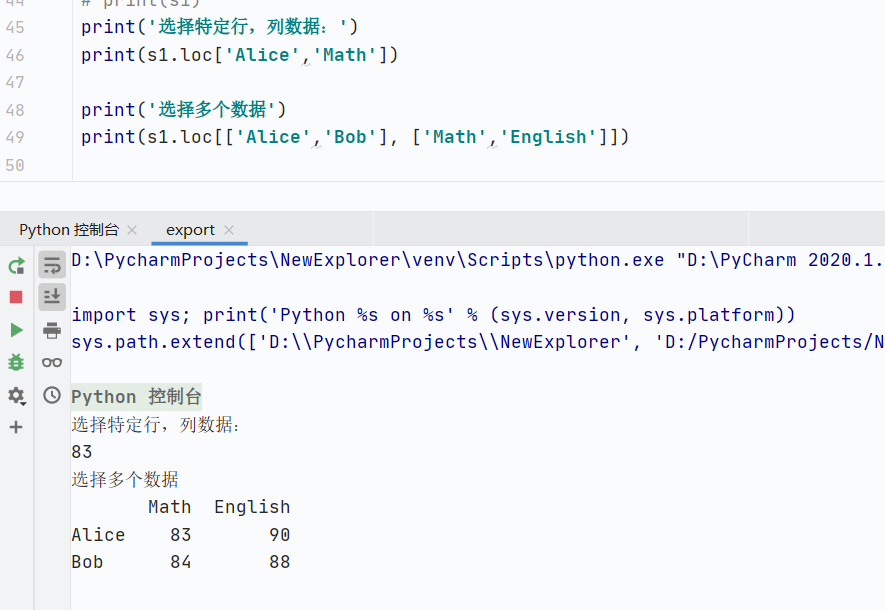
選擇單行,返回Series
![]()
-
選擇多行
![]()
-



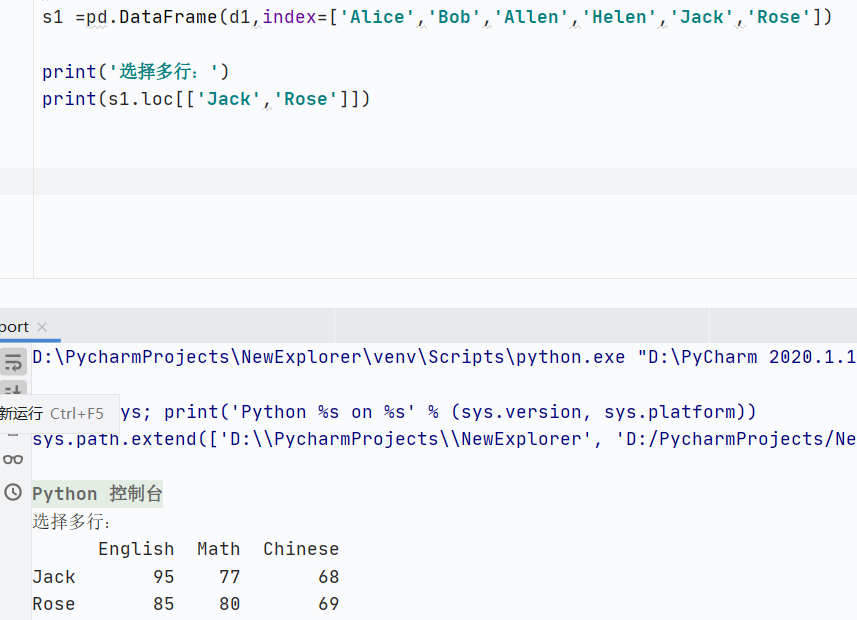
索引篩選
-
條件篩選
![]()
-
標(biāo)簽索引
![]()
-
位置索引
![]()
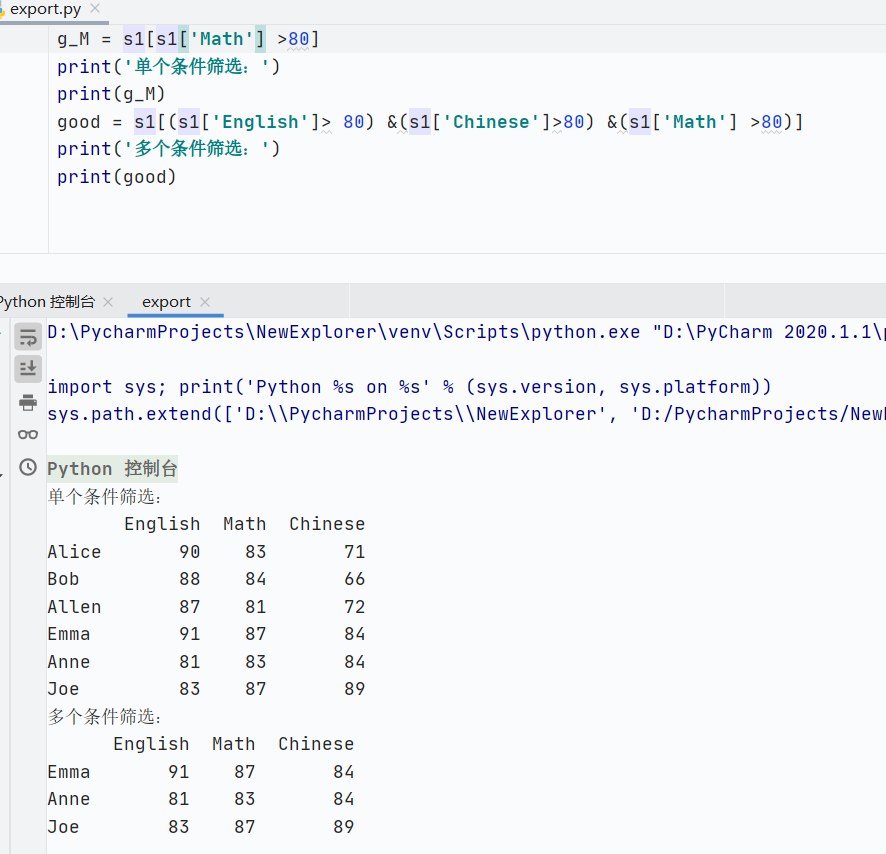

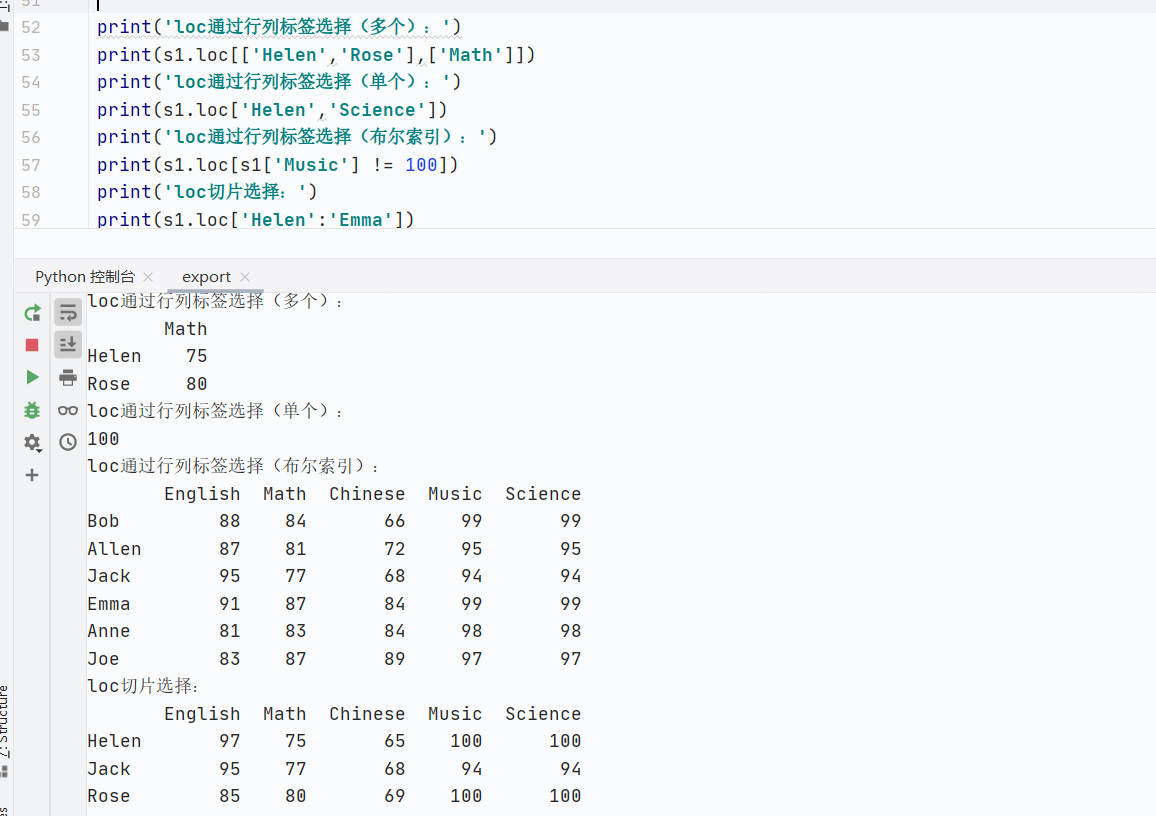
索引主要函數(shù)歸納
loc
-
索引類型:通過(guò)行標(biāo)簽和列標(biāo)簽選擇數(shù)據(jù)
-
切片行為:包含結(jié)束位置
-
支持操作:?jiǎn)沃担嘀担紶査饕瑮l件篩選
-
適用場(chǎng)景:已知行/列的精準(zhǔn)定位
![]()
iloc
-
索引類型:通過(guò)行位置和列位置選擇數(shù)據(jù)(從0開(kāi)始)
-
切片行為:左閉又開(kāi)(不包含結(jié)束位置)
-
支持操作:?jiǎn)沃担嘀担C書列表,布爾掩碼(需轉(zhuǎn)換為整數(shù))
-
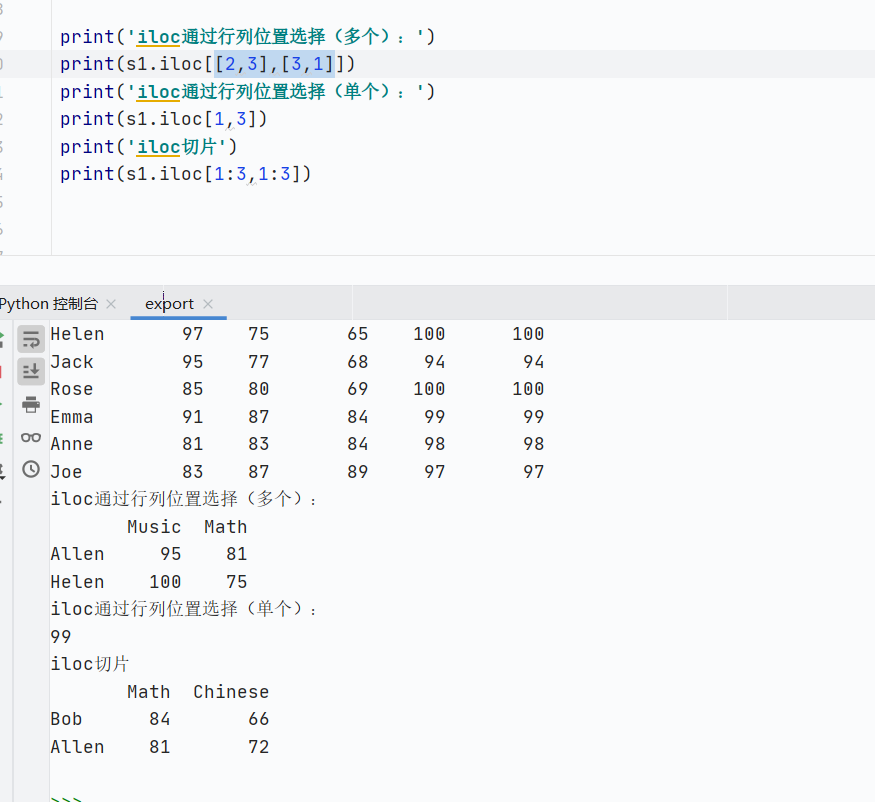
適用場(chǎng)景:按固定位置選擇數(shù)據(jù)(無(wú)需關(guān)心標(biāo)簽)
![]()
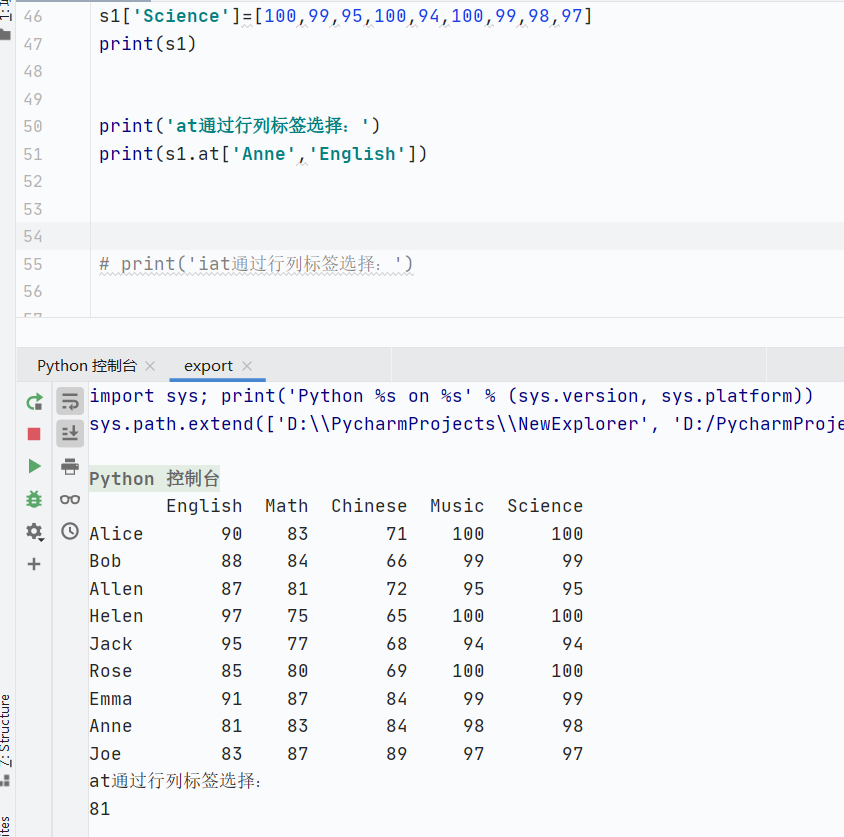
at
-
索引類型:通過(guò)行標(biāo)簽和列標(biāo)簽選擇單個(gè)數(shù)據(jù)
-
僅限單個(gè)元素,比
loc更快![]()
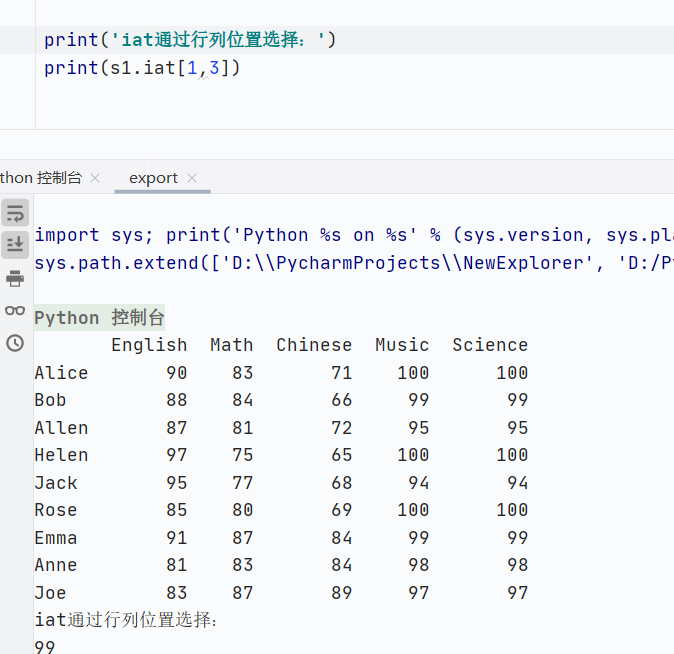
iat
-
索引類型:通過(guò)行位置和列位置選擇單個(gè)數(shù)據(jù)
-
僅限單個(gè)元素,比
iloc更快![]()
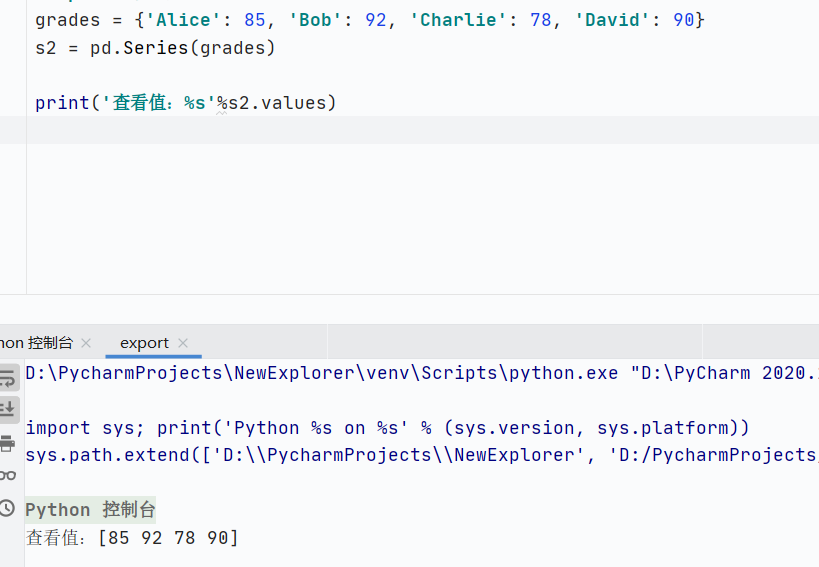
常用屬性函數(shù)歸納
values:查看值
index:查看索引

describe():統(tǒng)計(jì)摘要
詳細(xì)參數(shù):
- include:指定需要包含的數(shù)據(jù)類型;include='all':包含所有列(包括非數(shù)值列,如字符串、分類、布爾值等)
- exclude:指定需要排除的數(shù)據(jù)類型
include 和 exclude 不能同時(shí)使用,否則會(huì)報(bào)錯(cuò)
支持所有 Pandas 數(shù)據(jù)類型,例如:np.number(所有數(shù)值類型),'category'(分類數(shù)據(jù)),'datetime'(日期時(shí)間),'object'(字符串或混合類型)
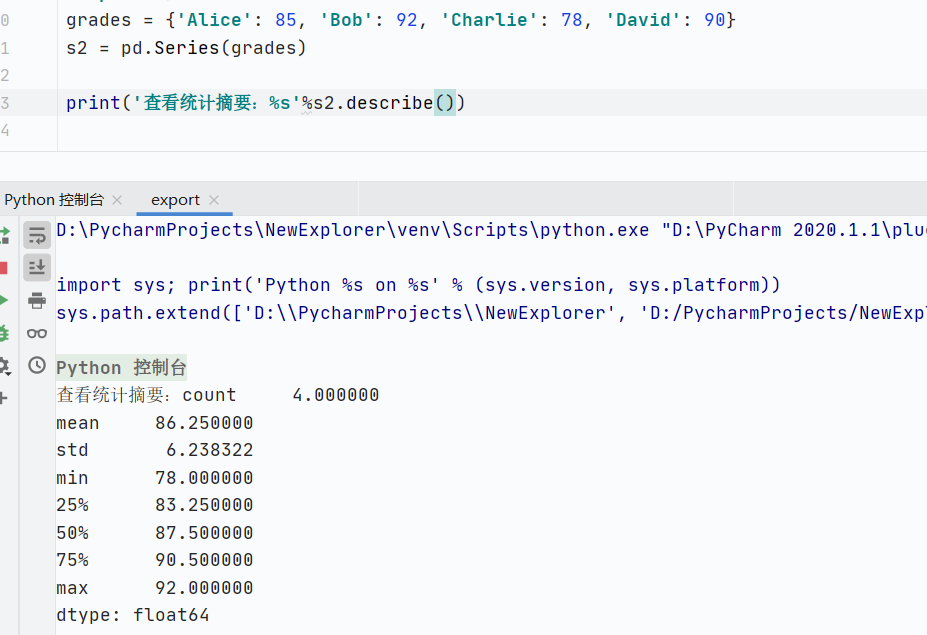
數(shù)值型
顯示如下:
- count:數(shù)據(jù)總數(shù)(非空值數(shù)量)
- mean:平均值
- std:標(biāo)準(zhǔn)差(反應(yīng)數(shù)據(jù)離散程度)
- min:最小值
- 25%:第一四分位數(shù)
- 50%:中位數(shù)
- 75%:第三四分位數(shù)
- max:最大值
![]()
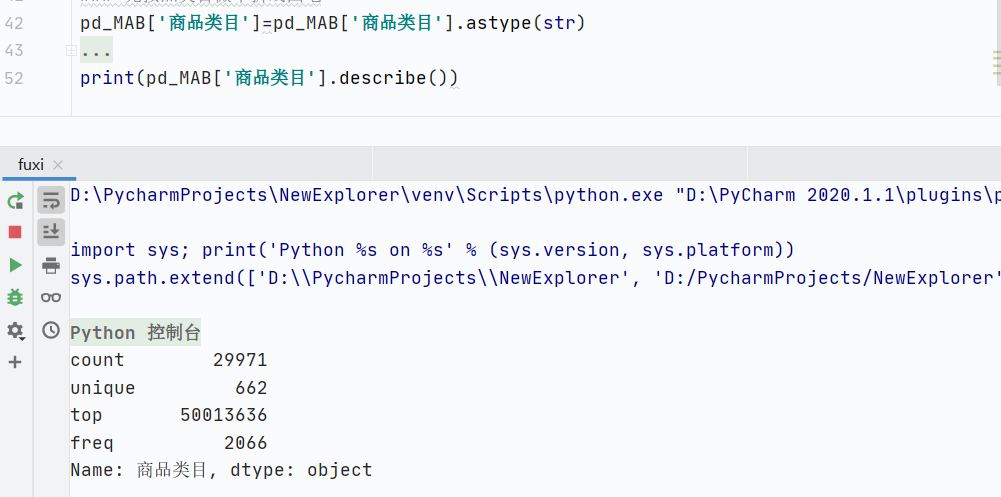
字符串型(或混合型)
- count:數(shù)據(jù)總數(shù)(非空值數(shù)量)
- unique:去重后數(shù)值數(shù)量
- top:出現(xiàn)頻率最高的值(眾數(shù))
- freq:眾數(shù)(top)出現(xiàn)的次數(shù)
![image]()
head():查看前n行數(shù)據(jù)

unique():唯一值數(shù)組

中級(jí)部分
數(shù)據(jù)清洗
處理缺失值
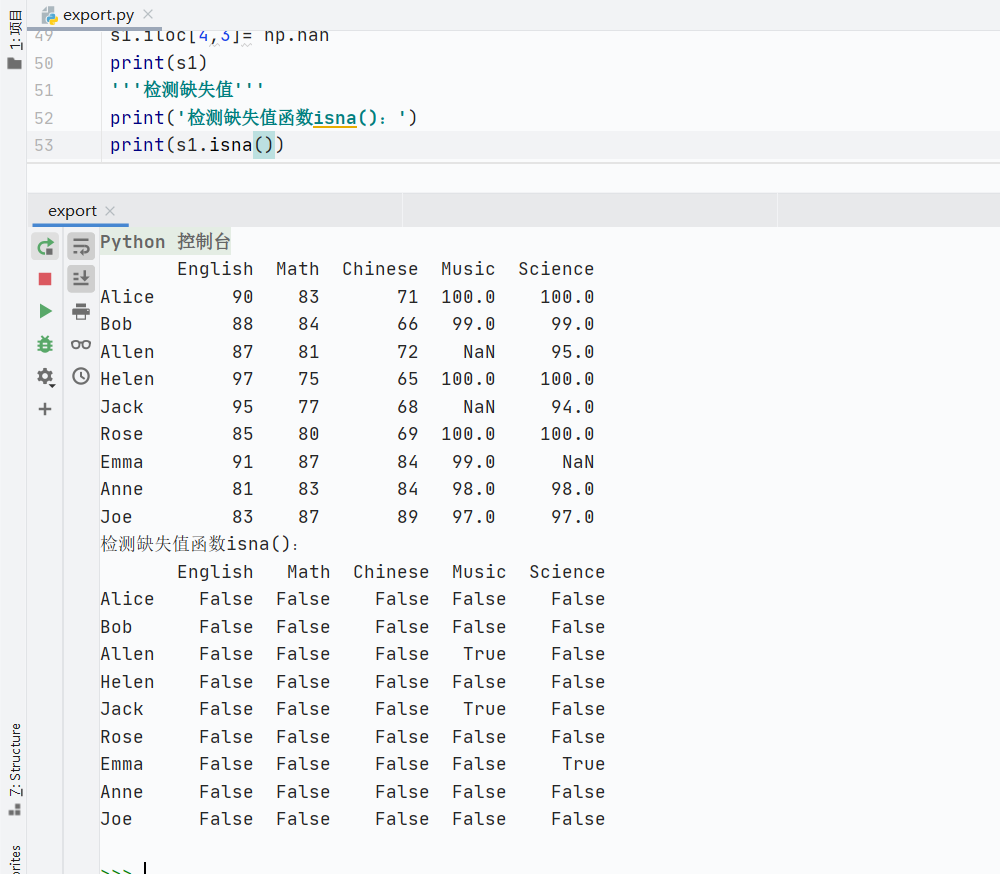
檢測(cè)缺失值
- isna():檢測(cè)缺失值
![]()
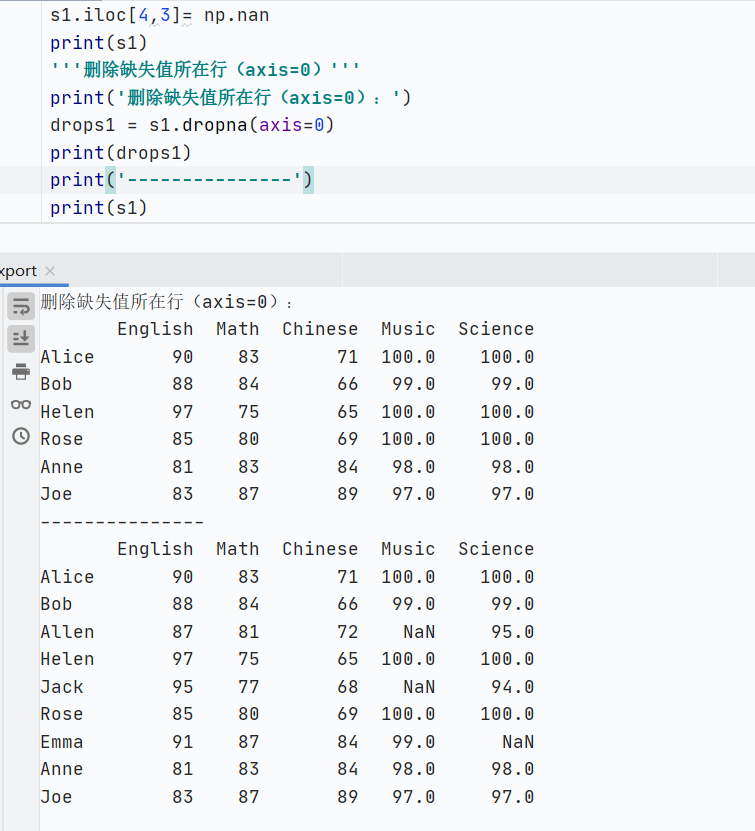
刪除缺失值
- dropna():刪除含有缺失值的行(axis=0)返回修改后的DataFrame
![]()
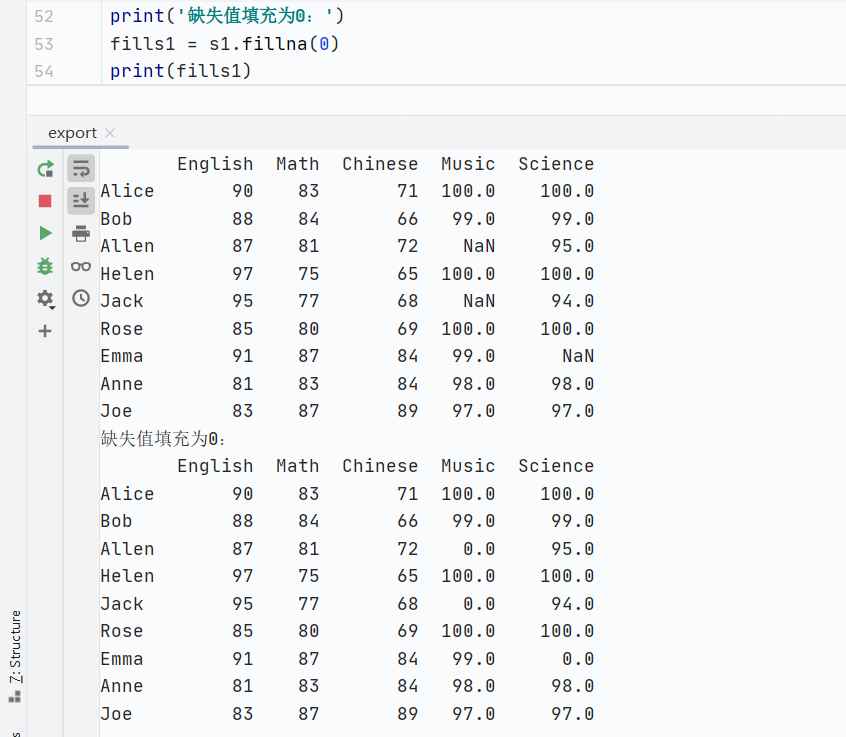
填充缺失值
-
固定值填充
![]()
-
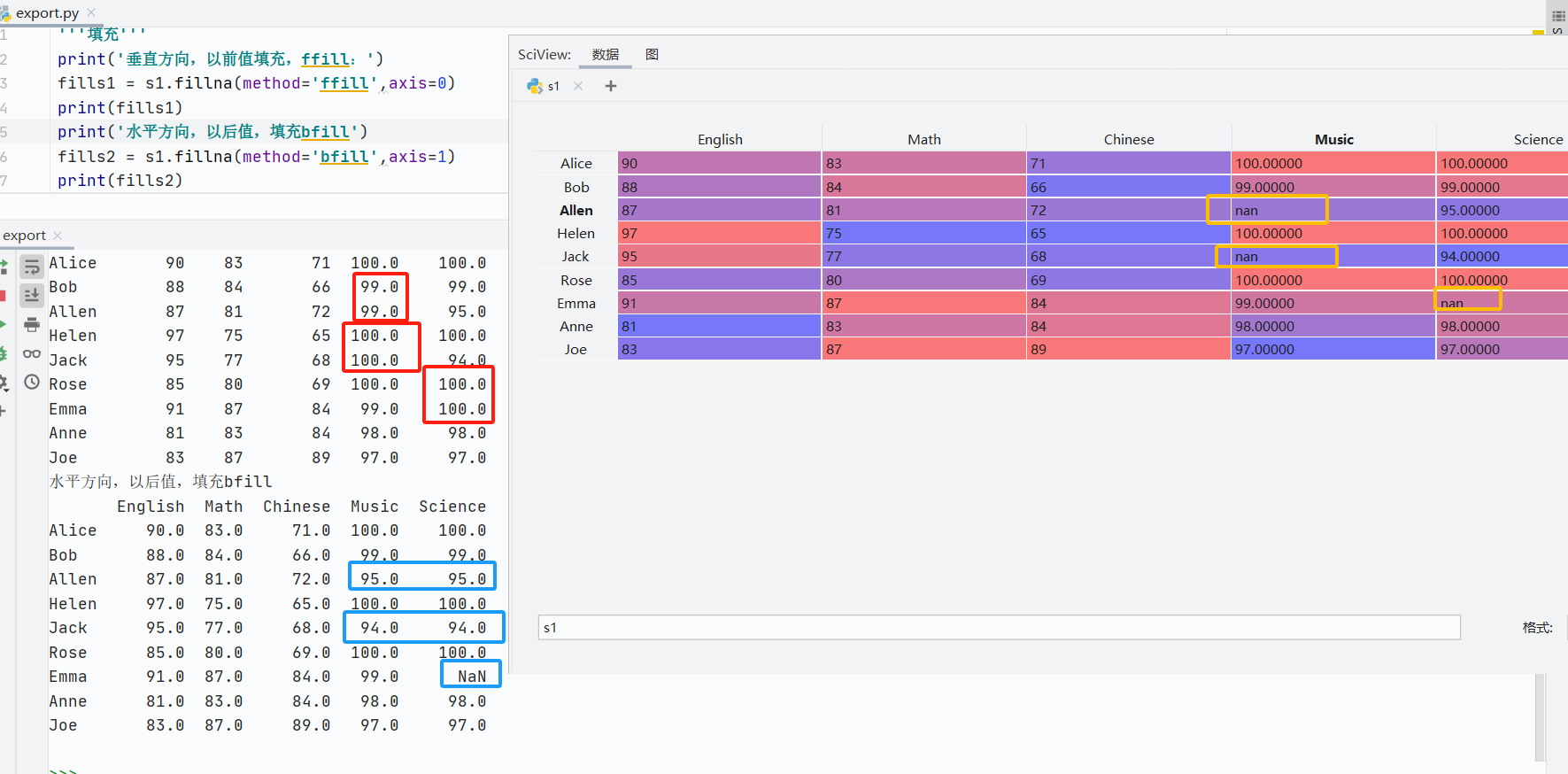
前后填充
![]()
數(shù)據(jù)轉(zhuǎn)換
-
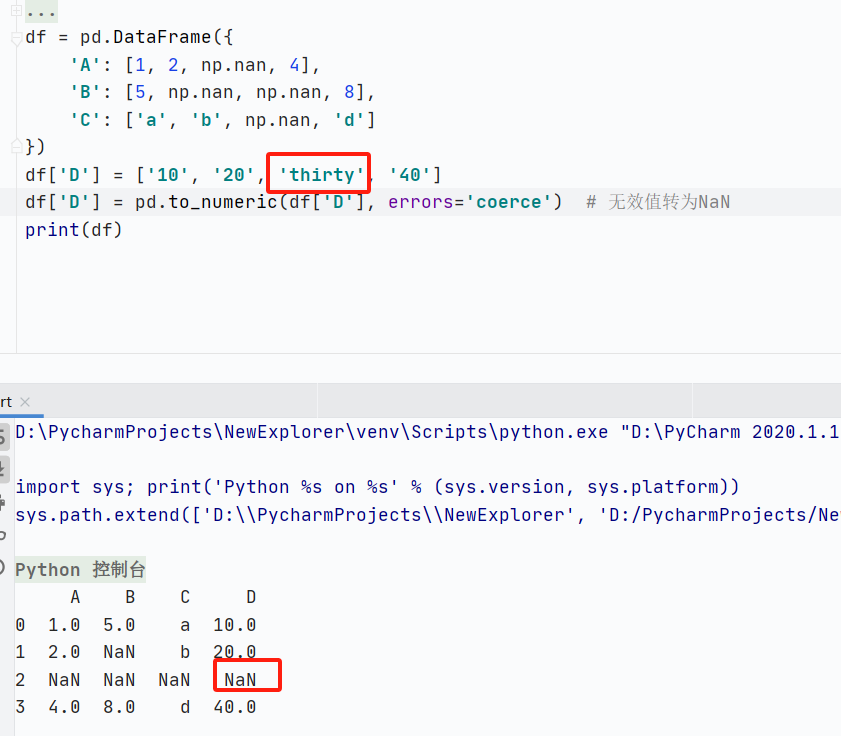
pd.to_numeric():將參數(shù)轉(zhuǎn)換為數(shù)值類型(例如整數(shù)或浮點(diǎn)數(shù))
核心參數(shù):-
arg:待轉(zhuǎn)換的數(shù)據(jù)(一維結(jié)構(gòu)),如 Series、列表、元組或數(shù)組
-
errors:錯(cuò)誤處理策略,'raise'(拋錯(cuò)) 'coerce'(無(wú)效值轉(zhuǎn)換成NaN)or 'ignore'(忽略)
-
downcast:數(shù)值類型降級(jí):'integer'(最小整數(shù)類型,有符號(hào)和無(wú)符號(hào)) or 'signed(最小的有符號(hào)整數(shù)類型,如:正數(shù),負(fù)數(shù)和0) or 'unsigned'(最小的無(wú)符號(hào)整數(shù)類型,如:uint8, uint16, uint32, uint64) or 'float'(最小浮點(diǎn)類型)
![]()
-
-
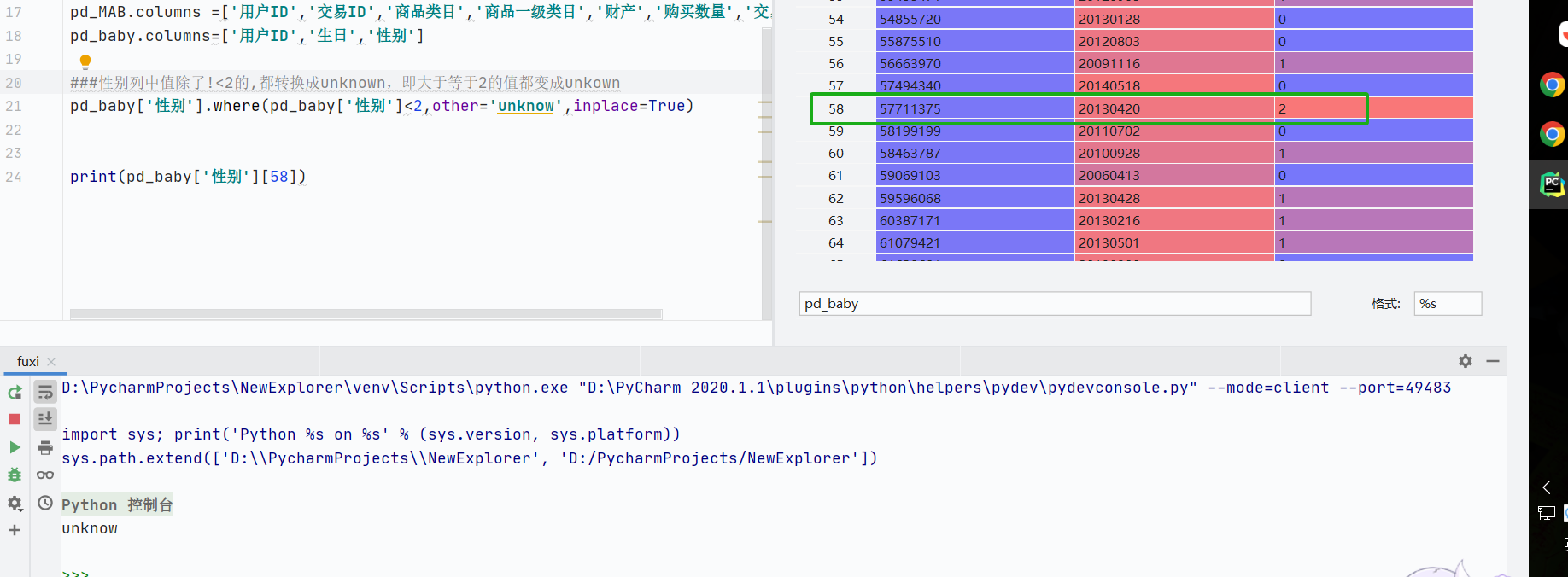
where():用于根據(jù)條件替換值
核心參數(shù):-
cond:布爾條件(DataFrame/Series/可調(diào)用對(duì)象),True的位置保留原值
-
other:替換值(標(biāo)量/Series/DataFrame/函數(shù)),False的位置替換為此值(默認(rèn)NaN)
-
inplace:是否原地修改(默認(rèn)False,返回新對(duì)象)
-
axis:對(duì)齊軸(用于索引對(duì)齊)
![image]()
-
重復(fù)數(shù)據(jù)處理
檢測(cè)重復(fù)行
-
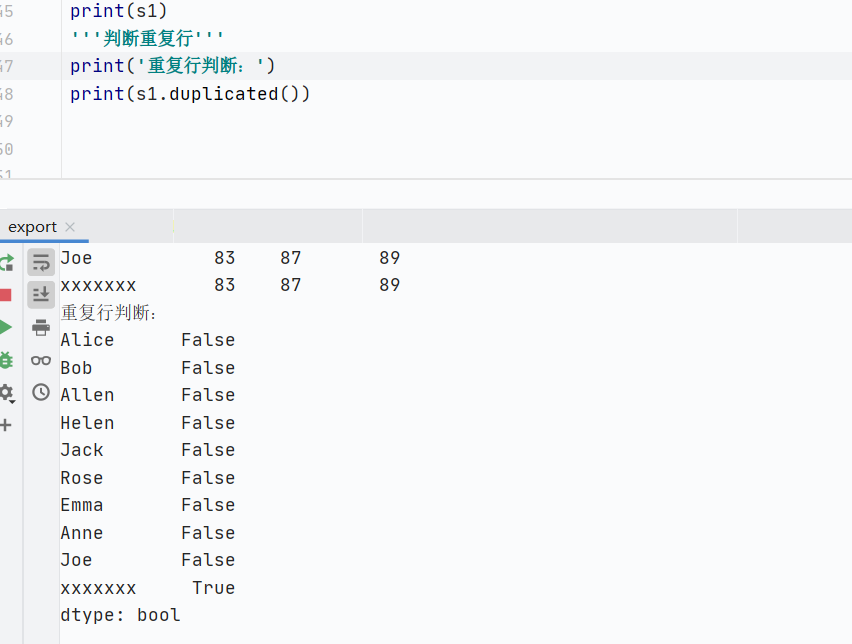
判斷重復(fù)行
![]()
-
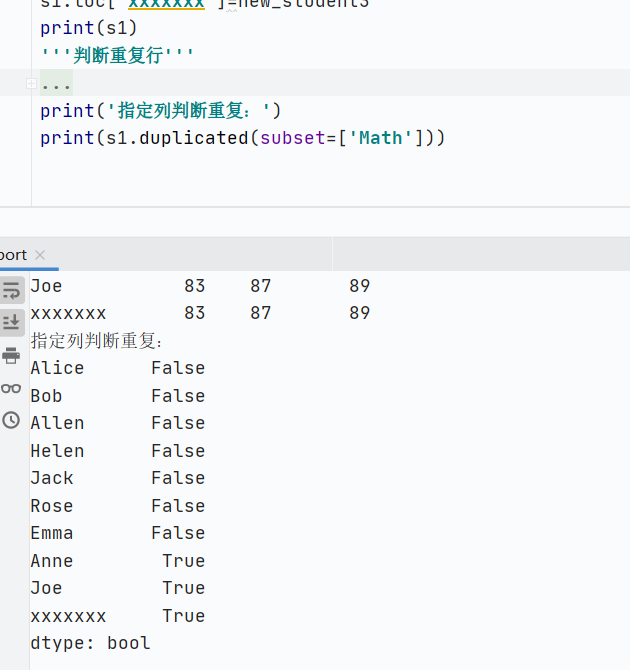
指定列判斷重復(fù)
![]()
刪除重復(fù)行

字符串操作
DataFrame的字符串拼接,大小寫轉(zhuǎn)換,替換與字符串的函數(shù)基本一致
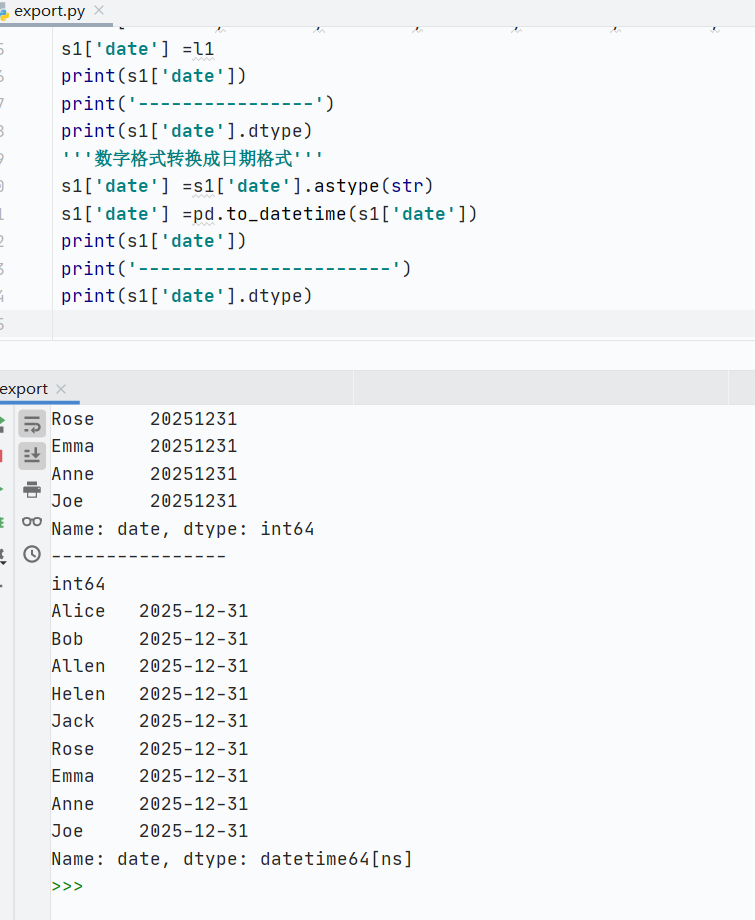
pd.to_datetime():時(shí)間序列處理
數(shù)字類型轉(zhuǎn)換成日期類型,數(shù)字類型如果不想被當(dāng)做時(shí)間戳轉(zhuǎn)換,就得先轉(zhuǎn)換成字符串類型,在轉(zhuǎn)成日期類型
核心參數(shù):
-
arg:字符串、日期時(shí)間對(duì)象、列表、元組、一維數(shù)組、Series、DataFrame
-
erros:錯(cuò)誤處理,raise(默認(rèn),拋錯(cuò)),coerce(無(wú)效值轉(zhuǎn)換成NaT),ignore(忽略)
-
dayfirst:當(dāng)日期模糊時(shí),(如01/01/2025),優(yōu)先解析為日/月格式
-
yearfirst:優(yōu)先解析為年/月/日,默認(rèn)為False,當(dāng)yearfirst=True時(shí),優(yōu)先級(jí)高于dayfirst
-
format:格式化字符串;用來(lái)指定輸入字符串的格式,而不是目標(biāo)格式
![]()
數(shù)據(jù)分組
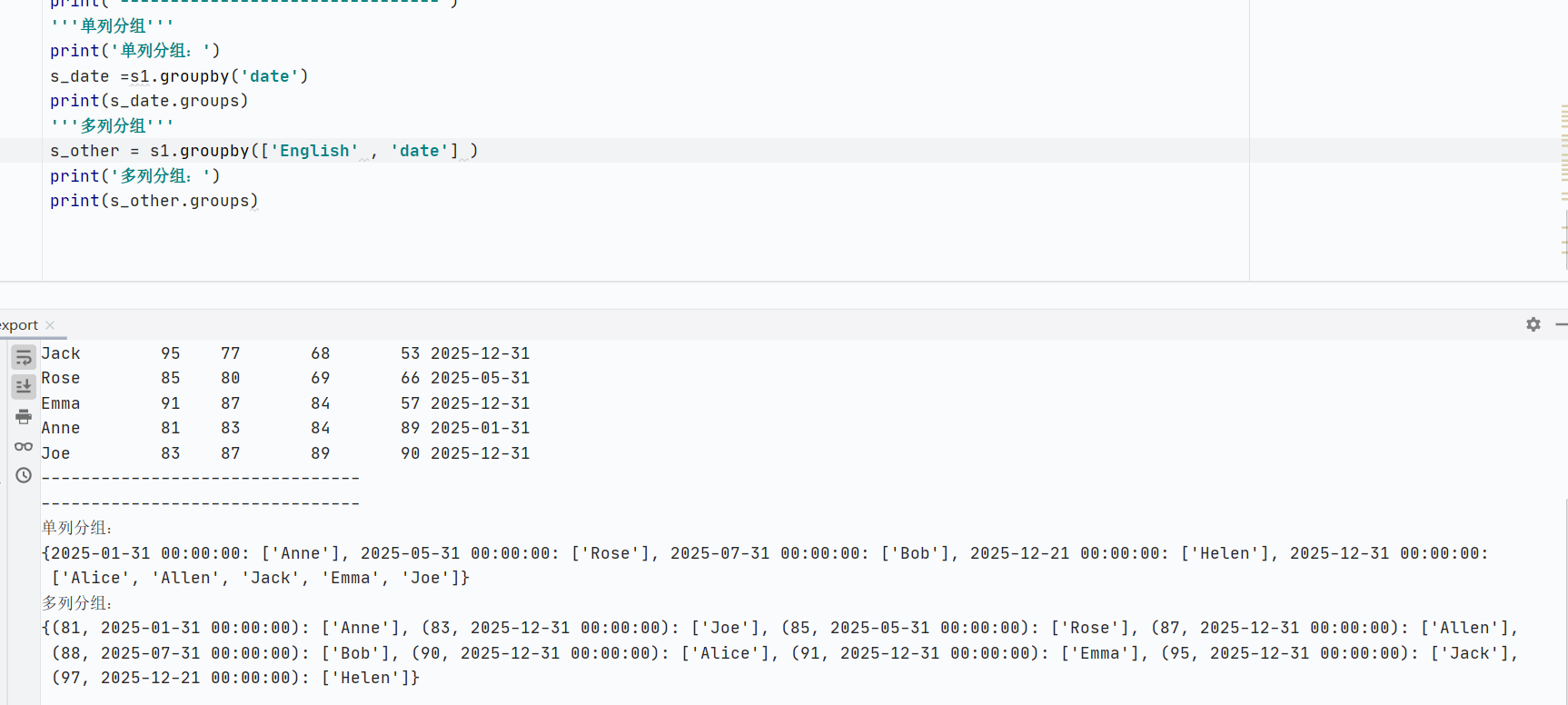
groupby():分組操作
-
分組
![]()
-
查詢
![]()

pd.cut():數(shù)據(jù)分箱(離散化)
將連續(xù)型數(shù)值數(shù)據(jù)分割為離散的區(qū)間(分箱),常用于數(shù)據(jù)分組或轉(zhuǎn)換。
核心參數(shù):
-
x:要分箱的一維數(shù)組或者Series
-
bins:定義分箱的邊界,整數(shù):自動(dòng)生成n個(gè)等寬區(qū)間,列表:自定義邊界
-
labels:為每個(gè)區(qū)間指定標(biāo)簽,標(biāo)簽列表長(zhǎng)度必須比bins少1
-
right:是否包含右邊界,默認(rèn)為True,即左開(kāi)右閉
-
precision:區(qū)間邊界的小數(shù)位精度
-
include_lowest:是否包含最小值,默認(rèn)False,第一個(gè)區(qū)間左開(kāi)右閉時(shí)可能要設(shè)為True
![]()
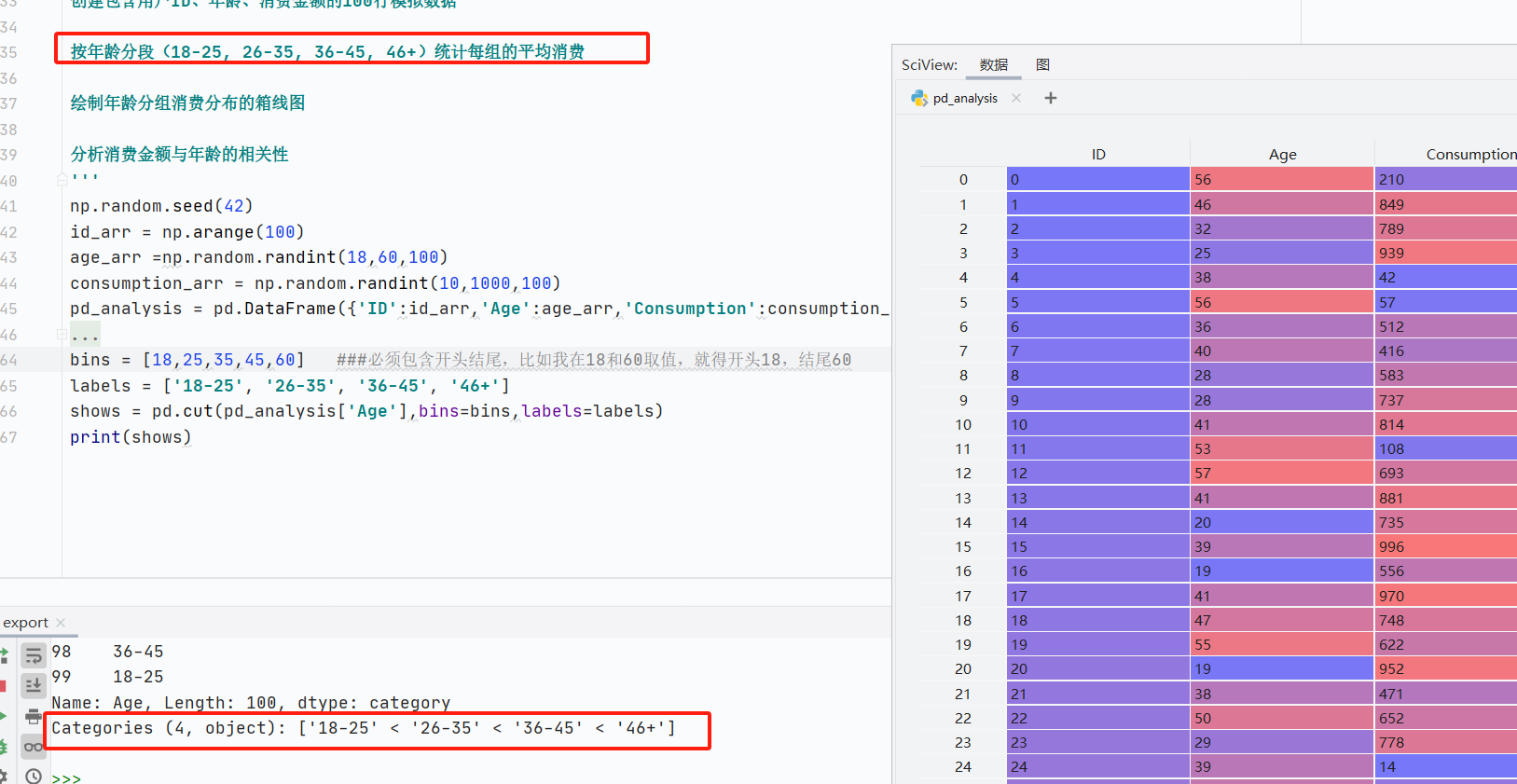
pd.qcut()按等頻分位數(shù)分箱,保證每箱數(shù)據(jù)量均衡
比較
-
相同點(diǎn)
- 兩者都用于將數(shù)據(jù)按照某種規(guī)則分成不同組別,便于后續(xù)分析或聚合操作
- pd.cut()生成的離散分組結(jié)果,常作為groupby的分組鍵值,組合使用
![]()
-
不同點(diǎn)
![]()
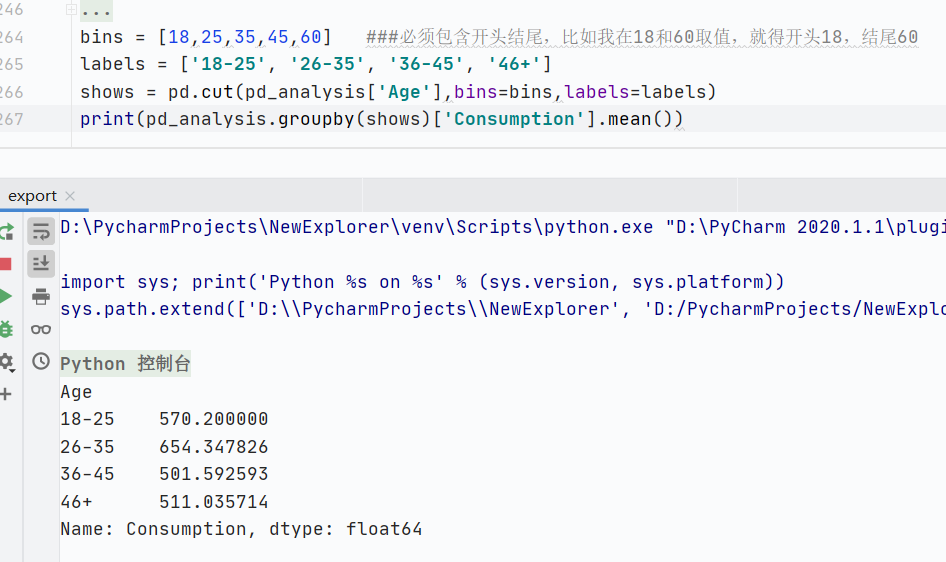
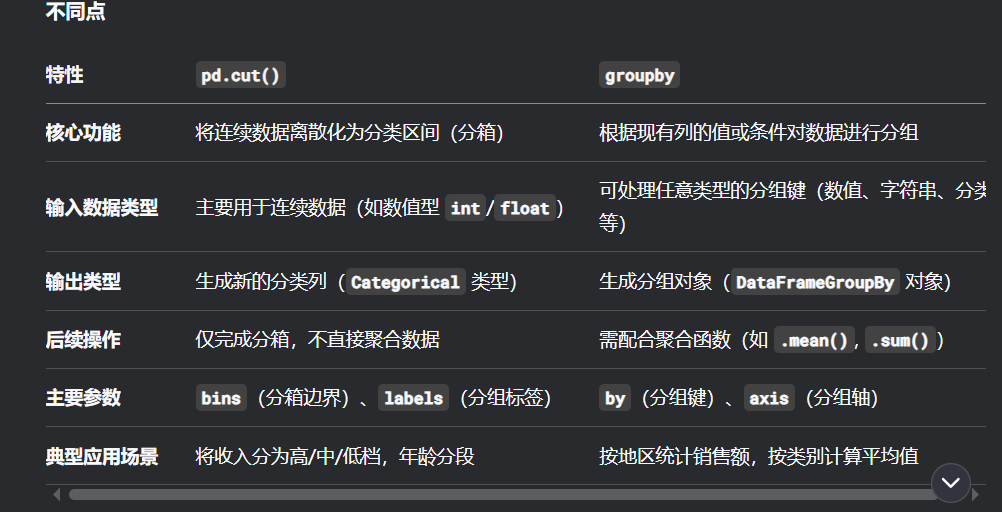

數(shù)據(jù)選擇與過(guò)濾
query():布爾索引的簡(jiǎn)化,布爾索引上面有寫過(guò)
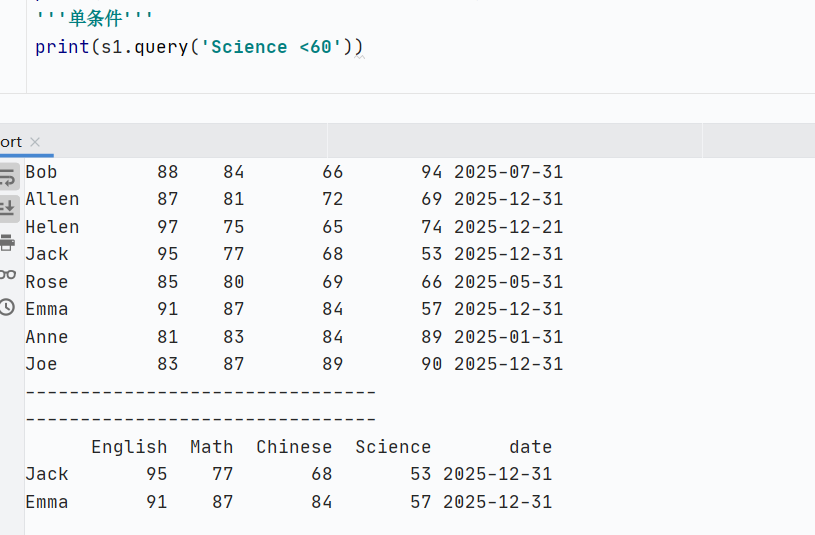
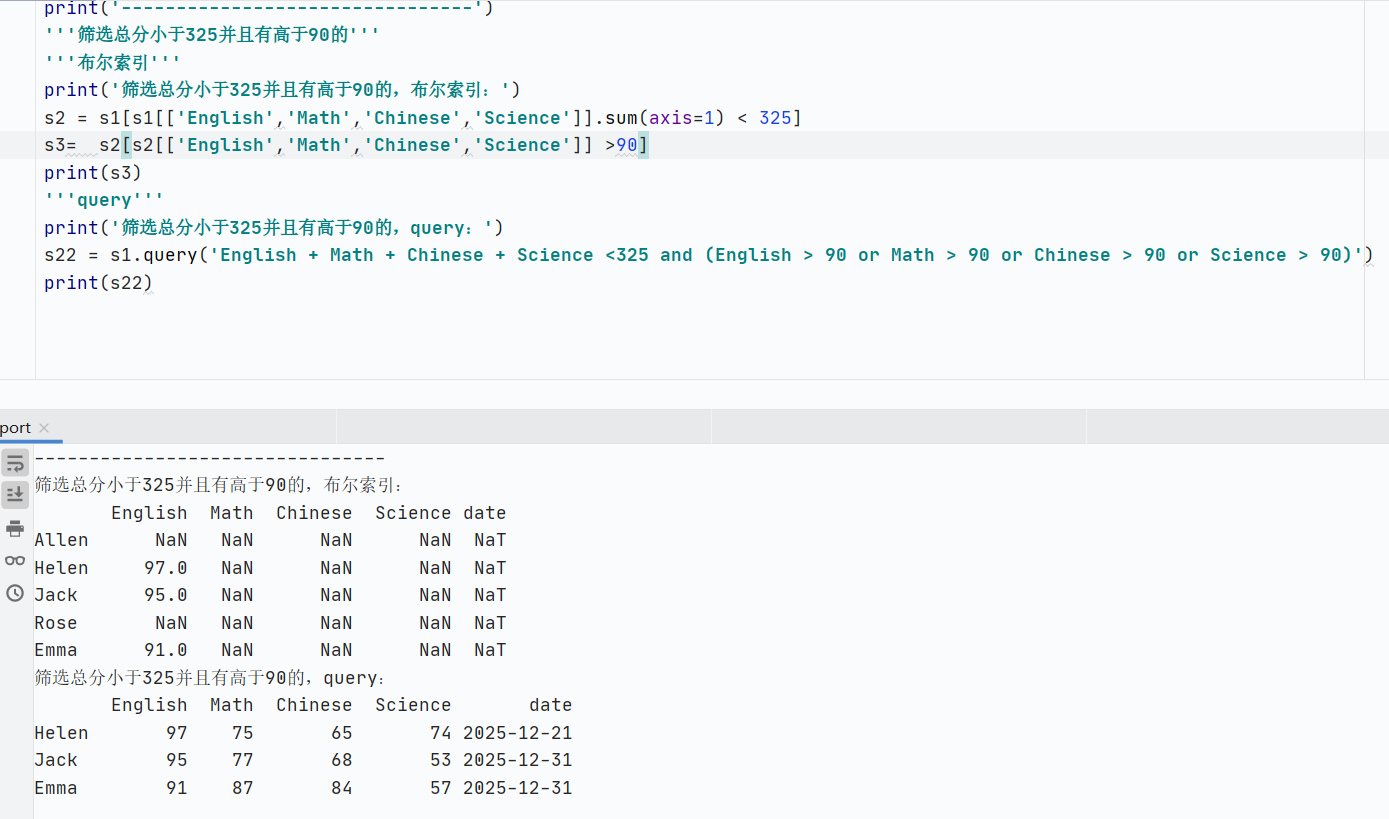
數(shù)據(jù)合并與連接
測(cè)試數(shù)據(jù)

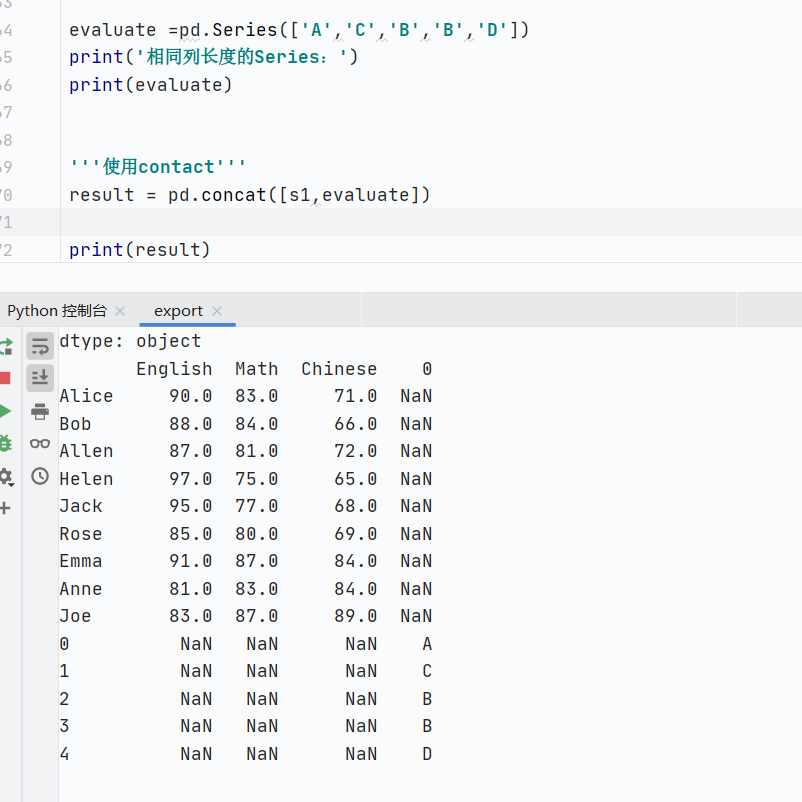
pd.concat:沿軸拼接數(shù)據(jù),需要匹配索引,否則直接向下拼接
- DataFrame拼接Series,索引不匹配的情況下,指定axis=1也不能橫向拼接
![]()

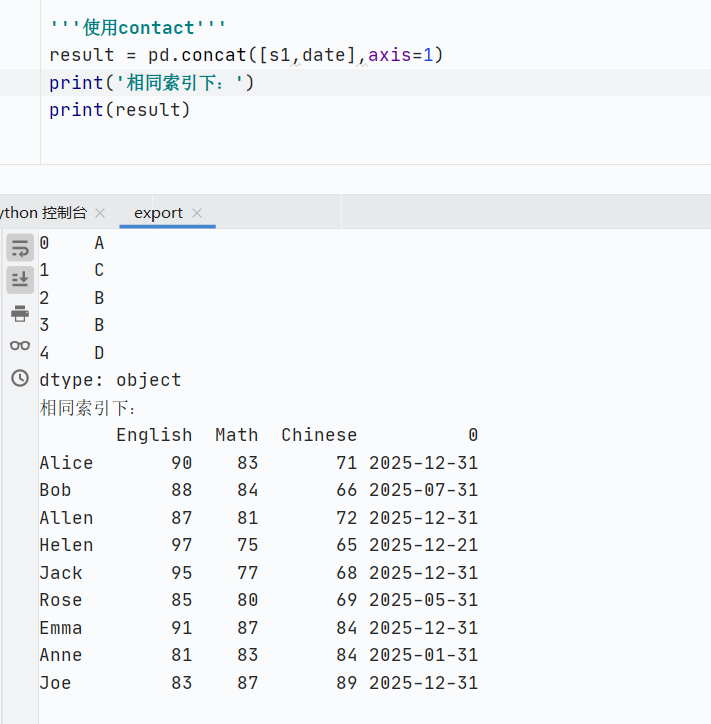
-
DataFrame拼接Series
![]()
-
DataFrame拼接DataFrame橫向拼接
![]()

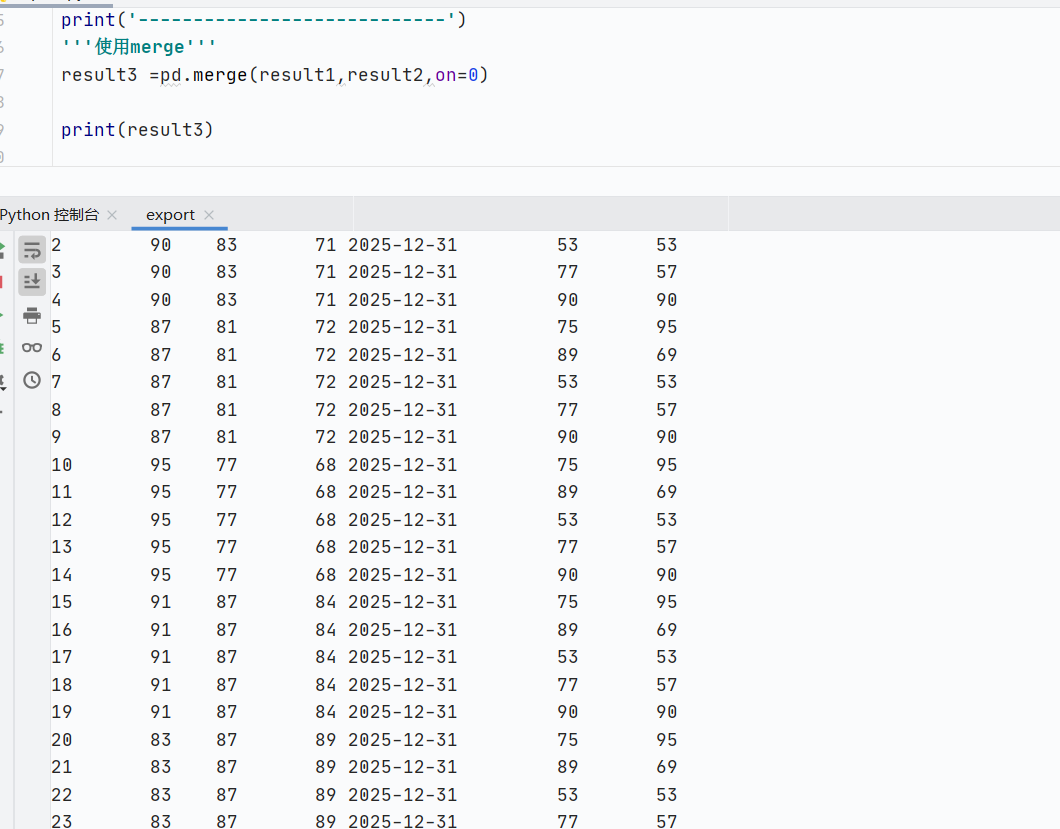
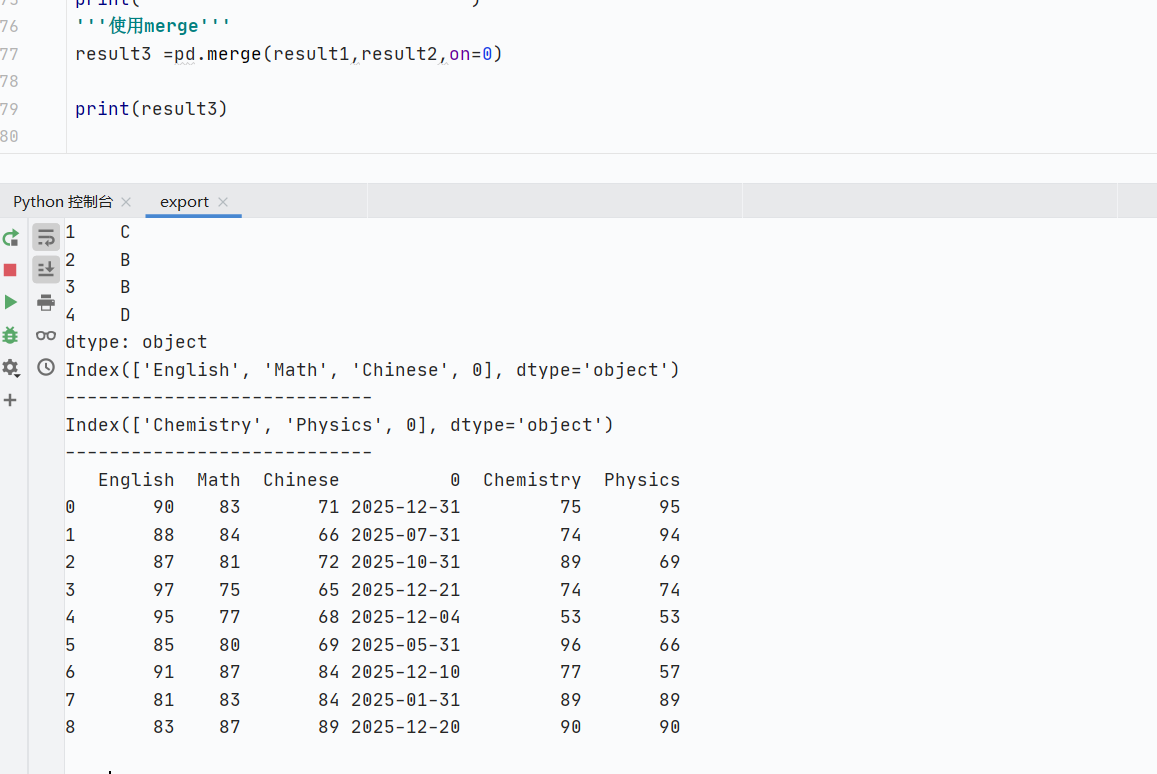
pd.merge:數(shù)據(jù)庫(kù)風(fēng)格連接
-
列數(shù)據(jù)重復(fù),導(dǎo)致合并后保留所有的匹配組合
![]()
-
以某列為基準(zhǔn)的合并,那一列不能有重復(fù)數(shù)據(jù)
![]()
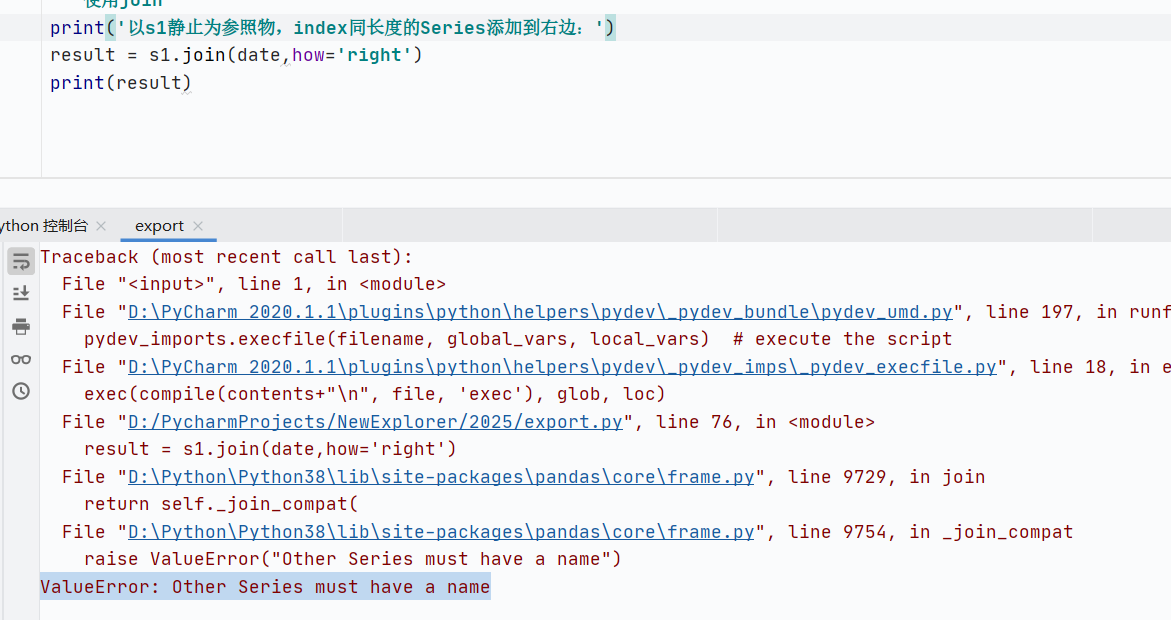
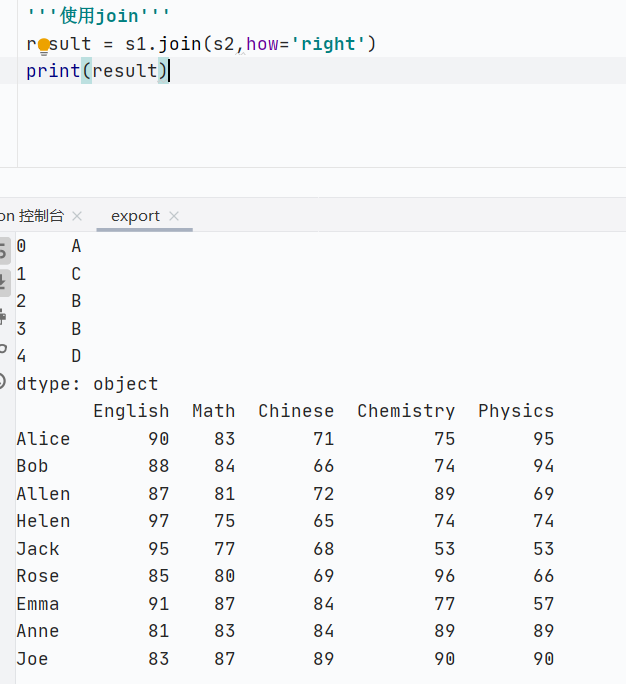
join:索引對(duì)齊連接
-
DataFrame拼接Series,由于Series沒(méi)有列名報(bào)錯(cuò)
![]()
-
DataFrame拼接DataFrame
![]()
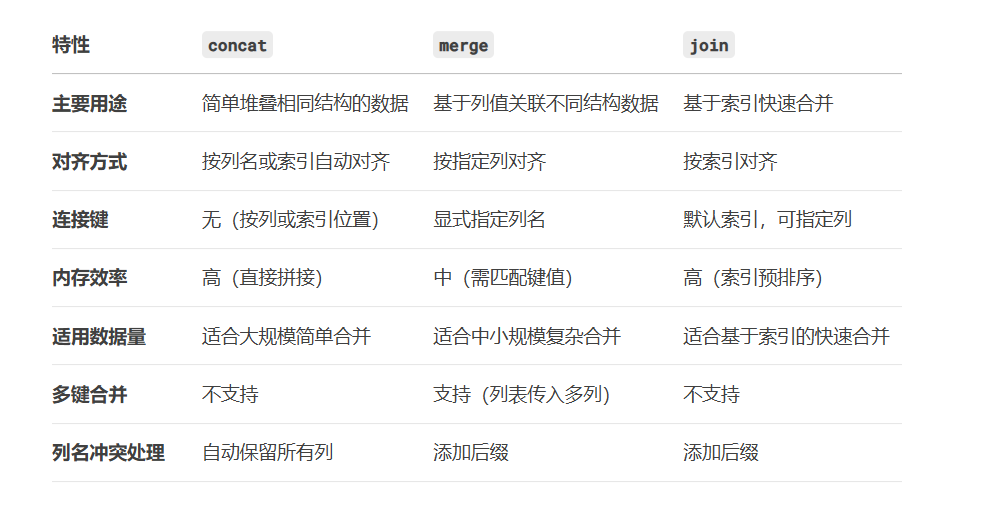
比較不同合并方法
其他功能拓展
屬性類
value_counts():根據(jù)值來(lái)進(jìn)行統(tǒng)計(jì)(本人真的覺(jué)得它好用到爆)

reset_index():將索引轉(zhuǎn)換為常規(guī)數(shù)據(jù)列(會(huì)用在value_counts)
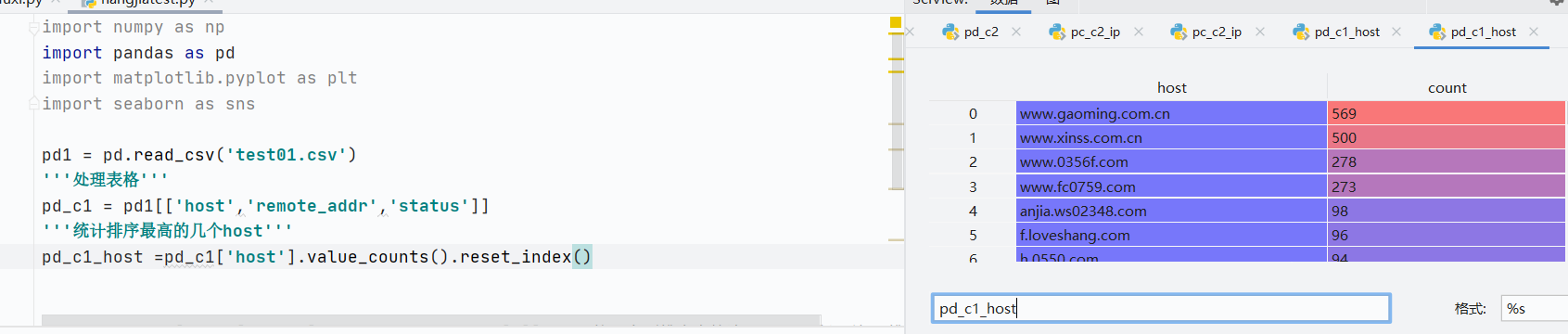
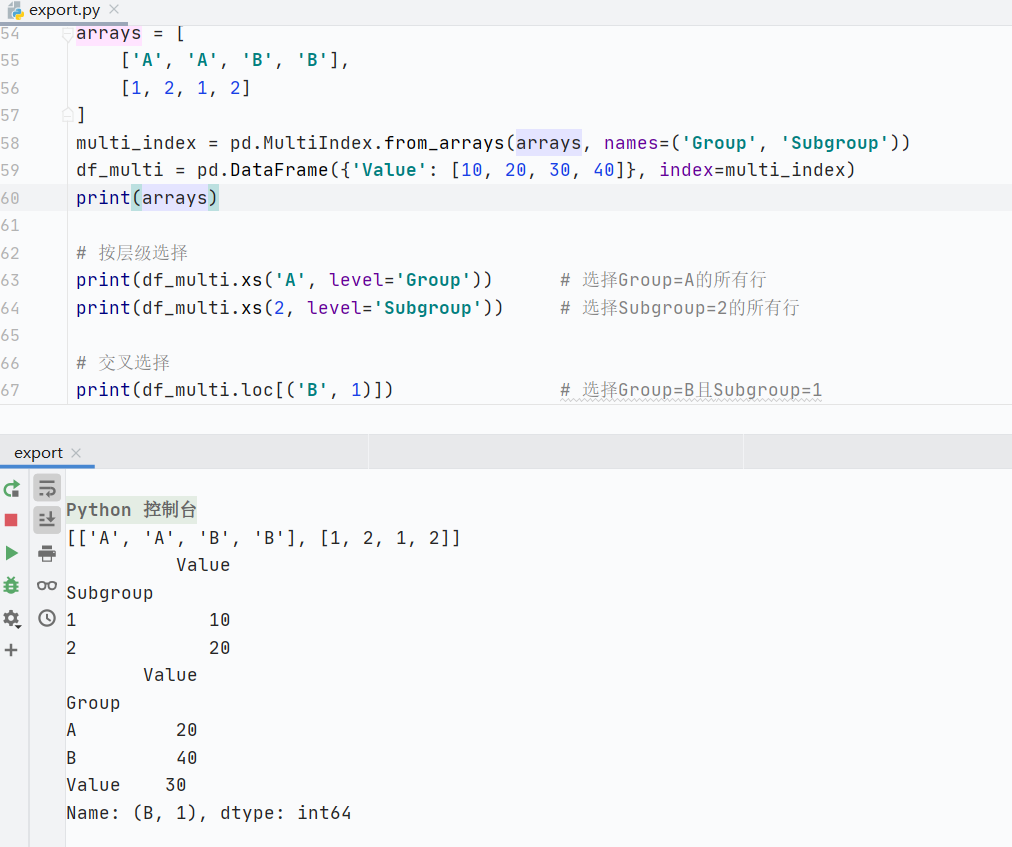
多重索引
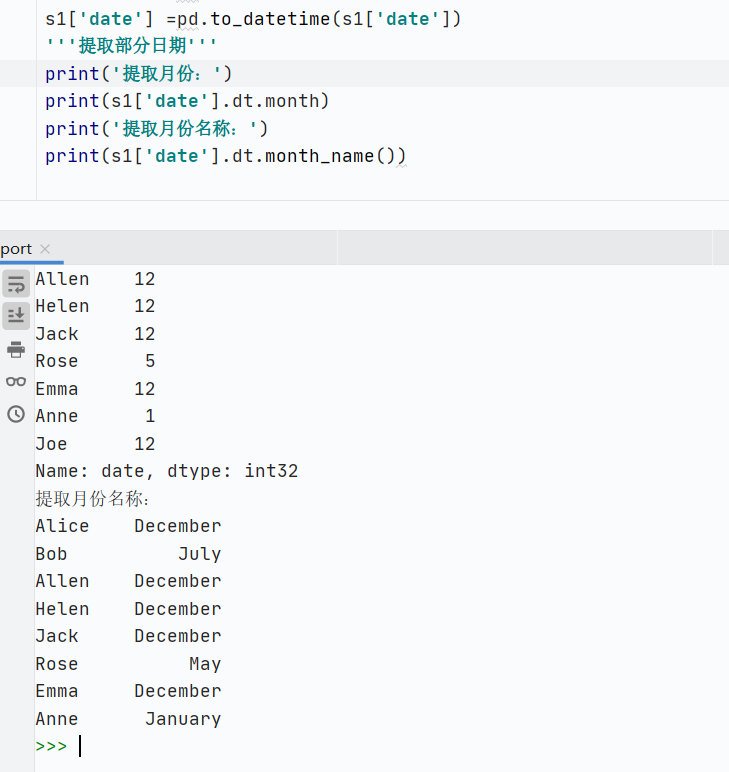
日期類
提取年月日
-
提取單個(gè)
![]()
-
提取多個(gè)
![image]()

高級(jí)演示
- 時(shí)間窗口計(jì)算(暫時(shí)沒(méi)有實(shí)例,所以先copy一下代碼)
# 7天滾動(dòng)平均值 df['RollingAvg'] = df['Sales'].rolling(window='7D').mean() # 重采樣為月統(tǒng)計(jì) monthly = df.resample('M', on='Date').agg({'Sales': 'sum'})
數(shù)據(jù)計(jì)算類
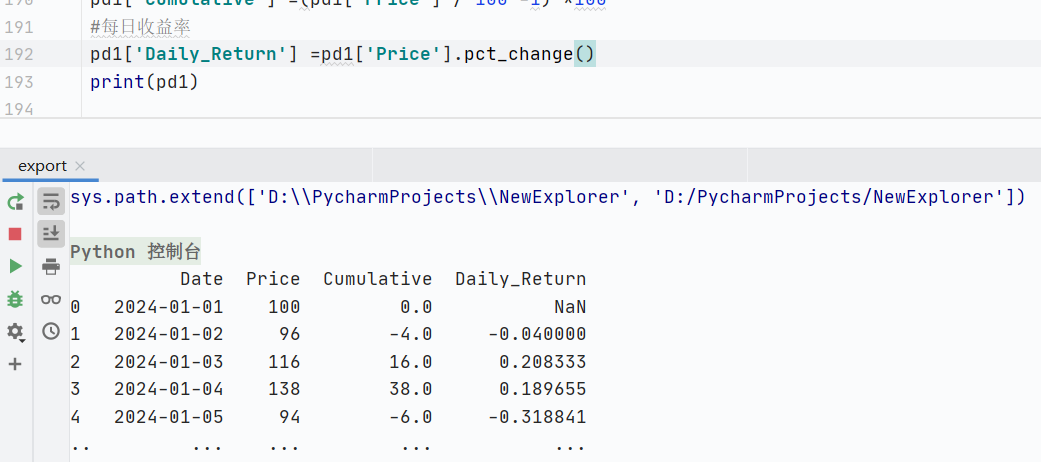
pct_change():直接計(jì)算相鄰元素的百分比變化

corr():計(jì)算列間相關(guān)系數(shù)
計(jì)算數(shù)據(jù)框中各列之間的相關(guān)系數(shù)矩陣
核心參數(shù):
- method:相關(guān)系數(shù)類型,'pearson'(默認(rèn))、'spearman'、'kendall'
- min_periods:計(jì)算所需的最小樣本數(shù)
- numeric_only:是否僅計(jì)算數(shù)值列的相關(guān)系數(shù)(默認(rèn)False,需Pandas 2.0+)
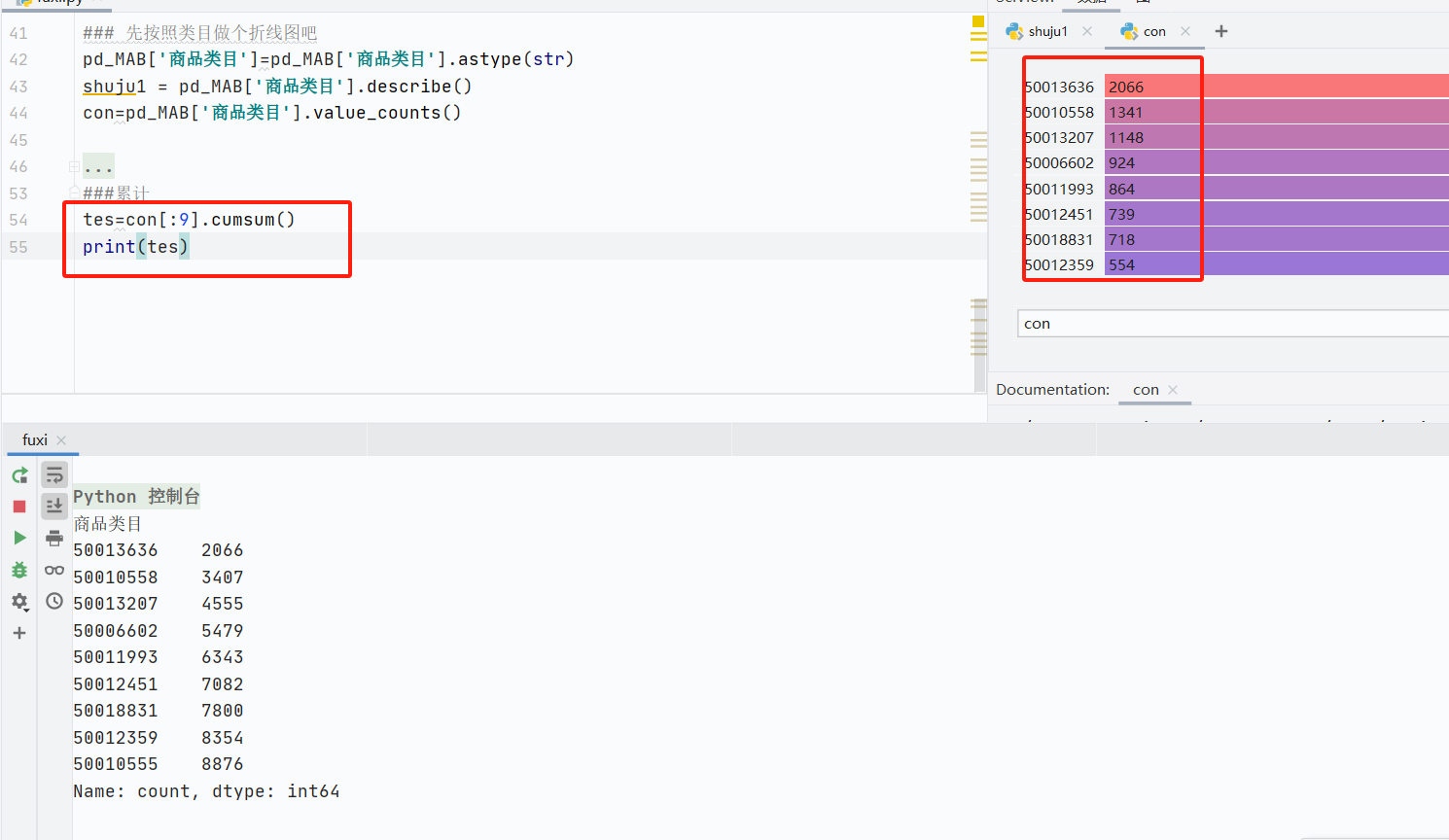
cumsum():數(shù)據(jù)累加

 浙公網(wǎng)安備 33010602011771號(hào)
浙公網(wǎng)安備 33010602011771號(hào)