
Numpy學習指南
基礎部分
入門結合參考:http://www.rzrgm.cn/yigehulu/p/18034817
numpy簡介
核心概念 - 軸(Axis)
軸(Axis)是數組的維度索引,從0開始編號
二維數組的軸
-
axis=0垂直方向(沿行方向,操作跨行) -
axis=1水平方向(沿列方向,操作跨列)
三維數組的軸
axis=0深度方向(跨層操作)axis=1垂直方向(跨行)axis=2水平方向(跨列)
numpy數組
創建數組
np.array()基礎創建
-
創建一維數組
![]()
-
創建二維數組
![]()
-
指定數據類型創建數組
![]()



np.random隨機數創建數組
np.random.randint創建整數數組
![]()


-
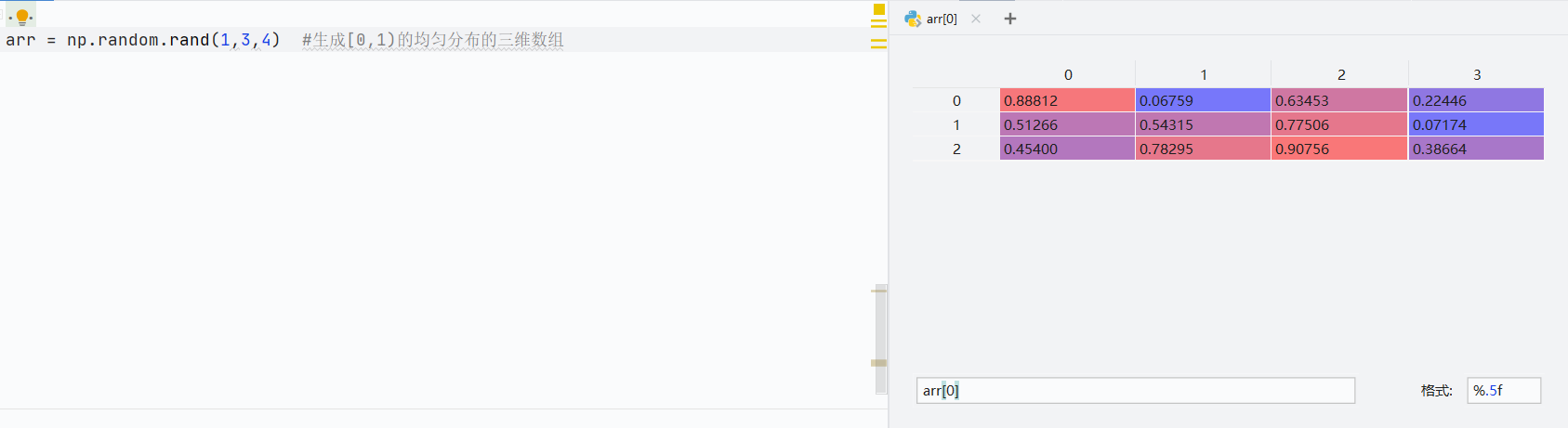
np.random.rand()創建[0,1)均態分布數組
![]()
-
np.random.randn()標準正態分布
![]()
-
np.random.random()通用均勻分布
![]()
-
np.random.normal()自定義正態分布
![]()
-
np.random.uniform()自定義均勻分布,區間內所有數值的概率相同
![]()
-
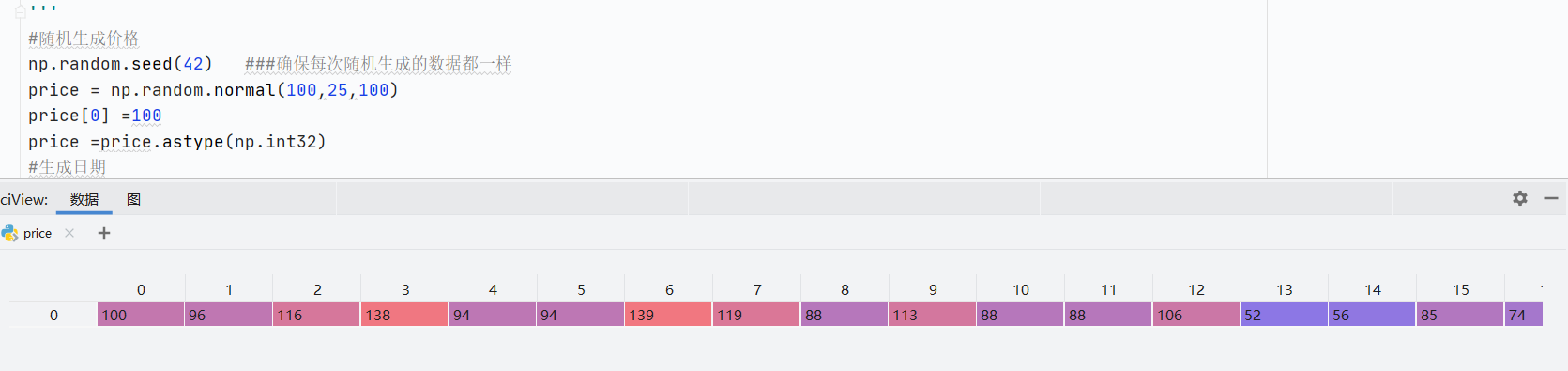
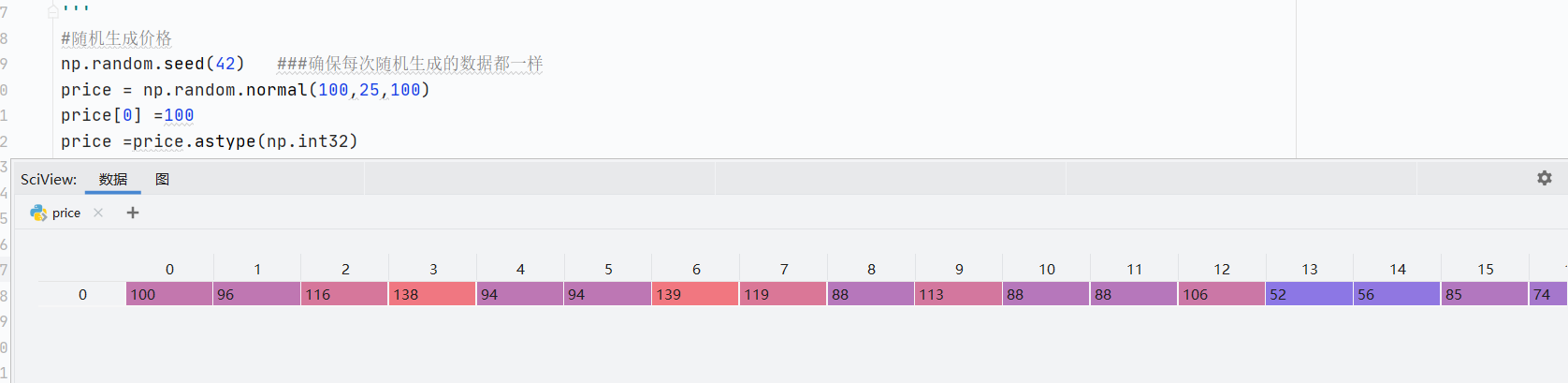
np.random.seed(42)確保每次隨機過后的數據值都一樣
![]()




-
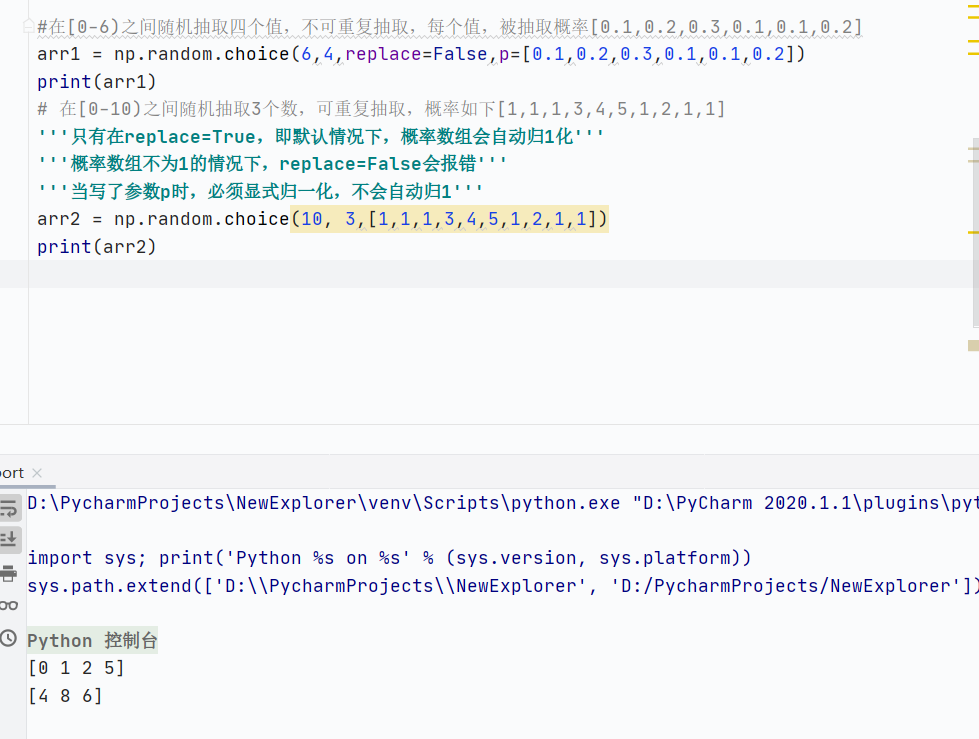
np.random.choice():隨機抽樣,a必須是一維數組,replace表示是否重復抽取,p表示抽取概率
![]()
-
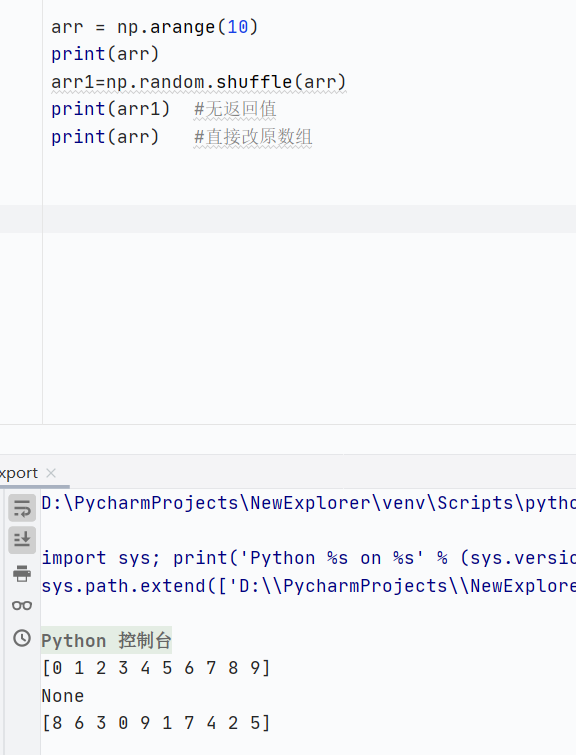
np.random.shuffle()原地洗牌,直接修改原數組
![]()
-
np.random.permutation()返回打亂后的新數組,原數組不變
![]()

其他特殊數組
-
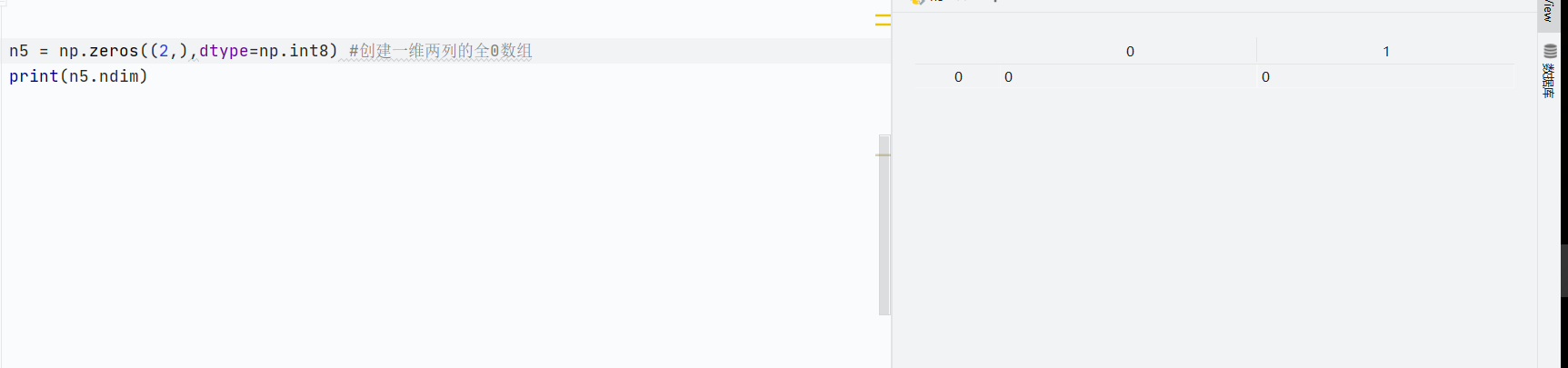
np.zeros()創造全0數組-
創建指定形狀的全0數組
![]()
-
創建指定類型的全0數組
![]()
-
-
np.ones()創建全1數組-
創建指定形狀的全1數組
![]()
-
創建指定數據類型的全1數組
![]()
-
自定義填充
![]()
-
-
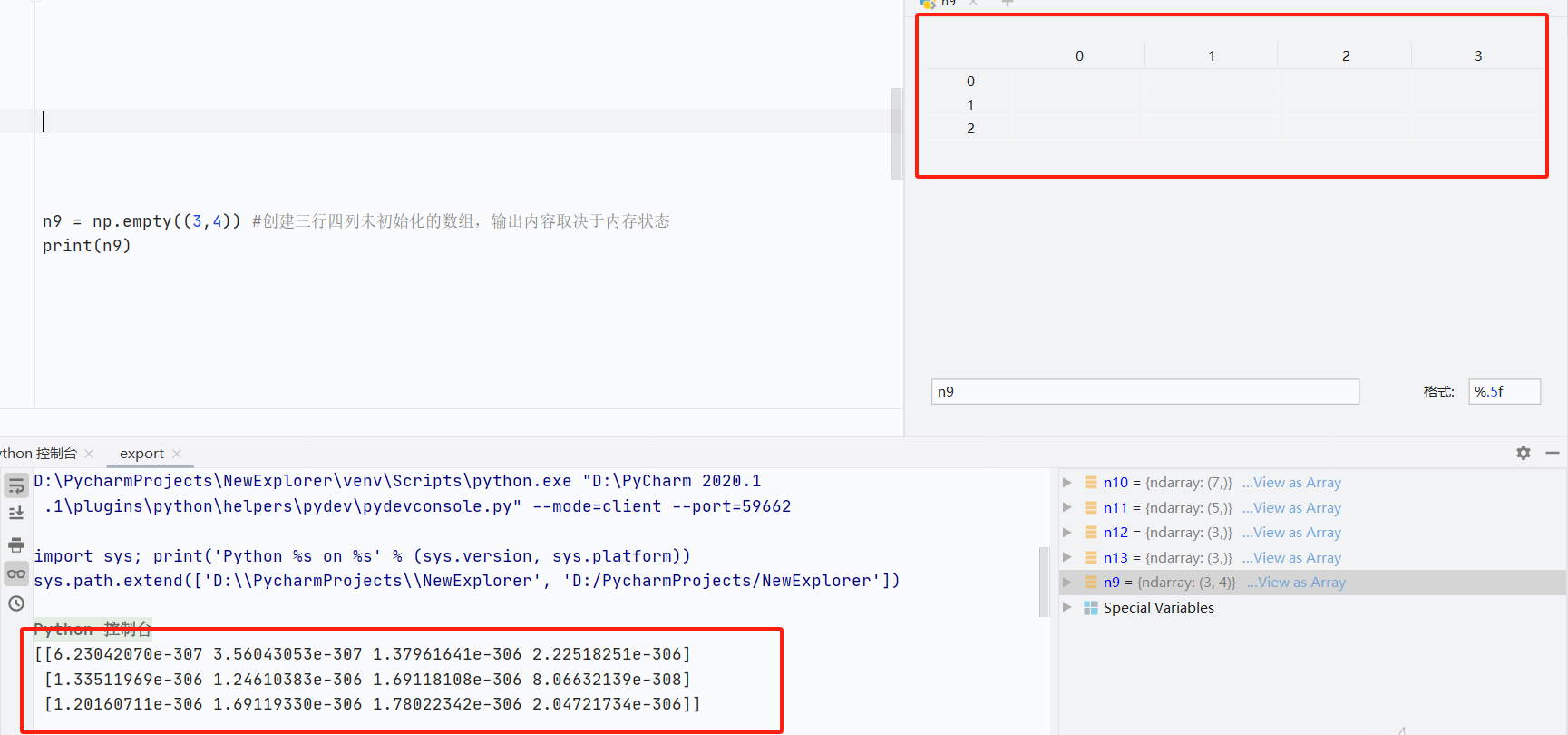
np.empty()未初始化數組- 創建隨機內容數組,取決于內存
![]()
- 創建隨機內容數組,取決于內存
-
np.arange()數值范圍數組-
創建指定范圍內數組
![]()
-
創建指定范圍內數組,并指定數據類型
![]()
-
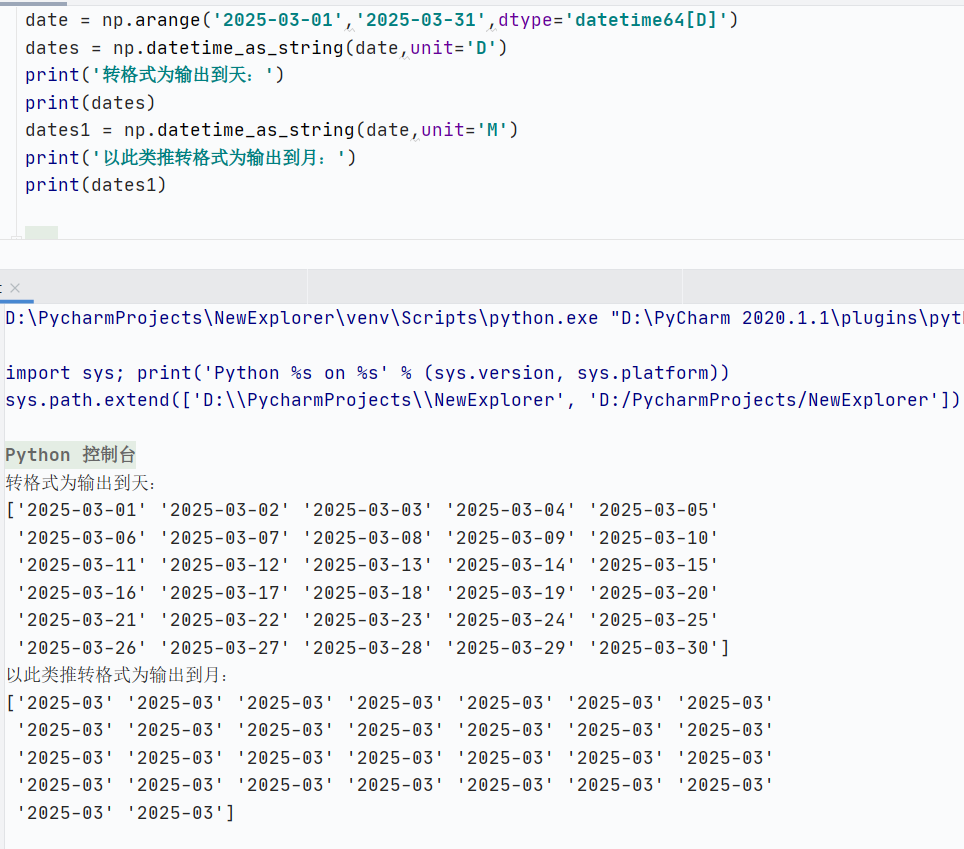
創建日期數組
![]()
格式化輸出(在使用 np.arange(start, end, dtype='datetime64[D]') 生成日期時,輸出的日期顯示包含時分秒的現象,是由 NumPy 內部日期時間表示機制和默認的字符串格式化規則 導致的)
![]()
-
-
np.linspace()線性間隔數組-
創建等距數組,默認包含終點
![]()
-
創建包含終點的等差數組
![]()
-









數組屬性
-
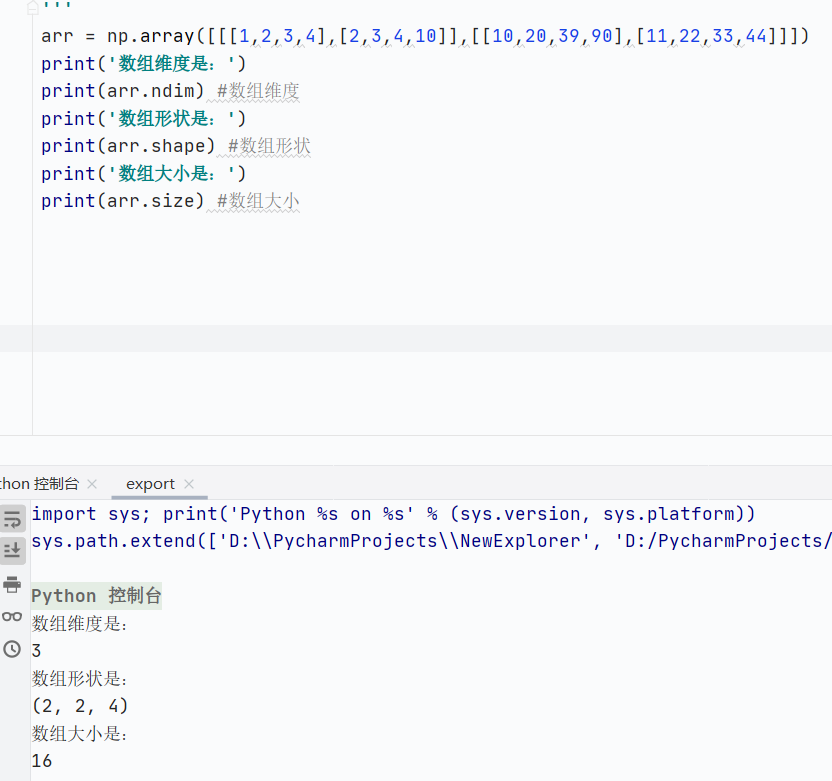
數組維度
![]()
-
數據類型
![]()
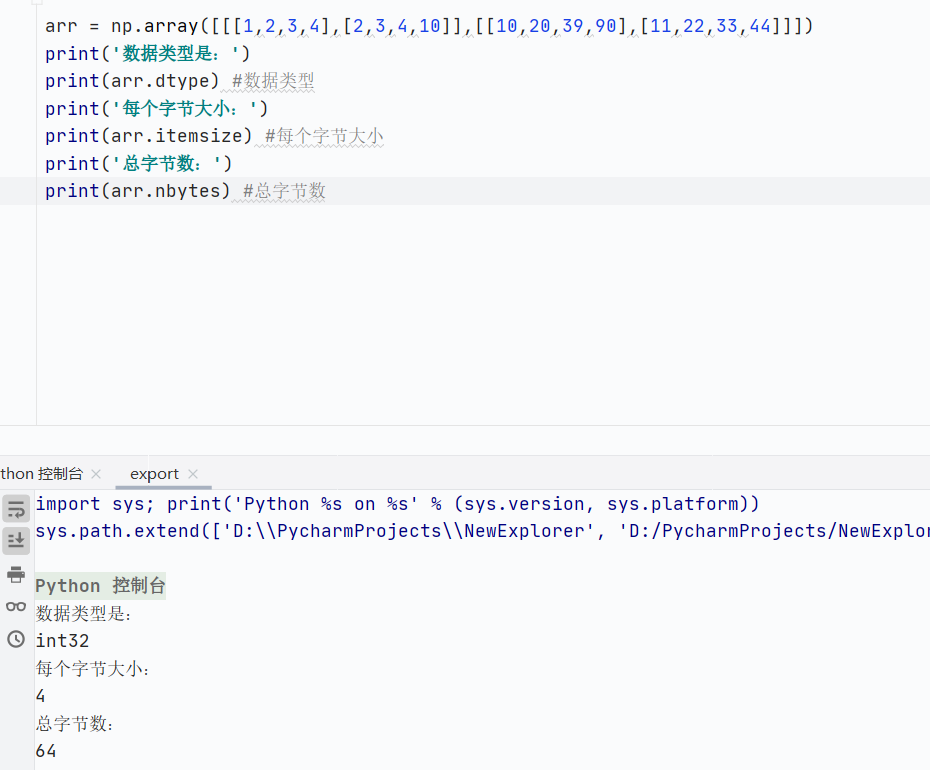
數組數據類型
-
常見數據類型如下圖
![]()
-
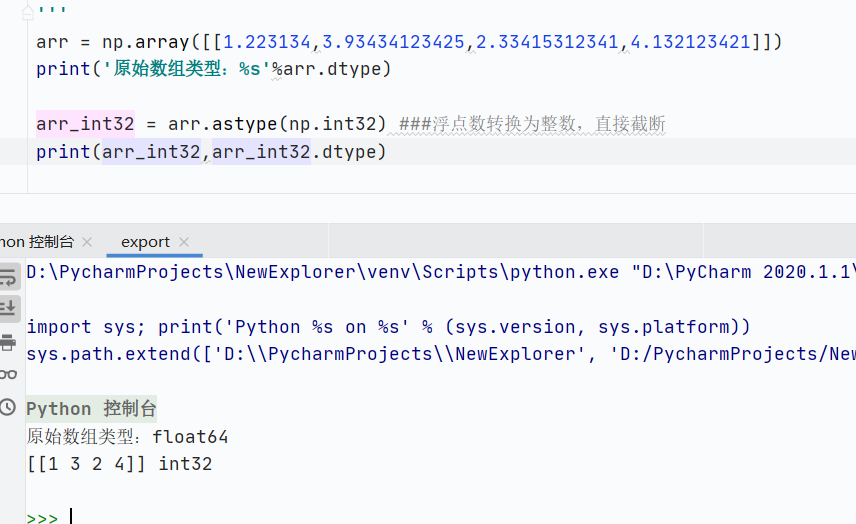
astype()數據類型轉換-
浮點數轉換為整數,直接截斷(非四舍五入)
![]()
-
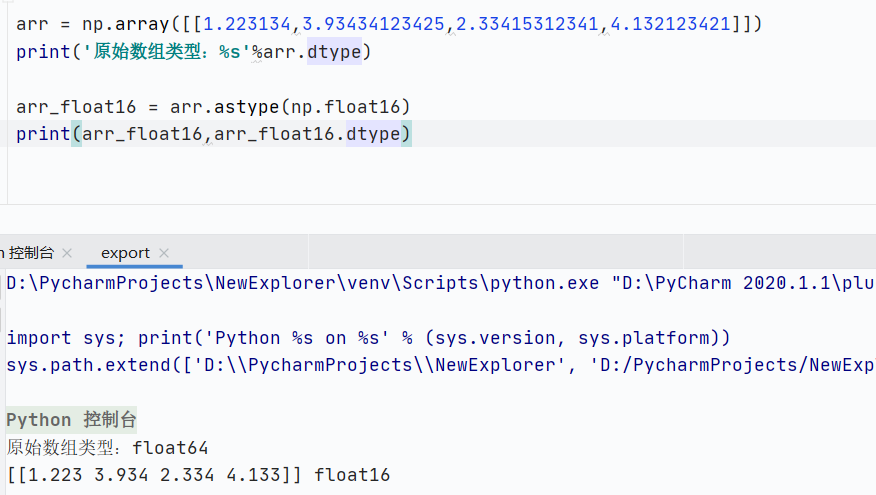
高精度浮點數轉換成低精度浮點數
![]()
-
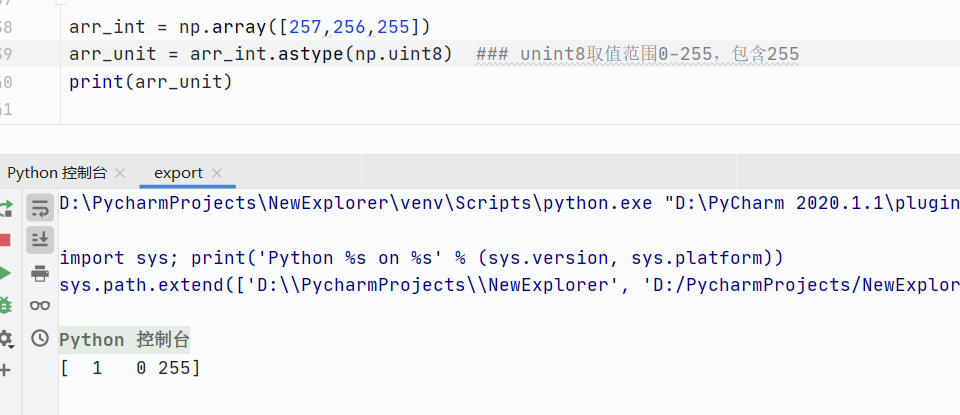
大整數轉換為小類型整數,溢出,自動取模
![]()
-
字符串轉換成數值
![]()
-
數值轉換成布爾值
![]()
-
數值轉換成日期格式
![]()
![]()
![]()
-






特殊數組
- 單位矩陣
np.eye()對角線為1,剩下數值由0填充
![]()


-
對角矩陣
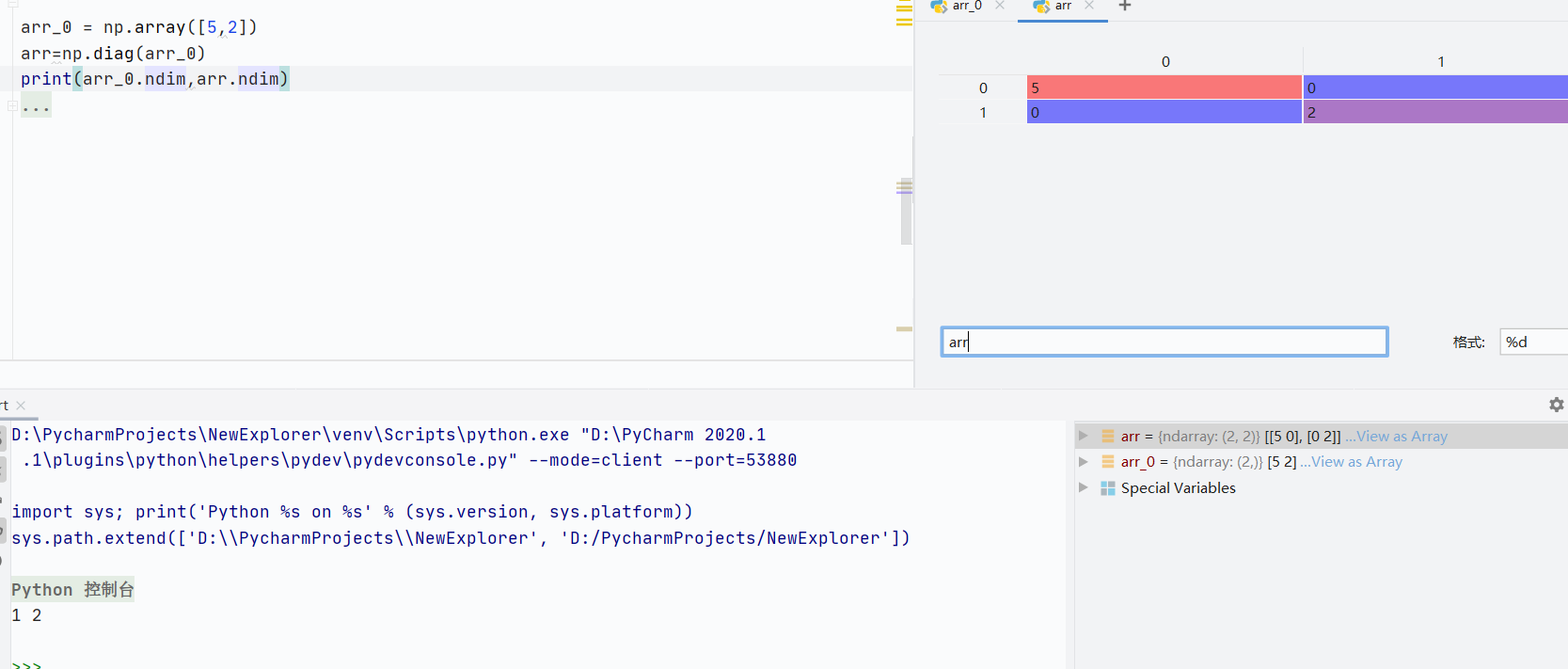
np.diag()-
一維數組會變成二維數組,對角線數值為給定數組,剩下由0填充
![]()
-
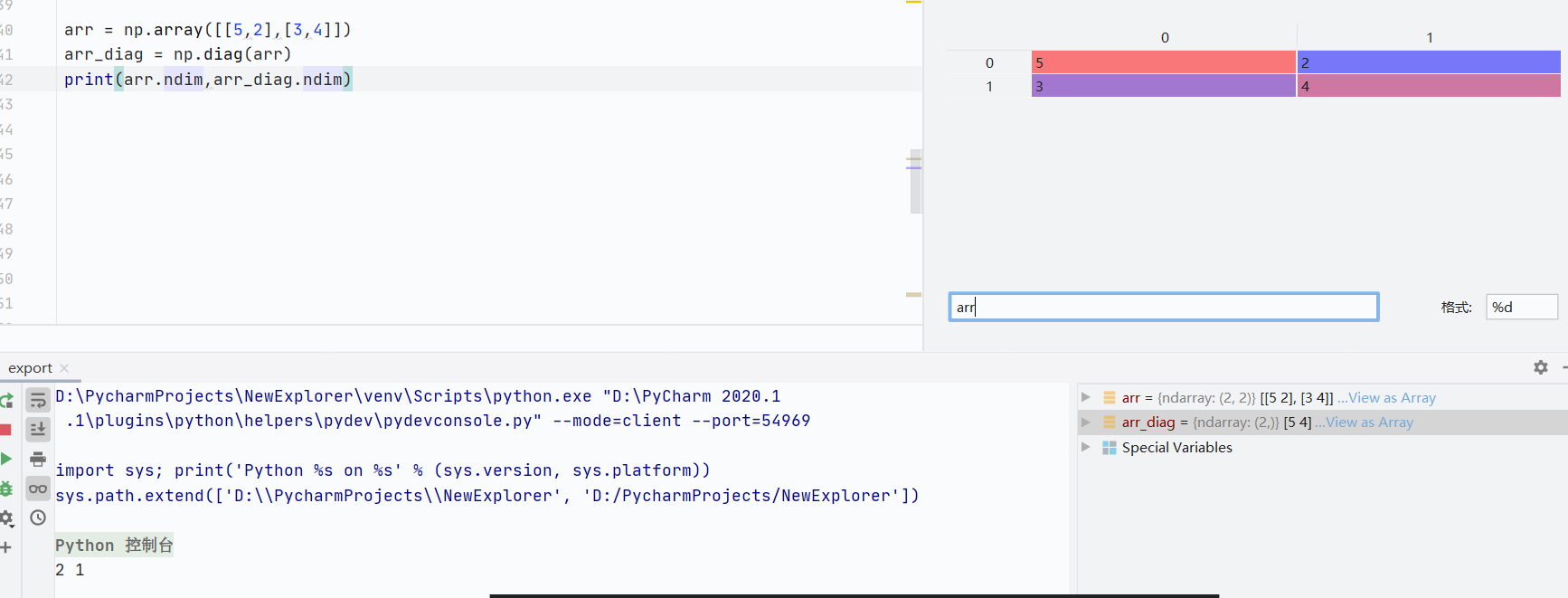
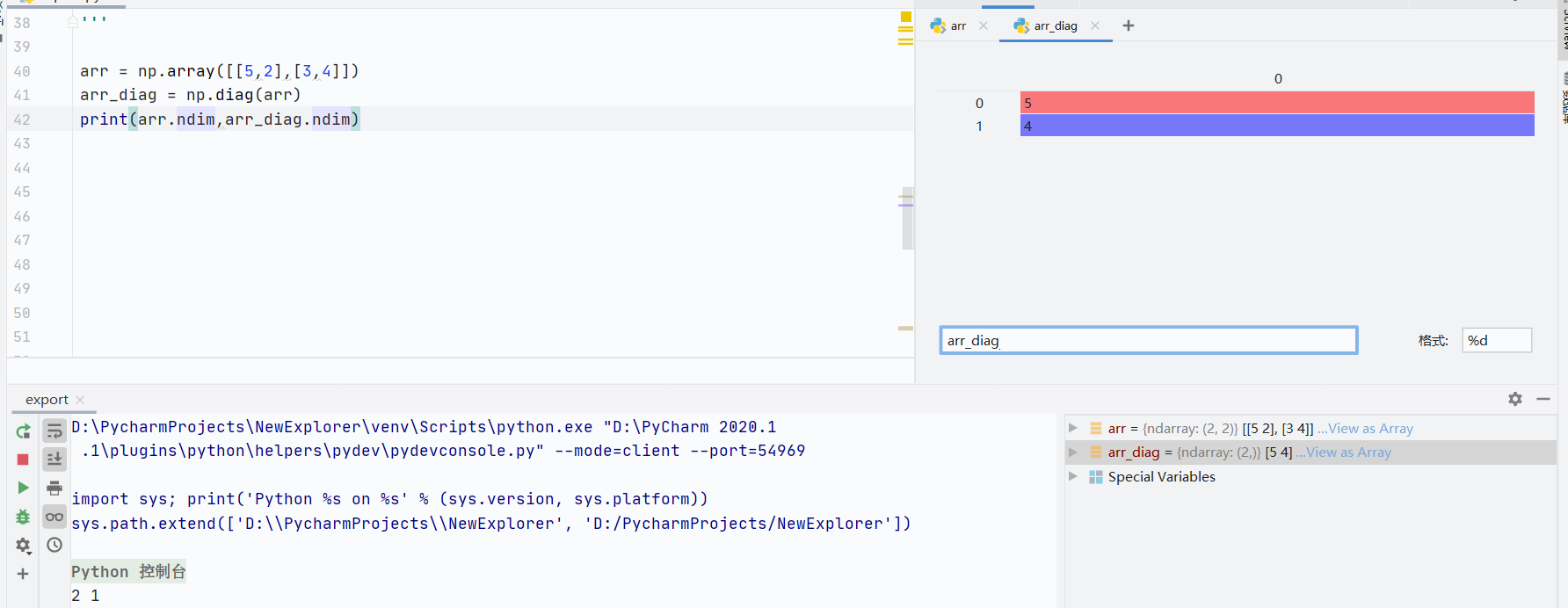
二維數組會變成一維數組,只顯示對角線數值
![]()
![]()
-
數組操作
索引和切片
-
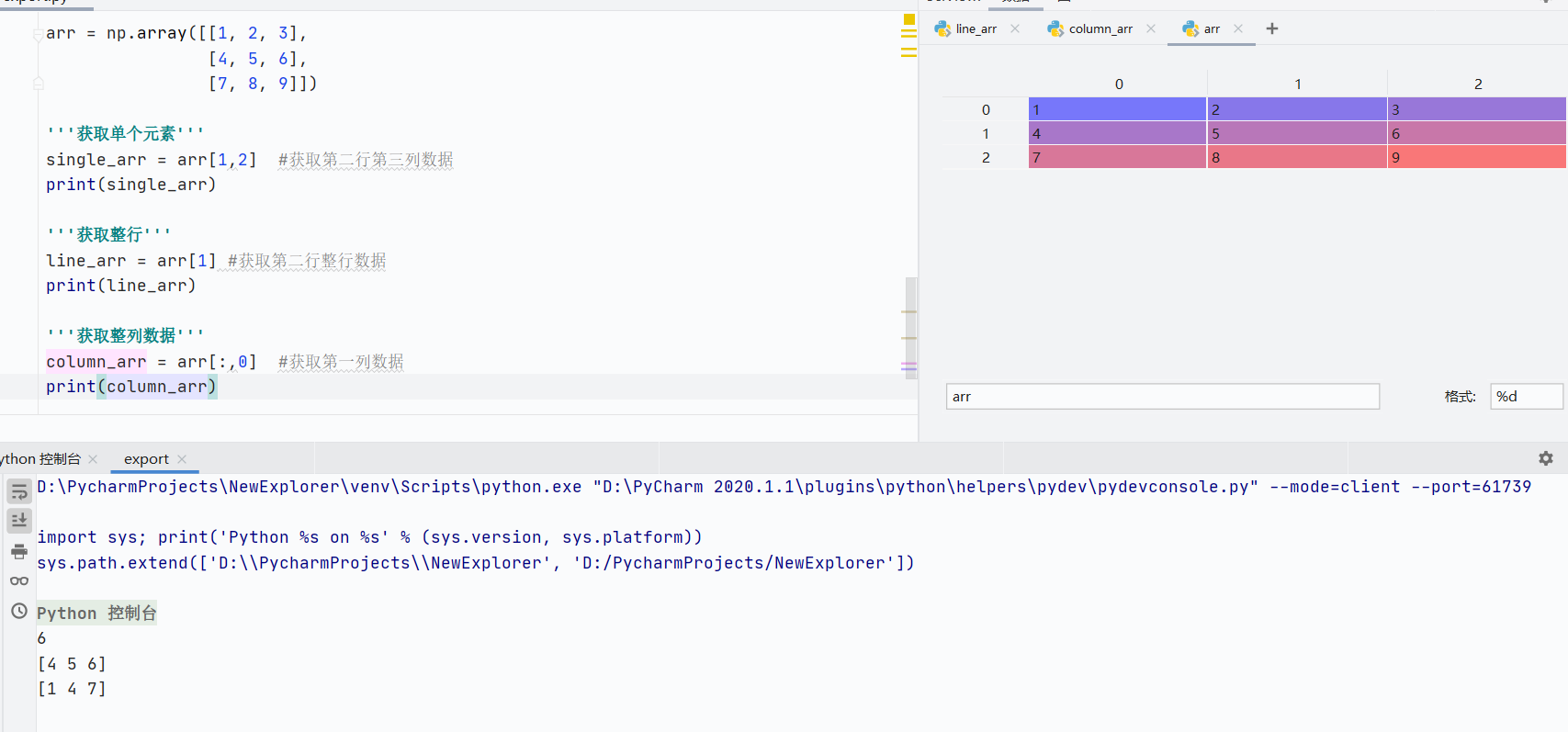
基礎索引
![]()
-
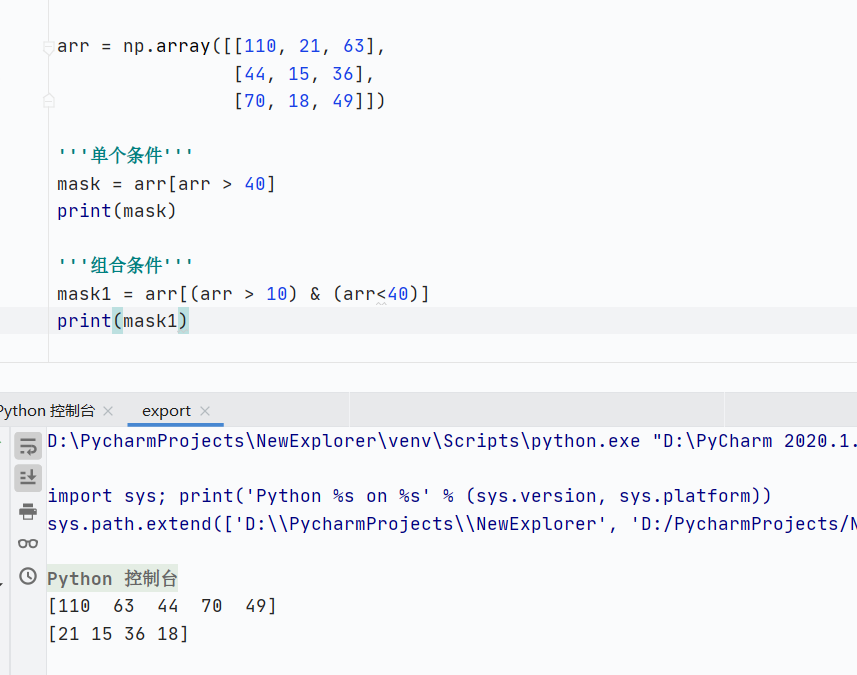
布爾索引
![]()
-
切片操作
-
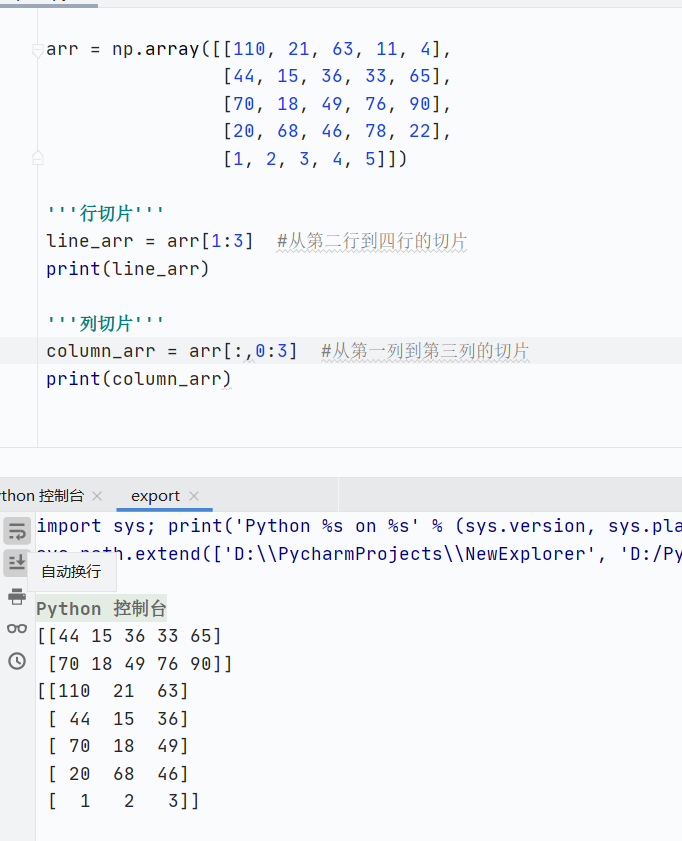
行列切片
![]()
-
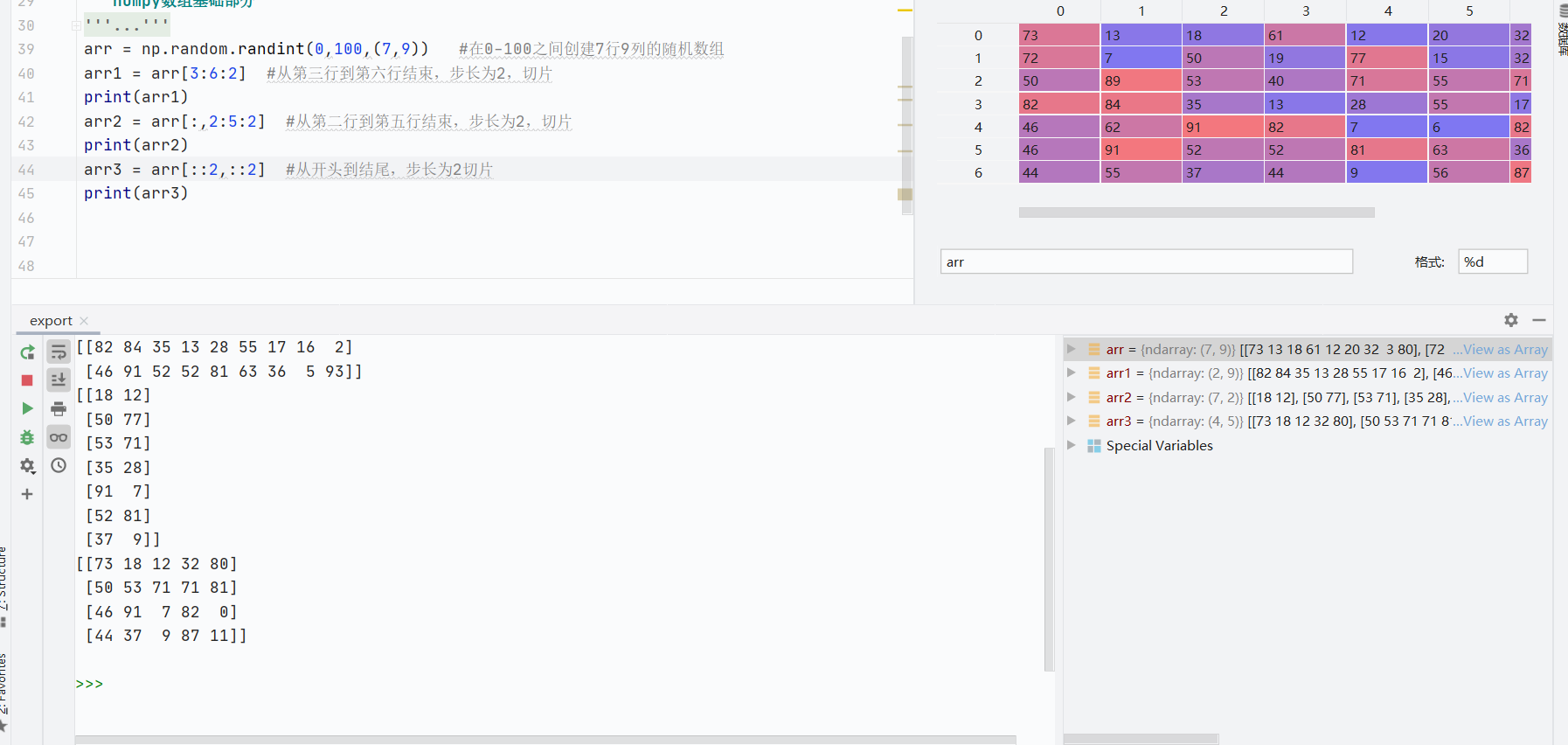
步長切片
![]()
-
形狀操作
-
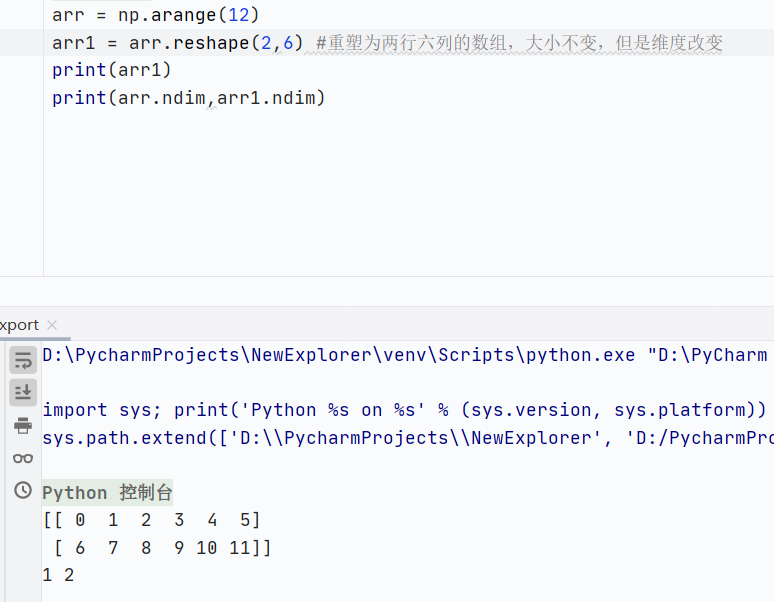
reshape()重塑形狀
![]()
-
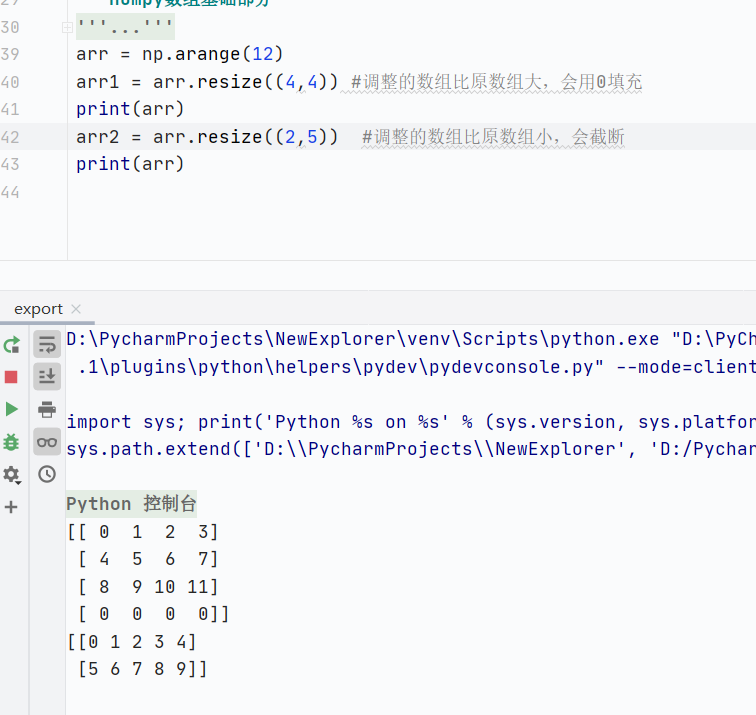
resize()調整大小,直接修改原數組,返回值為None
![]()
-
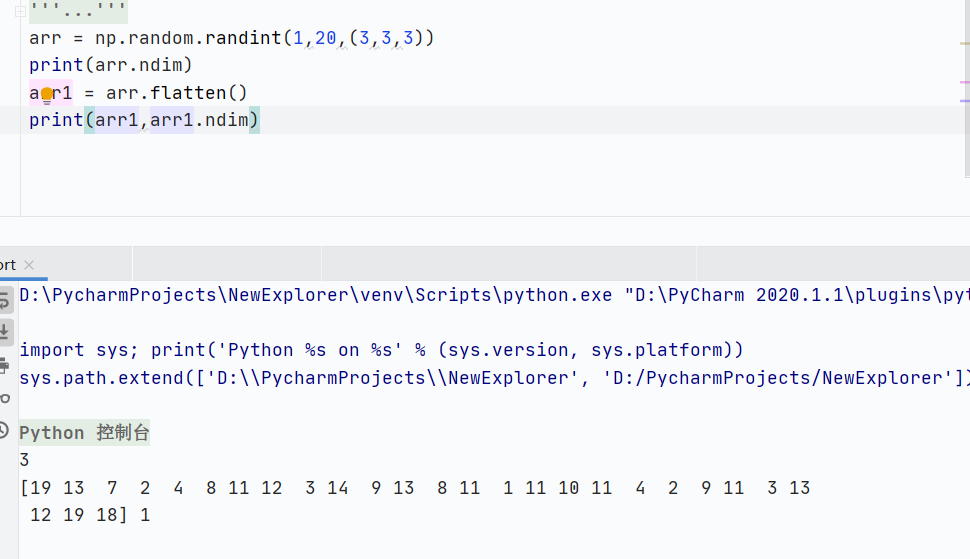
flatten()展平數組,多維數組轉換為一維數組,深拷貝,不影響原數組
![]()
數組堆疊
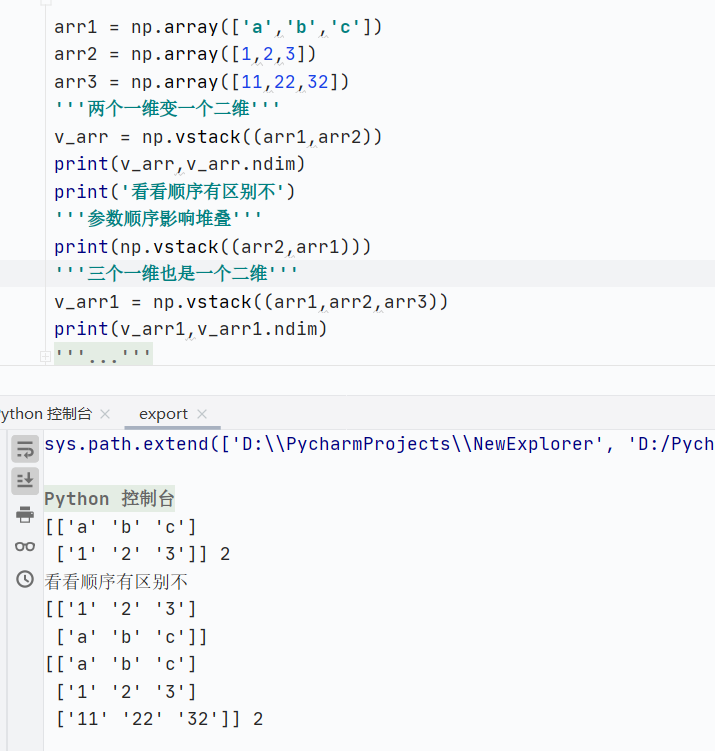
np.vstack()垂直堆疊
![]()

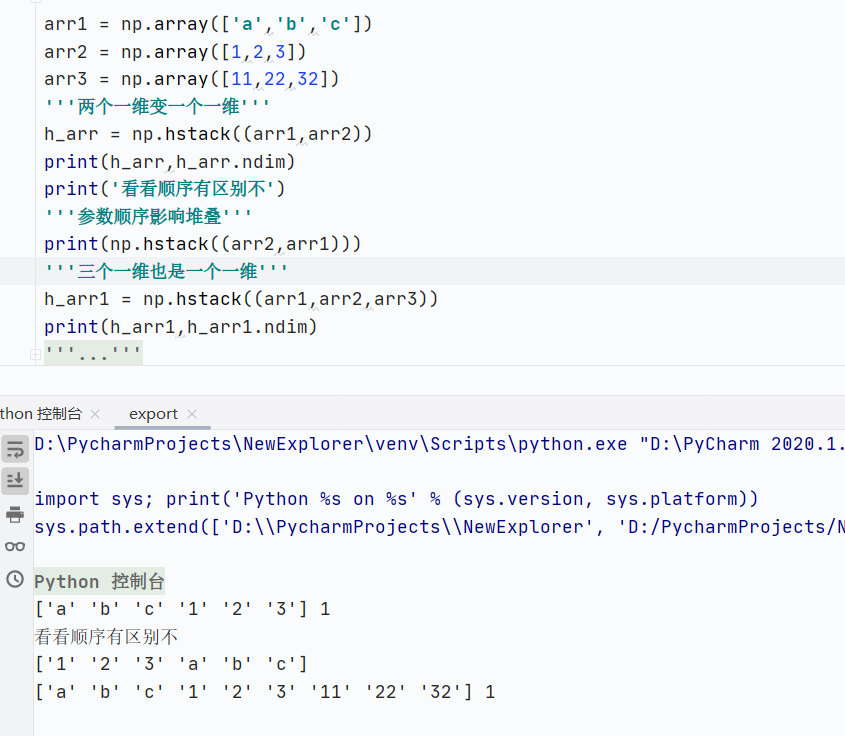
np.hstack()水平堆疊,數據類型必須相同,否則報錯
![]()

np.concatenate()通用堆疊,數據類型必須相同,否則報錯
![]()

數組分割
-
np.split()-
平均分,數組大小一定要能被均分,不然報錯
![]()
-
自定義分
![]()
-
-
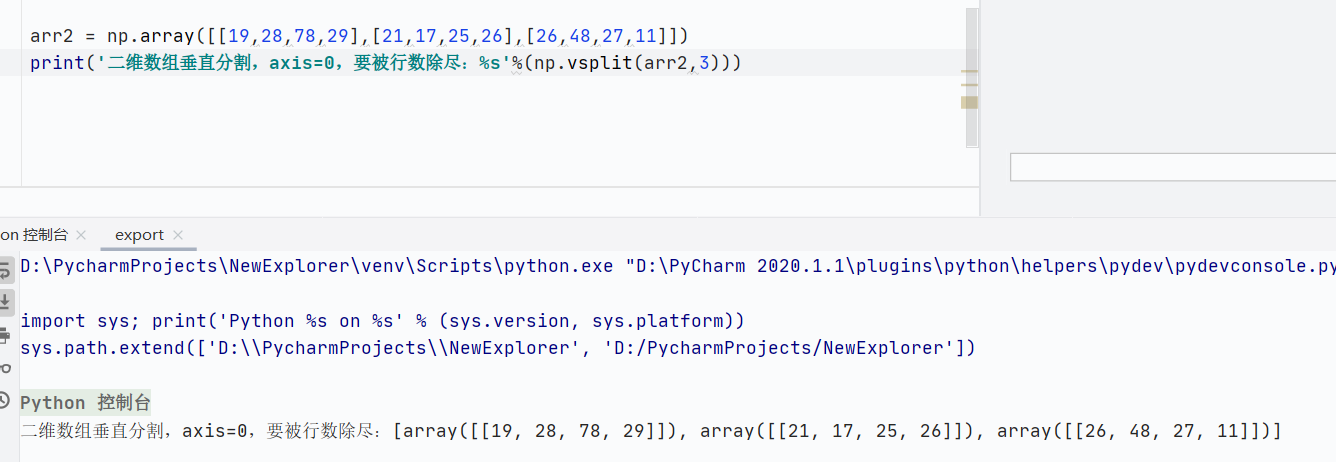
np.vsplit()垂直分割,用于一維數組報錯,axis=0,行相關
![]()
-
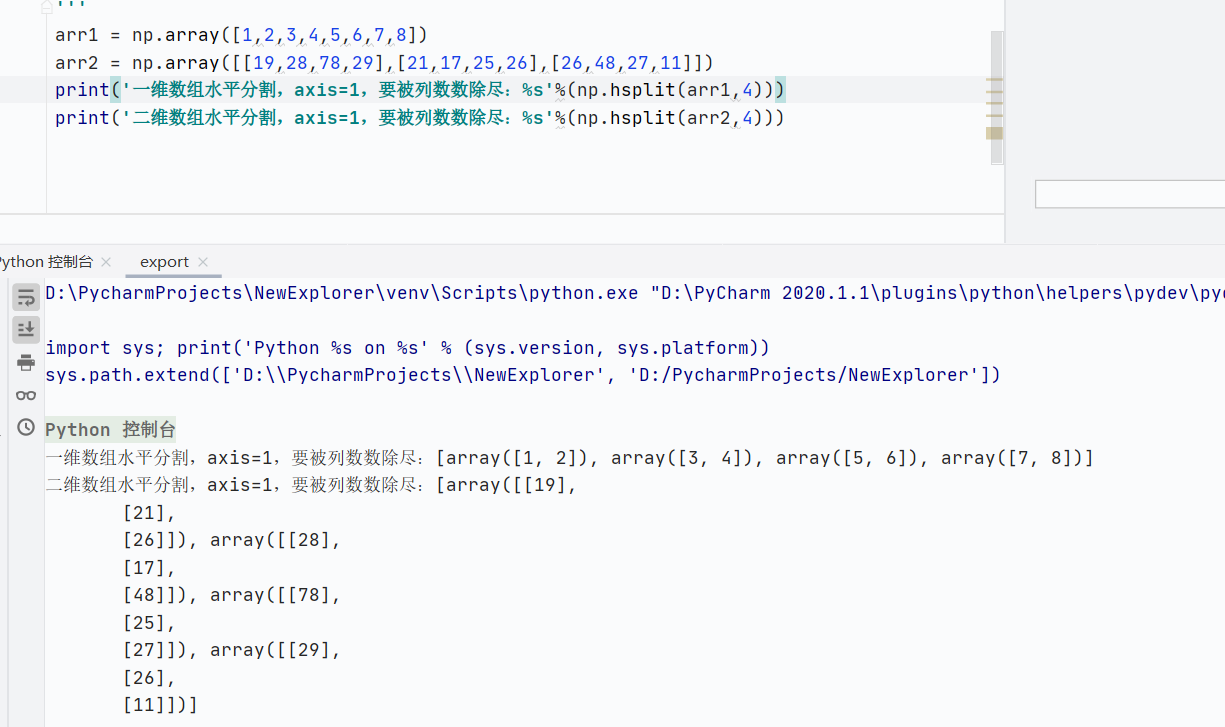
np.hsplit()水平分割,axis=1,列相關
![]()


中級部分
數組運算
廣播機制(Broadcasting)
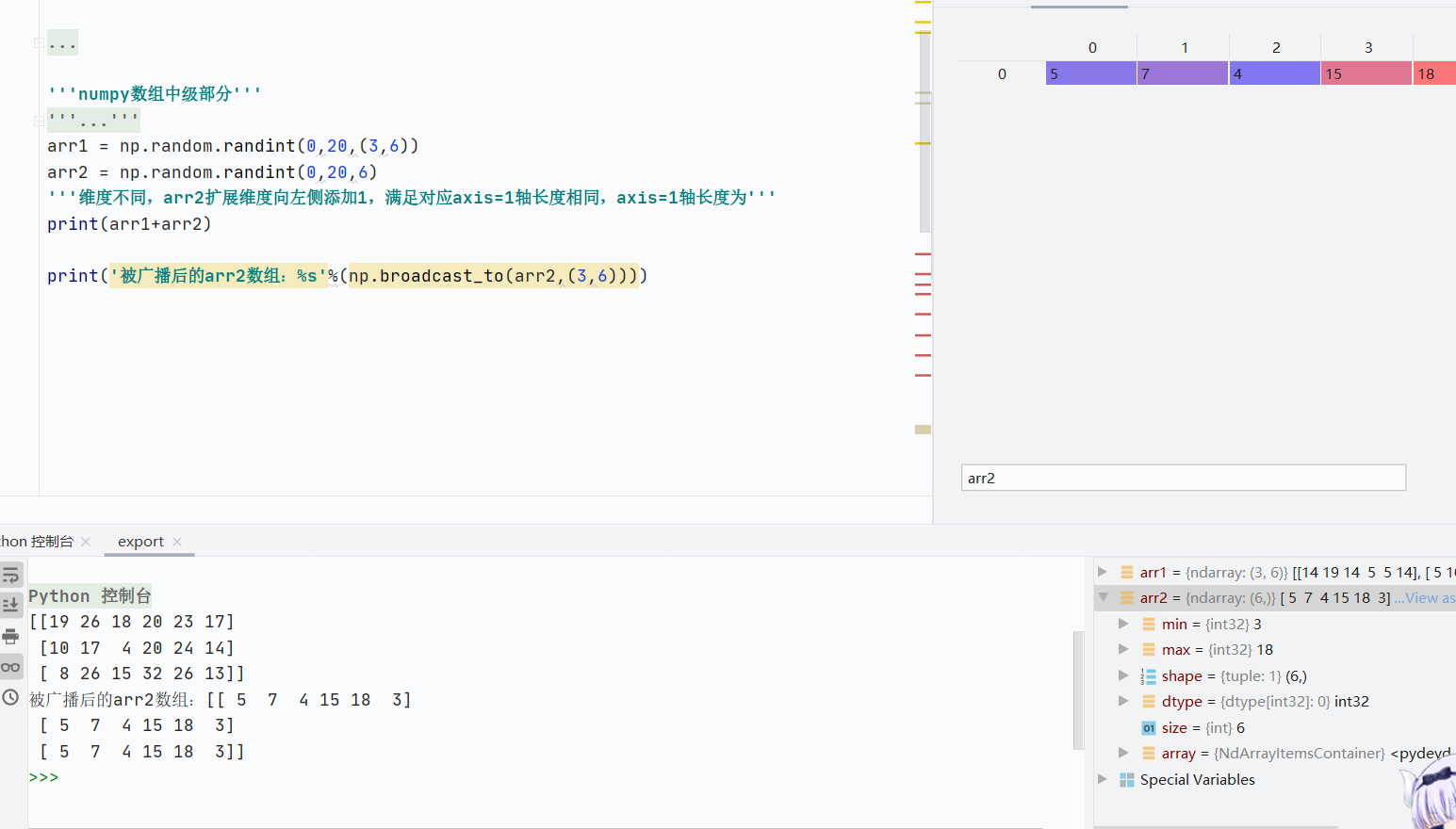
廣播是 NumPy 對不同形狀數組進行數學運算的規則。當兩個數組形狀不同時,自動擴展較小數組的維度,使其與較大數組的形狀兼容,從而完成逐元素運算。
廣播機制
-
先比較形狀,在比較維度,再比較對應軸長度
-
如果兩個數維度不相等,會在低維度數組形狀左側填充1,直到維度與高維度數組相等
![]()
-
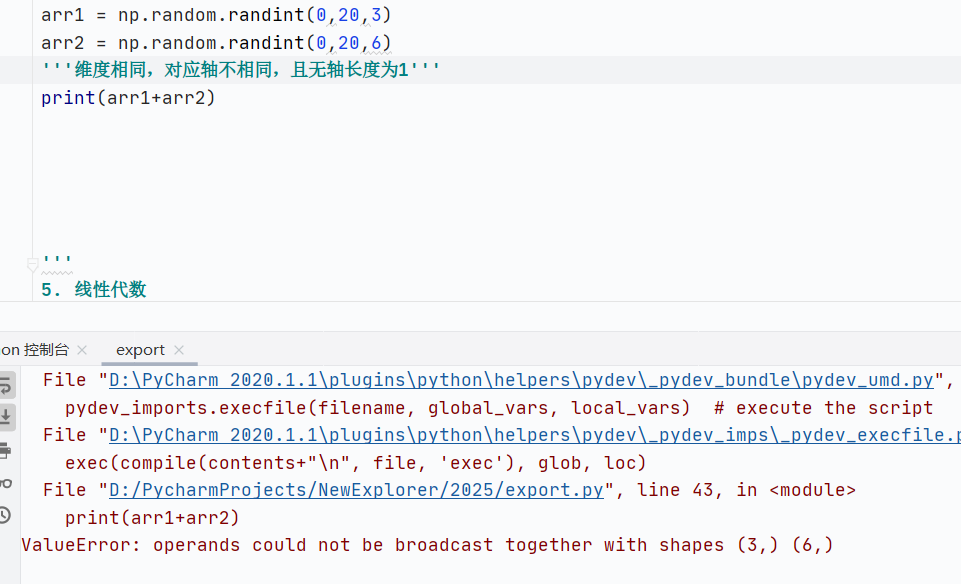
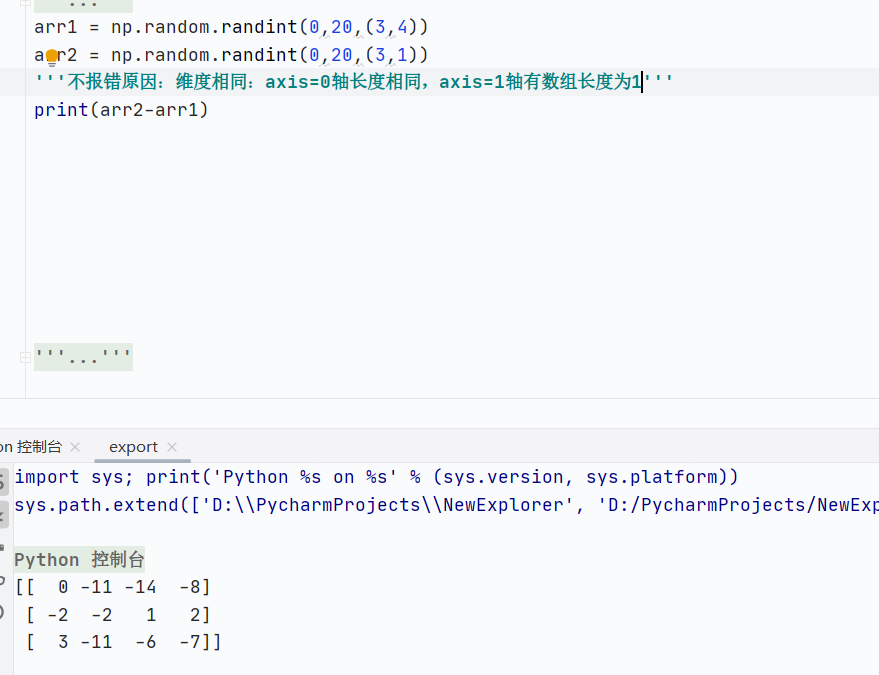
如果維度相同,形狀不同情況下,數組對應軸長度相同,且有一軸為1
![]()

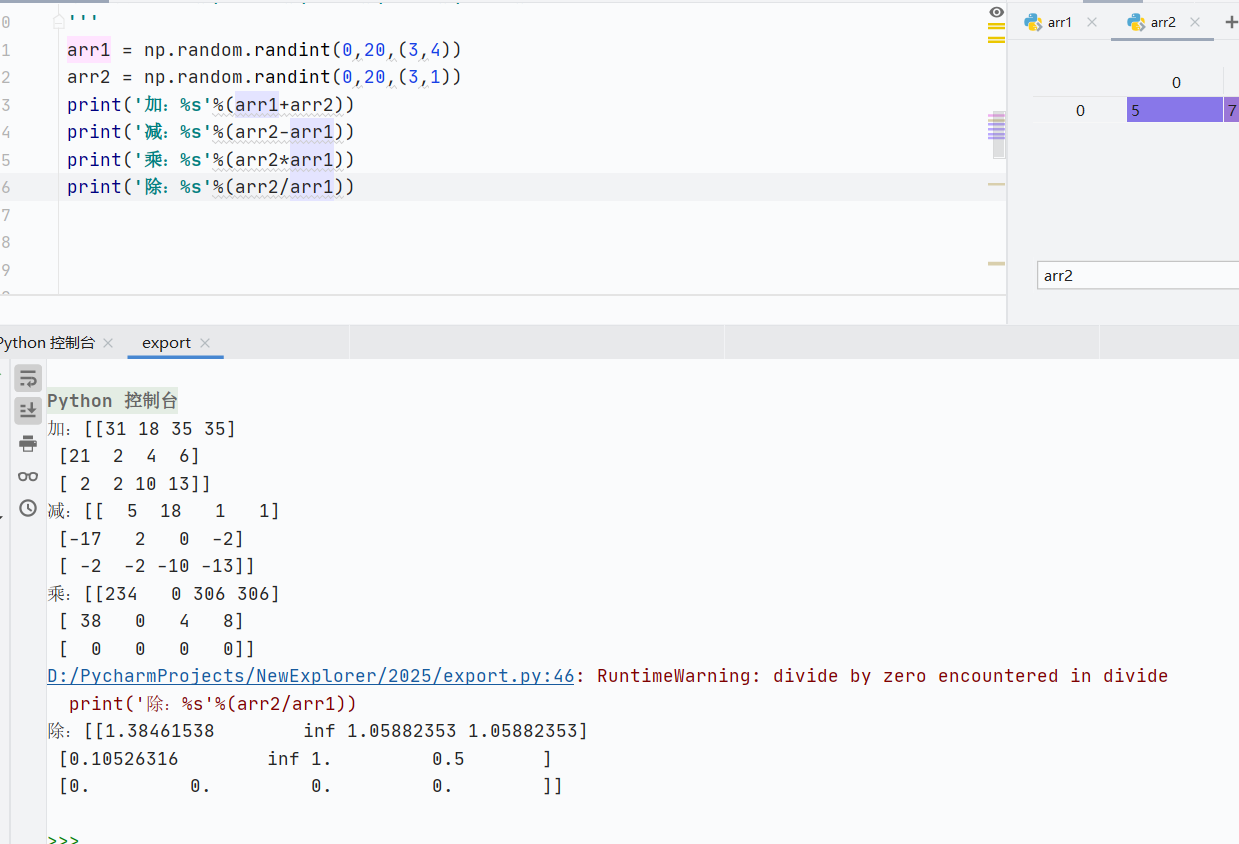
基礎數組運算
+,-,*,/,``
![]()
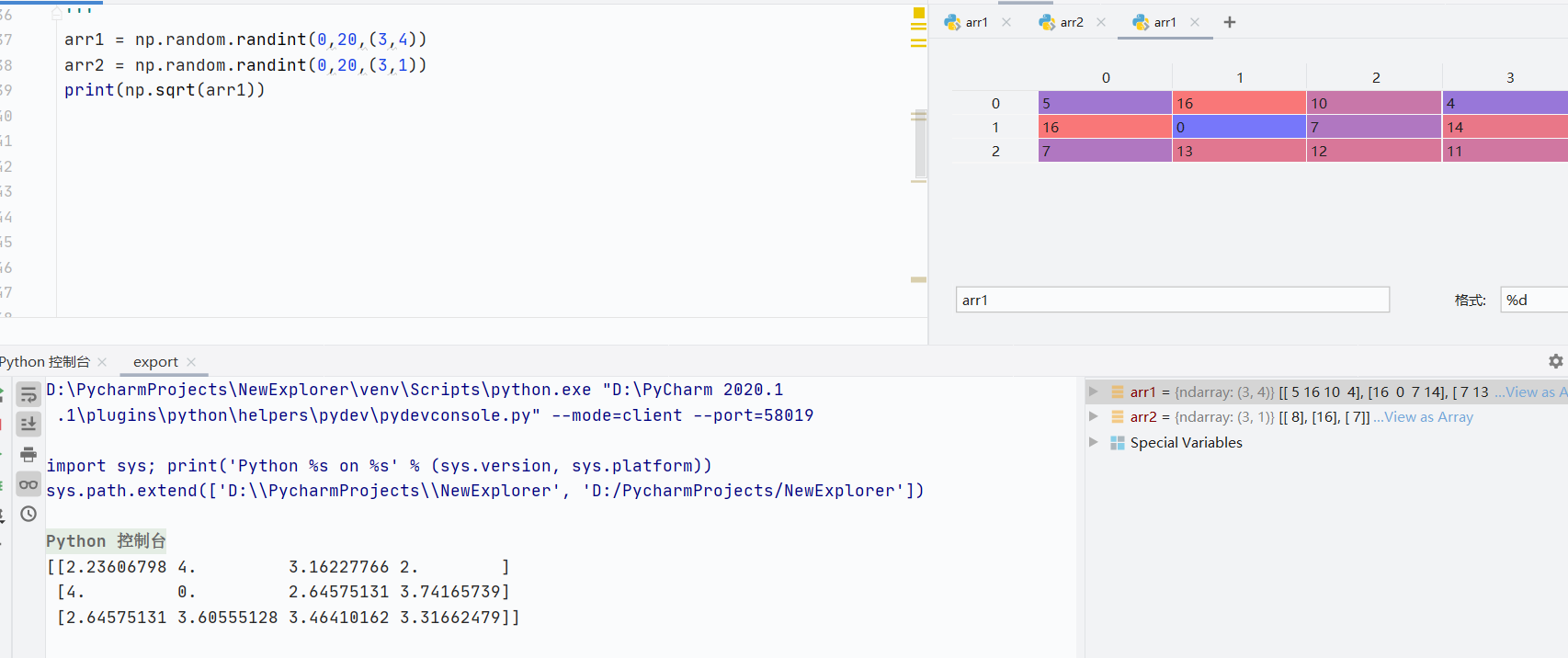
通用函數
-
np.sqrt()開根號
![]()
-
np.exp()指數
![]()
-
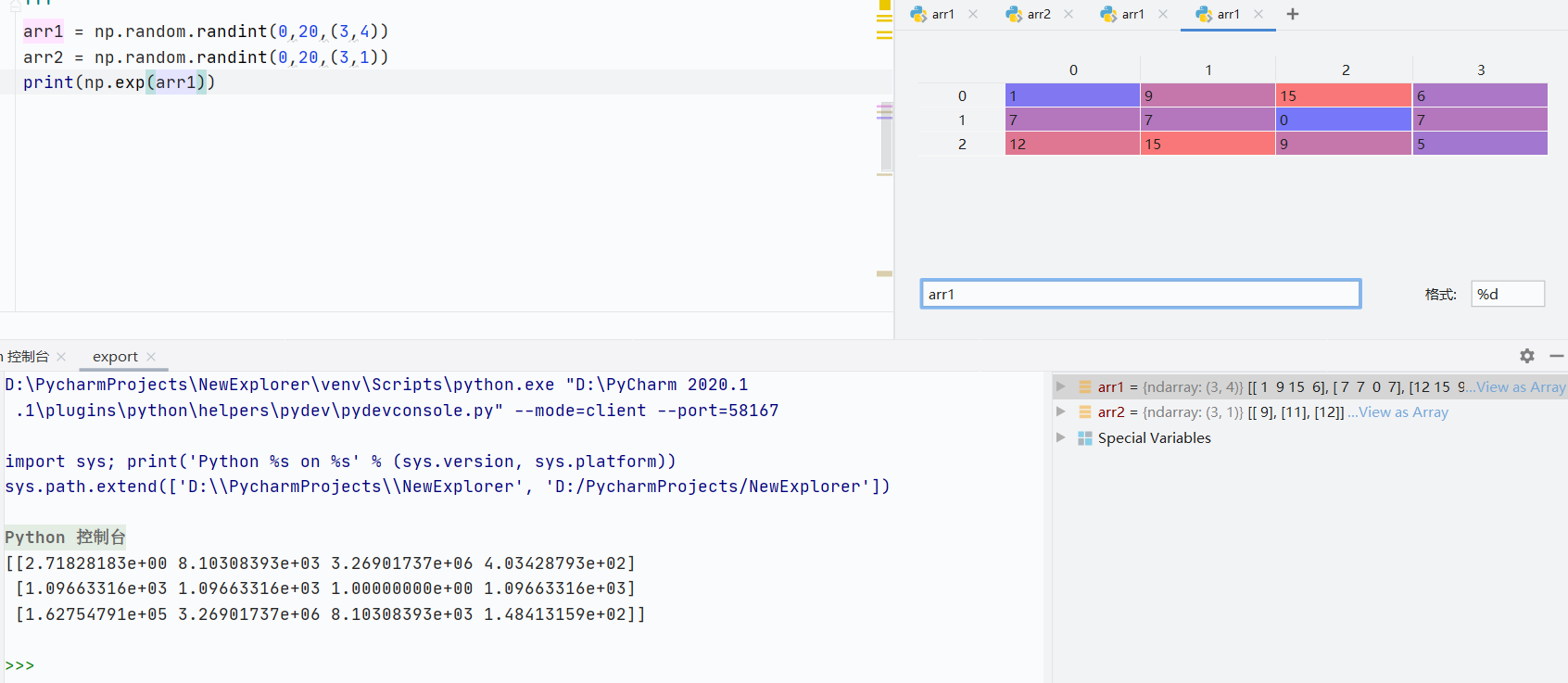
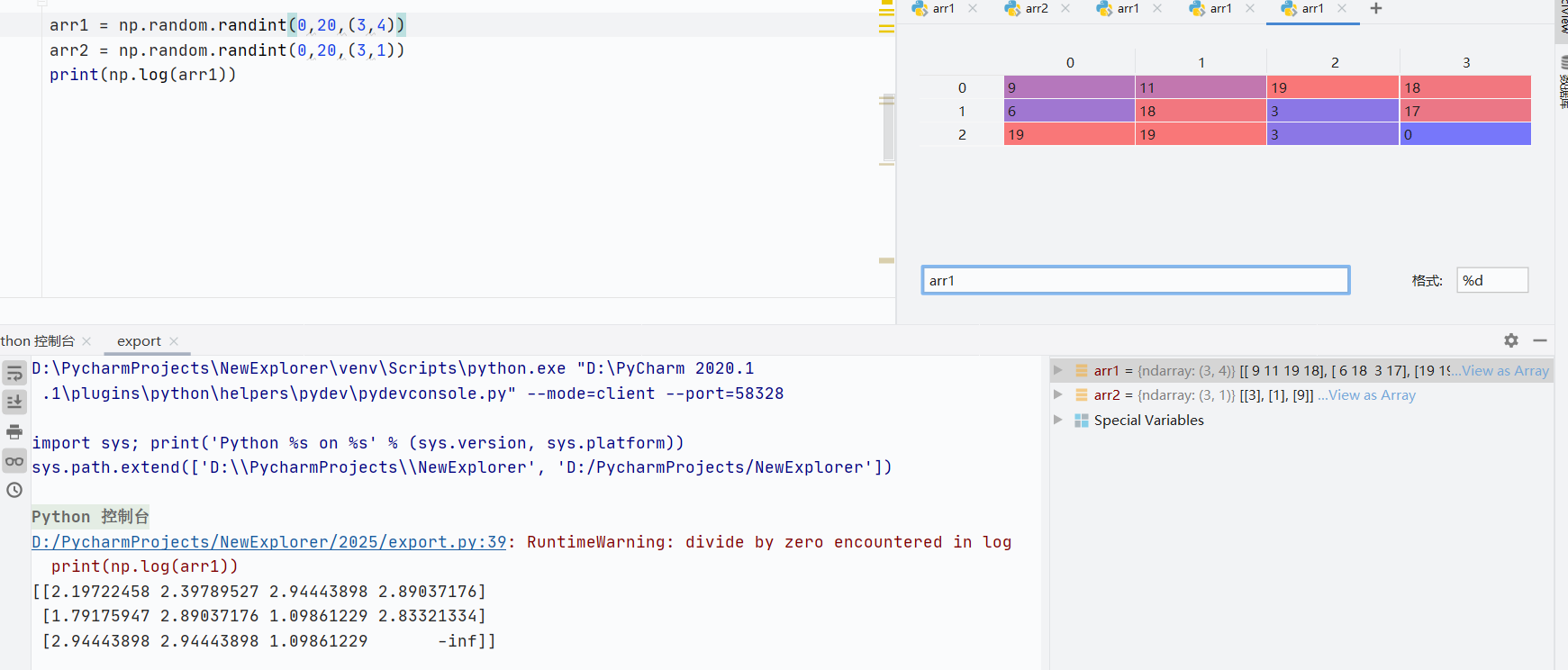
np.log()自然對數
![]()
聚合函數
-
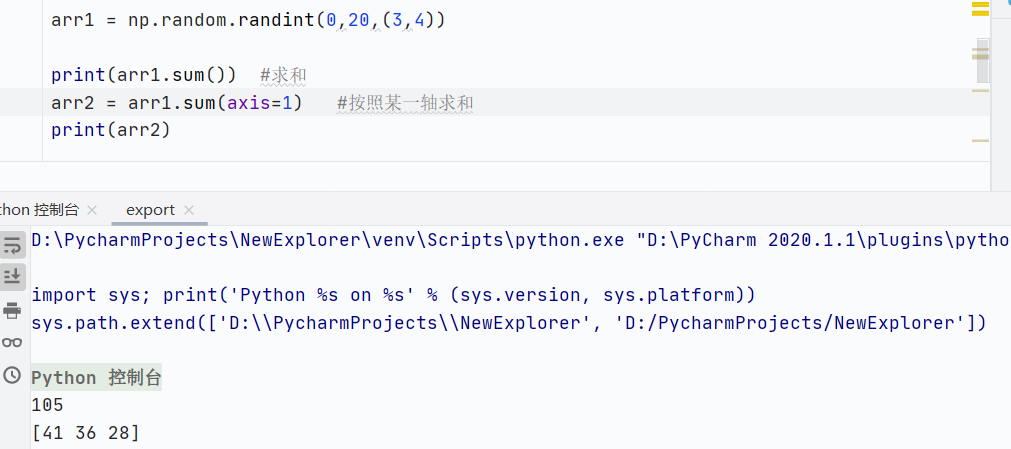
sum()求和
![]()
-
mean()平均值
![]()
-
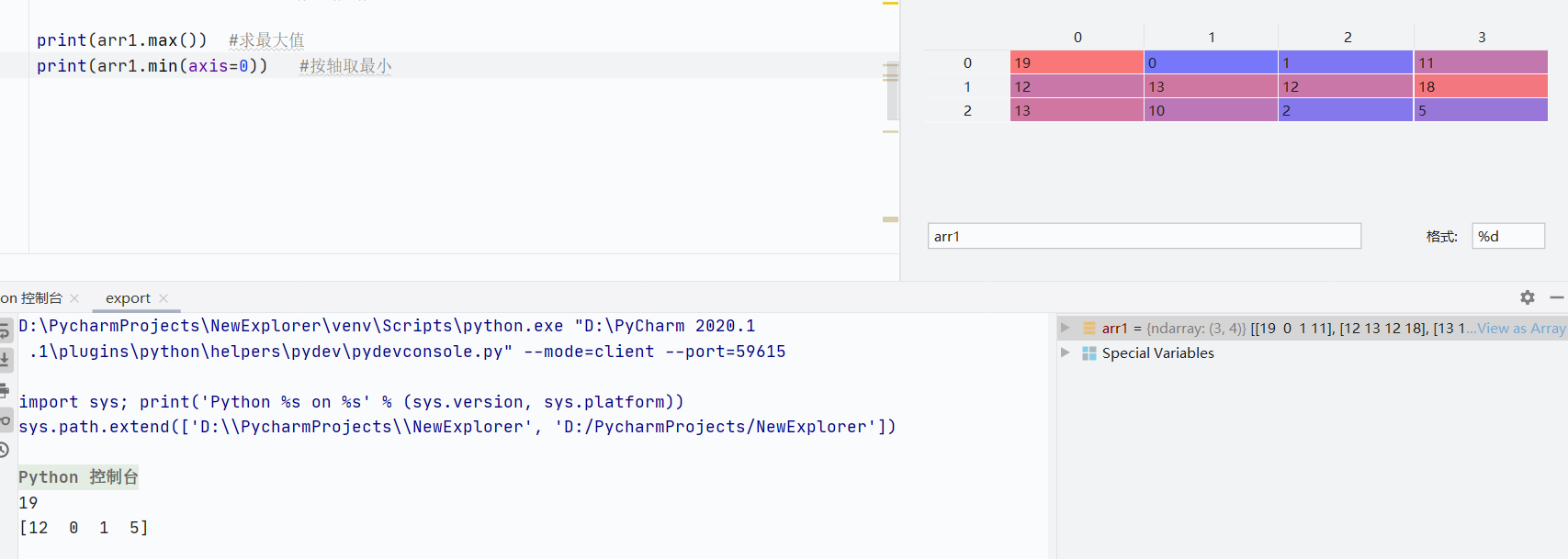
max()最大值np.min()最小值
![]()
-
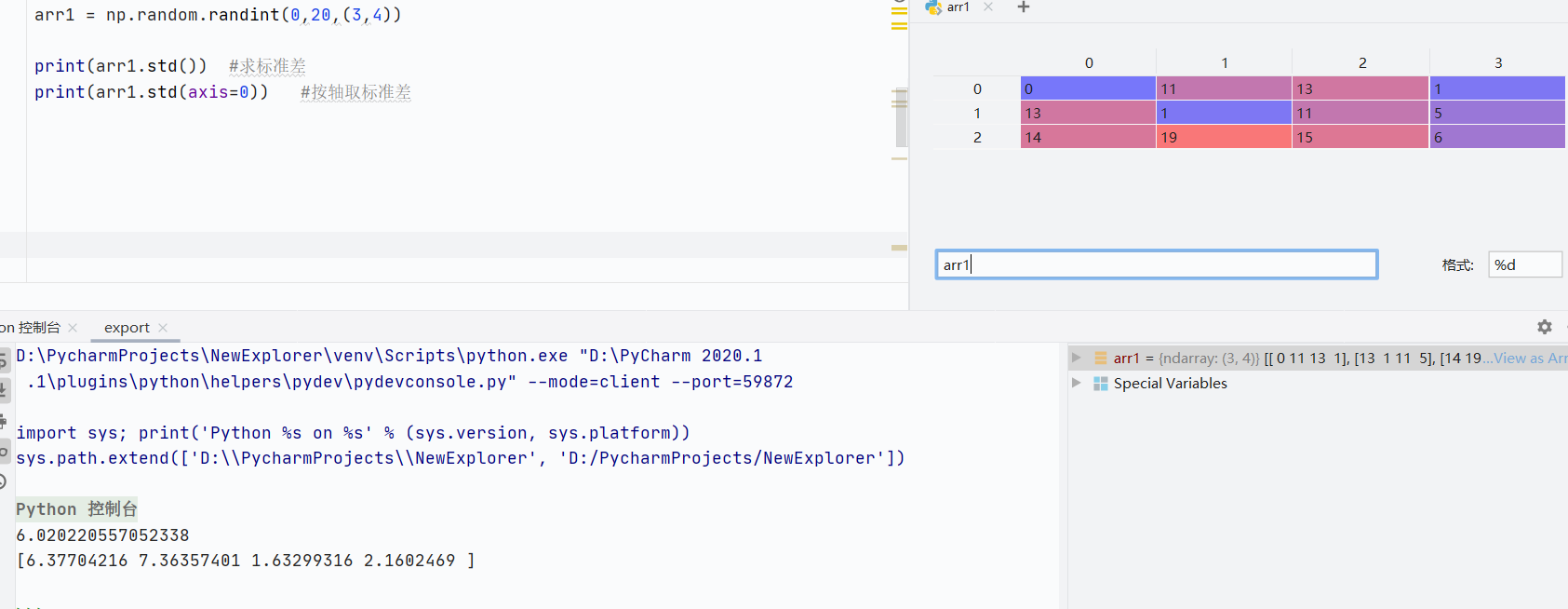
std()標準差
![]()

高級部分
高級索引
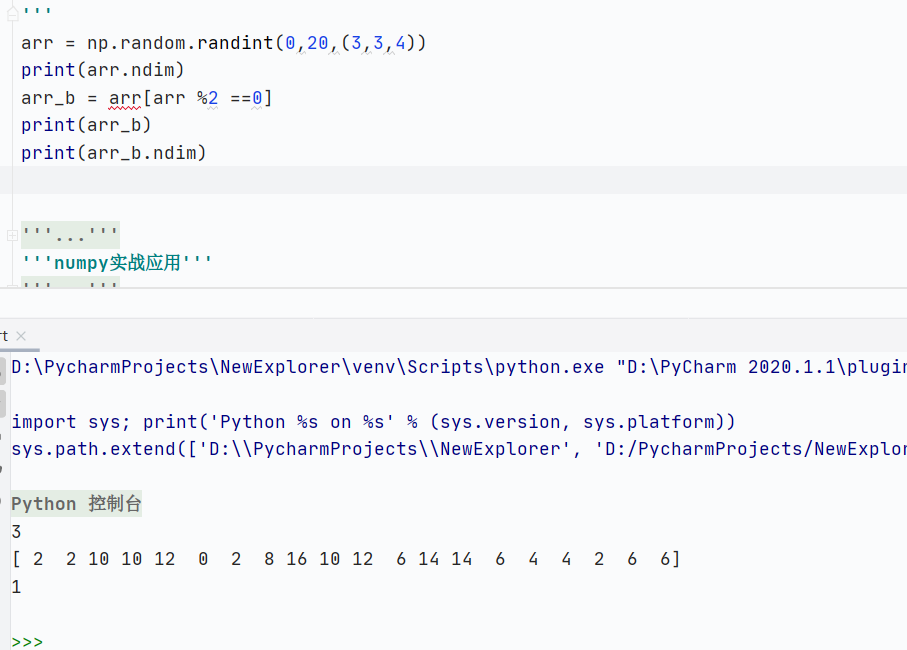
布爾索引
通過布爾條件(True/False)篩選數組中的元素
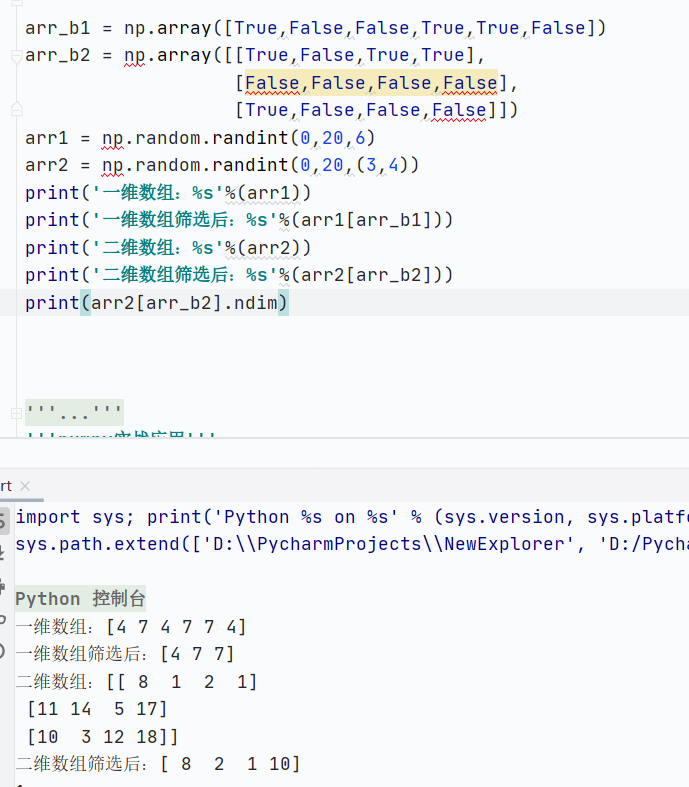
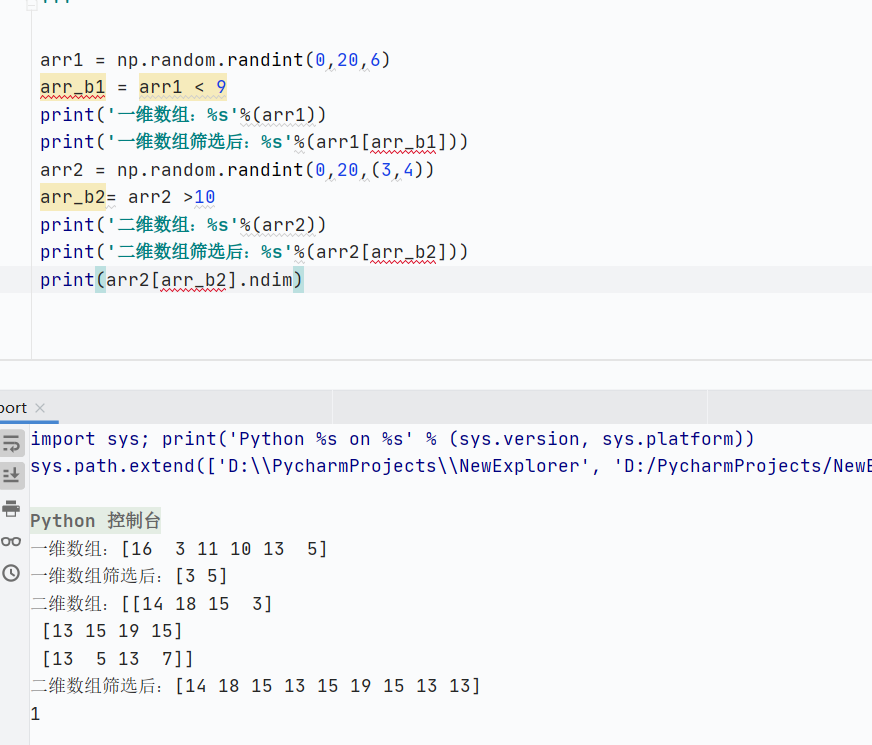
核心規則
布爾數組必須與目標數組的形狀相同
返回的是滿足條件(True)的元素
核心為題:NumPy 不支持直接用多維布爾數組索引多維數組,需逐層篩選
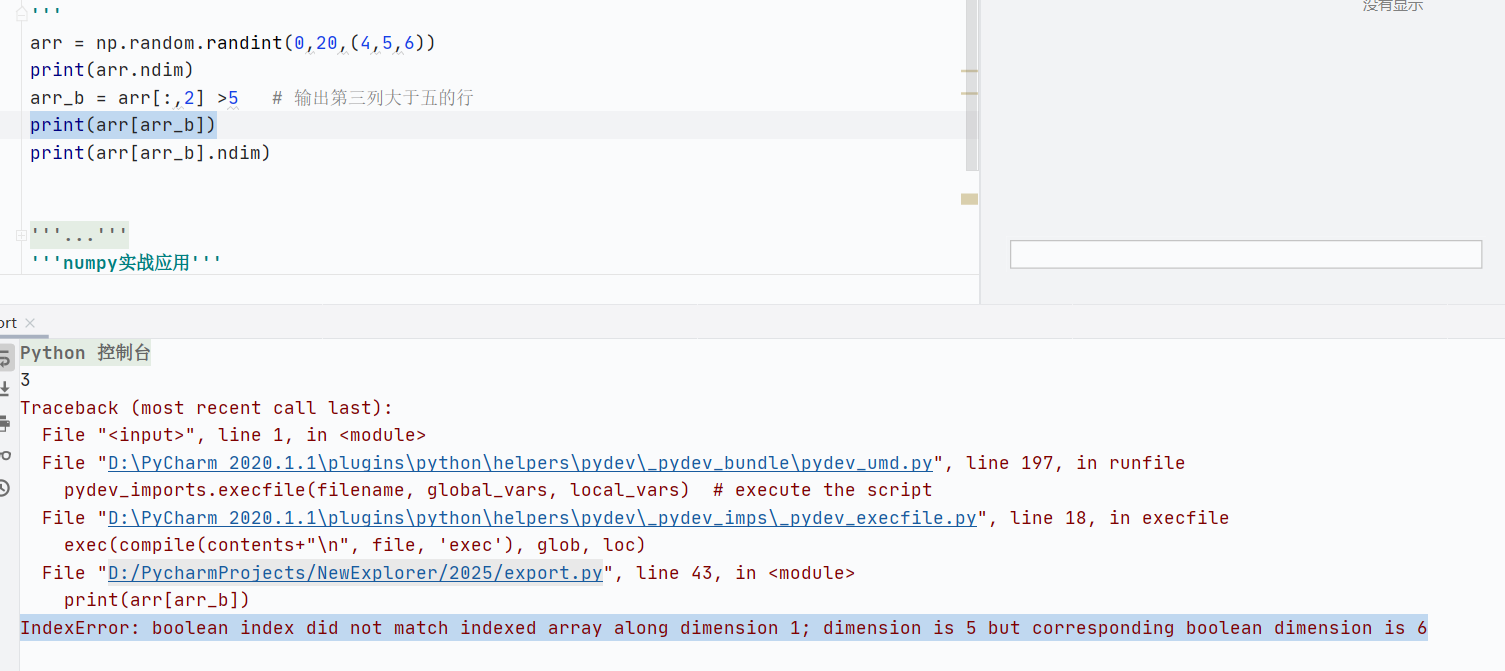
-
直接使用布爾數組
![]()
-
創建布爾掩碼判斷
![]()
-
直接使用條件表達式篩選
![]()
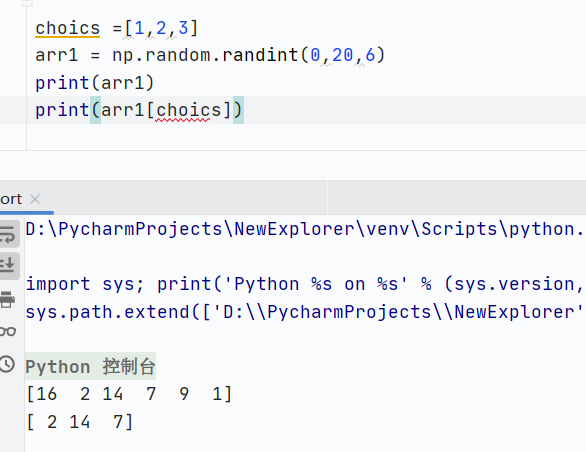
花式索引
通過整數數組(或列表)指定索引位置來訪問元素,它不依賴連續或規律的位置,可以靈活選擇任意位置的元素
核心規則:
傳遞一個整數數組作為左印,返回由這些位置元素組成的新數組
支持多維索引
-
一維數組
![]()
-
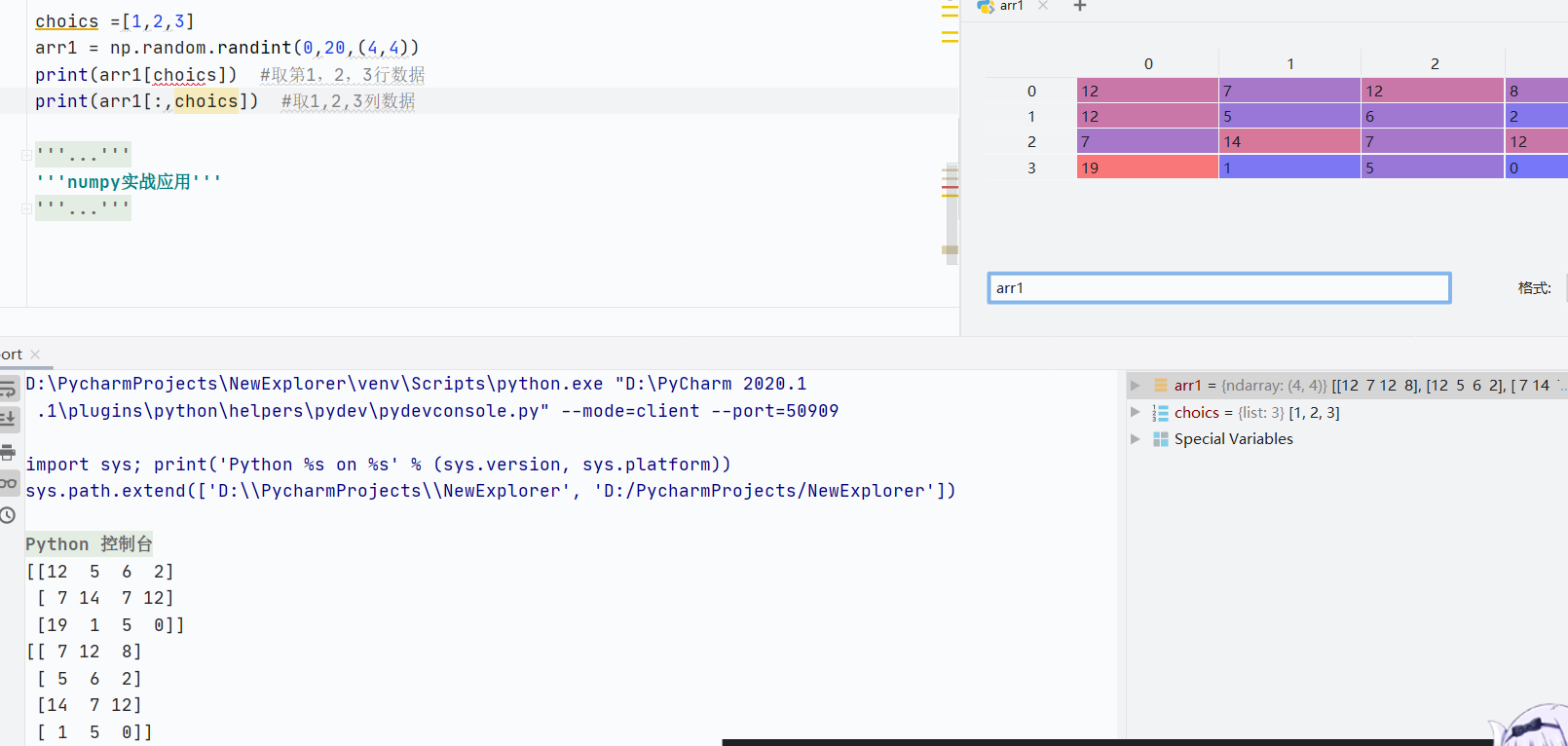
多維數組
![]()
-
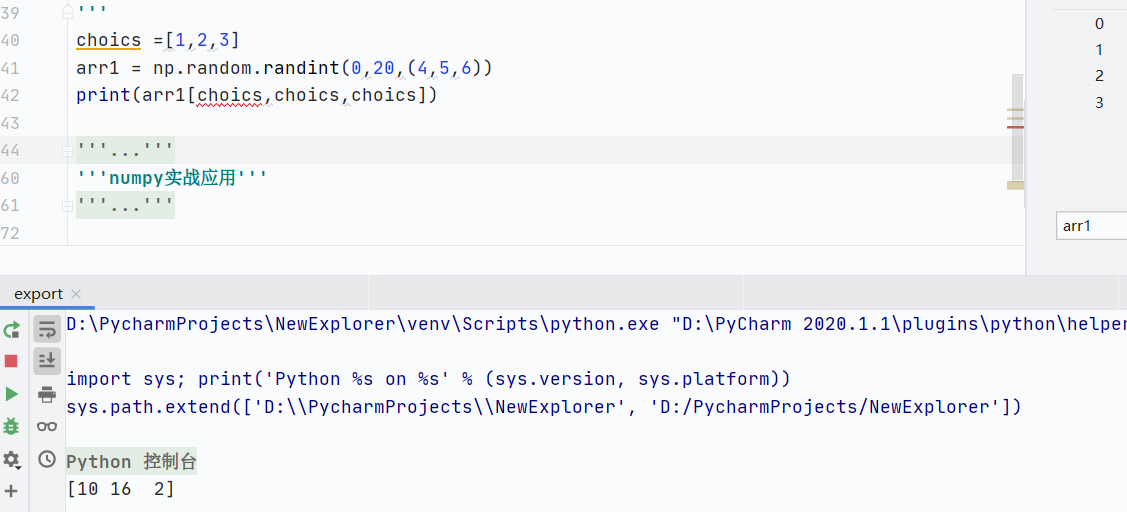
組合行列索引
![]()
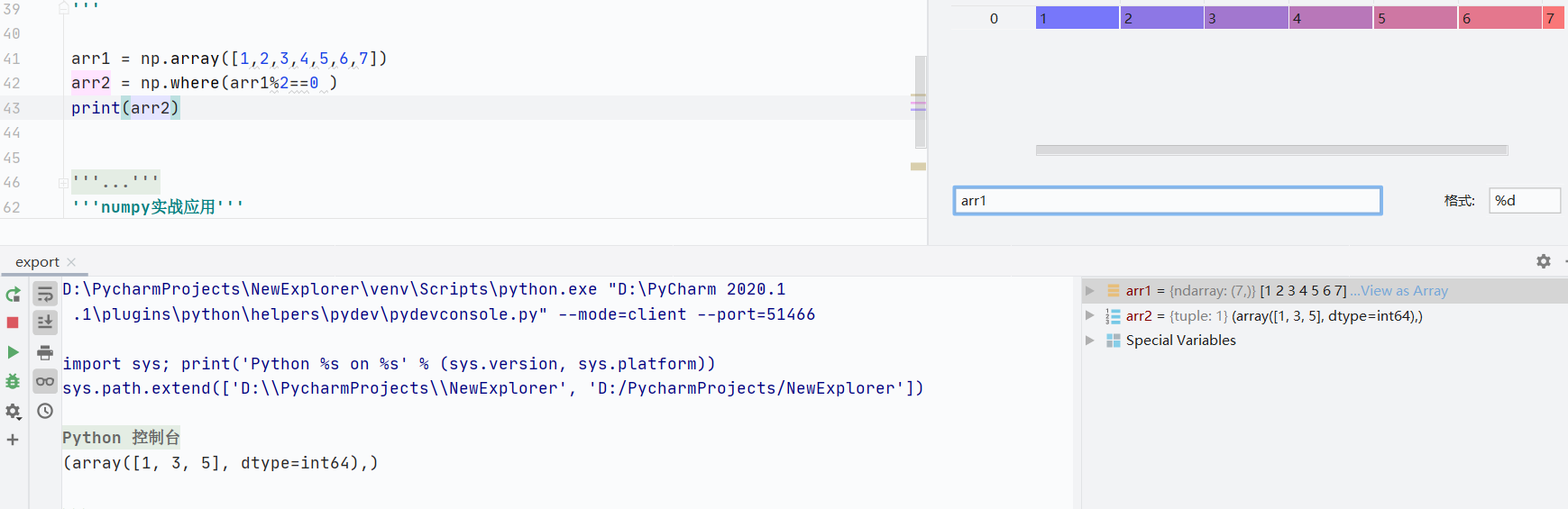
where()函數
根據條件返回滿足條件的元素索引或替換紙
-
返回滿足條件的索引
![]()
-
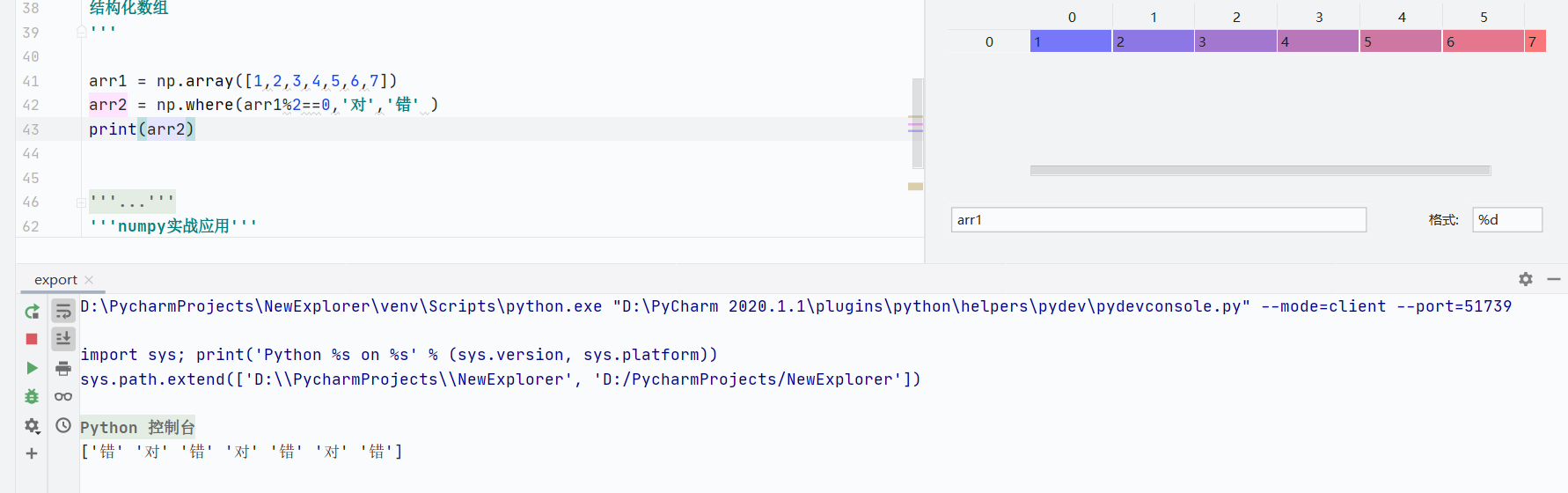
np.where(condition, value_if_true, value_if_false):條件替換
![]()
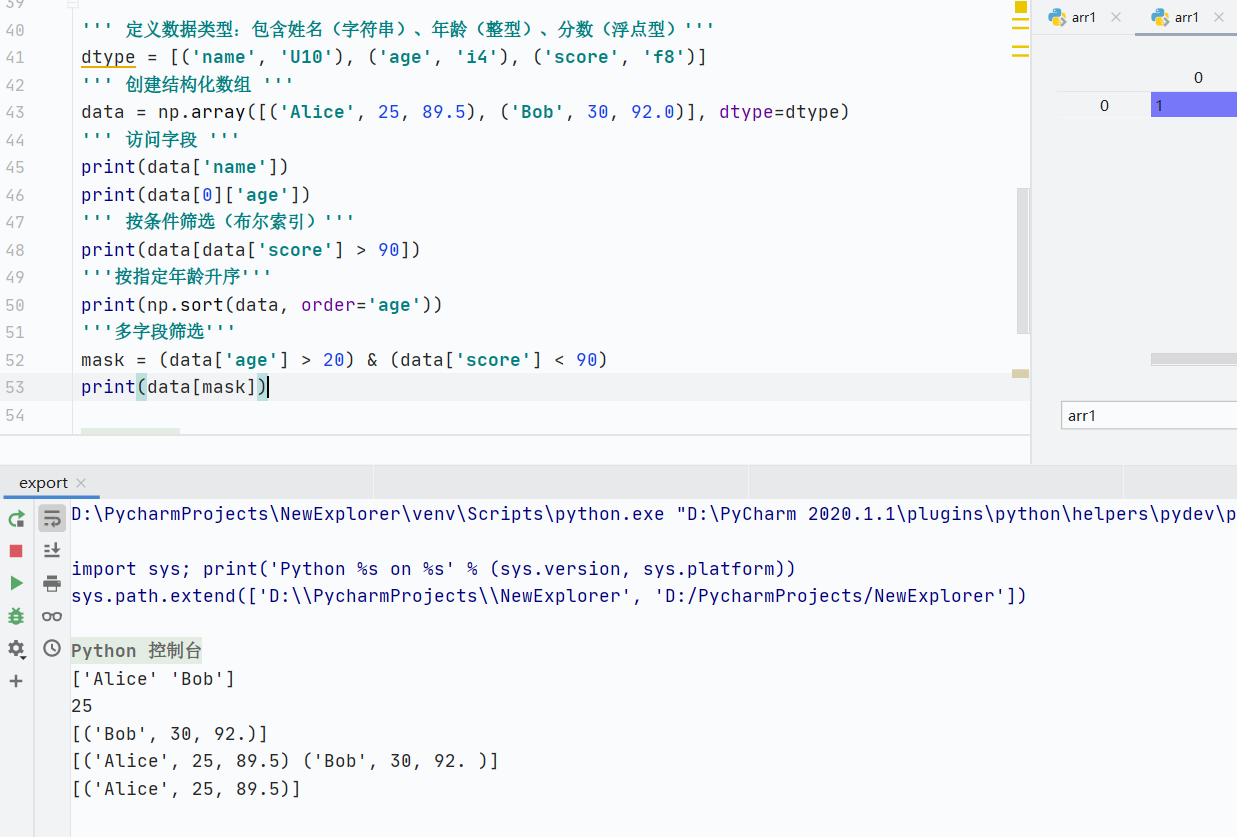
結構化數組
定義具有不同數據類型的數組,類似表格中的行
核心步驟:
定義數據類型:使用dtype指定每個字段的名稱和類型
創建結構化數組:通過指定字段初始化數組
''' 定義數據類型:包含姓名(字符串)、年齡(整型)、分數(浮點型)'''
dtype = [('name', 'U10'), ('age', 'i4'), ('score', 'f8')]
''' 創建結構化數組 '''
data = np.array([('Alice', 25, 89.5), ('Bob', 30, 92.0)], dtype=dtype)
''' 訪問字段 '''
print(data['name'])
print(data[0]['age'])
''' 按條件篩選(布爾索引)'''
print(data[data['score'] > 90])
'''按指定年齡升序'''
print(np.sort(data, order='age'))
'''多字段篩選'''
mask = (data['age'] > 20) & (data['score'] < 90)
print(data[mask])
性能優化
向量化操作 VS 循環
向量化的本質:將操作從“逐個處理元素”變為“批量處理整個數組”,底層通過優化的 C/Fortran 代碼和 CPU 的 SIMD 指令(單指令多數據)并行計算。
-
向量化操作
利用numpy內置底層C/Fortran 實現的高效函數,直接對整個數組進行操作。 -
循環
通過 Python 層級的 for 循環逐個處理元素,效率極低
內存布局:C順序 VS F順序
-
C順序
內存中相鄰的行元素連續存儲(如 arr[i, j] 和 arr[i, j+1] 相鄰) -
F 順序(列優先)
內存中相鄰的列元素連續存儲(如 arr[i, j] 和 arr[i+1, j] 相鄰)
視圖與副本
-
視圖(View)
- 共享原始數組的數據內存,不復制數據
- 修改視圖會影響原始數組
- 常見操作:切片,轉置,重塑形狀
-
副本(Copy)
- 完全獨立的新數組,復制數據導新內存
- 修改副本不影響原始數組
- 常見操作:顯示調用,高級索引等
輸入輸出
保存和加載數組;二進制格式(.npy,.npz)
-
np.save()保存;np.load()加載- 保存單個數組為
.npy二進制文件(保留形狀和數據類型) - 加載時回復數組原裝
- 保存單個數組為
-
np.savez()保存;np.load()加載- 保存多個數組導
.npz壓縮文件(類似字典格式) - 可指定關鍵字命名數組
- 保存多個數組導
文本文件;不規則數據(如每行列數不同)則失敗
-
np.loadtxt()讀取文本文件常用參數:
delimiter:分隔符dtype:指定數據類型skiprows:跳過N行usecols:選擇特定列
-
np.savetxt()寫入文本文件常用參數:
fmt:格式字符串(如 '%.2f' 保留兩位小數)header:文件頭部注釋
內存映射文件
用途:
- 處理超大型數組(無法一次性加載到內存)
- 多進程共享數據:不同進程可訪問同一內存映射文件
import numpy as np
# 創建一個內存映射文件(如果文件不存在則初始化)
shape = (1000, 1000)
dtype = np.float32
filename = 'large_array.dat'
# 創建或加載內存映射
mmap_arr = np.memmap(filename, dtype=dtype, mode='w+', shape=shape)
# 寫入數據(延遲到文件關閉或刪除對象時同步)
mmap_arr[:10, :10] = np.random.rand(10, 10)
# 顯式同步到磁盤(可選)
mmap_arr.flush()
# 重新以只讀模式打開
mmap_readonly = np.memmap(filename, dtype=dtype, mode='r', shape=shape)

 浙公網安備 33010602011771號
浙公網安備 33010602011771號