
Python-pandas庫學習
一、什么是Pandas庫
(1)、Pandas 應用
Pandas 可以從各種文件格式比如 CSV、JSON、SQL、Excel 導入數據。
Pandas 可以對各種數據進行運算操作,比如歸并、再成形、選擇,還有數據清洗和數據加工特征。
Pandas 廣泛應用在學術、金融、統計學等各個數據分析領域。
(2)、Pandas 功能
Pandas 是數據分析的利器,它不僅提供了高效、靈活的數據結構,還能幫助你以極低的成本完成復雜的數據操作和分析任務。
Pandas 提供了豐富的功能,包括:
- 數據清洗:處理缺失數據、重復數據等。
- 數據轉換:改變數據的形狀、結構或格式。
- 數據分析:進行統計分析、聚合、分組等。
- 數據可視化:通過整合 Matplotlib 和 Seaborn 等庫,可以進行數據可視化。
(3)、數據結構
Pandas 的主要數據結構是 Series (一維數據)與 DataFrame(二維數據)。
-
Series 是一種類似于一維數組的對象,它由一組數據(各種 Numpy 數據類型)以及一組與之相關的數據標簽(即索引)組成。
-
DataFrame 是一個表格型的數據結構,它含有一組有序的列,每列可以是不同的值類型(數值、字符串、布爾型值)。DataFrame 既有行索引也有列索引,它可以被看做由 Series 組成的字典(共同用一個索引)。
二、安裝pandas庫
(1)、在終端中運行
pip install pandas
(2)、導入Pandas庫并重命名為pd
import pandas as pd # 查看pandas版本 print(pd.__version__)
輸出: 2.2.3
三、操作教學
1.基礎操作
我想存儲一些人的信息和對應的數據
import pandas as pd df = pd.DataFrame( { "Name": ["Alice", "Bob", "Charlie"], "Age": [25, 30, 35], "City": ["New York", "Los Angeles", "Chicago"] } ) print(df)
打印的結果:

DataFrame是一個二維數據結構,可以存儲 不同類型的 (包括字符、整數、浮點值、 分類數據等)。它類似于電子表格,每一行都有自己的列標簽和值
2.拿取指定列的數據
print(df['City'])
打印的結果:

3.從頭開始創建DataFrame
a = pd.Series(["黑色", "紅色", "白色"], name="color") print(a)
打印的結果:

4.DataFrame的統計數據
df = pd.DataFrame( { "Name": ["Alice", "Bob", "Charlie"], "Age": [25, 30, 35], "City": ["New York", "Los Angeles", "Chicago"] } ) print(df.describe())
結果為:

5.分析csv文件中的數據
csv文件內容如下:
|
TABLE_SCHEMA |
TABLE_NAME |
ENGINE |
VERSION |
DATA_LENGTH |
CREATE_TIME |
|
information_schema |
CHARACTER_SETS |
MEMORY |
10 |
0 |
2025/3/10 10:04 |
|
information_schema |
COLLATIONS |
MEMORY |
10 |
0 |
2025/3/10 10:04 |
|
information_schema |
COLUMNS |
InnoDB |
10 |
16384 |
|
|
information_schema |
COLUMN_PRIVILEGES |
MEMORY |
10 |
0 |
2025/3/10 10:04 |
|
information_schema |
ENGINES |
MEMORY |
10 |
0 |
2025/3/10 10:04 |
|
information_schema |
EVENTS |
InnoDB |
10 |
16384 |
|
|
information_schema |
FILES |
MEMORY |
10 |
0 |
2025/3/10 10:04 |
|
information_schema |
GLOBAL_STATUS |
MEMORY |
10 |
0 |
2025/3/10 10:04 |
|
information_schema |
GLOBAL_VARIABLES |
MEMORY |
10 |
0 |
2025/3/10 10:04 |
|
information_schema |
KEY_COLUMN_USAGE |
MEMORY |
10 |
0 |
2025/3/10 10:04 |
只讀取數據
df = pd.read_csv("C:/Users/65742/Desktop/tables.csv") print(df)
結果為:

只想看前幾行的數據
df = pd.read_csv("C:/Users/65742/Desktop/tables.csv") print(df.head(8))
結果為:

分析每列的數據類型
df = pd.read_csv("C:/Users/65742/Desktop/tables.csv") print(df.dtypes)
結果為:

讀取更加詳細的數據
df = pd.read_csv("C:/Users/65742/Desktop/tables.csv") print(df.info)
結果為:

6.excel表格的操作
與csv同理,讀取方法換成read_excel()這個就可以了
import xlrd df = pd.read_excel("C:/Users/65742/Desktop/tables.xls") print(df)
注意: read_excel()需要依賴xlrd模塊,所以需要安裝xlrd。
7.選擇需要的列
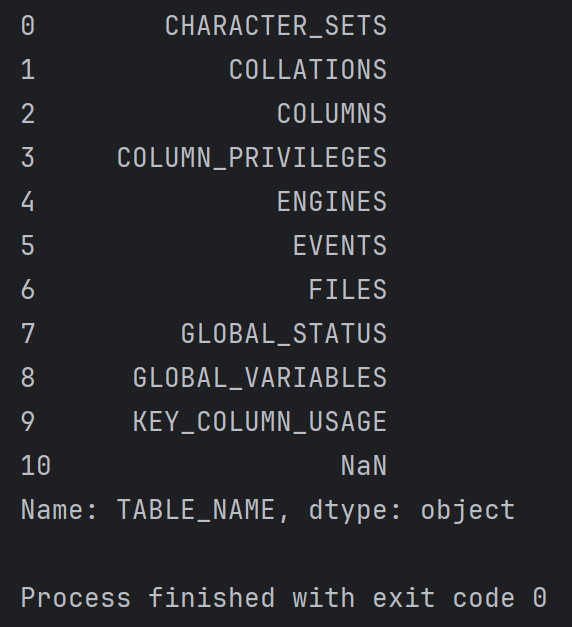
df = pd.read_csv("C:/Users/65742/Desktop/tables.csv") print(df['TABLE_NAME'])
結果為:
需要選擇多個列直接使用逗號拼接在中括號里面就OK了
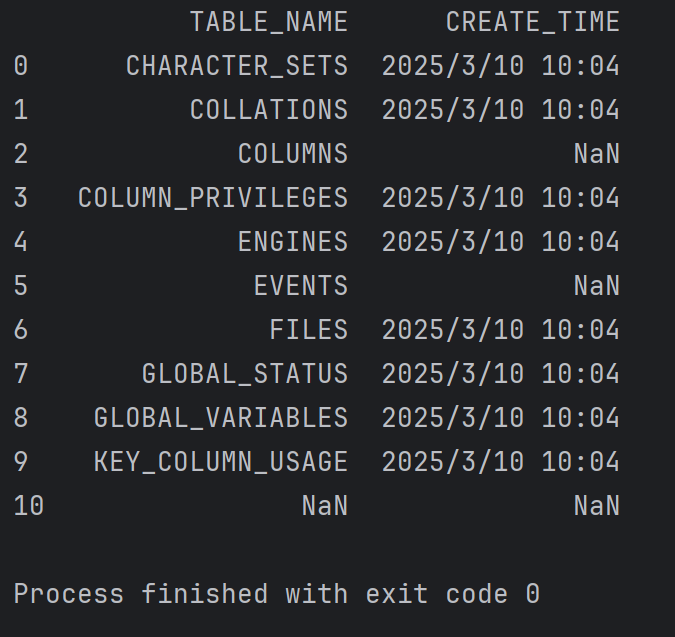
df = pd.read_csv("C:/Users/65742/Desktop/tables.csv") print(df[['TABLE_NAME', 'CREATE_TIME']])
結果為:
查看返回數據的行數以及列數
df = pd.read_csv("C:/Users/65742/Desktop/tables.csv") print(df[['TABLE_NAME']].shape)
結果為:

請注意,返回的數據包括行數和列數
篩選固定條件的數據
above_0 = df[df["DATA_LENGTH"] > 0] print(above_0)
結果為:

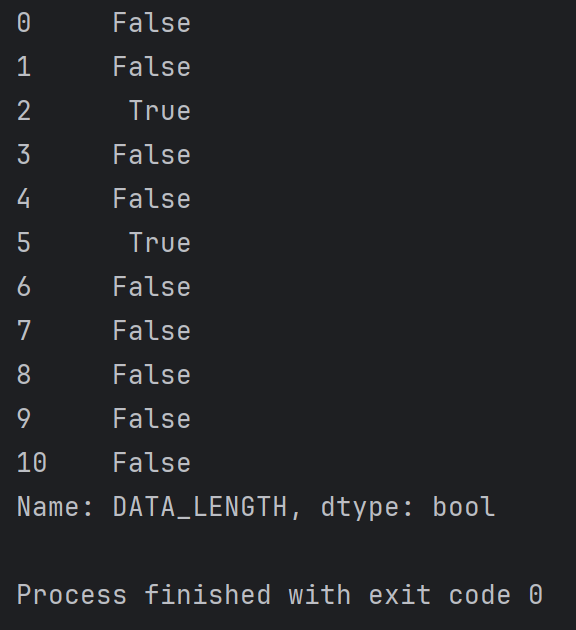
如果你想檢查數據是否大于某個值:
print(df["DATA_LENGTH"] > 0)
結果為:
查詢某個列中的多個值的數據
engine_select = df[df["ENGINE"].isin(['InnoDB', 'MEMORY'])] print(engine_select)
df[]中放置的是列名,isin中放的是感興趣的數據
結果為:

組合多個條件查詢
new_result = df[(df["ENGINE"] == 'InnoDB') | (df["TABLE_NAME"] == 'FILES')] print(new_result)
結果為:

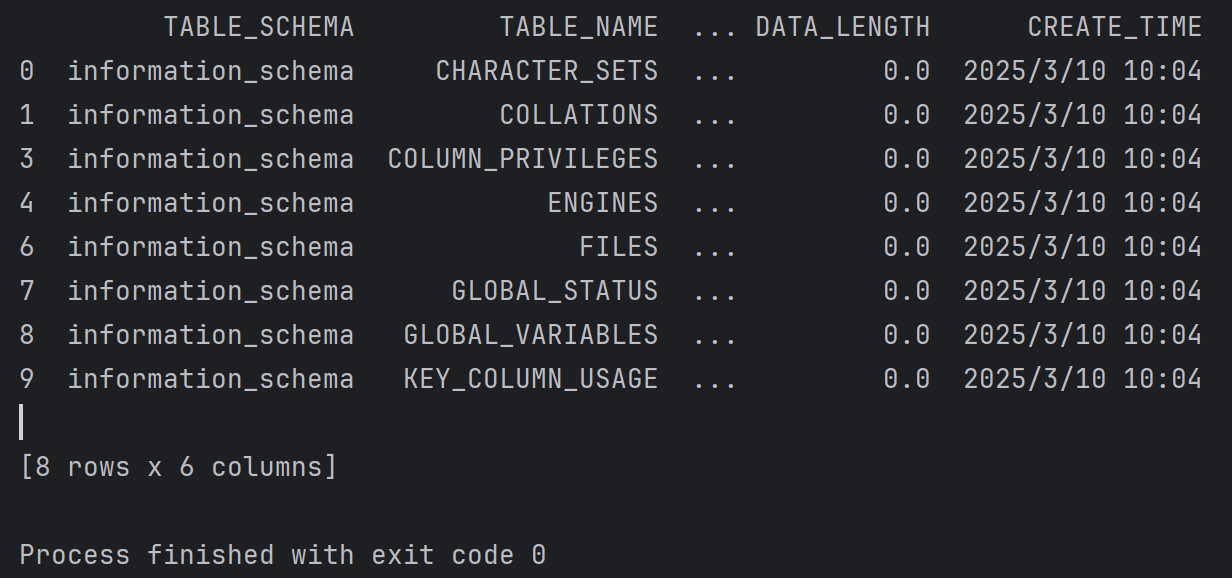
如果想驗證列中的數據是不是空值
create_time_not_na = df[df["CREATE_TIME"].notna()] print(create_time_not_na)
篩選出所有“CREATE_TIME”列不為缺失值(NaN)的行,并將結果存儲在一個新的 DataFrame 變量
結果為:
查詢某列符合條件的數據,并只取該行的數據某一列
table_names = df.loc[df["DATA_LENGTH"] > 0, "TABLE_NAME"] print(table_names)
結果為:

查詢特定行到特定行,特定列到特定列的數據
# 查詢第1到4行,第3到5列的數據
print(df.iloc[0:4, 2:5])
結果為:

切記:
選擇數據子集時,使用方括號。[]
在這些括號內,您可以使用單個列/行標簽、列表 的列/行標簽、標簽切片、條件表達式或 一個冒號。
使用行時選擇特定行和/或列 和列名稱。loc
使用 在表中的位置。iloc
您可以根據 / 為選擇分配新值。lociloc
8.增加列
df = pd.read_excel("C:/Users/65742/Desktop/tables.xls", sheet_name='tables') print(df) df["數據長度"] = df["DATA_LENGTH"]*100 # 增加一列 print(df)
等號前面為你要新增加的列名,后面是原本存在的列名,執行之后會幫我們新建一個列名“數據長度”。
結果為:

且等號后面的數據是可以和其他類的數據運算或者直接運算的
9.修改列名
df = pd.read_excel("C:/Users/65742/Desktop/tables.xls", sheet_name='tables') print(df) c = df.rename(columns={"TABLE_NAME": "表名"}) print(c)
columns中鍵值對里面的key是原表格中的列,value是要替換的列名
結果為:

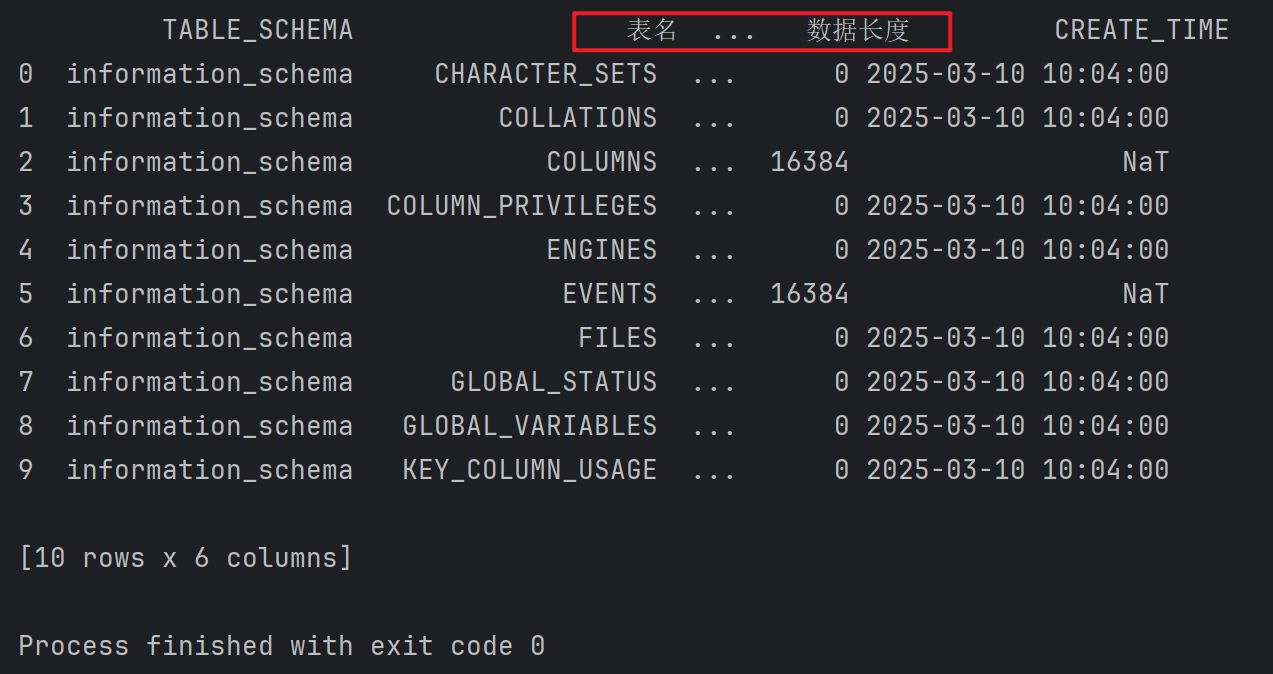
修改多個列的列名
c = df.rename(columns={"TABLE_NAME": "表名", "DATA_LENGTH": "數據長度"})
print(c)
結果為:
10.對數據進行分組并計算平均數
f = pd.DataFrame({ "name": ["吳昊", '趙括', "李月榮", "吳昊", "李月榮"], "age": [28, 32, 35, 30, 36], "gender": ["男", "女", "男", "男", "女"], "score": [92, 85, 98, 88, 95] }) print(f[["name","age","score"]].groupby("name").mean())
結果為:

本文來自博客園,作者:業余磚家,轉載請注明原文鏈接:http://www.rzrgm.cn/yeyuzhuanjia/p/18762234

 浙公網安備 33010602011771號
浙公網安備 33010602011771號