

消息隊(duì)列的存儲(chǔ)設(shè)計(jì),就看這一篇
基礎(chǔ)知識
一、零拷貝
目的:
1. 減少或避免不必要的CPU拷貝, 2. 減少用戶空間(應(yīng)用程序自己的空間)和內(nèi)核空間(linux內(nèi)核自身的空間,包括進(jìn)程調(diào)度、連接硬件資源、內(nèi)存分配等)的上下文切換, 3. 減少內(nèi)存的占用
典型應(yīng)用:
Netty、Kafka等
基本概念:
1. 緩沖區(qū):是所有I/O的基礎(chǔ),I/O 無非就是把數(shù)據(jù)移進(jìn)或移出緩沖區(qū)。
2. 虛擬內(nèi)存:通過虛擬技術(shù),將外部存儲(chǔ)設(shè)備的一部分空間,劃分給系統(tǒng),作為在內(nèi)存不足時(shí)臨時(shí)用作數(shù)據(jù)緩存。
3. 直接內(nèi)存訪問(Direct Memory Access)(DMA):DMA允許不同速度的硬件裝置來溝通,而不需要依于 CPU 的大量中斷負(fù)載,是一種可以大大減輕 CPU 工作量的數(shù)據(jù)轉(zhuǎn)移方式。基于 DMA 訪問方式,系統(tǒng)主內(nèi)存于硬盤或網(wǎng)卡之間的數(shù)據(jù)傳輸可以繞開 CPU 的調(diào)度。
額外提一下,RDMA(Remote Direct Memory Access):遠(yuǎn)程直接內(nèi)存訪問,允許遠(yuǎn)程訪問磁盤IO,減少CPU參與。
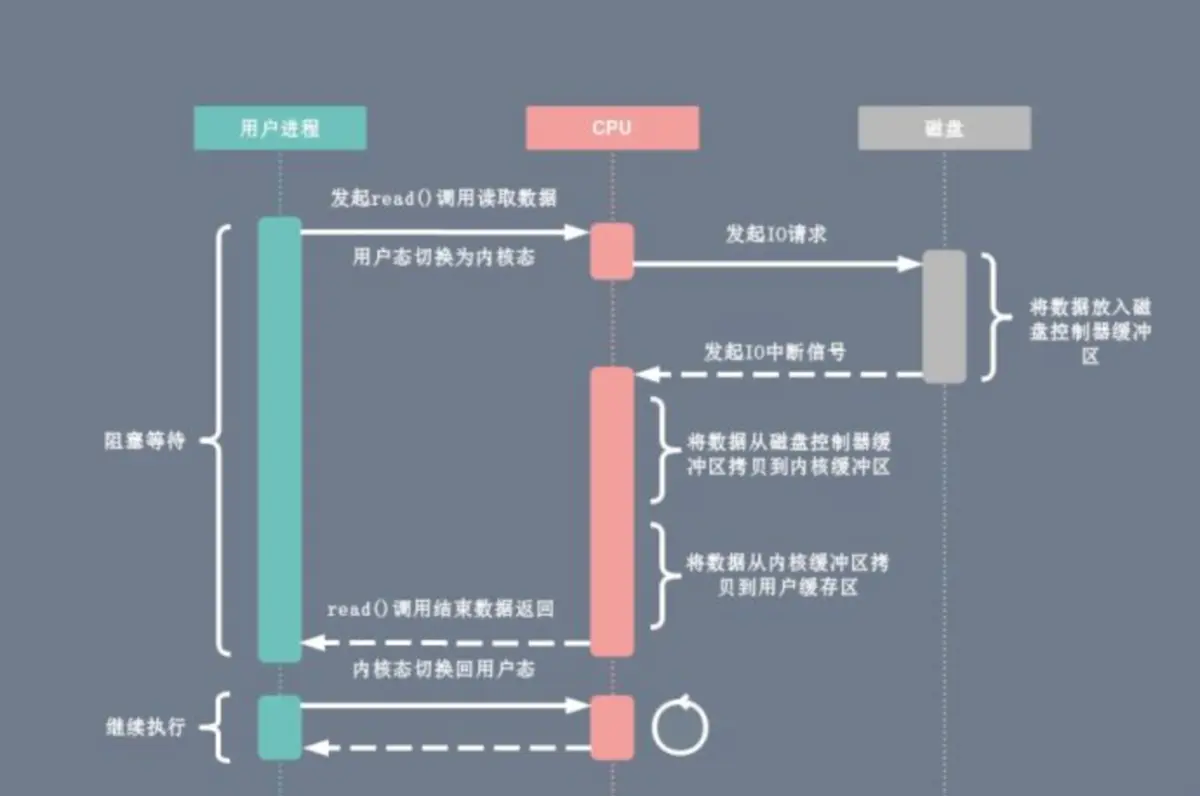 ------》
------》 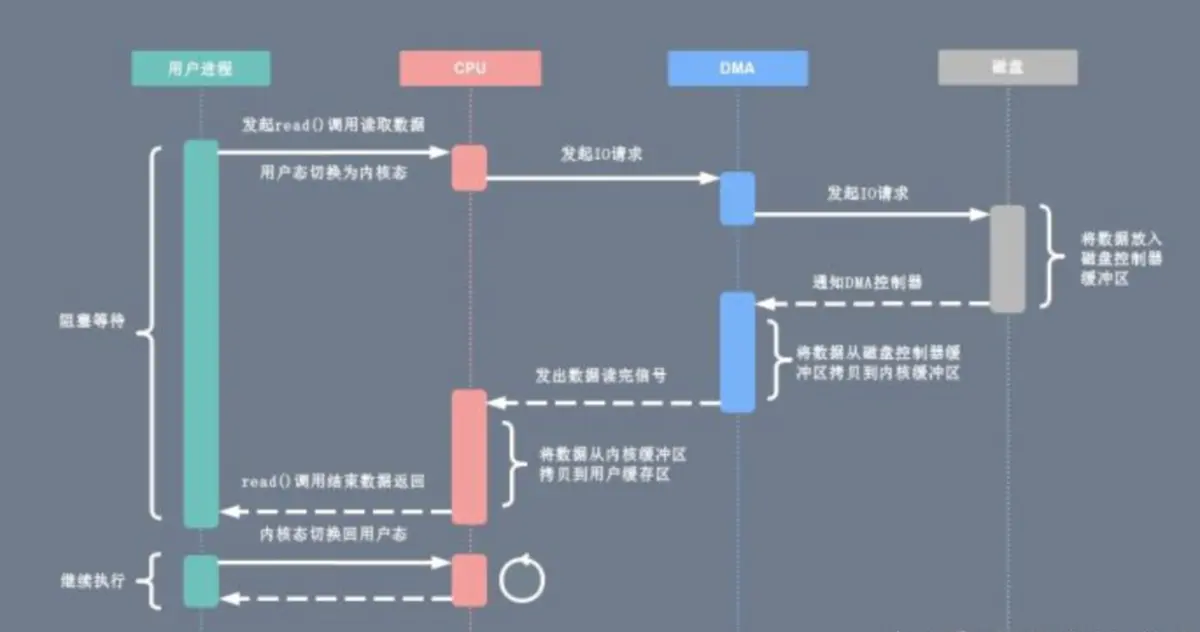
把磁盤控制器緩存區(qū)和內(nèi)核緩沖區(qū)之間的數(shù)據(jù)拷貝,由CPU轉(zhuǎn)移到DMA去做。通過 DMA 和虛擬內(nèi)存技術(shù),我們實(shí)現(xiàn)了 Zero Copy 的目標(biāo),IO 設(shè)備跟用戶程序空間傳輸數(shù)據(jù)的過程中,減少數(shù)據(jù)拷貝次數(shù),減少系統(tǒng)調(diào)用,實(shí)現(xiàn) CPU 的零參與,徹底消除 CPU 在這方面的負(fù)載。(圖片來源網(wǎng)絡(luò),鏈接建參考)
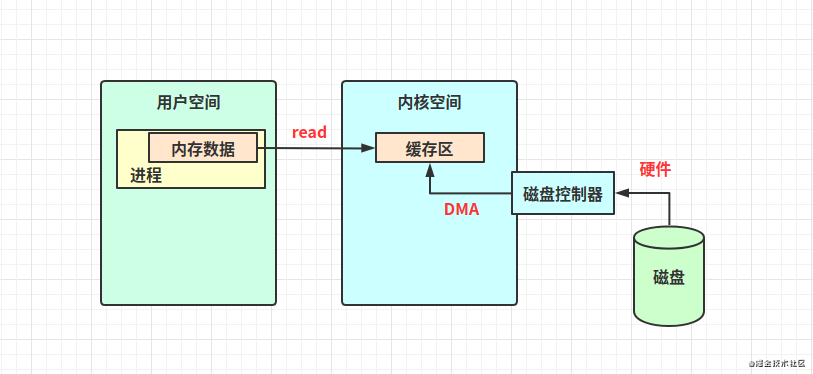
見下圖:把內(nèi)核空間地址和用戶空間的虛擬地址映射到同一個(gè)物理地址(下圖物理內(nèi)存藍(lán)色區(qū)塊),這樣DMA就可以填充(讀寫)對內(nèi)核和用戶空間進(jìn)程同時(shí)可見的緩沖區(qū)了。
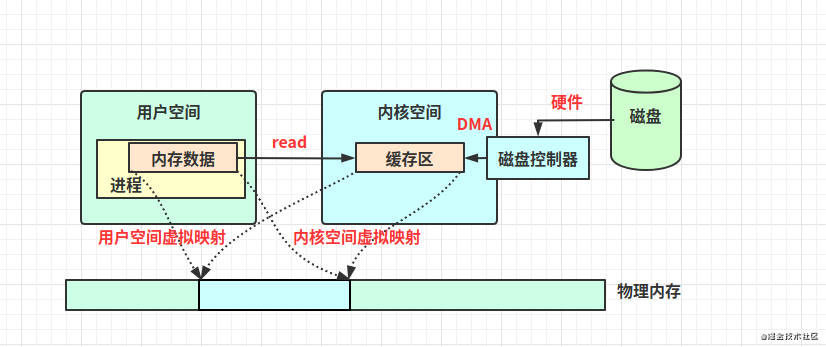 (來源網(wǎng)絡(luò))
(來源網(wǎng)絡(luò))
傳統(tǒng)IO
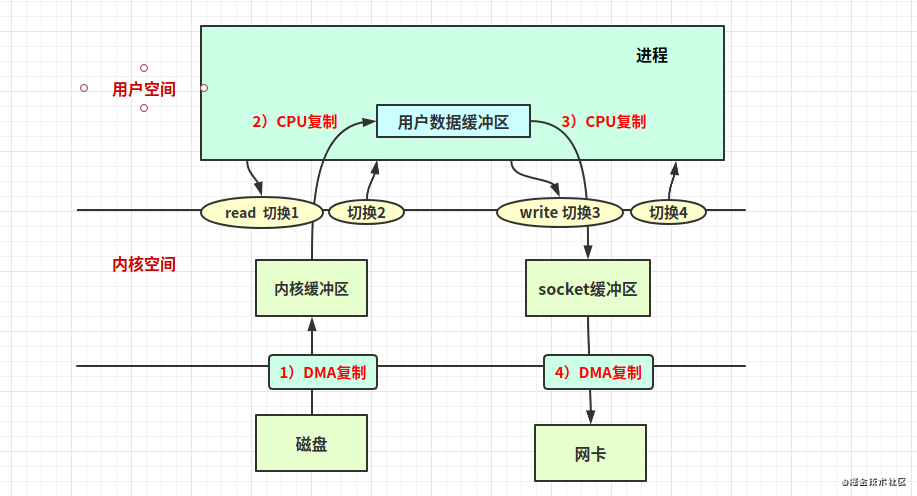
(說明:應(yīng)用進(jìn)程的堆內(nèi)和堆外內(nèi)存都在用戶空間)
4次用戶態(tài)到內(nèi)核態(tài)上下文切換、4次拷貝(2次CPU復(fù)制)。
零拷貝可以通過FileChannel的sendfile或者mmap+write方式實(shí)現(xiàn),減少用戶空間和內(nèi)核空間之間的內(nèi)存拷貝/CPU復(fù)制/上下文切換。
mmap+write實(shí)現(xiàn)的零拷貝
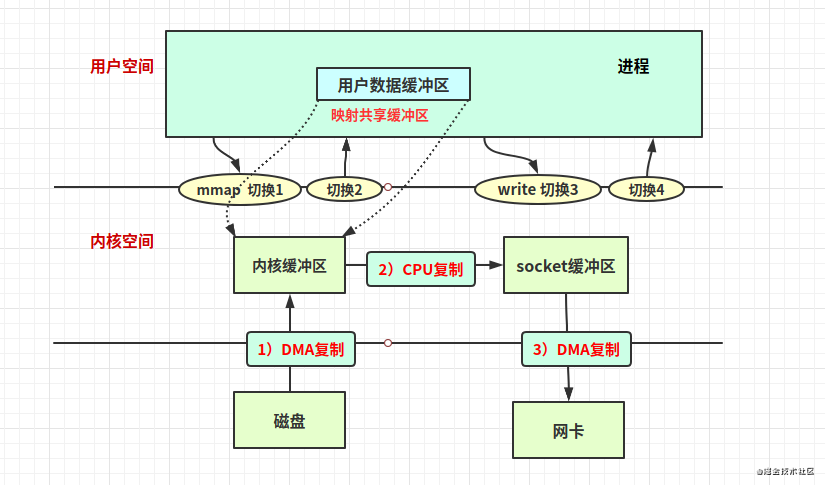
用戶空間和內(nèi)核空間映射
4次用戶態(tài)到內(nèi)核態(tài)的上下文切換、3次拷貝(其中一次CPU復(fù)制)。
sendfile實(shí)現(xiàn)的零拷貝
(有文檔介紹說linux 內(nèi)核2.6以后版本不支持sendfile)
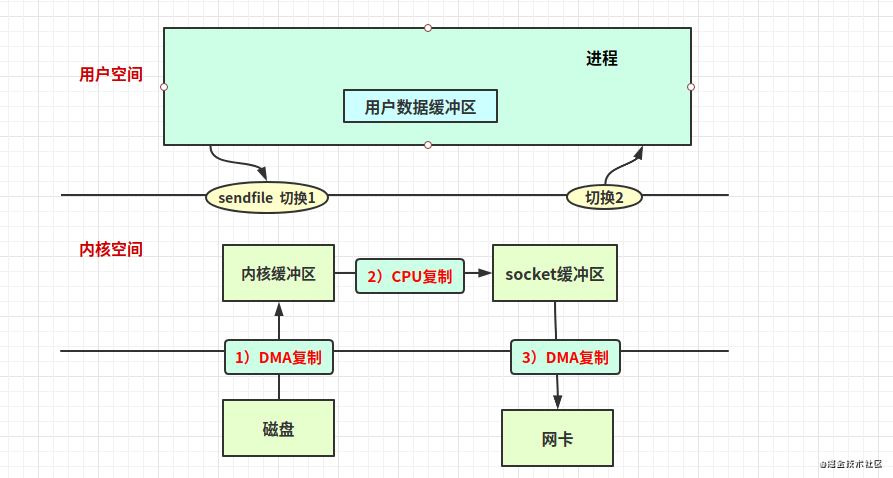
2次上下文切換、3次拷貝(其中1次CPU復(fù)制)。
對比:
mmap+write方式多了2次mmap/write用戶態(tài)到內(nèi)核態(tài)的上下文切換,他們比傳統(tǒng)IO(fileInputstream.write/read方式)少1次CPU復(fù)制(都用DMA復(fù)制的情況下)。
DMA復(fù)制,減少了2次磁盤和內(nèi)核數(shù)據(jù)傳輸導(dǎo)致的CPU占用。
二、Page Cache
Page cache是通過將磁盤中的數(shù)據(jù)緩存到內(nèi)存中,為了減少磁盤I/O操作,提高性能。
由物理page組成,內(nèi)容對應(yīng)磁盤的block。大小是動(dòng)態(tài)變化的,可以擴(kuò)大,也可以在內(nèi)存不足時(shí)縮小。一個(gè)page通常包括多個(gè)block。
page cache可以大大加快文件的讀寫速度,一次讀取或?qū)懭?strong>4k的數(shù)據(jù),節(jié)省連接的各種開銷。程序?qū)?shù)據(jù)先寫入page cache,在fsync到磁盤(page cache回寫)中。
但是,一旦斷電或者是故障,數(shù)據(jù)會(huì)丟失,沒辦法保障數(shù)據(jù)安全。
page cache會(huì)根據(jù)策略刷入磁盤,比如,2G內(nèi)存,規(guī)定50%刷入磁盤,超過1G后就會(huì)將page cache刷入磁盤。如果不足1G,這部分內(nèi)存稱為臟頁,如果忽然斷電,臟頁會(huì)丟失的。如果直接來了一個(gè)超過2G的數(shù)據(jù)寫入了page cache,會(huì)通過LRU算法(最近最常用的數(shù)據(jù)保留),通過swap交換硬盤的空間,將最不常用的數(shù)據(jù)刷入swap區(qū)中。臟頁會(huì)先刷到磁盤,才可以淘汰,保證數(shù)據(jù)不丟。但是不是臟頁,會(huì)直接通過LRU淘汰調(diào)最遠(yuǎn)最不常用數(shù)據(jù)。
在Linux內(nèi)核中,文件的每個(gè)數(shù)據(jù)塊最多只能對應(yīng)一個(gè)page cache項(xiàng),它通過兩個(gè)數(shù)據(jù)結(jié)構(gòu)來管理這些cache項(xiàng),一個(gè)是radix tree,另一個(gè)是雙向鏈表。
Radix tree是一種搜索樹,Linux內(nèi)核利用這個(gè)數(shù)據(jù)結(jié)構(gòu),快速查找臟的(dirty)和回寫的(writeback)頁面,得到其文件內(nèi)偏移,從而對page cache進(jìn)行快速定位。圖1是radix tree的一個(gè)示意圖,該radix tree的分叉為4(22),樹高為4,用來快速定位8位文件內(nèi)偏移。
另一個(gè)數(shù)據(jù)結(jié)構(gòu)是雙向鏈表,Linux內(nèi)核為每一片物理內(nèi)存區(qū)域(zone)維護(hù)active_list和 inactive_list兩個(gè)雙向鏈表,這兩個(gè)list主要用來實(shí)現(xiàn)物理內(nèi)存的回收。這兩個(gè)鏈表上除了文件Cache之外,還包括其它匿名 (Anonymous)內(nèi)存,如進(jìn)程堆棧等。
Page Cache 操作API
FileChannel:
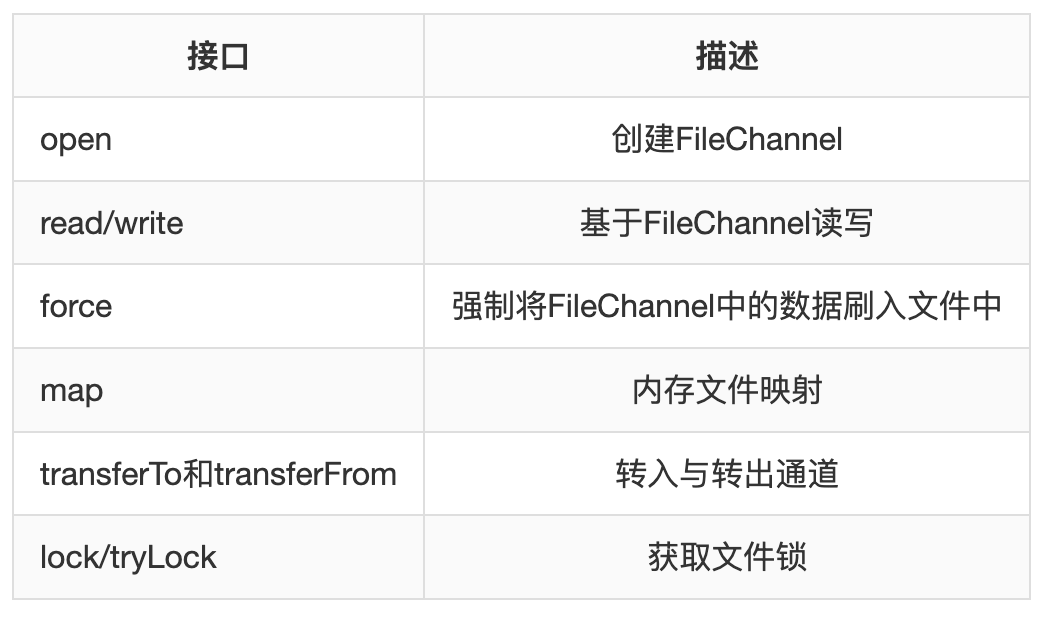
讀寫主要兩種,1. FileChannel的read/write/sendfile(linux內(nèi)核有些版本不支持sendfile)
2. mmap
mmap原理
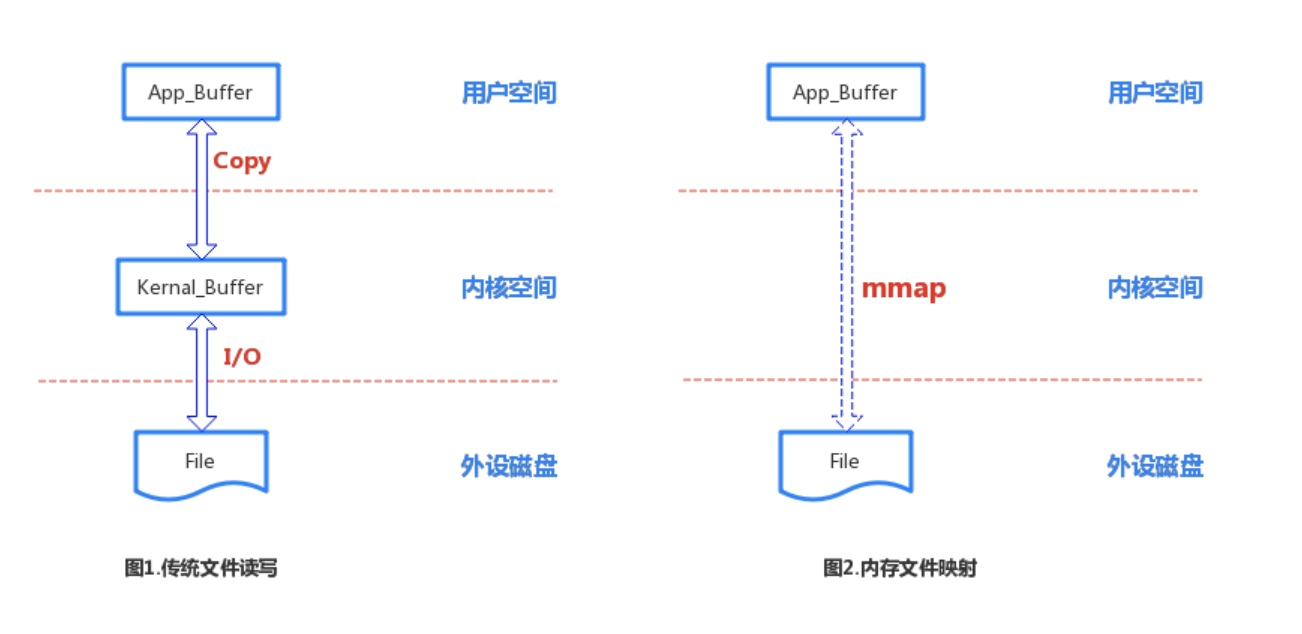
傳統(tǒng)文件I/O和內(nèi)存文件映射的過程圖的區(qū)別。內(nèi)存文件映射是將文件直接映射至用戶空間內(nèi)存,未經(jīng)過內(nèi)核空間緩沖區(qū)的拷貝,相對于傳統(tǒng)的I/O減少一次內(nèi)存拷貝。
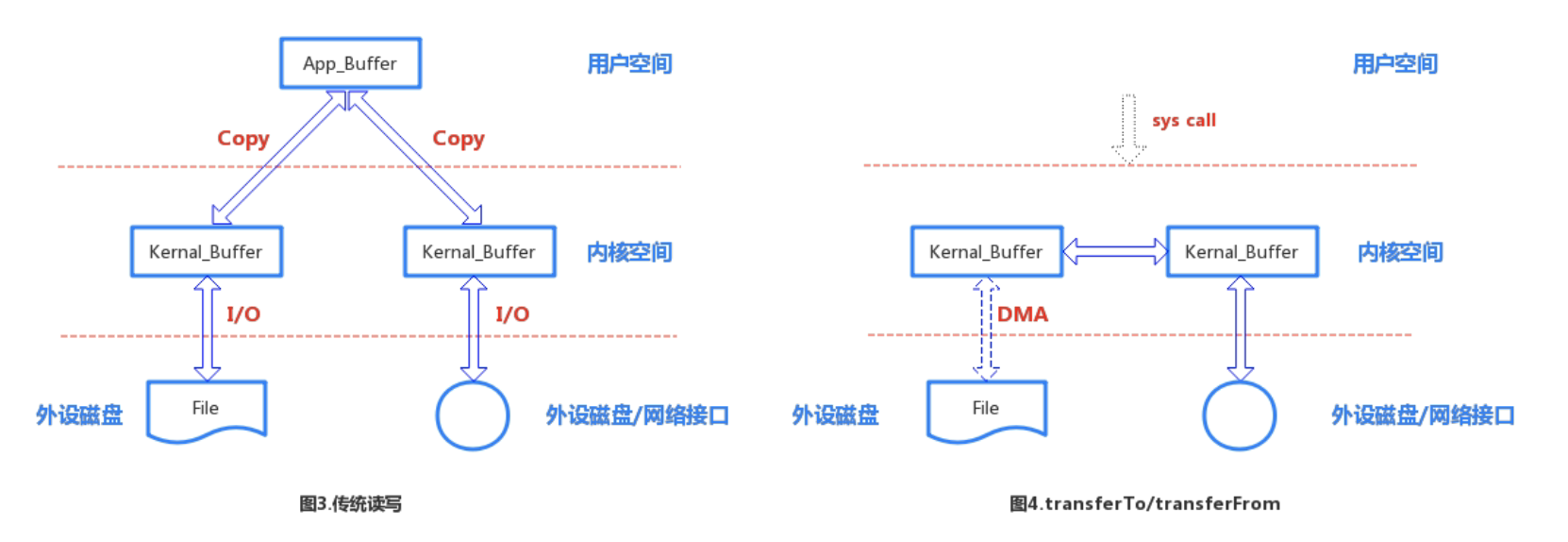
transferFrom和transferTo原理
Page Cache回寫
page cache回寫是指 將page cache寫入磁盤中。回寫后,系統(tǒng)也會(huì)將page cache這部分內(nèi)存回收。
觸發(fā)條件
1. 空間層面: 臟數(shù)據(jù)占比閾值(dirty_background_ratio)+ 臟數(shù)據(jù)大小閾值(dirty_background_bytes,優(yōu)先級別高于前者)。
分級別:
1)略超閾值,比如臟數(shù)據(jù)占比默認(rèn)為10%,超過10%,不足20%,后端異步線程回寫;
2)嚴(yán)重超閾值,比如臟數(shù)據(jù)占比超過20%,堵塞page cache write程序,進(jìn)行回寫。
2. 從時(shí)間的層面:即周期性的回寫(dirty_writeback_interval)
3. 用戶主動(dòng)發(fā)起sync()/msync()/fsync()調(diào)用
線程
三、mmap、allocateDirect+write和allocate+write性能對比
Java中NIO的核心緩沖就是ByteBuffer,所有的IO操作都是通過這個(gè)ByteBuffer進(jìn)行的;
Bytebuffer有兩種: 分配HeapByteBuffer:ByteBuffer buffer = ByteBuffer.allocate(int capacity);
分配DirectByteBuffer:ByteBuffer buffer = ByteBuffer.allocateDirect(int capacity);

HeapByteBuffer會(huì)多一次拷貝:
傳統(tǒng) BIO 是面向 Stream 的,底層實(shí)現(xiàn)可以理解為寫入的是 byte 數(shù)組,調(diào)用 native 方法寫入 IO,傳的參數(shù)是這個(gè)數(shù)組,就算GC改變了內(nèi)存地址,但是拿這個(gè)數(shù)組的引用照樣能找到最新的地址,對應(yīng)的方法時(shí)是:FileOutputStream.write
但是NIO,為了提升效率,傳的是內(nèi)存地址,省去了一次間接應(yīng)用。GC會(huì)回收無用對象,同時(shí)還會(huì)進(jìn)行碎片整理,移動(dòng)對象在內(nèi)存中的位置,來減少內(nèi)存碎片。如果在調(diào)用系統(tǒng)調(diào)用時(shí),發(fā)生了GC,導(dǎo)致HeapByteBuffer內(nèi)存位置發(fā)生了變化,但是內(nèi)核態(tài)并不能感知到這個(gè)變化導(dǎo)致系統(tǒng)調(diào)用讀取或者寫入錯(cuò)誤的數(shù)據(jù)。而DirectByteBuffer不受GC控制。所以HeapByteBuffer會(huì)多一次拷貝到堆外內(nèi)存的過程。(題外話 mmap用到的MappedByteBuffer也是堆外)
1. Direct buffer(allocateDirect)是相當(dāng)于固定的內(nèi)核buffer還是JVM進(jìn)程內(nèi)的堆外內(nèi)存?J
VM進(jìn)程的堆外內(nèi)存,屬于用戶空間。
2. Direct buffer的好處和壞處
好處:
a. 相比HeapByteBuffer,少一次堆內(nèi)拷貝到堆外的過程
b. gc壓力小
壞處:
自己管理內(nèi)存。創(chuàng)建開銷大。
對比代碼:
|
import org.junit.Test; import java.io.File; public class Demo { private final int writeSize = 1024 * 1024; // 單次寫入大小 //allocate+write @Test //write byte buffer for (int i = 0; i < totalSize / writeSize; i++) { System.out.println("Write byte buffer to channel elapse " + (SystemClock.now() - start) + " ms"); fileChannel.close(); |
|
//mmap @Test //write mapped byte buffer //mappedByteBuffer屬于堆外內(nèi)存 long start = SystemClock.now(); System.out.println("Write mapped byte buffer elapse " + (SystemClock.now() - start) + " ms"); fileChannel.close(); |
|
//allocateDirect+write @Test byte b = 110; //write direct buffer for (int i = 0; i < totalSize / writeSize; i++) { System.out.println("Write direct byte buffer to channel elapse " + (SystemClock.now() - start) + " ms"); fileChannel.close(); |
對比結(jié)果,總共寫入1GB文件,采用上述三次方式,每次分別寫入1KB、10KB、100KB、1MB,發(fā)現(xiàn)100KB是個(gè)分水嶺,1KB和10KB 性能mmap > allocateDirect(堆外) > allocate(堆內(nèi));100KB以后, allocateDirect > mmap.
自研MQ采用allocate+write寫,mmap讀的方式。
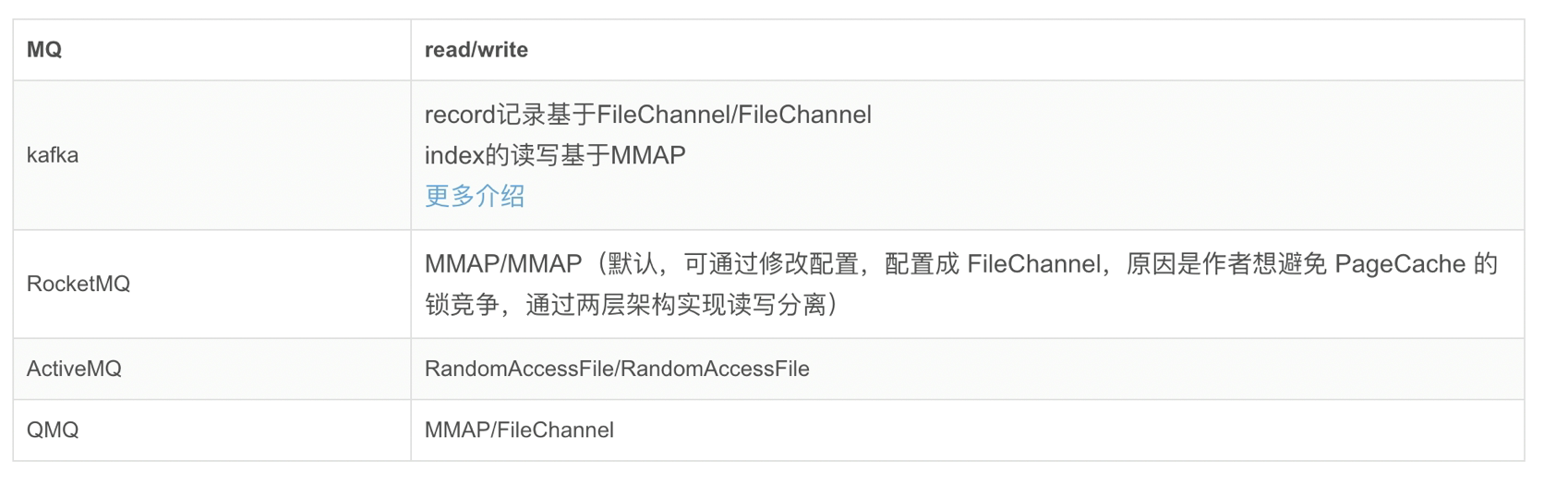
四、各MQ的存儲(chǔ)結(jié)構(gòu)對比
待完善。。。。
參考:
FileChannel詳解:http://www.rzrgm.cn/lxyit/p/9170741.html
框架篇:Linux零拷貝機(jī)制和FileChannel http://www.rzrgm.cn/cscw/p/13883420.html
DMA 技術(shù)是什么,在哪里用?看完絕對有收獲 https://www.jianshu.com/p/3a26e8c9f402
Java 堆外內(nèi)存、零拷貝、直接內(nèi)存以及針對于NIO中的FileChannel的思考 https://zhuanlan.zhihu.com/p/161939673

 浙公網(wǎng)安備 33010602011771號
浙公網(wǎng)安備 33010602011771號