
Prometheus 簡介
什么是普羅米修斯?
Prometheus是一個開源系統監控和警報工具包,最初由 SoundCloud構建。自 2012 年啟動以來,許多公司和組織都采用了 Prometheus,該項目擁有非常活躍的開發者和用戶社區。它現在是一個獨立的開源項目,獨立于任何公司進行維護。為了強調這一點,并明確項目的治理結構,Prometheus 于 2016 年作為繼Kubernetes之后的第二個托管項目加入了云原生計算基金會。
Prometheus 將其指標收集并存儲為時間序列數據,即指標信息與記錄時的時間戳以及稱為標簽的可選鍵值對一起存儲。
有關 Prometheus 的更詳盡的概述,請參閱從 媒體部分鏈接的資源。
特征
普羅米修斯的主要特點是:
- 具有由指標名稱和鍵/值對標識的時間序列數據的多維數據模型
- PromQL,一種靈活的查詢語言 來利用這個維度
- 不依賴分布式存儲;單個服務器節點是自治的
- 時間序列收集通過 HTTP 上的拉模型進行
- 通過中間網關支持推送時間序列
- 通過服務發現或靜態配置發現目標
- 多種圖形和儀表板支持模式
什么是指標?
用外行的話來說,指標是數字測量。時間序列意味著隨著時間的推移記錄變化。用戶想要測量的內容因應用程序而異。對于 Web 服務器,它可能是請求時間,對于數據庫,它可能是活動連接數或活動查詢數等。
指標在理解您的應用程序為何以某種方式工作方面起著重要作用。假設您正在運行一個 Web 應用程序并發現該應用程序運行緩慢。您將需要一些信息來了解您的應用程序發生了什么。例如,當請求數量很高時,應用程序可能會變慢。如果您有請求計數指標,您可以找出原因并增加服務器數量來處理負載。
組件
Prometheus 生態系統由多個組件組成,其中許多組件是可選的:
- 抓取和存儲時間序列數據的主要Prometheus 服務器
- 用于檢測應用程序代碼的客戶端庫
- 支持短期工作的推送網關
- 用于 HAProxy、StatsD、Graphite 等服務的特殊用途出口商。
- 一個alertmanager來處理警報
- 各種支持工具
大多數 Prometheus 組件都是用Go編寫的,這使得它們易于構建和部署為靜態二進制文件。
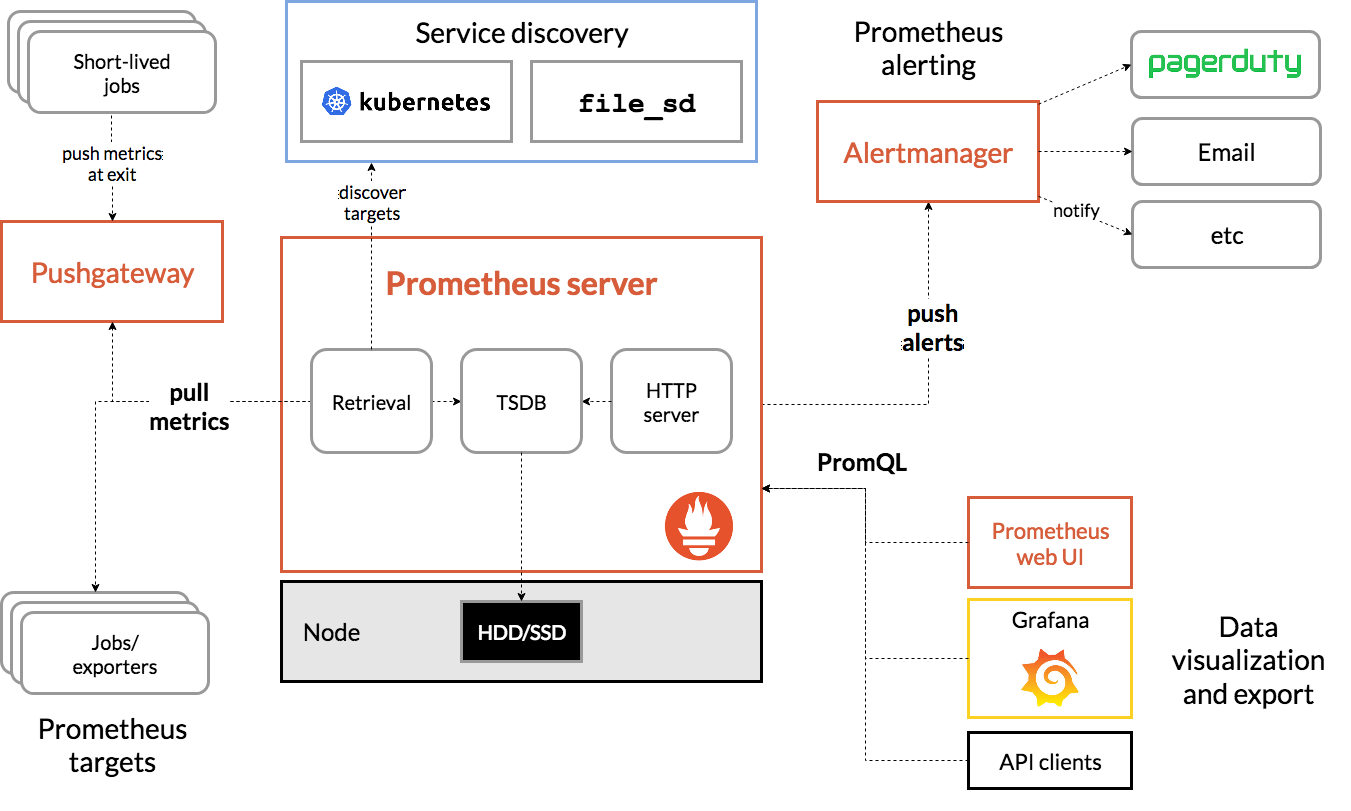
Prometheus 直接或通過一個用于短期作業的中間推送網關從檢測作業中抓取指標。它在本地存儲所有抓取的樣本,并對這些數據運行規則,以聚合和記錄現有數據的新時間序列或生成警報。Grafana或其他 API 消費者可用于可視化收集的數據。
1.1.1 Prometheus生態圈組件
- Prometheus Server:主服務器,負責收集和存儲時間序列數據
- client libraies:應用程序代碼插樁,將監控指標嵌入到被監控應用程序中
- Pushgateway:推送網關,為支持short-lived作業提供一個推送網關
- exporter:專門為一些應用開發的數據攝取組件—exporter,例如:HAProxy、StatsD、Graphite等等。
- Alertmanager:從Prometheus server端接收到alerts后,會進行去除重復數據,分組,并路由到對收的接受方式,發出報警。常見的接
收方式有:電子郵件,企業微信,釘釘,webhook
1.1.2 架構理解
Prometheus既然設計為一個維度存儲模型,可以把它理解為一個OLAP系統。
1、存儲計算層
- Prometheus Server,里面包含了存儲引擎和計算引擎。
- Retrieval組件為取數組件,它會主動從Pushgateway或者Exporter拉取指標數據。
- Service discovery,可以動態發現要監控的目標。
- TSDB,數據核心存儲與查詢。
- HTTP server,對外提供HTTP服務。
2、采集層
采集層分為兩類,一類是生命周期較短的作業,還有一類是生命周期較長的作業。
- 短作業:直接通過API,在退出時間指標推送給Pushgateway。
- 長作業:Retrieval組件直接從Job或者Exporter拉取數據。
3、應用層
應用層主要分為兩種,一種是AlertManager,另一種是數據可視化。
- AlertManager
對接Pagerduty,是一套付費的監控報警系統。可實現短信報警、5分鐘無人ack打電話通知、仍然無人ack,通知值班人員Manager...
Emial,發送郵件
... ...
- 數據可視化
Prometheus build-in WebUI
Grafana
其他基于API開發的客戶端
Prometheus工作原理
- Prometheus server定期從配置好的jobs或者exporters中拉metrics,或者接收來自Pushgateway發過來的metrics,或者從其他
的Prometheus server中拉netrics.
- Prometheus server在本地存儲收集到的metrics,并運行已定義好的alert.rules,記錄新的時間序列或者向Alertmanager推送警報。
- Alertmanager根據配置文件,對接收到的警報進行處理,發出告警。
- 在圖形界面中,可視化采集數據。
什么時候適合?
Prometheus 可以很好地記錄任何純數字時間序列。它既適合以機器為中心的監控,也適合監控高度動態的面向服務的架構。在微服務的世界中,它對多維數據收集和查詢的支持是一個特別的優勢。
Prometheus 專為可靠性而設計,是您在中斷期間訪問的系統,可讓您快速診斷問題。每個 Prometheus 服務器都是獨立的,不依賴于網絡存儲或其他遠程服務。當您的基礎架構的其他部分出現故障時,您可以依賴它,并且您無需設置大量基礎架構即可使用它。
什么時候不合適?
普羅米修斯重視可靠性。您始終可以查看有關系統的可用統計信息,即使在出現故障的情況下也是如此。如果您需要 100% 的準確性,例如按請求計費,Prometheus 不是一個好的選擇,因為收集的數據可能不夠詳細和完整。在這種情況下,您最好使用其他系統來收集和分析計費數據,并使用 Prometheus 進行其余監控。
普羅米修斯配置
Prometheus 配置為YAML。Prometheus 下載在一個名為 的文件中附帶了一個示例配置,prometheus.yml這是一個很好的起點。
我們刪除了示例文件中的大部分注釋以使其更加簡潔(注釋是前綴為 a 的行#)。
global:
scrape_interval: 15s
evaluation_interval: 15s
rule_files:
# - "first.rules"
# - "second.rules"
scrape_configs:
- job_name: prometheus
static_configs:
- targets: ['localhost:9090']
示例配置文件中包含三個配置塊:global、rule_files和scrape_configs。
該global塊控制 Prometheus 服務器的全局配置。我們有兩個選擇。第一個,scrape_interval控制 Prometheus 抓取目標的頻率。您可以為單個目標覆蓋它。在這種情況下,全局設置是每 15 秒抓取一次。該evaluation_interval選項控制 Prometheus 評估規則的頻率。Prometheus 使用規則來創建新的時間序列并生成警報。
該rule_files塊指定我們希望 Prometheus 服務器加載的任何規則的位置。現在我們還沒有規則。
最后一個塊,scrape_configs控制 Prometheus 監控的資源。由于 Prometheus 還將有關自身的數據公開為 HTTP 端點,因此它可以抓取和監控自身的健康狀況。在默認配置中,有一個名為 的作業prometheus,用于抓取 Prometheus 服務器公開的時間序列數據。該作業包含一個單一的、靜態配置的目標,即localhoston port 9090。Prometheus 期望指標在 . 路徑上的目標上可用/metrics。所以這個默認作業是通過 URL 抓取的:http://localhost:9090/metrics。
返回的時間序列數據將詳細說明 Prometheus 服務器的狀態和性能。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號