
詳細介紹:【c++】深入理解string類(4)
目錄
一 常見接口補充
1 c_str

這個接口就是為了兼容C語言,C++有時候會去調用C的接口,因為C++的庫里面有時候提供api時會直接按照C的方式提供。就意味著就算當前我們的程序是用C++!寫的,也不可避免地會調用C風格的接口。例如我們后面學習網絡工程的時候,用到的send()這個接口,就會調用C_str.
2 不同類型之間的相互轉換
(1)其他類型轉換成浮點數
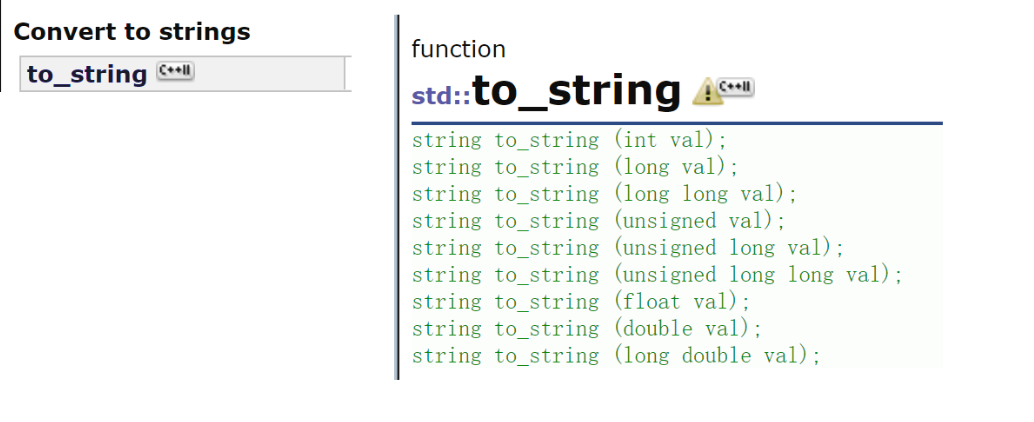
(2)浮點數轉換成不同類型
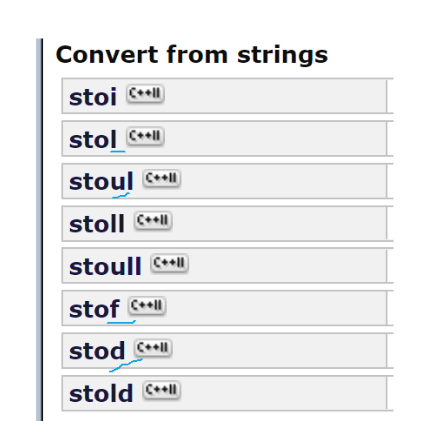
每一個看最后的字母就可以判斷出是什么類型轉換:例如第一個最后一個字母是i,就表示是浮點數轉換成整型,第三個ul表示 unsigned long
二 string類問題的模擬實現
先包含一下頭文件:
#define _CRT_SECURE_NO_WARNINGS 1
#include
#include
#include
#include
using namespace std;
1 打印函數
博主直接將代碼的解析附錄在注釋中:
// 函數功能:打印字符串的正序和逆序字符
// 參數:const string& s - 傳入的字符串常量引用,保證原字符串不會被修改
void Print(const string& s)
{
// 1. 正序遍歷字符串
// 使用const_iterator迭代器,用于遍歷常量字符串,只能讀取不能修改
// 注意:不能用const string::iterator,因為s是const類型,其begin()返回const_iterator
string::const_iterator it1 = s.begin();
// 循環遍歷直到字符串末尾(end()指向最后一個字符的下一位)
while (it1 != s.end())
{
// *it1 = 'x'; // 編譯錯誤:const_iterator不允許修改指向的內容
cout << *it1 << " "; // 輸出當前迭代器指向的字符
++it1; // 迭代器向后移動一位,指向 next 字符
}
cout << endl; // 正序輸出結束,換行
// 2. 逆序遍歷字符串
// 使用const_reverse_iterator逆序迭代器,用于逆序遍歷常量字符串,只能讀取不能修改
string::const_reverse_iterator it2 = s.rbegin();
// 循環遍歷直到逆序末尾(rend()指向第一個字符的前一位)
while (it2 != s.rend())
{
// *it2 = 'x'; // 編譯錯誤:const_reverse_iterator同樣不允許修改內容
cout << *it2 << " "; // 輸出當前逆序迭代器指向的字符
++it2; // 逆序迭代器"++"表示向前前移動,指向 previous 字符
}
cout << endl; // 逆序輸出結束,換行
}我們來測試一下:
#include
#include
#include
#include // 用于find函數
using namespace std;
// 假設已有之前定義的Print函數
void Print(const string& s);
// 測試字符串操作及相關C++特性的函數
void test_string2()
{
// 用字符串常量初始化string對象
string s1("hello world");
cout << s1 << endl; // 輸出: hello world
// 通過下標[]修改字符串中的字符([]不做越界檢查)
s1[0] = 'x';
cout << s1 << endl; // 輸出: xello world
cout << s1[0] << endl; // 輸出: x
// 越界訪問的兩種方式及區別
// s1[12]; // 用[]越界訪問會觸發斷言(debug模式下),直接崩潰
// s1.at(12); // 用at()越界訪問會拋出out_of_range異常,可以捕獲處理
// 獲取字符串長度的兩種方法
cout << s1.size() << endl; // 輸出: 11 (推薦使用size())
cout << s1.length() << endl; // 輸出: 11 (與size()功能相同,歷史原因保留)
// 1. 使用下標+[]遍歷并修改字符串
for (size_t i = 0; i < s1.size(); i++)
{
s1[i]++; // 每個字符的ASCII值加1('x'->'y','e'->'f'等)
}
cout << s1 << endl; // 輸出: yfmmp!xpsme
// 2. 使用迭代器遍歷字符串(iterator支持修改)
// 迭代器是一種類似指針的對象,用于訪問容器元素
string::iterator it1 = s1.begin(); // begin()返回指向第一個元素的迭代器
while (it1 != s1.end()) // end()返回指向最后一個元素下一位的迭代器
{
// (*it1)--; // 取消注釋可將字符改回原來的值
cout << *it1 << " "; // 解引用迭代器獲取字符
++it1; // 迭代器向后移動
}
cout << endl; // 輸出: y f m m p ! x p s m e
// 演示list容器的迭代器使用(與string迭代器用法一致,體現容器迭代器的統一性)
list lt;
lt.push_back(1);
lt.push_back(2);
lt.push_back(3);
list::iterator lit = lt.begin();
while (lit != lt.end())
{
cout << *lit << " "; // 輸出: 1 2 3
++lit;
}
cout << endl;
// 調用Print函數,打印字符串的正序和逆序(使用const迭代器)
Print(s1);
// 使用標準庫find函數查找元素(需要包含)
// find返回迭代器,找到則指向該元素,否則指向end()
// string::iterator ret1 = find(s1.begin(), s1.end(), 'x');
auto ret1 = find(s1.begin(), s1.end(), 'x'); // 使用auto簡化類型聲明
if (ret1 != s1.end())
{
cout << "找到了x" << endl; // 此例中會輸出該信息
}
// 在list中查找元素,迭代器用法與string一致
// list::iterator ret2 = find(lt.begin(), lt.end(), 2);
auto ret2 = find(lt.begin(), lt.end(), 2); // auto自動推導為list::iterator
if (ret2 != lt.end())
{
cout << "找到了2" << endl; // 此例中會輸出該信息
}
// C++11特性:auto關鍵字(自動類型推導)
int i = 0;
auto j = i; // j被推導為int類型
auto k = 10; // k被推導為int類型
auto p1 = &i; // p1被推導為int*類型(指針)
auto* p2 = &i; // p2顯式指定為指針類型,同樣是int*
cout << p1 << endl; // 輸出i的地址
cout << p2 << endl; // 輸出i的地址(與p1相同)
// auto與引用的結合
int& r1 = i; // r1是i的引用
auto r2 = r1; // r2被推導為int類型(不是引用),是r1所指值的拷貝
auto& r3 = r1; // r3被推導為int&類型(是r1的引用,即i的引用)
// 打印地址驗證
cout << &r2 << endl; // 輸出r2的地址(與i不同)
cout << &r1 << endl; // 輸出i的地址
cout << &i << endl; // 輸出i的地址
cout << &r3 << endl; // 輸出i的地址(與r1相同)
// C++11特性:范圍for循環(語法糖,簡化迭代器遍歷)
// 范圍for會自動遍歷容器中所有元素,自動判斷結束
// for (auto ch : s1) // 傳值方式,修改ch不影響原字符串
for (auto& ch : s1) // 傳引用方式,修改ch會影響原字符串
{
ch -= 1; // 每個字符ASCII值減1(恢復之前的++操作)
}
cout << endl;
// 用范圍for遍歷并打印字符串(const引用方式,防止意外修改)
for (const auto& ch : s1)
{
cout << ch << ' '; // 輸出: x e l l o w o r l d
}
cout << endl;
// 用范圍for遍歷list容器
for (auto e : lt)
{
cout << e << ' '; // 輸出: 1 2 3
}
cout << endl;
// 范圍for也支持數組(編譯器做了特殊處理)
int a[10] = { 1,2,3 }; // 初始化前3個元素,其余為0
for (auto e : a)
{
cout << e << " "; // 輸出: 1 2 3 0 0 0 0 0 0 0
}
cout << endl;
}
2 構造函數 析構函數
namespace bit
{
string::string(const char* str)
:_size(strlen(str))
{
// ?
_str = new char[_size + 1];
_capacity = _size;
strcpy(_str, str);
}
string::~string()
{
delete[] _str;
_str = nullptr;
_size = 0;
_capacity = 0;
}
}代碼解析:
strcpy(_str, str); // 將C風格字符串復制到已分配的內存中 delete[] _str; // 釋放字符數組占用的內存(注意用delete[]匹配new[])3 擴容函數
void string::reserve(size_t n)
{
if (n > _capacity)
{
//
char* tmp = new char[n + 1];
strcpy(tmp, _str);
delete[] _str;
_str = tmp;
_capacity = n;
}
}創建了一塊新的空間來存出數據,tmp就是新的空間
// 3. 釋放原有內存,避免內存泄漏
delete[] _str;
// 4. 將字符串指針指向新內存
_str = tmp;
// 5. 更新容量為n(新容量)
_capacity = n;4 尾插函數
void string::push_back(char ch)
{
if (_size == _capacity)
{
reserve(_capacity == 0 ? 4 : _capacity * 2);
}
_str[_size] = ch;
_size++;
_str[_size] = '\0';
}
void string::append(const char* str)
{
size_t len = strlen(str);
if (_size + len > _capacity)
{
reserve(std::max(_size + len, _capacity * 2));
}
strcpy(_str + _size, str);
_size += len;
}區分:
push_back 函數:
- 用于在字符串末尾添加單個字符
- 擴容策略:當容量不足時,空容量時初始化為 4,否則翻倍擴容
- 每次操作都確保保證字符串以 '\0' 結尾,維持 C 風格字符串的兼容性
append 函數:
- 用于在字符串末尾添加一個完整的 C 風格字符串
- 擴容策略:取 "所需總長度" 和 "當前容量翻倍" 的最大值,平衡內存利用率和擴容效率
- 利用
strcpy直接復制字符串,自動包含終止符,簡化實現
// 檢查現有容量是否足夠容納追加后的所有字符
if (_size + len > _capacity)
{
// 擴容到"當前長度+追加長度"和"當前容量*2"中的較大值
// 保證既能容納新內容,又能減少后續擴容次數
reserve(std::max(_size + len, _capacity * 2));
} // 更新有效長度(原有長度 + 追加的長度)
_size += len;
// 注意:strcpy會復制原字符串的'\0',因此無需額外手動添加終止符注意:這里的_size是string類的一個成員變量,你哦啊是當前字符串的有效數據個數。
那么我們就可以分別用push_back和append對字符和字符串進行尾插操作:
string& operator+=(const char* str)
{
append(str);
return *this;
}
string& operator+=(char ch)
{
push_back(ch);
return *this;
}5 測試
我們來測試一下上面自己實現的string類:
?
#include
// 假設包含了自定義string類的頭文件
using namespace std;
// 測試自定義string類的各種功能和特性
void test_string1()
{
// 1. 測試默認構造函數(創建空字符串)
bit::string s1;
// c_str()返回C風格字符串指針(以'\0'結尾),用于輸出
cout << s1.c_str() << endl; // 輸出空字符串
// 2. 測試帶參構造函數及字符串修改
string s2("hello world");
cout << s2.c_str() << endl; // 輸出: hello world
// 通過[]運算符修改字符串第一個字符
s2[0] = 'x'; // s2變為: xello world
// 遍歷并修改每個字符(ASCII值+1)
for (size_t i = 0; i < s2.size(); i++)
{
s2[i]++; // 每個字符遞增:x->y, e->f, l->m等
}
cout << s2.c_str() << endl; // 輸出: yfmmp!xpsme
// 3. 測試字符串初始化方式
// 隱式類型轉換:const char* -> string(編譯器優化為直接構造,避免拷貝)
string s3 = "hello world";
// 直接構造(與s3等價,兩種初始化方式效果相同)
string s4("hello world");
// 常量字符串對象(內容不可修改)
const string s5("hello world");
// 4. 測試常量字符串的訪問(const對象只能讀不能寫)
for (size_t i = 0; i < s2.size(); i++)
{
// s5[i] = 'a'; // 編譯錯誤:const對象不能修改
cout << s5[i] << "-"; // 輸出: h-e-l-l-o- -w-o-r-l-d-
}
cout << endl;
// 5. 測試范圍for循環遍歷(普通對象,可讀寫)
for (auto ch : s4)
{
cout << ch << " "; // 輸出: h e l l o w o r l d
}
cout << endl;
// 6. 測試普通迭代器(可修改元素)
string::iterator it4 = s4.begin();
while (it4 != s4.end())
{
*it4 += 1; // 每個字符ASCII值+1(h->i, e->f等)
cout << *it4 << " "; // 輸出: i f m m p ! x p s m e
++it4;
}
cout << endl;
// 7. 測試范圍for遍歷const字符串(只讀)
for (auto ch : s5)
{
// ch = 'a'; // 編譯錯誤:范圍for遍歷const對象時元素是只讀的
cout << ch << " "; // 輸出: h e l l o w o r l d
}
cout << endl;
// 8. 測試const迭代器(只能讀不能修改)
string::const_iterator it5 = s5.begin();
while (it5 != s5.end())
{
// *it5 += 1; // 編譯錯誤:const迭代器不能修改指向的元素
cout << *it5 << " "; // 輸出: h e l l o w o r l d
++it5;
}
cout << endl;
}
? 6 迭代器實現
typedef char* iterator;
typedef const char* const_iterator;
iterator begin()
{
return _str;
}
iterator end()
{
return _str + _size;
}
const_iterator begin() const
{
return _str;
}
const_iterator end() const
{
return _str + _size;
}7 insert
insert是在指定位置插入字符串或字符
void string::insert(size_t pos, char ch)
{
assert(pos <= _size);
if (_size == _capacity)
{
reserve(_capacity == 0 ? 4 : _capacity * 2);
}
// ?
int end = _size;
while (end >= (int)pos)
{
_str[end + 1] = _str[end];
--end;
}
_str[pos] = ch;
_size++;
}字符移動:從后往前將原有字符串向后挪動一位(最后一位指向\0,這樣增加完新的字符之后就不需要單獨處理\0了)
為什么要將pos 強轉為int類型?
因為在二目操作符中,如果先后兩個類型會把小的類型自動強轉為大的類型,此處就是把無符號轉化成有符號,循環的終止條件是size<0(因為有可能是頭插),無符號類型的-1是最大的整型,這樣就會出現問題,所以需要把pos強轉為int類型
有符號和無符號比較時會把無符號轉換成有符號
那么除了把pos強轉成int類型,還有什么其他的辦法嗎?
挪動數據的時候可以為end-1挪給end,判斷循環條件變為end>pos
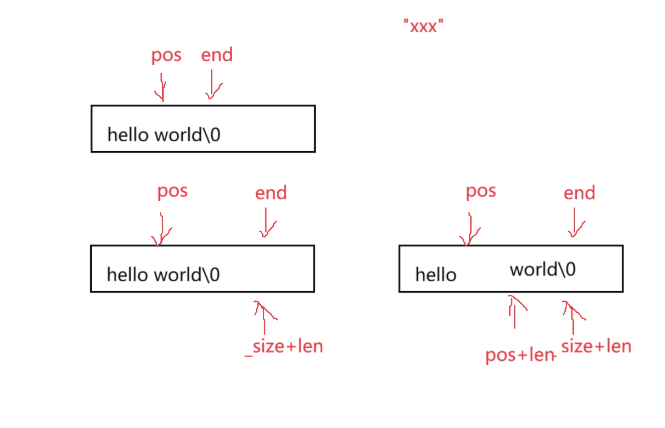
兩種版本對比:

改進版本:改進版本為要插入長度為len的字符
// 在當前字符串的 pos 位置插入 C 風格字符串 str
void string::insert(size_t pos, const char* str)
{
// 斷言:插入位置必須合法(pos 不能超過當前字符串長度)
// 若 pos > _size,屬于越界插入,Debug 模式下直接崩潰提示
assert(pos <= _size);
// 若插入的字符串為空(str 是 nullptr),直接斷言失敗(避免后續 strlen 崩潰)
assert(str != nullptr);
// 計算待插入字符串的有效長度(不含末尾的 '\0')
size_t len = strlen(str);
// 若插入的是空字符串(len=0),無需操作,直接返回
if (len == 0)
{
return;
}
// 檢查是否需要擴容:插入后總長度(原長度 + 插入長度)是否超過當前容量
if (_size + len > _capacity)
{
// 擴容策略:取「插入后所需最小容量」和「原容量的2倍」中的較大值
// 避免擴容后仍不足,同時兼顧減少未來擴容次數
reserve(std::max(_size + len, _capacity * 2));
}
// 數據挪動:將原字符串中 pos 及之后的字符整體向后挪動 len 個位置
// 從原字符串末尾(_size)向后偏移 len 個位置開始挪動(避免覆蓋未處理的數據)
size_t end = _size + len;
// 終止條件:當 end 挪到「pos + len - 1」時,說明已騰出插入所需的空間
// 循環中每次向前移動一個位置,直到 end 不大于目標位置
while (end > pos + len - 1)
{
// 將當前位置的字符替換為「向前偏移 len 個位置」的字符(即原位置的字符)
_str[end] = _str[end - len];
--end; // 向前移動一個位置,繼續處理前一個字符
}
// 將待插入字符串 str 拷貝到騰出來的 pos 位置
// 從 _str + pos 開始,拷貝 len 個字符(str 中恰好有 len 個有效字符)
strncpy(_str + pos, str, len);
// 更新字符串的有效長度(原長度 + 插入的字符數)
_size += len;
}挪動長度為len的兩種版本對比:

注意循環的條件!!end是到pos+len的位置停止循環
8 erase
用于刪除字符串中指定長度和位置的字符
刪除的時候要確保刪除的位置是有效字符,判斷是否合法
有兩種情況:1刪除pos后全部的字符 2 刪除一部分
思路一:使用strcpy

思路二:使用memcpy
void string::erase(size_t pos, size_t len)
{
assert(pos < _size);
// 情況1:刪除長度為 npos(通常定義為 -1,無符號下表示最大值),
// 或刪除長度超過「從 pos 到末尾的剩余字符數」(即刪除到字符串末尾)
if (len == npos || len >= _size - pos)
{
// 直接將字符串長度截斷到 pos 位置(pos 及之后的字符全部刪除)
_size = pos;
// 在新的末尾添加 '\0',確保字符串符合 C 風格規范(避免后續輸出亂碼)
_str[_size] = '\0';
}
else
{
// 情況2:刪除部分字符(未刪完,需要將后續字符前移覆蓋)
// 計算需要前移的字符長度:從 pos+len 到原末尾(包含 '\0')的總長度
// +1 是為了將原末尾的 '\0' 也前移(確保新字符串末尾有 '\0')
size_t move_len = _size - (pos + len) + 1;
// 將 pos+len 位置開始的字符,拷貝到 pos 位置(覆蓋被刪除的部分)
// 使用 memcpy 比 strcpy 更高效(直接按字節拷貝,無需檢查 '\0')
memcpy(_str + pos, _str + pos + len, move_len);
// 更新有效長度:原長度減去刪除的字符數
_size -= len;
}
}還有一些模擬實現的內容沒有講完,博主放到下一篇中

 浙公網安備 33010602011771號
浙公網安備 33010602011771號