
完整教程:【DINOv3教程1-圖像分割】使用DINOv3+邏輯回歸器進行圖像前景分割【附源碼】
《博主簡介》
小伙伴們好,我是阿旭。
專注于計算機視覺領域,包括目標檢測、圖像分類、圖像分割和目標跟蹤等項目開發,提供模型對比實驗、答疑輔導等。
《------往期經典推薦------》
二、機器學習實戰專欄【鏈接】,已更新31期,歡迎關注,持續更新中~~
三、深度學習【Pytorch】專欄【鏈接】
四、【Stable Diffusion繪畫系列】專欄【鏈接】
五、YOLOv8改進專欄【鏈接】,持續更新中~~
六、YOLO性能對比專欄【鏈接】,持續更新中~
《------正文------》
目錄
引言
DINOv3是Meta于2025年8月推出的第三代自監督視覺基礎模型,其核心優勢在于:?首次證明了自監督學習模型能在圖像分類、目標檢測、語義分割等超過60項視覺任務上全面超越弱監督和專業模型?
,并且僅需單一凍結的骨干網絡無需微調即可實現多任務高性能,極大提升了推理效率和部署靈活性?。
本文將詳細介紹如何使用最新的DINOv3模型搭配邏輯回歸器進行圖像前景分割,包含完整步驟與代碼說明,基本流程如下:
- 特征學習:利用DINOv3預訓練模型提取圖像patch的高級特征
- 數據準備:將圖像和mask對齊,準備訓練數據
- 模型訓練:使用邏輯回歸將特征映射到前景/背景標簽
- 模型驗證:通過交叉驗證選擇最佳參數
- 應用部署:保存模型并用于新圖像的前景分割
這種方法的優勢在于利用了DINOv3強大的自監督學習能力,無需大量標注數據就能獲得高質量的視覺特征表示。
1. 導入必要的庫和模塊
import io
import os
import pickle
import tarfile
import urllib
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
from scipy import signal
from sklearn.metrics import precision_recall_curve
from sklearn.metrics import average_precision_score
from sklearn.linear_model import LogisticRegression
import torch
import torchvision.transforms.functional as TF
from tqdm import tqdm
from transformers import AutoModel這些庫分別用于:
- 文件操作和數據處理(io, os, pickle等)
- 圖像處理(PIL, torchvision)
- 數值計算和科學計算(numpy, scipy)
- 機器學習(sklearn)
- 深度學習(torch)
- 進度顯示(tqdm)
- 模型加載(transformers)
2. 加載DINOv3預訓練模型
model = AutoModel.from_pretrained(
r'D:\7studying\DinoV3_Study\dinov3-main\PreModels\dinov3-vits16-pretrain-lvd1689m',
local_files_only=True
)加載本地的DINOv3預訓練視覺Transformer模型,該模型已經學習了豐富的視覺特征表示。這里加載的是dinov3-vits16-pretrain-lvd1689m模型。
3. 數據加載和預處理
def load_images_from_path(base_path):
images = []
for name in os.listdir(base_path):
image_path = os.path.join(base_path, name)
image = Image.open(image_path)
images.append(image)
return images
images = load_images_from_path(r'D:\7studying\DinoV3_Study\dinov3-main\datasets\data1\images')
labels = load_images_from_path(r'D:\7studying\DinoV3_Study\dinov3-main\datasets\data1\masks')加載圖像和對應的mask標簽數據,用于訓練前景分割模型。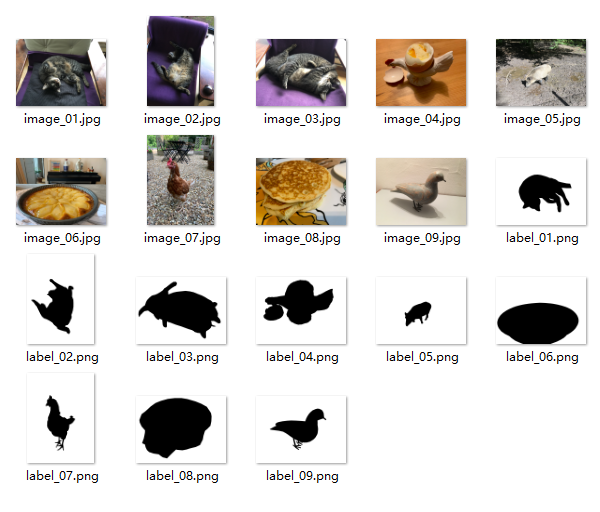
4. 數據可視化
# 顯示第一張圖像及其mask、前景和背景
data_to_show = [image, mask, foreground, background]
data_labels = ["Image", "Mask", "Foreground", "Background"]
plt.figure(figsize=(16, 4), dpi=300)
for i in range(len(data_to_show)):
plt.subplot(1, len(data_to_show), i + 1)
plt.imshow(data_to_show[i])
plt.axis('off')
plt.title(data_labels[i], fontsize=12)可視化展示原始圖像、mask標簽、前景和背景,幫助理解數據。
5. 圖像預處理函數
def resize_transform(mask_image, image_size=768, patch_size=16):
w, h = mask_image.size
h_patches = int(image_size / patch_size)
w_patches = int((w * image_size) / (h * patch_size))
target_size = (h_patches * patch_size, w_patches * patch_size)
resized_image = TF.resize(mask_image, target_size)
tensor_image = TF.to_tensor(resized_image)
return tensor_image, (h_patches, w_patches)將圖像調整為適合ViT模型處理的尺寸,確保圖像尺寸能被patch大小(16)整除。

6. 特征提取和訓練數據準備
with torch.inference_mode():
for i in tqdm(range(n_images), desc="Processing images"):
# 1. 加載mask并量化
mask_i = labels[i].split()[-1]
mask_i_resized, (h_patches, w_patches) = resize_transform(mask_i)
with torch.no_grad():
mask_i_quantized = patch_quant_filter(mask_i_resized).squeeze().view(-1).detach().cpu()
# 2. 加載并預處理圖像
image_i = images[i].convert('RGB')
image_i_resized,_ = resize_transform(image_i)
image_i_resized = TF.normalize(image_i_resized, mean=IMAGENET_MEAN, std=IMAGENET_STD)
image_i_resized = image_i_resized.unsqueeze(0)
# 3. 使用DINOv3提取特征
outputs = model(image_i_resized)
patch_features = outputs.last_hidden_state[:, 1:, :] # 去掉cls token
# 4. 確保特征和標簽數量一致
if actual_patches > expected_patches:
patch_features = patch_features[:, :expected_patches, :]這是整個流程的核心部分:
- Mask處理:將mask圖像量化為patch級別的標簽
- 圖像預處理:調整圖像大小并進行標準化
- 特征提取:使用DINOv3模型提取每個patch的特征表示
- 數據對齊:確保特征向量和標簽數量一致
7. 數據過濾和準備
# keeping only the patches that have clear positive or negative label
idx = (ys < 0.01) | (ys > 0.99)
xs = xs[idx]
ys = ys[idx]
image_index = image_index[idx]只保留標簽非常明確(接近0或1)的patch,過濾掉模糊的中間值,提高訓練質量。
8. 模型訓練和驗證
# 使用留一法交叉驗證尋找最佳參數
cs = np.logspace(-7, 0, 8)
scores = np.zeros((n_images, len(cs)))
for i in range(n_images):
# 留一法:用除第i張圖像外的所有圖像訓練,用第i張圖像驗證
train_selection = image_index != float(i)
fold_x = xs[train_selection].numpy()
fold_y = (ys[train_selection] > 0).long().numpy()
val_x = xs[~train_selection].numpy()
val_y = (ys[~train_selection] > 0).long().numpy()
for j, c in enumerate(cs):
# 訓練邏輯回歸分類器
clf = LogisticRegression(random_state=0, C=c, max_iter=10000).fit(fold_x, fold_y)
output = clf.predict_proba(val_x)
precision, recall, thresholds = precision_recall_curve(val_y, output[:, 1])
s = average_precision_score(val_y, output[:, 1])
scores[i, j] = s使用留一法交叉驗證訓練邏輯回歸器,尋找最佳的正則化參數C。
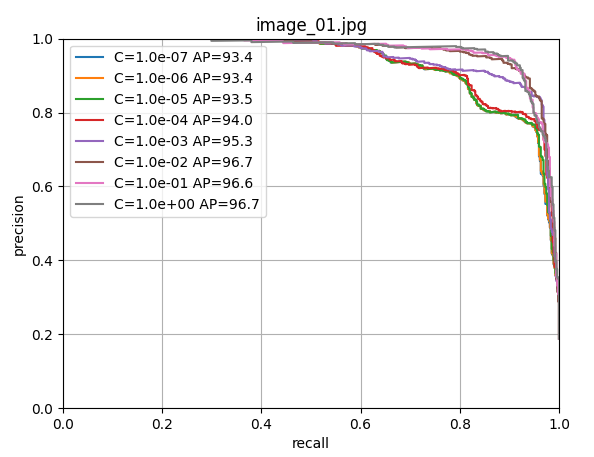
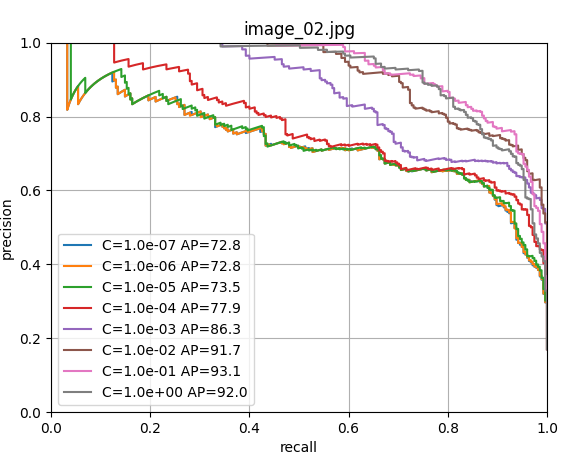
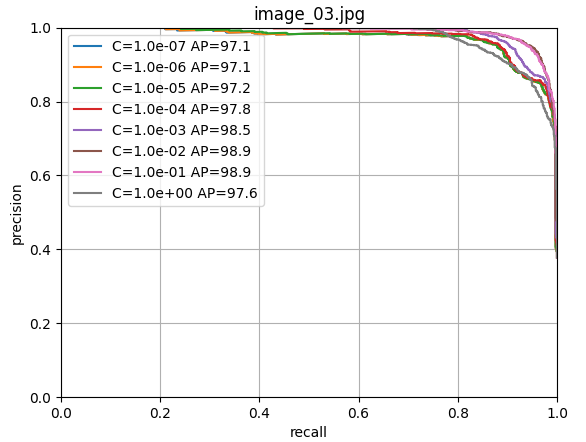
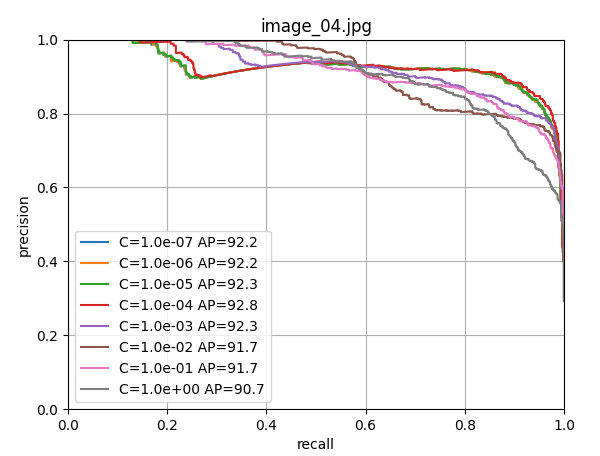
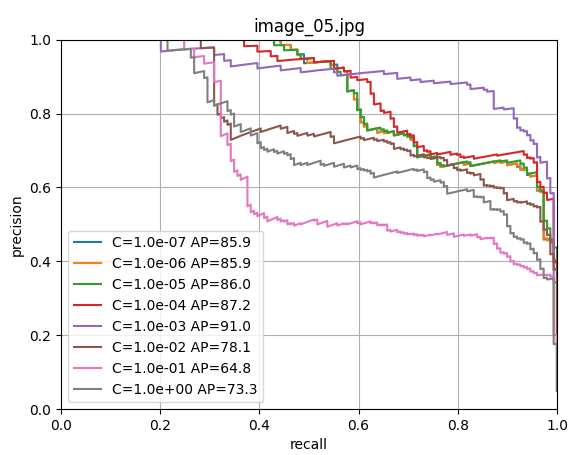
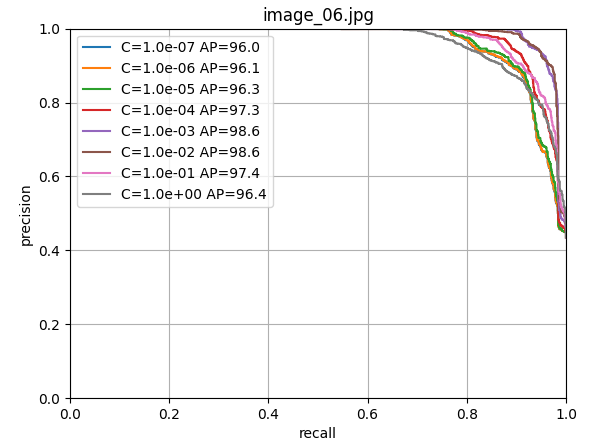
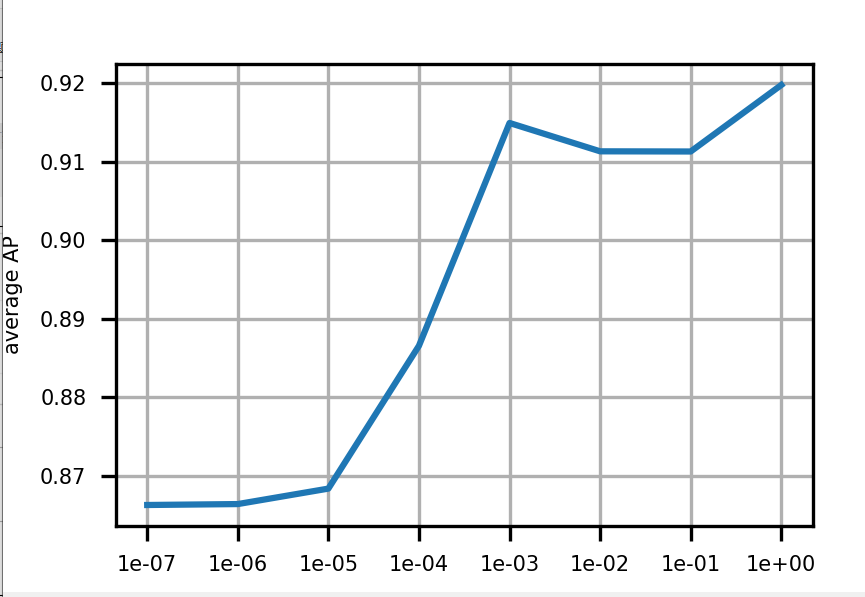
9. 最終模型訓練和保存
由上圖可以看出c=1.0時,模型性能最佳,這里直接取c=1.0,進行LogisticRegression回歸器的模型訓練;
# 使用最佳參數訓練最終模型
clf = LogisticRegression(random_state=0, C=1.0, max_iter=100000, verbose=2).fit(xs.numpy(), (ys > 0).long().numpy())
# 保存模型
with open(model_path, "wb") as f:
pickle.dump(clf, f)使用所有數據訓練最終的前景分割分類器,并將其保存到磁盤。
10. 測試和可視化
# 對測試圖像進行預測
with torch.inference_mode():
outputs = model(test_image_normalized.unsqueeze(0))
patch_features = outputs.last_hidden_state[:, 1:, :]
x = patch_features.squeeze().detach().cpu()
# 使用訓練好的分類器預測前景概率
fg_score = clf.predict_proba(x)[:, 1].reshape(h_patches, w_patches)
fg_score_mf = torch.from_numpy(signal.medfilt2d(fg_score, kernel_size=3))
# 可視化結果
plt.figure(figsize=(9, 3), dpi=300)
plt.subplot(1, 3, 1)
plt.imshow(test_image_resized.permute(1, 2, 0))
plt.title('input image')
plt.subplot(1, 3, 2)
plt.imshow(fg_score)
plt.title('foreground score')
plt.subplot(1, 3, 3)
plt.imshow(fg_score_mf)
plt.title('+ median filter')對新圖像進行前景分割預測,并可視化結果,包括原始圖像、前景得分圖和經過中值濾波平滑的結果。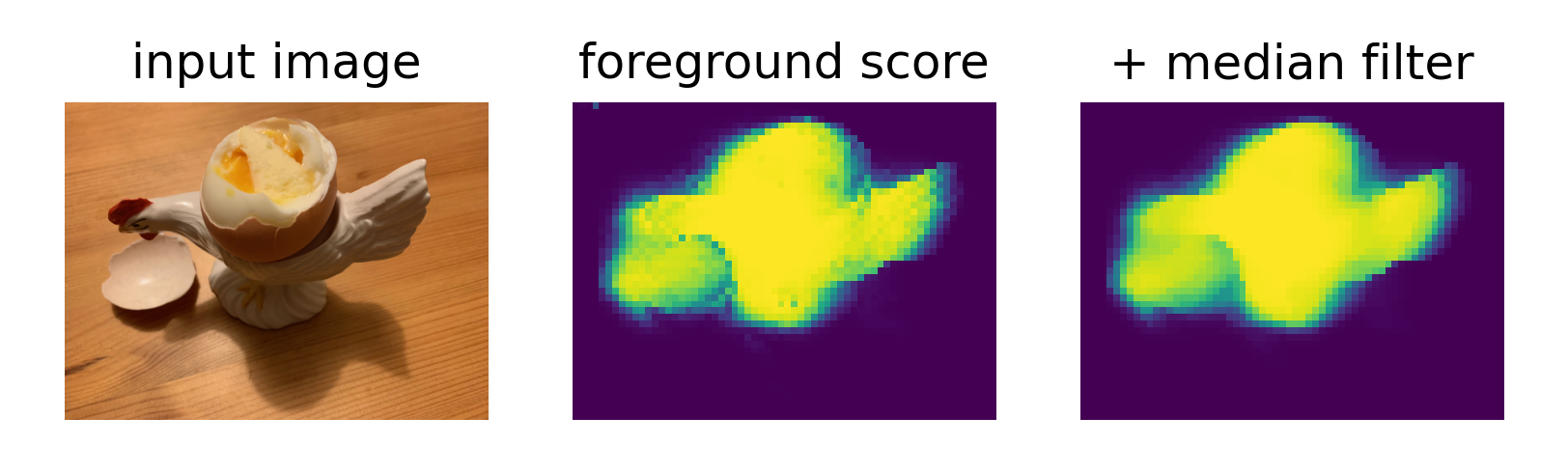
總結
這種方法的優勢在于利用了DINOv3強大的自監督學習能力,無需大量標注數據就能獲得高質量的視覺特征表示。如果感覺不錯的小伙伴,感謝你們的點贊關注。后續還會出一些其他的使用案例~

好了,這篇文章就介紹到這里,喜歡的小伙伴感謝給點個贊和關注,更多精彩內容持續更新~~
關于本篇文章大家有任何建議或意見,歡迎在評論區留言交流!

 浙公網安備 33010602011771號
浙公網安備 33010602011771號