背景需求
因為園所只有五種淺色A4紙(粉紅、黃、淺綠、淺藍、白色),分園都是一共4個班級,正好一人一種顏色,但是總部中班、大班都是6個,所以一個班級沒法用到不同顏色紙,
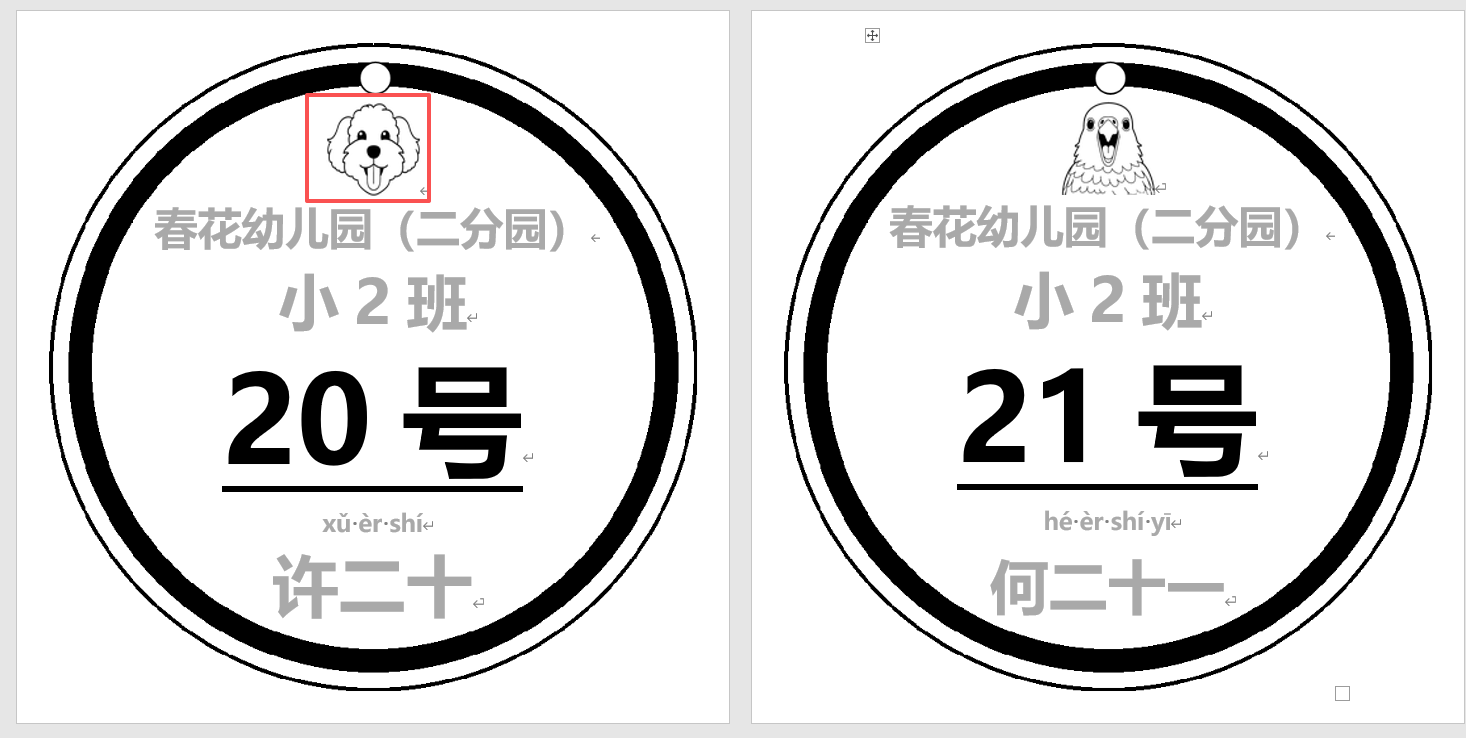
因此校級家長講座接待家長簽到時,我看到組長班就是自己設計打印了15CM手工紙的被子掛牌和掛牌名字卡(用了網絡圖片模版框自己打印的)

小班組長還在紙上插入了小動物圖片。

這樣好處是,
1、直接打印15CM手工紙,不用裁剪,不用剪圓,直接塑封。
2、有小動物更符合低年齡幼兒的興趣。
設計思考:
我完全可以做15CM小動物的圓牌卡(換一個自定義尺寸,插入小動物圖片)

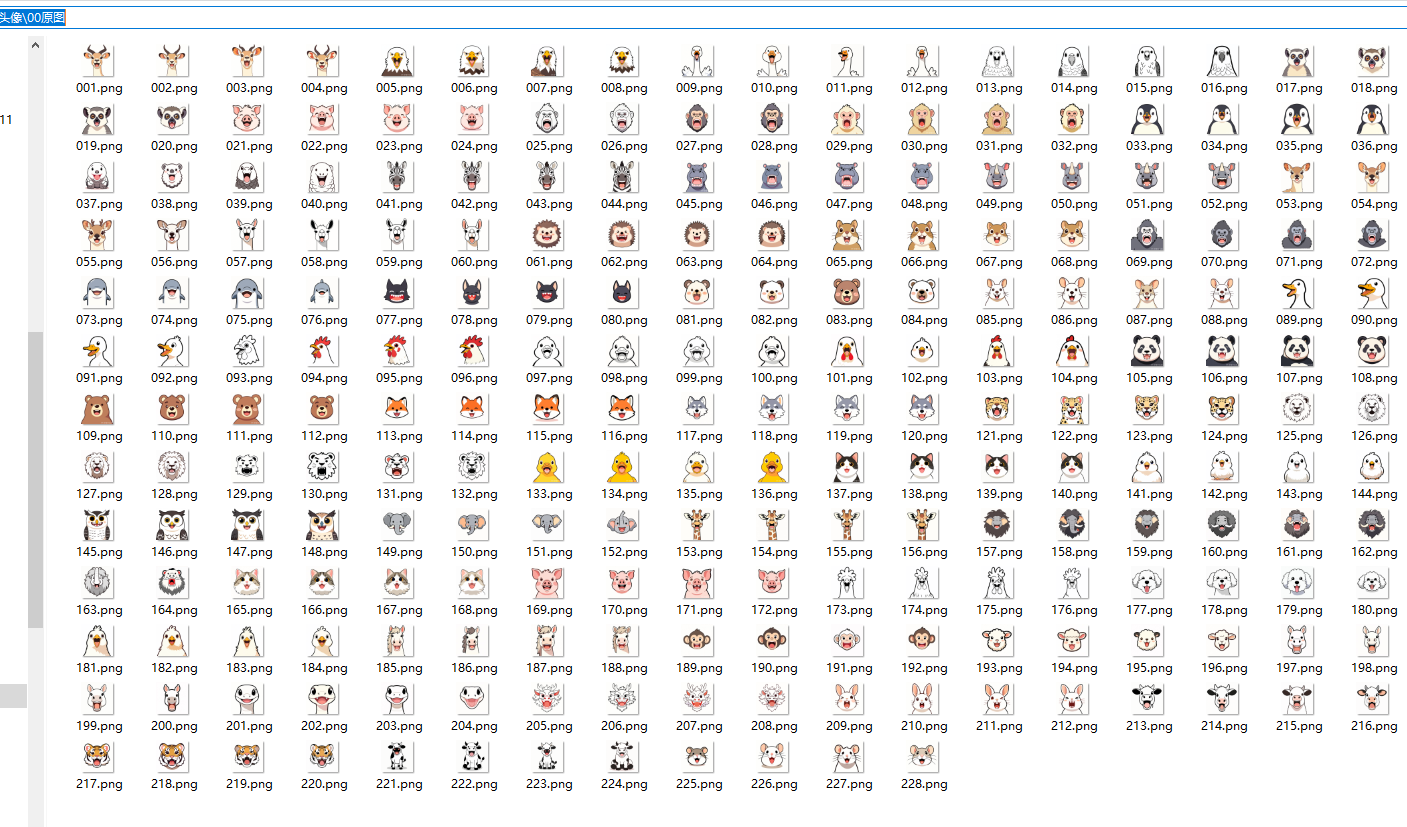
一、圖像獲取
通義萬相:萬相2.1專業 萌系卡通

純白色背景,卡通簡筆畫,無顏色,一只羚羊的頭像,正面頭像,開口大笑,簡單筆畫,卡通,加粗黑白輪廓線,無色,幼兒插圖,線條畫,黑白漫畫線條藝術:,線描,粗輪廓,清晰的線條,矢量線。簡單,大,

通義萬相下載動物頭像

二、圖像處理
用程序把彩色圖片轉黑白藍圖,再切邊
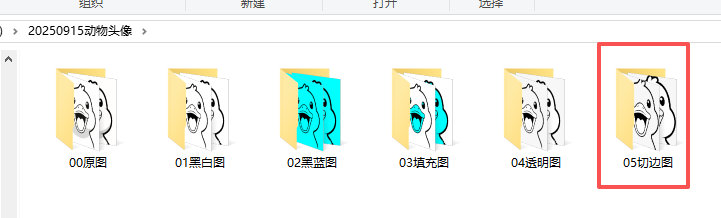
由于動物頭像輪廓線沒有封閉,所以很多圖像沒有實現內部填充白色(還是透明的)

手動挑選,適合的動物頭像
為了節省墨水,黑色多的圖案刪除

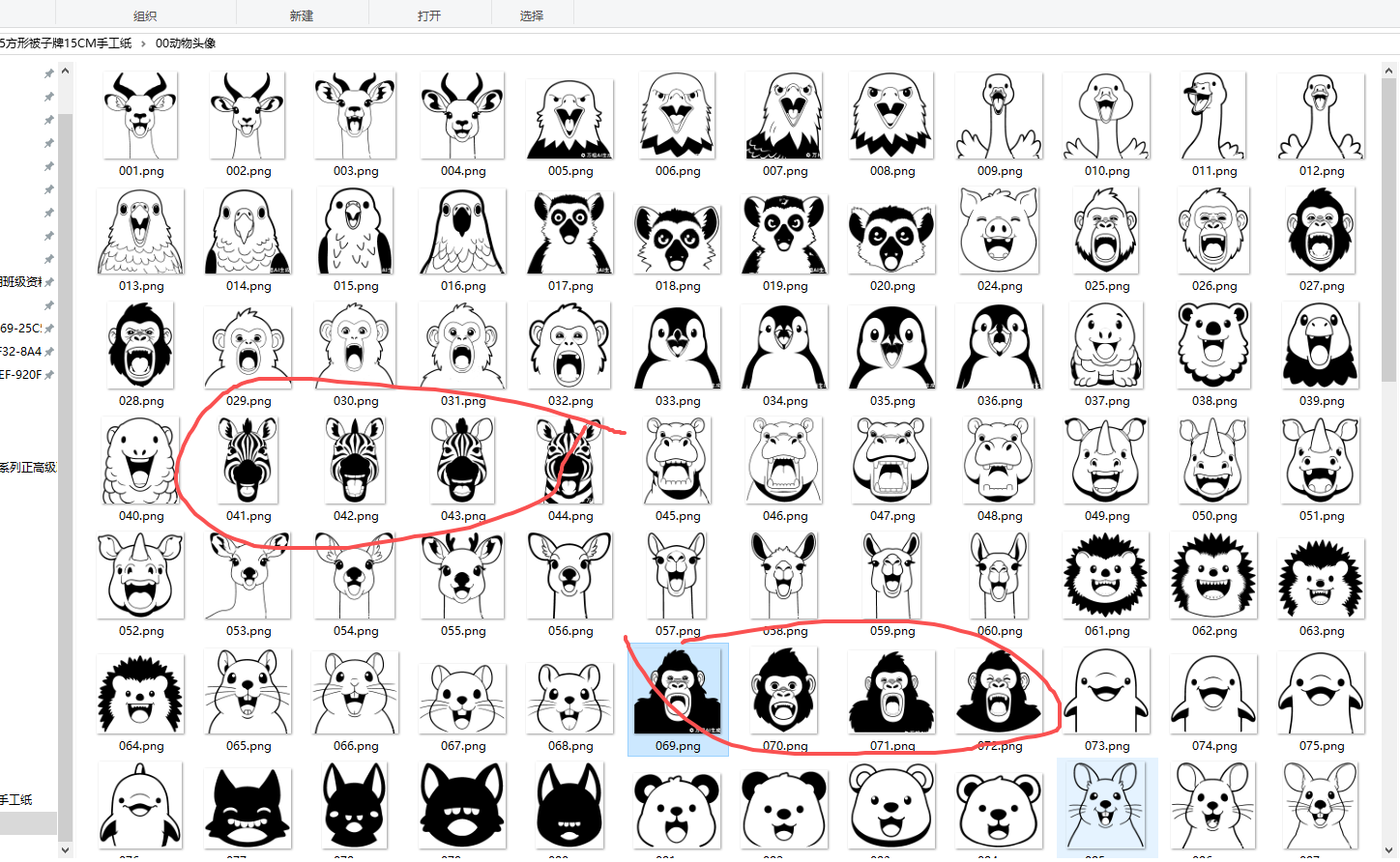
全選,看看透明部分,刪除臉部是透明的圖片,我需要的是臉部是白色的圖片

因為學額最大是35人,圓牌是一頁6張*6=最多36人,方卡片是一頁9張*4=最多36人。所以我留了36種動物頭像
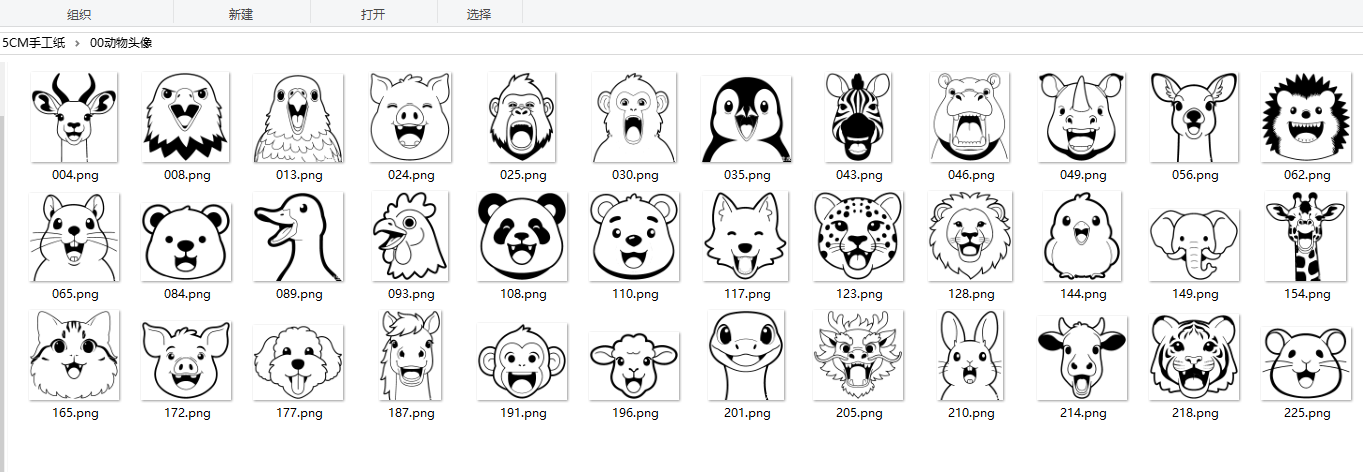
他們的長寬不同。

三、模版制作
在PPT里修改背景圖片的樣式,把打孔圓形上移,做一個2CM的動物圖片位子灰線框
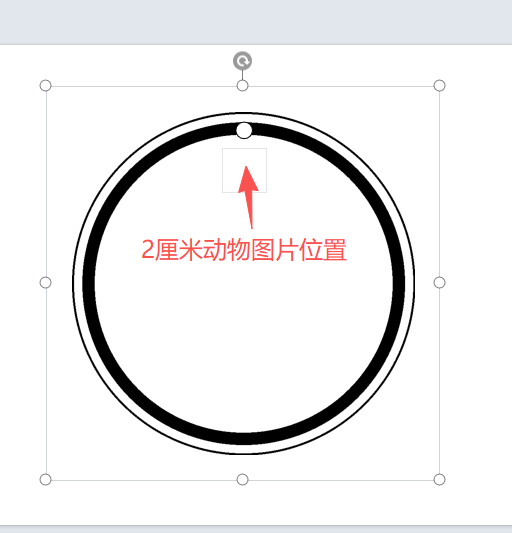
原來代碼的參數(9CM大小,一頁6個圓圈)在此基礎上,增大文字大小
https://blog.csdn.net/reasonsummer/article/details/151996771?spm=1011.2415.3001.5331 https://blog.csdn.net/reasonsummer/article/details/151996771?spm=1011.2415.3001.5331
https://blog.csdn.net/reasonsummer/article/details/151996771?spm=1011.2415.3001.5331
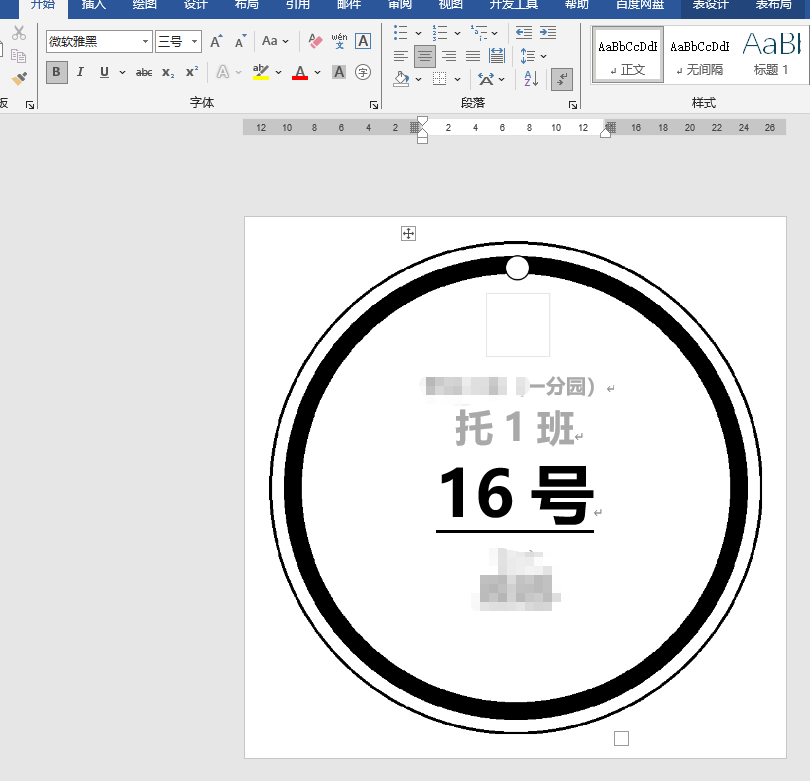
手動修改字體大小、字間距
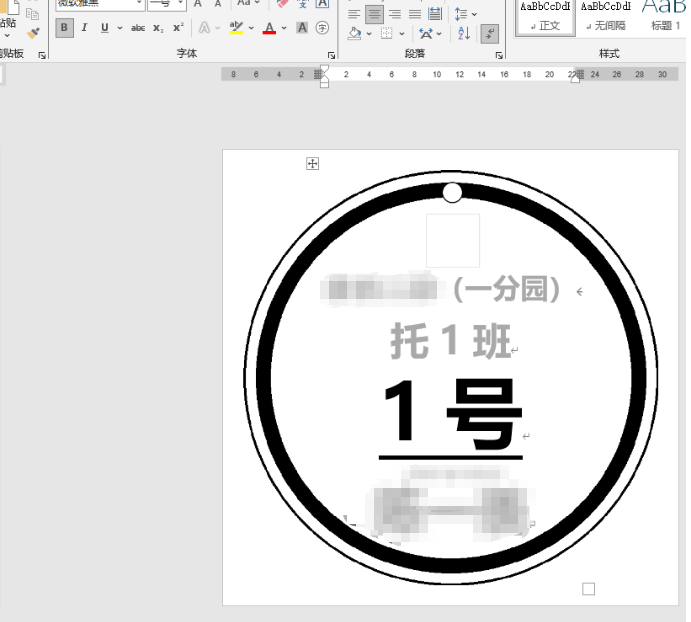
四、代碼修改
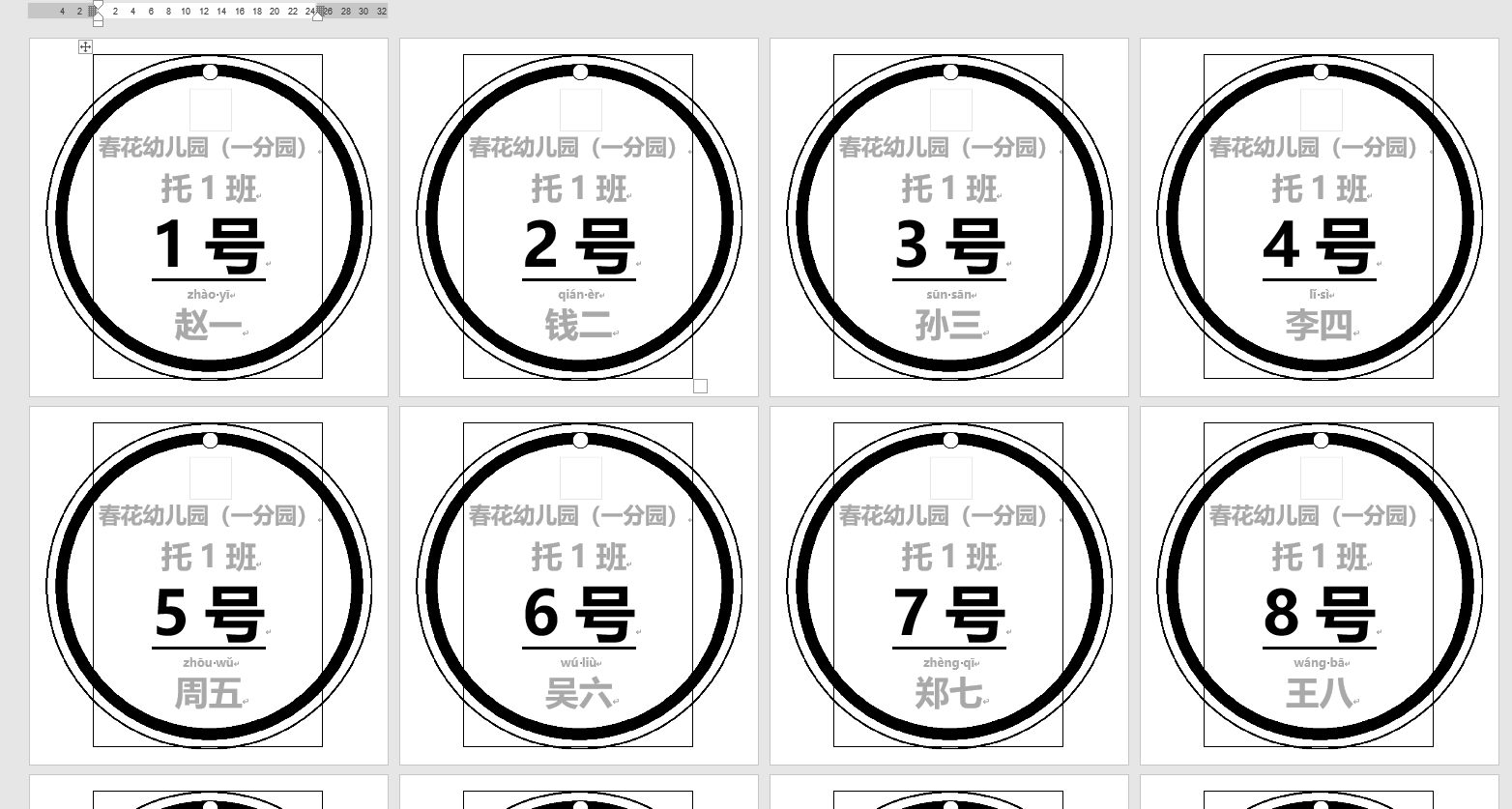
無動物圖的15CM手工紙打印效果(無拼音表)
# -*- coding:utf-8 -*-
'''
制作被子圓牌(word合并)多個班級-湊滿整夜,如托班20人,湊滿6*4頁、中班30人,湊滿5頁,不存在的名字都是"張三"占位用,以后有插班生就可以自己修改名字了
預先再word里面頁面背景-紋理,插入A4大小的圖片背景(有6個園),
一個人兩個牌子(被子圓牌、接送牌)
15CM手工紙大小(單面沒有動物)
deepseek,豆包 阿夏
20250923
修改:每個名字制作2個相同的掛牌,一頁3個名字*2
'''
import os
import pandas as pd
from docx import Document
from docx.shared import Cm
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT
from docx.shared import Pt # 用于設置字體大小
from docx.oxml.ns import qn # 用于設置中文字體
from pypinyin import pinyin, Style
from docx.enum.table import WD_CELL_VERTICAL_ALIGNMENT
from docx.shared import RGBColor # 用于設置字體顏色
import shutil
import time
import re
# ========== 1. 核心配置(僅修改此部分路徑) ==========
base_dir = r'c:\Users\jg2yXRZ\OneDrive\桌面\20250915方形被子牌15CM手工紙'
excel_file = os.path.join(base_dir, "班級信息表.xlsx") # Excel數據路徑
template_word = os.path.join(base_dir, "15厘米手工紙模版(無動物).docx") # 現有3行2列表格模板
output_dir = os.path.join(base_dir, "零時文件夾") # 結果保存目錄
editable_dir = os.path.join(base_dir, "20251005手工紙15CM無動物圓形掛牌(word編輯)" ) # 新建的可編輯文件夾
os.makedirs(output_dir, exist_ok=True) # 創建結果目錄
os.makedirs(editable_dir, exist_ok=True) # 創建可編輯文件夾
# 每個名字制作的份數(一個名字兩張卡,連在一起的
COPIES_PER_NAME = 1
# 定義各年級的固定人數(現在每個名字做2個,所以實際人數減半)
GRADE_SIZES = {
"托": 24*COPIES_PER_NAME, # 托班20人(湊滿4張)
"小": 30*COPIES_PER_NAME, # 小班25人(5張)
"中": 30*COPIES_PER_NAME, # 中班30人(5張)
"大": 35*COPIES_PER_NAME # 大班35人(6張)
}
# ========== 2. Excel數據讀取與拼音生成(保留核心邏輯) ==========
def read_excel_and_generate_pinyin(file_path):
"""讀取Excel數據,生成帶聲調的姓名拼音,返回{班級名: 學生數據列表}"""
# 特殊姓氏讀音校正(確保拼音準確性)
SPECIAL_SURNAMES = {
"樂": "Yuè", "單": "Shàn", "解": "Xiè", "查": "Zhā",
"蓋": "Gě", "仇": "Qiú", "種": "Chóng", "樸": "Piáo",
"翟": "Zhái", "區": "ōu", "繁": "Pó", "覃": "Qín",
"召": "Shào", "華": "Huà", "紀": "Jǐ", "曾": "Zēng",
"繆": "Miào", "員": "Yùn", "車": "Chē", "過": "Guō",
"尉": "Yù", "萬": "Wàn"
}
COMPOUND_SURNAMES = {
"歐陽": "ōu yáng", "上官": "Shàng guān", "皇甫": "Huáng fǔ",
"尉遲": "Yù chí", "萬俟": "Mò qí", "長孫": "Zhǎng sūn",
"司徒": "Sī tú", "司空": "Sī kōng", "司徒": "Sī tú",
"諸葛": "Zhū gě", "東方": "Dōng fāng", "獨孤": "Dú gū",
"慕容": "Mù róng", "宇文": "Yǔ wén"
}
def correct_name_pinyin(name):
"""生成帶聲調的姓名拼音(姓氏校正)"""
if not name or not isinstance(name, str):
return ""
name = name.strip()
# 優先處理復姓
for compound_surn in COMPOUND_SURNAMES:
if name.startswith(compound_surn):
surn_pinyin = COMPOUND_SURNAMES[compound_surn]
given_name = name[len(compound_surn):]
given_pinyin = ' '.join([p[0] for p in pinyin(given_name, style=Style.TONE)])
return f"{surn_pinyin} {given_pinyin}"
# 處理單姓多音字
first_char = name[0]
if first_char in SPECIAL_SURNAMES:
surn_pinyin = SPECIAL_SURNAMES[first_char]
given_name = name[1:]
given_pinyin = ' '.join([p[0] for p in pinyin(given_name, style=Style.TONE)])
return f"{surn_pinyin} {given_pinyin}"
# 普通姓名拼音
return ' '.join([p[0] for p in pinyin(name, style=Style.TONE)])
try:
# 讀取所有工作表
excel = pd.ExcelFile(file_path)
sheet_names = excel.sheet_names
class_data = {}
for sheet_name in sheet_names:
# 跳過非班級工作表(如果有的話)
if not any(keyword in sheet_name for keyword in ["班", "class", "Class"]):
continue
df = pd.read_excel(file_path, sheet_name=sheet_name, usecols=range(5), header=None, dtype={0: str})
df = df.iloc[1:] # 跳過第1行標題
student_list = []
for idx, row in df.iterrows():
# 過濾無效數據(學號為空、姓名為空)
raw_id = str(row[0]).strip() if pd.notna(row[0]) else ""
name = str(row[3]).strip() if pd.notna(row[3]) else ""
if not raw_id.isdigit() or not name: # 如果沒有學號,沒有名字
name='張三'
elif not name: # 如果有學號,沒有名字
name='張三'
# 提取核心信息
student_info = {
"campus": "春花幼兒園(" + (str(row[1]).strip() if pd.notna(row[1]) else "")+")", # 園區
"class_name": str(row[2]).strip() if pd.notna(row[2]) else "", # 班級
"student_id": f"{int(raw_id)}號", # 學號(如:1號)
"name": name, # 姓名
"name_pinyin": correct_name_pinyin(name) # 帶聲調拼音
}
student_list.append(student_info)
if student_list:
print(f"讀取[{sheet_name}]:{len(student_list)}個有效學生")
class_data[sheet_name] = student_list
else:
print(f"工作表[{sheet_name}]無有效學生數據")
return class_data
except Exception as e:
print(f"Excel讀取失敗:{str(e)}")
return {}
def get_grade_size(class_name):
"""根據班級名稱獲取對應的固定人數"""
# 提取班級名稱中的年級信息
if "托" in class_name:
return GRADE_SIZES["托"]
elif "小" in class_name:
return GRADE_SIZES["小"]
elif "中" in class_name:
return GRADE_SIZES["中"]
elif "大" in class_name:
return GRADE_SIZES["大"]
else:
# 默認返回小班人數
return GRADE_SIZES["小"]
def expand_student_list(student_list, target_size, class_name):
"""擴展學生列表到目標大小,用空學生填充"""
# 因為每個名字要做2份,所以實際需要的名字數量是目標大小的一半
name_count_needed = target_size // COPIES_PER_NAME
if len(student_list) >= name_count_needed:
return student_list[:name_count_needed] # 如果實際學生多于目標,截取前name_count_needed個
# 擴展學生列表
expanded_list = student_list.copy()
# 獲取園區和班級名稱(從第一個有效學生獲取)
campus = student_list[0]["campus"] if student_list else "春花幼兒園"
class_name_full = student_list[0]["class_name"] if student_list else class_name
# 添加空學生
for i in range(len(student_list), name_count_needed):
empty_student = {
"campus": campus,
"class_name": class_name_full,
"student_id": f"{i+1}號",
"name": "張三", # 空姓名
"name_pinyin": "Zhang San" # 空拼音
}
expanded_list.append(empty_student)
return expanded_list
def duplicate_students_for_copies(student_list):
"""為每個學生復制COPIES_PER_NAME份"""
duplicated_list = []
for student in student_list:
for i in range(COPIES_PER_NAME):
duplicated_list.append(student.copy())
return duplicated_list
# ========== 3. 寫入Word表格(3行2列,單個單元格含5種信息+回車) ==========
def write_student_to_word(student_list, template_path, output_path, class_name):
"""
將學生數據寫入Word模板的3行2列表格
單個單元格內容:園區\n班級\n學號\n拼音\n姓名(按此順序換行)
字體:微軟雅黑;拼音大小:10pt;姓名大小:20pt;其他信息:14pt
顏色:班級、拼音、姓名為灰色,學號為黑色
"""
# 根據班級類型確定目標人數
target_size = get_grade_size(class_name)
print(f"班級 {class_name} 目標人數: {target_size}, 實際人數: {len(student_list)}")
# 擴展學生列表到目標大小(注意:現在擴展的是名字數量,不是總掛牌數)
expanded_student_list = expand_student_list(student_list, target_size, class_name)
# 為每個名字復制COPIES_PER_NAME份
final_student_list = duplicate_students_for_copies(expanded_student_list)
print(f"復制后總掛牌數: {len(final_student_list)} (每個名字{COPIES_PER_NAME}份)")
# 按1個學生一組分割只有一個孩子
student_groups = [final_student_list[i:i+1] for i in range(0, len(final_student_list), 1)]
generated_files = [] # 存儲生成的文件路徑
for group_idx, group in enumerate(student_groups, 1):
# 復制模板文件(避免修改原模板)
temp_template = os.path.join(output_path, f"temp_{class_name}_{group_idx}.docx")
shutil.copy2(template_path, temp_template)
# 打開復制后的模板,操作表格
doc = Document(temp_template)
# 獲取模板中的第一個表格(需確保"掛牌2.docx"的第一個表格是3行2列")
if not doc.tables:
print(f"模板{template_path}中未找到表格,跳過此組")
os.remove(temp_template)
continue
table = doc.tables[0]
# 清除表格原有內容
for row in table.rows:
for cell in row.cells:
for para in cell.paragraphs:
p = para._element
p.getparent().remove(p)
cell._element.clear() # 完全清空單元格
# 定義字體樣式
def set_paragraph_style(para, text, font_size, is_bold=False, is_gray=True, underline=False):
"""設置段落的字體、大小、對齊(居中)和顏色"""
if not text: # 跳過空文本
return
run = para.add_run(text)
# 設置中文字體為微軟雅黑
run.font.name = '微軟雅黑'
run.element.rPr.rFonts.set(qn('w:eastAsia'), '微軟雅黑')
run.font.size = Pt(font_size)
run.font.bold = is_bold
run.font.underline = underline # 設置下劃線
# 設置顏色:灰色或黑色
if is_gray:
run.font.color.rgb = RGBColor(169, 169, 169) # DarkGray
else:
run.font.color.rgb = RGBColor(0, 0, 0) # 黑色
para.alignment = WD_PARAGRAPH_ALIGNMENT.CENTER # 文字居中
# 逐個單元格寫入學生信息(3行2列,共6個單元格)
cell_index = 0 # 單元格索引(0-5對應3行2列的6個單元格)
for row_idx, row in enumerate(table.rows):
for cell_idx, cell in enumerate(row.cells):
if cell_index >= len(group):
break # 學生不足6個時,空單元格跳過
# 添加這行代碼:設置單元格垂直居中
cell.vertical_alignment = WD_CELL_VERTICAL_ALIGNMENT.CENTER
# 當前學生的5種信息(按"園區→班級→學號→拼音→姓名"順序")
student = group[cell_index]
info_lines = [
student["campus"], # 第1行:園區
student["class_name"], # 第2行:班級
student["student_id"], # 第3行:學號
student["name_pinyin"], # 第4行:拼音(10pt)
student["name"] # 第5行:姓名(20pt,加粗)
]
# 向單元格寫入內容(每行單獨設置字體大小和顏色)
for line_idx, line in enumerate(info_lines):
if line: # 只寫入非空內容
para = cell.add_paragraph()
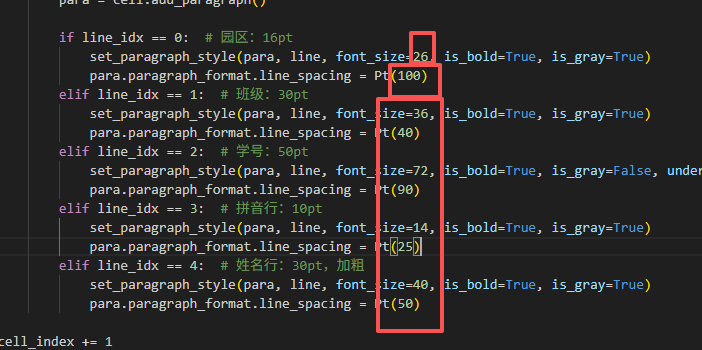
if line_idx == 0: # 園區:16pt
set_paragraph_style(para, line, font_size=26, is_bold=True, is_gray=True)
para.paragraph_format.line_spacing = Pt(100)
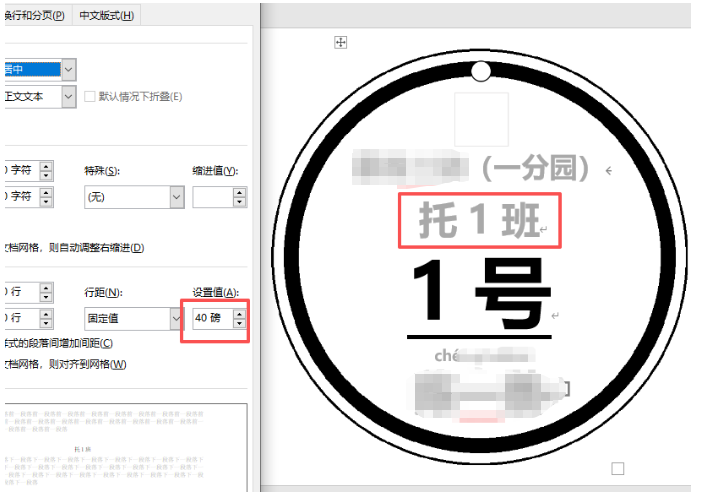
elif line_idx == 1: # 班級:30pt
set_paragraph_style(para, line, font_size=36, is_bold=True, is_gray=True)
para.paragraph_format.line_spacing = Pt(40)
elif line_idx == 2: # 學號:50pt
set_paragraph_style(para, line, font_size=72, is_bold=True, is_gray=False, underline=True)
para.paragraph_format.line_spacing = Pt(90)
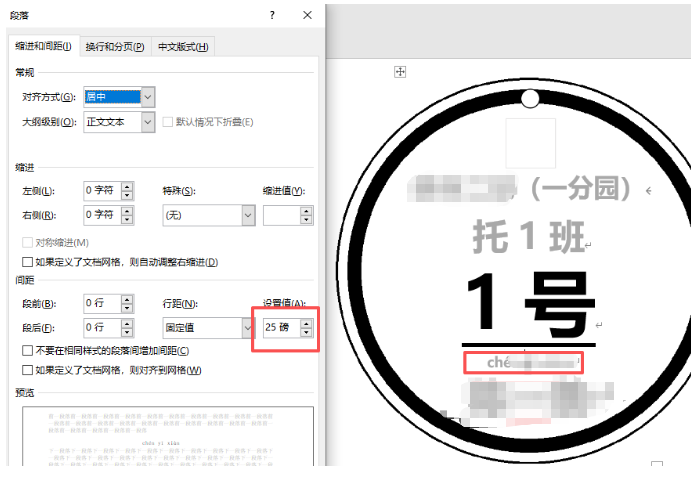
elif line_idx == 3: # 拼音行:10pt
set_paragraph_style(para, line, font_size=14, is_bold=True, is_gray=True)
para.paragraph_format.line_spacing = Pt(25)
elif line_idx == 4: # 姓名行:30pt,加粗
set_paragraph_style(para, line, font_size=40, is_bold=True, is_gray=True)
para.paragraph_format.line_spacing = Pt(50)
cell_index += 1
# 保存當前組的Word文件
final_word_path = os.path.join(output_path, f"{class_name}_掛牌_{group_idx:02d}.docx")
doc.save(final_word_path)
generated_files.append(final_word_path) # 添加到生成文件列表
os.remove(temp_template) # 刪除臨時模板
print(f"生成第{group_idx}組Word:{os.path.basename(final_word_path)}")
return generated_files
def merge_docx_files_with_win32(template_file, files_list, output_filename):
"""使用win32com合并Word文檔,去掉換頁符"""
if not files_list:
print("沒有文件可合并")
return
word = None
doc = None
try:
# 啟動Word應用程序
import win32com.client as win32
word = win32.Dispatch("Word.Application")
word.Visible = False # 不顯示Word界面
word.DisplayAlerts = False # 不顯示警告
# 復制模板文件到輸出文件
shutil.copy2(template_file, output_filename)
# 打開輸出文件
doc = word.Documents.Open(output_filename)
# 將光標移動到文檔末尾
selection = word.Selection
selection.EndKey(6) # wdStory = 6, 移動到文檔末尾
# 逐個插入其他文件的內容(跳過第一個文件,因為已經是模板)
for i, file_path in enumerate(files_list):
if i == 0: # 跳過模板文件本身
continue
print(f"正在插入文件: {os.path.basename(file_path)}")
# 插入文件內容
selection.InsertFile(file_path)
# 移動到文檔末尾準備插入下一個文件
selection.EndKey(6)
time.sleep(1) # 添加延時,確保Word有足夠時間處理
# 保存合并后的文檔
doc.Save()
print(f"已合并所有文檔到:{output_filename}")
except Exception as e:
print(f"合并文檔時出錯:{e}")
# 嘗試使用備選方法
try:
print("嘗試使用備選合并方法...")
merge_docx_files_simple(template_file, files_list, output_filename)
except Exception as e2:
print(f"備選方法也失敗:{e2}")
finally:
# 確保正確關閉文檔和Word應用程序
try:
if doc:
doc.Close(False)
time.sleep(0.5)
except:
pass
try:
if word:
word.Quit()
time.sleep(0.5)
except:
pass
def merge_docx_files_simple(template_file, files_list, output_filename):
"""簡單的合并方法:復制模板,然后逐個追加內容"""
# 復制模板文件
shutil.copy2(template_file, output_filename)
# 打開模板文件
main_doc = Document(output_filename)
# 逐個添加其他文件的內容
for i, file_path in enumerate(files_list):
if i == 0: # 跳過模板文件本身
continue
# 添加分頁符
if i > 1: # 從第二個文件開始添加分頁符
main_doc.add_page_break()
# 讀取要添加的文件
sub_doc = Document(file_path)
# 復制表格內容
for table in sub_doc.tables:
# 創建新表格
new_table = main_doc.add_table(rows=len(table.rows), cols=len(table.columns))
# 復制內容和格式
for row_idx, row in enumerate(table.rows):
for col_idx, cell in enumerate(row.cells):
new_cell = new_table.cell(row_idx, col_idx)
# 清空新單元格
for paragraph in new_cell.paragraphs:
p = paragraph._element
p.getparent().remove(p)
new_cell._element.clear()
# 復制內容
for paragraph in cell.paragraphs:
new_para = new_cell.add_paragraph()
for run in paragraph.runs:
new_run = new_para.add_run(run.text)
# 復制字體樣式
new_run.font.name = run.font.name
new_run.font.size = run.font.size
new_run.font.bold = run.font.bold
new_run.font.underline = run.font.underline
if hasattr(run.font.color, 'rgb'):
new_run.font.color.rgb = run.font.color.rgb
# 保存合并后的文檔
main_doc.save(output_filename)
print(f"使用簡單方法合并完成:{output_filename}")
def cleanup_directory(directory_path):
"""清理目錄"""
try:
if os.path.exists(directory_path):
shutil.rmtree(directory_path)
print(f"已刪除目錄: {directory_path}")
except Exception as e:
print(f"刪除目錄時出錯: {e}")
# ========== 4. 主程序(處理所有班級) ==========
if __name__ == "__main__":
# 步驟1:讀取Excel數據(含拼音生成)
print("=== 開始讀取Excel數據 ===")
class_data = read_excel_and_generate_pinyin(excel_file)
if not class_data:
print("無有效學生數據,程序退出")
exit()
# 為每個班級創建單獨的輸出目錄
class_output_dirs = {}
for class_name in class_data.keys():
class_dir = os.path.join(output_dir, class_name)
os.makedirs(class_dir, exist_ok=True)
class_output_dirs[class_name] = class_dir
# 步驟2:遍歷每個班級,寫入Word表格
all_merged_files = []
for sheet_name, student_list in class_data.items():
# 獲取班級名稱(取第一個學生的班級信息)
class_name = student_list[0]["class_name"] if student_list else sheet_name
print(f"\n=== 處理班級:{class_name} ===")
# 步驟3:寫入Word(3行2列表格,6個學生一組)
generated_files = write_student_to_word(
student_list=student_list,
template_path=template_word,
output_path=class_output_dirs[sheet_name],
class_name=class_name
)
# 步驟4:為每個班級合并所有生成的docx文件
if generated_files:
# 使用第一個文件作為模板
template_file = generated_files[0]
# 合并后的文件保存到可編輯文件夾
merged_filename = os.path.join(editable_dir, f"20250923_{class_name}_15CM圓形牌(無動物)_word編輯(接送&被子&床卡,一人兩塊圓牌).docx")
print(f"開始合并{class_name}的文檔...")
try:
merge_docx_files_with_win32(template_file, generated_files, merged_filename)
all_merged_files.append(merged_filename)
print(f"{class_name}合并完成")
except Exception as e:
print(f"{class_name}的win32合并失敗,嘗試簡單方法: {e}")
try:
merge_docx_files_simple(template_file, generated_files, merged_filename)
all_merged_files.append(merged_filename)
print(f"{class_name}使用簡單方法合并完成")
except Exception as e2:
print(f"{class_name}的所有合并方法都失敗: {e2}")
# 處理完一個班級后稍作延時,釋放資源
time.sleep(2)
# 步驟5:清理臨時文件
print("\n=== 清理臨時文件 ===")
cleanup_directory(output_dir)
print(f"\n=== 所有處理完成 ===")
print(f"合并后的文件已保存到:{editable_dir}")
print(f"生成的合并文件:")
for file in all_merged_files:
print(f" - {os.path.basename(file)}")
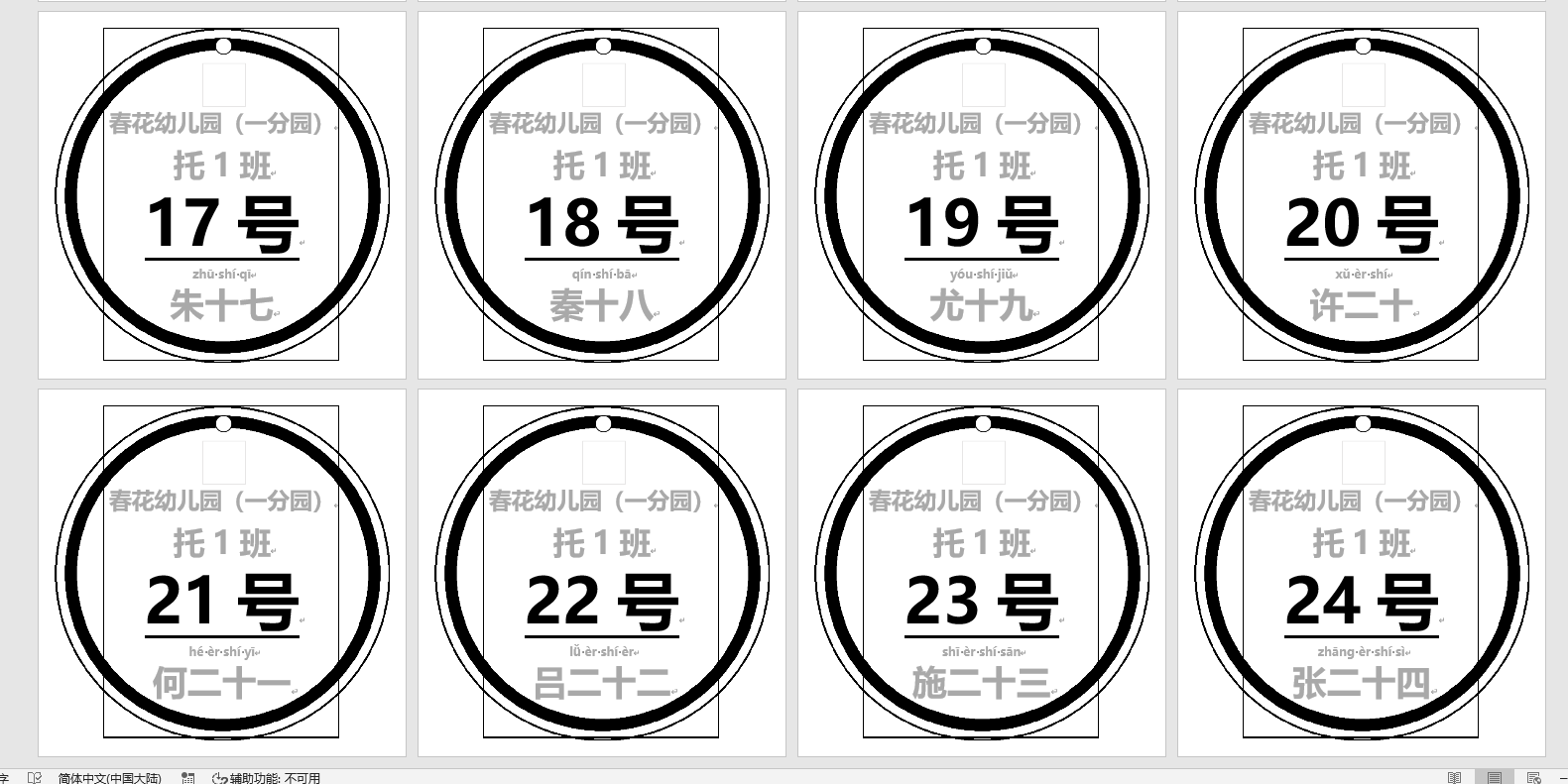
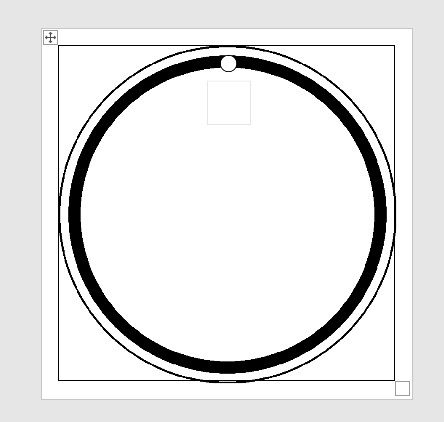
我在模版里把邊框取消

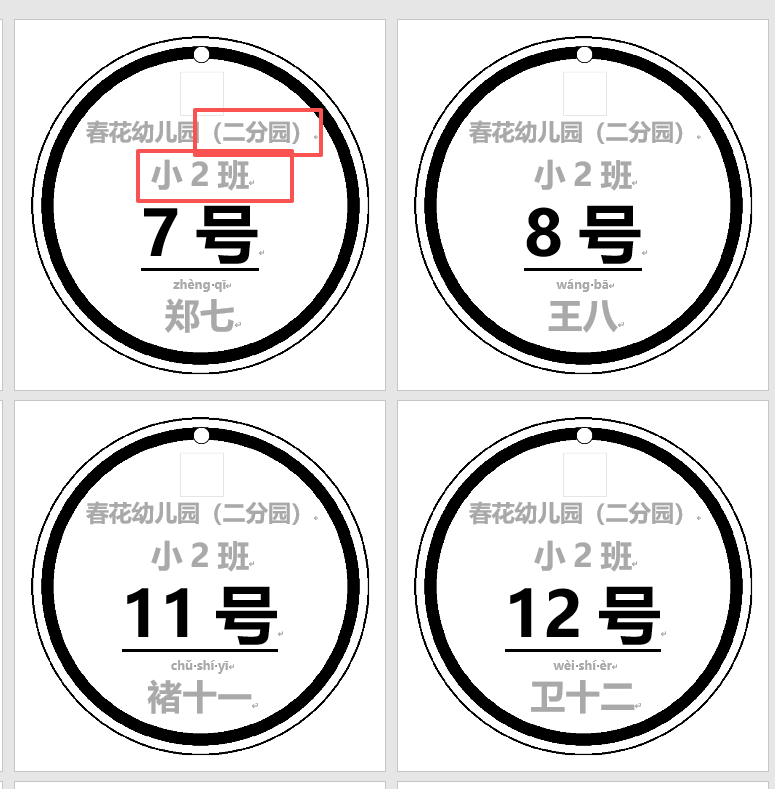
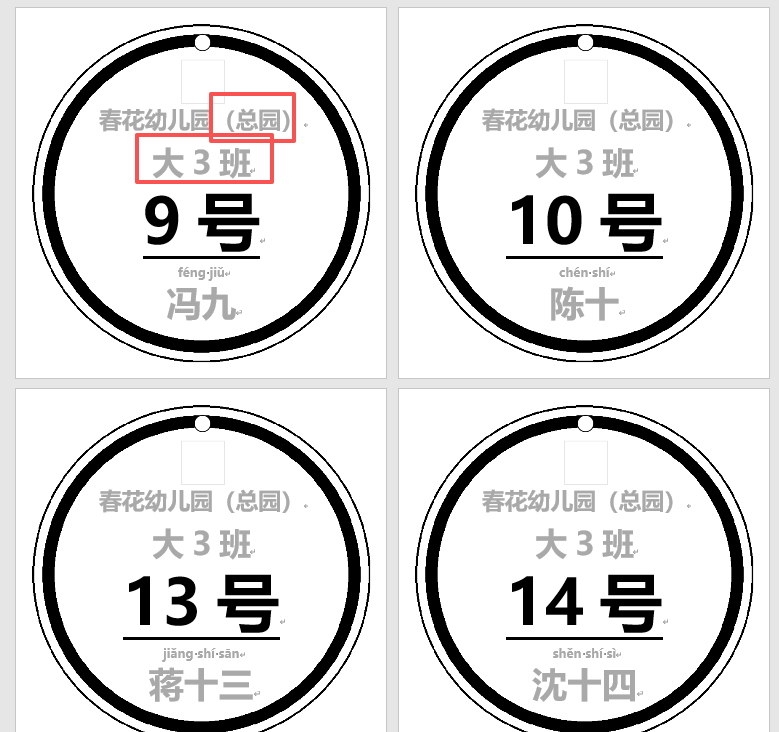
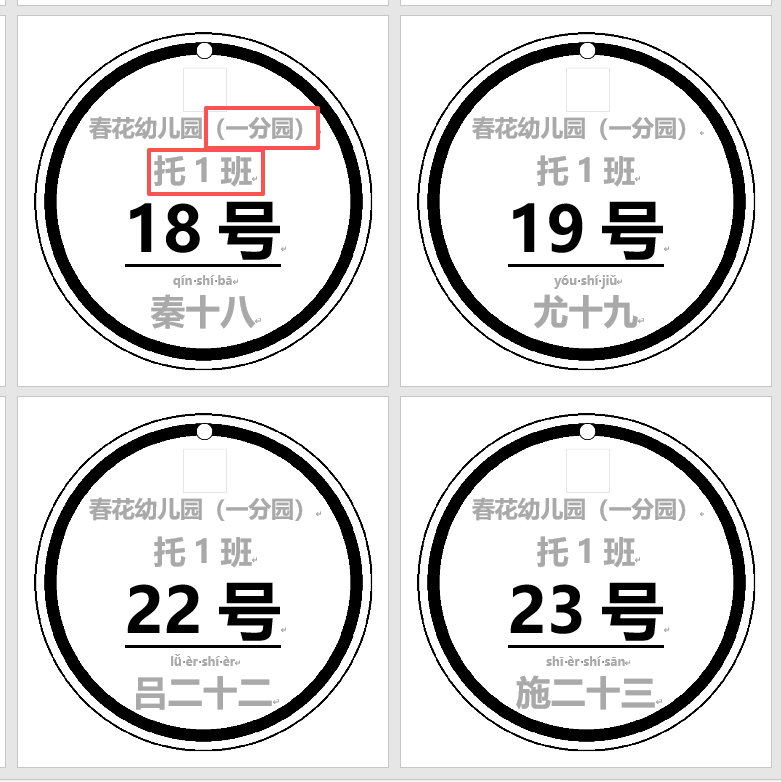
無動物圖的15CM手工紙打印效果(有拼音表)
# -*- coding:utf-8 -*-
'''
制作被子圓牌(word合并)多個班級-湊滿整夜,如托班20人,湊滿6*4頁、中班30人,湊滿5頁,不存在的名字都是"張三"占位用,以后有插班生就可以自己修改名字了
預先再word里面頁面背景-紋理,插入A4大小的圖片背景(有6個園),
一個人兩個牌子(被子圓牌、接送牌)
15CM手工紙大小(單面沒有動物)
deepseek,豆包 阿夏
20250923
修改:每個名字制作2個相同的掛牌,一頁3個名字*2
新增:在文檔末尾插入拼音表
'''
import os
import pandas as pd
from docx import Document
from docx.shared import Cm
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT
from docx.shared import Pt # 用于設置字體大小
from docx.oxml.ns import qn # 用于設置中文字體
from pypinyin import pinyin, Style
from docx.enum.table import WD_CELL_VERTICAL_ALIGNMENT
from docx.shared import RGBColor # 用于設置字體顏色
import shutil
import time
import re
import win32com.client as


 浙公網安備 33010602011771號
浙公網安備 33010602011771號