
RDD概念、特性、緩存策略與容錯
一、RDD概念與特性
1. RDD的概念
RDD(Resilient Distributed Dataset),是指彈性分布式數(shù)據(jù)集。數(shù)據(jù)集:Spark中的編程是基于RDD的,將原始數(shù)據(jù)加載到內(nèi)存變成RDD,RDD再經(jīng)過若干次轉(zhuǎn)化,仍為RDD。分布式:讀數(shù)據(jù)一般都是從分布式系統(tǒng)中去讀,如hdfs、kafka等,所以原始文件存在磁盤是分布式的,spark加載完數(shù)據(jù)的RDD也是分布式的,換句話說RDD是抽象的概念,實際數(shù)據(jù)仍在分布式文件系統(tǒng)中;因為有了RDD,在開發(fā)代碼過程會非常方便,只需要將原始數(shù)據(jù)理解為一個集合,然后對集合進行操作即可。RDD里面每一塊數(shù)據(jù)/partition,分布在某臺機器的物理節(jié)點上,這是物理概念。彈性:這里是指數(shù)據(jù)集會進行轉(zhuǎn)換,所以會忽大忽小,partition數(shù)量忽多忽少。
2. RDD的特性
Spark-1.6.1源碼在org.apache.spark.rdd下的RDD.scala指出了每一個RDD都具有五個主要特點,如下:

- A list of partion
RDD是由一組partition組成。例如要讀取hdfs上的文本文件的話,可以使用textFile()方法把hdfs的文件加載過來,把每臺機器的數(shù)據(jù)放到partition中,并且封裝了一個HadoopRDD,這就是一個抽象的概念。每一個partition都對應(yīng)了機器中的數(shù)據(jù)。因為在hdfs中的一個Datanode,有很多的block,讀機器的數(shù)據(jù)時,會將每一個block變成一個partition,與MapReduce中split的大小由min split,max split,block size (max(min split, min(max split, block size)))決定的相同,spark中的partition大小實際上對應(yīng)了一個split的大小。經(jīng)過轉(zhuǎn)化,HadoopRDD會轉(zhuǎn)成其他RDD,如FilteredRDD、PairRDD等,但是partition還是相應(yīng)的partition,只是因為有函數(shù)應(yīng)用里面的數(shù)據(jù)變化了。
- A function for computing each split
對每個split(partition)都有函數(shù)操作。一個函數(shù)應(yīng)用在一個RDD上,可以理解為一個函數(shù)對集合(RDD)內(nèi)的每個元素(split)的操作。
- A list of dependencies on other RDDs
一個RDD依賴于一組RDD。例如,下列代碼片段
val lines=sc.textFlie("hdfs://namenode:8020/path/file.txt")
val wc=lines.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).sortBy(_._2)
wc.foreach(println)
sc.stop()
這里就存在RDD的依賴關(guān)系。
- Optionally, a Partitioner for key-value RDDs
該可選項意思是對于一個RDD,如果其中的每一個元素是Key-Value形式時,可以傳一個Partitioner(自定義分區(qū)),讓這個RDD重新分區(qū)。這種情況的本質(zhì)是shuffle,多點到多點的數(shù)據(jù)傳輸。
- Optionally, a list of preferred locations to compute each split on
textFile()過程中,可以指定加載到性能好的機器中。例如,hdfs中的數(shù)據(jù)可能放在一大堆破舊的機器上,hdfs數(shù)據(jù)在磁盤上,磁盤可能很大,CPU、內(nèi)存的性能很差。Spark默認做的事情是,把數(shù)據(jù)加載進來,會把數(shù)據(jù)抽象成一個RDD,抽象進來的數(shù)據(jù)在內(nèi)存中,這內(nèi)存指的是本機的內(nèi)存,這是因為在分布式文件系統(tǒng)中,要遵循數(shù)據(jù)本地性原則,即移動計算(把函數(shù)、jar包發(fā)過去)而不移動數(shù)據(jù)(移動數(shù)據(jù)成本較高)。而一般hdfs的集群機器的內(nèi)存比較差,如果要把這么多數(shù)據(jù)加載到爛機器的內(nèi)存中,會存在問題,一是內(nèi)存可能裝不下,二是CPU差、計算能力差,這就等于沒有發(fā)揮出spark的性能。在這種情況下,Spark的RDD可以提供一個可選項,可以指定一個preferred locations,即指定一個位置來加載數(shù)據(jù)。這樣就可以指定加載到性能好的機器去計算。例如,可以將hdfs數(shù)據(jù)加載到Tachyon內(nèi)存文件系統(tǒng)中,然后再基于Tachyon來做spark程序。
二、RDD緩存策略
1. 源碼
源碼org.apache.spark.storage包下的StorageLevel.scala中定義緩存策略。
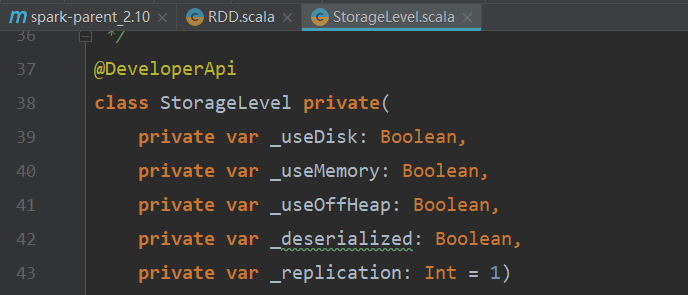
StorageLevel類默認的構(gòu)造器有五個屬性,如下圖所示:
2. 源碼解讀
- StorageLevel私有類的構(gòu)造器
class StorageLevel private( private var _useDisk: Boolean,/*使用磁盤*/ private var _useMemory: Boolean,/*使用內(nèi)存*/ private var _useOffHeap: Boolean,/*不使用堆內(nèi)存(堆在JVM中)*/ private var _deserialized: Boolean,/*不序列化*/ private var _replication: Int = 1)/*副本數(shù),默認為1*/
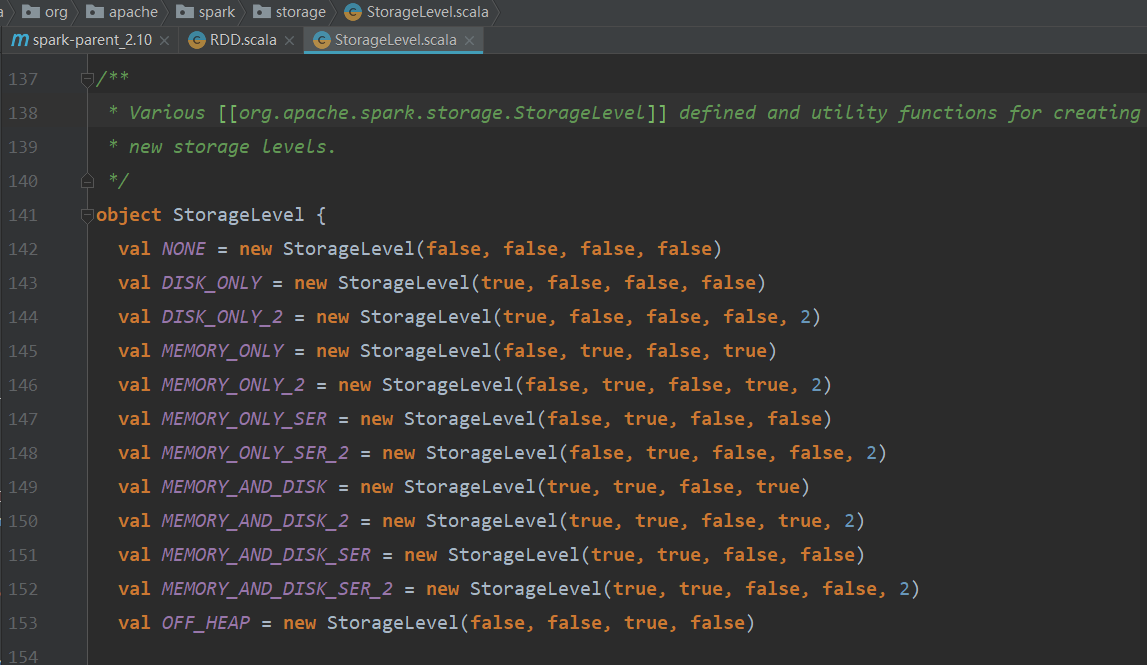
- NONE
val NONE = new StorageLevel(false, false, false, false)
NONE表示不需要緩存。(不使用磁盤,不用內(nèi)存,使用堆,序列化)
- DISK_ONLY
val DISK_ONLY = new StorageLevel(true, false, false, false)
DISK_ONLY表示使用磁盤。(使用磁盤,不用內(nèi)存,使用堆,序列化)
- DISK_ONLY_2
val DISK_ONLY_2 = new StorageLevel(true, false, false, false, 2)
DISK_ONLY_2表示使用磁盤,兩個副本。(使用磁盤,不用內(nèi)存,使用堆,序列化,2)
- MEMORY_ONLY
val MEMORY_ONLY = new StorageLevel(false, true, false, true)
MEMORY_ONLY表示只使用內(nèi)存,例如1G的數(shù)據(jù)要放入512M的內(nèi)存,會將數(shù)據(jù)切成兩份,先將512M加載到內(nèi)存,剩下的512M還在原來位置(如hdfs),之后如果有RDD的運算,會從內(nèi)存和磁盤中去找各自的512M數(shù)據(jù)。(不使用磁盤,使用內(nèi)存,使用堆,不序列化)
- MEMORY_ONLY_2
val MEMORY_ONLY_2 = new StorageLevel(false, true, false, true, 2)
MEMORY_ONLY_2表示只使用內(nèi)存,2個副本。(不使用磁盤,使用內(nèi)存,使用堆,不序列化,2)
- MEMORY_ONLY_SER
val MEMORY_ONLY_SER = new StorageLevel(false, true, false, false)
MEMORY_ONLY_SER表示只使用內(nèi)存,序列化。(不使用磁盤,使用內(nèi)存,使用堆,序列化)
- MEMORY_ONLY_SER_2
val MEMORY_ONLY_SER_2 = new StorageLevel(false, true, false, false, 2)
MEMORY_ONLY_SER表示只使用內(nèi)存,序列化,2個副本。(不使用磁盤,使用內(nèi)存,使用堆,序列化,2)
- MEMORY_AND_DISK
val MEMORY_AND_DISK = new StorageLevel(true, true, false, true)
MEMORY_AND_DISK和MEMORY_ONLY很類似,都使用到了內(nèi)存和磁盤,只是使用的是本機本地磁盤,例如1G數(shù)據(jù)要加載到512M的內(nèi)存中,首先將hdfs的1G數(shù)據(jù)的512M加載到內(nèi)存,另外的512M加載到本地的磁盤緩存著(和hdfs就沒有關(guān)系了),RDD要讀取數(shù)據(jù)的話就在內(nèi)存和本地磁盤中找。(使用磁盤,使用內(nèi)存,使用堆,不序列化)
- MEMORY_AND_DISK_2
val MEMORY_AND_DISK_2 = new StorageLevel(true, true, false, true, 2)
MEMORY_AND_DISK_2表示兩個副本。(使用磁盤,使用內(nèi)存,使用堆,不序列化,2)
- MEMORY_AND_DISK_SER
val MEMORY_AND_DISK_SER = new StorageLevel(true, true, false, false)
MEMORY_AND_DISK_SER本地內(nèi)存和磁盤,序列化。序列化的好處在于可以壓縮,但是壓縮就意味著要解壓縮,需要消耗一些CPU。
- MEMORY_AND_DISK_SER_2
val MEMORY_AND_DISK_SER_2 = new StorageLevel(true, true, false, false, 2)
MEMORY_AND_DISK_SER2,兩個副本。
- OFF_HEAP
val OFF_HEAP = new StorageLevel(false, false, true, false)
OFF_HEAP不使用堆內(nèi)存(例如可以使用Tachyon的分布式內(nèi)存文件系統(tǒng))。(不使用磁盤,不用內(nèi)存,不使用堆,序列化)
3. 緩存策略試驗
- 不緩存
package com.huidoo.spark import org.apache.spark.{SparkConf, SparkContext} object TestCache { def main(args: Array[String]): Unit = { val conf = new SparkConf().setAppName("TestCache").setMaster("local[2]") val sc = new SparkContext(conf) val lines = sc.textFile("hdfs://cdh01:8020/flume/2018-03-23/2230") //目錄下有17個文件,總大小約為335MB,不做緩存 val beginTime1 = System.currentTimeMillis() //記錄第1個job開始時間 val count1 = lines.count() //調(diào)用count()方法,會產(chǎn)生一個job val endTime1 = System.currentTimeMillis() //記錄第1個job結(jié)束時間 val beginTime2 = System.currentTimeMillis() //記錄第2個job開始時間 val count2 = lines.count() //調(diào)用count()方法,會產(chǎn)生一個job val endTime2 = System.currentTimeMillis() //記錄第2個job結(jié)束時間 println(count1) println("第1個job總共消耗時間" + (endTime1 - beginTime1) + "毫秒") println(count2) println("第2個job總共消耗時間" + (endTime2 - beginTime2) + "毫秒") sc.stop() } }
運行結(jié)果如下:

可見,所有文件的總行數(shù)為1935077行,第一個job和第二個job的用時分別為14.7s和12.2s,差別不大。
- 緩存
只需在原代碼基礎(chǔ)上將HadoopRDD lines添加調(diào)用cache()方法即可。
val lines = sc.textFile("hdfs://cdh01:8020/flume/2018-03-23/2230").cache() //目錄下有17個文件,總大小約為335MB,做緩存
運行結(jié)果如下:
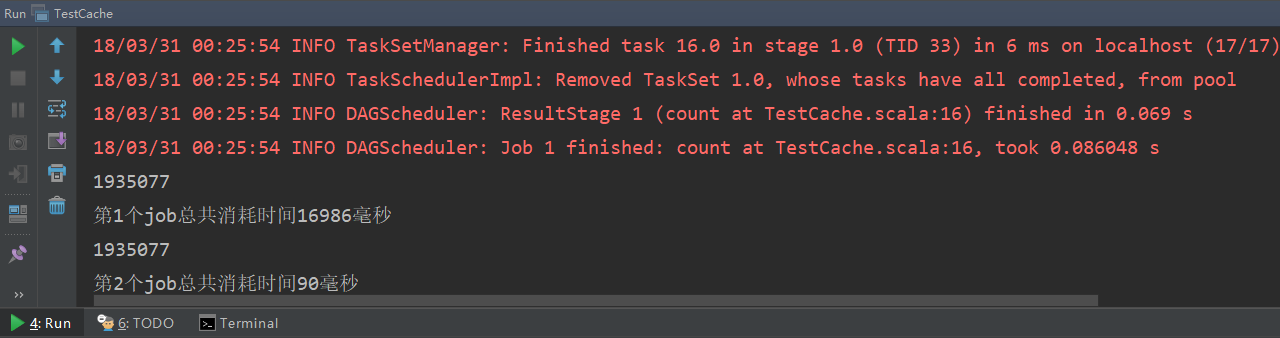
可見,所有文件的總行數(shù)為1935077行,第一個job和第二個job的用時分別為19.4s和0.09s,速度相比不做緩存明顯提升。這是因為沒有做緩存,第二個job還需要先從hdfs上讀取數(shù)據(jù),需要消耗更長時間;而做了緩存則直接從緩存中讀取(cache方法默認緩存策略是MEMORY_ONLY),所以速度會快很多。
三、RDD Lineage與容錯
1. Lineage(血統(tǒng))
一系列RDD到RDD的transformation操作,稱為lineage(血統(tǒng))。某個RDD依賴于它前面的所有RDD。例如一個由10個RDD到RDD的轉(zhuǎn)化構(gòu)成的lineage,如果在計算到第9個RDD時失敗了,一般較好的計算框架會自動重新計算。一般地,這種錯誤發(fā)生了會去找上一個RDD,但是實際上如果不做緩存是找不到的,因為即使RDD9知道它是由RDD8轉(zhuǎn)化過來的,但是因為它并沒有存RDD數(shù)據(jù)本身,在內(nèi)存中RDD瞬時轉(zhuǎn)化,瞬間就會在內(nèi)存中消失,所以還是找不到數(shù)據(jù)。如果這時RDD8做過cache緩存,那么就是在RDD8的時候進行了數(shù)據(jù)的保存并記錄了位置,這時如果RDD9失敗了就會從緩存中讀取RDD8的數(shù)據(jù);如果RDD8沒有做cache就會找RDD7,以此類推,如果都沒有做cache就需要重新從HDFS中讀取數(shù)據(jù)。所以所謂的容錯就是指,當計算過程復雜,為了降低因某些關(guān)鍵點計算出錯而需要重新計算的帶來的慘重代價的風險,則需要在某些關(guān)鍵點使用cache或用persist方法做一下緩存。
2. 容錯
- 容錯理論
上述緩存策略還存在一個問題。使用cache或persist的緩存策略是使用默認的僅在內(nèi)存,所以實際的RDD緩存位置是在內(nèi)存當中,如果機器出現(xiàn)問題,也會造成內(nèi)存中的緩存RDD數(shù)據(jù)丟失。所以可以將要做容錯的RDD數(shù)據(jù)存到指定磁盤(可以是hdfs)路徑中,可以對RDD做doCheckpoint()方法。使用doCheckpoint()方法的前提示,需要在sc中要先設(shè)置SparkContext.setCheckpointDir(),設(shè)置數(shù)據(jù)存儲路徑。這時候如果程序計算過程中出錯了,會先到cache中找緩存數(shù)據(jù),如果cache中沒有就會到設(shè)置的磁盤路徑中找。
在RDD計算,通過checkpoint進行容錯,做checkpoint有兩種方式,一個是checkpoint data,一個是logging the updates。用戶可以控制采用哪種方式來實現(xiàn)容錯,默認是logging the updates方式,通過記錄跟蹤所有生成RDD的轉(zhuǎn)換(transformations)也就是記錄每個RDD的lineage(血統(tǒng))來重新計算生成丟失的分區(qū)數(shù)據(jù)。
- 容錯源碼解讀
//RDD.scala中的doCheckpoint方法: /** * Performs the checkpointing of this RDD by saving this. It is called after a job using this RDD * has completed (therefore the RDD has been materialized and potentially stored in memory). * doCheckpoint() is called recursively on the parent RDDs. */ private[spark] def doCheckpoint(): Unit = { RDDOperationScope.withScope(sc, "checkpoint", allowNesting = false, ignoreParent = true) { //如果doCheckpointCalled不為true,就先將其改為true if (!doCheckpointCalled) { doCheckpointCalled = true //如果checkpointData已定義,就把data get出來,然后做一下checkpoint。 if (checkpointData.isDefined) { checkpointData.get.checkpoint() } else { //如果checkpointData沒有的話,就把這個RDD的所有依賴拿出來,foreach一把,把里面的每個元素RDD,再遞歸調(diào)用本方法。 dependencies.foreach(_.rdd.doCheckpoint()) } } } }
//RDD.scala中的checkpoint()方法 def checkpoint(): Unit = RDDCheckpointData.synchronized { // NOTE: we use a global lock here due to complexities downstream with ensuring // children RDD partitions point to the correct parent partitions. In the future // we should revisit this consideration. //首先檢查context的checkpointDir是否為空,如果沒有設(shè)置就會拋出異常 if (context.checkpointDir.isEmpty) { throw new SparkException("Checkpoint directory has not been set in the SparkContext") } else if (checkpointData.isEmpty) { checkpointData = Some(new ReliableRDDCheckpointData(this)) } }
//SparkContext.scala中的setCheckpointDir方法 /** * Set the directory under which RDDs are going to be checkpointed. The directory must * be a HDFS path if running on a cluster. */ def setCheckpointDir(directory: String) { // If we are running on a cluster, log a warning if the directory is local. // Otherwise, the driver may attempt to reconstruct the checkpointed RDD from // its own local file system, which is incorrect because the checkpoint files // are actually on the executor machines. //如果運行了集群模式,checkpointDir必須是非本地的。 if (!isLocal && Utils.nonLocalPaths(directory).isEmpty) { logWarning("Checkpoint directory must be non-local " + "if Spark is running on a cluster: " + directory) } checkpointDir = Option(directory).map { dir => val path = new Path(dir, UUID.randomUUID().toString) val fs = path.getFileSystem(hadoopConfiguration) fs.mkdirs(path) fs.getFileStatus(path).getPath.toString } }

 浙公網(wǎng)安備 33010602011771號
浙公網(wǎng)安備 33010602011771號