
Hulu大規(guī)模容器調(diào)度系統(tǒng)Capos
Hulu是美國領(lǐng)先的互聯(lián)網(wǎng)專業(yè)視頻服務(wù)平臺(tái),目前在美國擁有超過2000萬付費(fèi)用戶。Hulu總部位于美國洛杉磯,北京辦公室是僅次于總部的第二大研發(fā)中心,也是從Hulu成立伊始就具有重要戰(zhàn)略地位的分支辦公室,獨(dú)立負(fù)責(zé)播放器開發(fā),搜索和推薦,廣告精準(zhǔn)投放,大規(guī)模用戶數(shù)據(jù)處理,視頻內(nèi)容基因分析,人臉識(shí)別,視頻編解碼等核心項(xiàng)目。
在視頻領(lǐng)域我們有大量的視頻轉(zhuǎn)碼任務(wù);在廣告領(lǐng)域當(dāng)我們需要驗(yàn)證一個(gè)投放算法的效果時(shí),我們需要為每種新的算法運(yùn)行一個(gè)模擬的廣告系統(tǒng)來產(chǎn)出投放效果對(duì)比驗(yàn)證;在AI領(lǐng)域我們需要對(duì)視頻提取幀,利用一些訓(xùn)練框架產(chǎn)出模型用于線上服務(wù)。這一切都需要運(yùn)行在一個(gè)計(jì)算平臺(tái)上,Capos是Hulu內(nèi)部的一個(gè)大規(guī)模分布式任務(wù)調(diào)度和運(yùn)行平臺(tái)。
Capos是一個(gè)容器運(yùn)行平臺(tái),包含鏡像構(gòu)建,任務(wù)提交管理,任務(wù)調(diào)度運(yùn)行,日志收集查看,metrics收集,監(jiān)控報(bào)警,垃圾清理各個(gè)組件。整個(gè)平臺(tái)包含的各個(gè)模塊,如下圖所示:
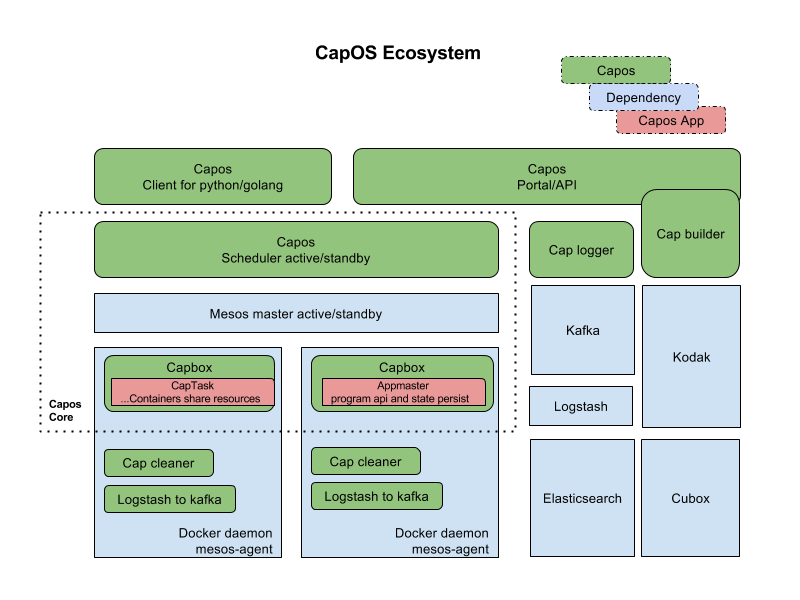
用戶可以在界面上創(chuàng)建鏡像描述符,綁定github的repo,生成鏡像。之后在界面上創(chuàng)建作業(yè)描述符,填上鏡像地址,啟動(dòng)參數(shù),資源需求,選擇資源池,就可以運(yùn)行作業(yè),看作業(yè)運(yùn)行日志等。這些所有操作也可以通過restapi來調(diào)用,對(duì)于一些高級(jí)的需求,capos提供golang和python的sdk,可以讓用戶申請(qǐng)資源,然后啟動(dòng)作業(yè),廣告系統(tǒng)就是利用sdk,在capos上面申請(qǐng)多個(gè)資源,靈活的控制這些資源的生命周期,一鍵啟動(dòng)一個(gè)分布式的廣告系統(tǒng)來做模擬測試。
Capos大部分組件都是用Golang實(shí)現(xiàn)的,Capos的核心組件,任務(wù)調(diào)度運(yùn)行CapScheduler是今天主要和大家分享和探討的模塊。CapScheduler是一個(gè)基于mesos的scheduler,負(fù)責(zé)任務(wù)的接收,元數(shù)據(jù)的管理,任務(wù)調(diào)度。CapExecutor是mesos的一個(gè)customized executor,實(shí)現(xiàn)Pod-like的邏輯,以及pure container resource的功能,在設(shè)計(jì)上允許Capos用戶利用capos sdk復(fù)用計(jì)算資源做自定義調(diào)度。
Capos Scheduler的架構(gòu)圖如下所示:
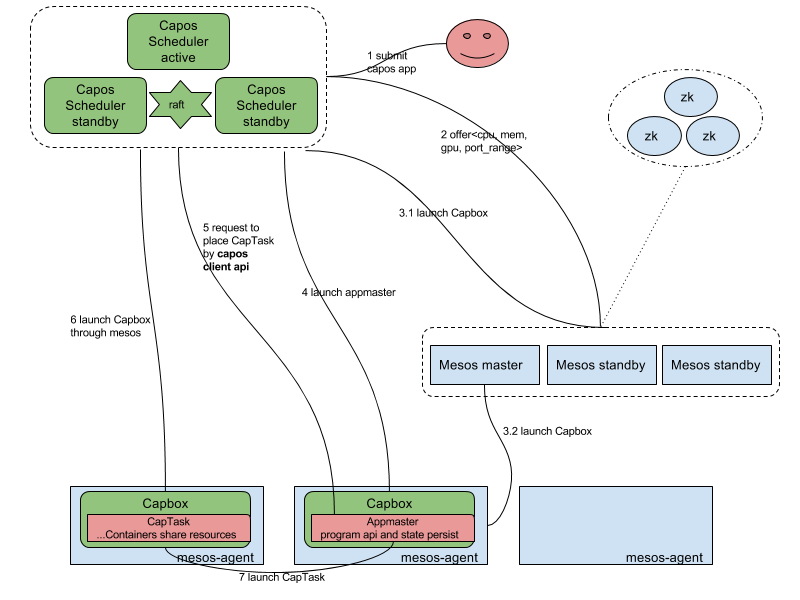
上圖淺藍(lán)色部分是mesos的組件,包括mesos master,mesos agent,mesos zookeeper。mesos作用是把所有單體的主機(jī)的資源管理起來,抽象成一個(gè)cpu,memory,port,gpu等的資源池,供之上的capos scheduler使用。
其中capos scheduler是一個(gè)active-standy的HA模型,在scheduler中我們實(shí)現(xiàn)了一個(gè)raft based的k-v用來存儲(chǔ)metadata,active的scheduler注冊(cè)成為mesos之上的一個(gè)framework,可以收到資源,根據(jù)調(diào)度策略來啟動(dòng)作業(yè)。
Capbox是一個(gè)定制實(shí)現(xiàn)的mesos的executor,作為mesos agent的資源的占位符,接收請(qǐng)求與mesos agent上的docker daemon通信啟動(dòng)容器。其中也實(shí)現(xiàn)了POD-like的功能,同時(shí)可以啟動(dòng)多個(gè)容器共享network,磁盤等。
Capos scheduler提供兩類作業(yè)運(yùn)行,一個(gè)是簡單作業(yè)直接在Capbox運(yùn)行,另一個(gè)是復(fù)雜帶有編程語義的作業(yè),我們稱之為appmaster,其本身運(yùn)行占用一個(gè)capbox,然后通過編程語義二次申請(qǐng)capbox運(yùn)行作業(yè)。
首先說明下簡單作業(yè)運(yùn)行流程,這里的簡單作業(yè),提交的作業(yè)通過json描述,可以包含多個(gè)container,然后scheduler收到請(qǐng)求之后,命中某個(gè)offer,向mesos發(fā)送offer啟動(dòng)請(qǐng)求,在請(qǐng)求中同時(shí)夾帶著作業(yè)json信息,把作業(yè)啟動(dòng)起來,scheduler根據(jù)mesos狀態(tài)同步信息來控制作業(yè)的生命周期。
如果是appmaster programmatically二次調(diào)度的作業(yè),首先需要把a(bǔ)ppmaster啟動(dòng),這部分和簡單作業(yè)運(yùn)行是一致的,然后appmaster再申請(qǐng)一個(gè)到多個(gè)資源來啟動(dòng)capbox,運(yùn)行作業(yè)。此時(shí)appmaster申請(qǐng)的capbox的生命周期完全由appmaster決定,所以這里appmaster可以復(fù)用capbox,或者批量申請(qǐng)capbox完成自己特定的調(diào)度效果。多說一句,appmaster可以支持client-mode和cluster-mode,client-mode是指appmaster運(yùn)行在集群之外,這種情況適用于把a(bǔ)ppmaster嵌入在用戶原先的程序之中,在某些場景更符合用戶的使用習(xí)慣。
說完capos的使用方式后,我們可以聊下在capos系統(tǒng)中一些設(shè)計(jì)的思考:
1 Scheduler的調(diào)度job和offer match策略,如下圖所示:

1.1 緩存offer。當(dāng)scheduler從mesos中獲取offer時(shí)候,capos scheduler會(huì)把offer放入到cache,offer在TTL后,offer會(huì)被launch或者歸還給mesos,這樣可以和作業(yè)和offer的置放策略解耦。
1.2 插件化的調(diào)度策略。capos scheduler會(huì)提供一系列的可插拔的過濾函數(shù)和優(yōu)先級(jí)函數(shù),這些優(yōu)先級(jí)函數(shù)對(duì)offer進(jìn)行打分,作用于調(diào)度策略。用戶在提交作業(yè)的時(shí)候,可以組合過濾函數(shù)和優(yōu)先級(jí)函數(shù),來滿足不同workload的調(diào)度需求。
1.3 延遲調(diào)度。當(dāng)一個(gè)作業(yè)選定好一個(gè)offer后,這個(gè)offer不會(huì)馬上被launch,scheduler會(huì)延遲調(diào)度,以期在一個(gè)offer中match更多作業(yè)后,再launch offer。獲取更高的作業(yè)調(diào)度吞吐。
2 Metadata的raft-base key value store
2.1 多個(gè)scheduler之間需要有一個(gè)分布式的kv store,來存儲(chǔ)作業(yè)的metadata以及同步作業(yè)的狀態(tài)機(jī)。在scheduler downtime切換的時(shí)候,新的scheduler可以接管,做一些recovery工作后,繼續(xù)工作。
2.2 基于raft實(shí)現(xiàn)的分布式一致性存儲(chǔ)。Raft是目前業(yè)界最流行的分布式一致性算法之一,raft依靠leader和WAL(write ahead log)保證數(shù)據(jù)一致性,利用Snapshot防止日志無限的增長,目前raft各種語言均有開源實(shí)現(xiàn),很多新興的數(shù)據(jù)庫都采用 Raft 作為其底層一致性算法。Capos利用了etcd提供的raft lib (https://github.com/coreos/etcd/tree/master/raft), 實(shí)現(xiàn)了分布式的一致性數(shù)據(jù)存儲(chǔ)方案。etcd為了增強(qiáng)lib的通用性,僅實(shí)現(xiàn)了raft的核心算法,網(wǎng)絡(luò)及磁盤io需要由使用者自行實(shí)現(xiàn)。Capos中利用etcd提供的rafthttp包來完成網(wǎng)絡(luò)io,數(shù)據(jù)持久化方面利用channel并行化leader的本地?cái)?shù)據(jù)寫入以及follower log同步過程,提高了吞吐率。
2.3 Capos大部分的模塊都是golang開發(fā),所以目前的實(shí)現(xiàn)是基于etcd的raft lib,底層的kv存儲(chǔ)可以用boltdb,badger和leveldb。有些經(jīng)驗(yàn)可以分享下,在調(diào)度方面我們應(yīng)該關(guān)注關(guān)鍵路徑上的消耗,我們起初有引入stormdb來自動(dòng)的做一些key-value的index,來加速某些帶filter的查詢。后來benchmark之后發(fā)現(xiàn),index特別在大規(guī)模meta存儲(chǔ)之后,性能下降明顯,所以目前用的純kv引擎。在追求高性能調(diào)度時(shí)候,寫會(huì)比讀更容器達(dá)到瓶頸,boltdb這種b+ tree的實(shí)現(xiàn)是對(duì)讀友好的,所以調(diào)度系統(tǒng)中對(duì)于kv的選型應(yīng)該著重考慮想leveldb這種lsm tree的實(shí)現(xiàn)。如果更近一步,在lsm tree基礎(chǔ)上,考慮kv分離存儲(chǔ),達(dá)到更高的性能,可以考慮用badger。不過最終選型,需要綜合考慮,所以我們底層存儲(chǔ)目前實(shí)現(xiàn)了boltdb,badger和leveldb這三種引擎。
3 編程方式的appmaster
3.1 簡單的作業(yè)可以直接把json描述通過restapi提交運(yùn)行,我們這邊討論的是,比較復(fù)雜場景的SaaS,可能用戶的workload是一種分布式小系統(tǒng),需要多個(gè)container資源的運(yùn)行和配合。這樣需要capos提供一種編程方式,申請(qǐng)資源,按照用戶需要先后在資源上運(yùn)行子任務(wù),最終完成復(fù)雜作業(yè)的運(yùn)行。
3.2 我們提供的編程原語如下, Capbox.go capbox是capos中資源的描述
package client import ( "capos/types/server" ) type CapboxCallbackHandler interface { OnCapboxesRunning(*prototypes.Capbox) error OnCapboxesCompleted(*prototypes.Capbox) error } type RecoveryCapboxHandler interface { GetCallbackHandler(string) (CapboxCallbackHandler, error) } type AMSchedulerLifeCycle interface { Start(*prototypes.AMContext) (*prototypes.RegisterAMResponse, error) Stop() error } type AMSchedulerAction interface { // container resource api CreateCapbox(*prototypes.CapboxRequest, CapboxCallbackHandler) (*prototypes.Capbox, error) ReleaseCapbox(string) error PreviousStateRecovery(*prototypes.RegisterAMResponse, RecoveryCapboxHandler) error PreviousStateDrop(*prototypes.RegisterAMResponse) error GetCapAgentsSnapshot() ([]*prototypes.CapAgent, error) ListenCapboxStateChange() StopListenCapboxStateChange() }
appmaster可以用這些api可以申請(qǐng)資源,釋放資源,獲取資源的狀態(tài)更新,在此基礎(chǔ)上可以實(shí)現(xiàn)靈活的調(diào)度。
Task.go task也就是可以在capbox上運(yùn)行的task, 如下圖所示
package client import ( "capos/types/server" ) type TaskCallbackHandler interface { OnTaskCompleted(*prototypes.CapTask) error } type RecoveryTaskHandler interface { GetCallbackHandler(capboxId string, taskId string) (TaskCallbackHandler, error) } type AMCapboxLifeCycle interface { Start() error Stop() error } type AMCapboxAction interface { // task management api StartTask(*prototypes.Capbox, *prototypes.CapTaskRequest, TaskCallbackHandler) (*prototypes.CapTask, error) StopTask(*prototypes.Capbox, string) error ListTask(*prototypes.Capbox) ([]*prototypes.CapTask, error) PreviousStateRecovery(*prototypes.RegisterAMResponse, RecoveryTaskHandler) error ListenCapTaskStateChange() StopListenCapTaskStateChange() }
在資源基礎(chǔ)上,appmaster可以用api啟動(dòng)/停止作業(yè),appmaster也可以復(fù)用資源不斷的啟動(dòng)新的作業(yè)。基于以上的api,我們可以把廣告模擬系統(tǒng),AI框架tensorflow,xgboost等分布式系統(tǒng)運(yùn)行在Capos之上。
4 capos對(duì)比下netflix開源的titus和kubernetes
4.1 netflix在今年開源了容器調(diào)度框架titus,Titus是一個(gè)mesos framework, titus-master是基于fenso lib的java based scheduler,meta存儲(chǔ)在cassandra中。titus-executor是golang的mesos customized executor。因?yàn)槭莕etflix的系統(tǒng),所以和aws的一些設(shè)施是綁定的,基本上在私有云中不太適用。
4.2 Kubernetes是編排服務(wù)方面很出色,在擴(kuò)展性方面有operator,multiple scheduler,cri等,把一切可以開放實(shí)現(xiàn)的都接口化,是眾人拾柴的好思路,但是在大規(guī)模調(diào)度短作業(yè)方面還是有提升空間。
4.3 Capos是基于mesos之上的調(diào)度,主要focus在大規(guī)模集群中達(dá)到作業(yè)的高吞吐調(diào)度運(yùn)行。
在分布式調(diào)度編排領(lǐng)域,有諸多工業(yè)界和學(xué)術(shù)界的作品,比如開源產(chǎn)品Mesos,Kubernetes,YARN, 調(diào)度算法Flow based的Quincy, Firmament。在long run service,short term workload以及function call需求方面有service mesh,微服務(wù),CaaS,F(xiàn)aaS等解決思路,私有云和公有云的百家爭鳴的解決方案和角度,整個(gè)生態(tài)還是很有意思的。絕技源于江湖、將軍發(fā)于卒伍,希望這次分享可以給大家?guī)硪恍﹩l(fā),最后感謝Capos的individual contributor(字母序): chenyu.zheng,fei.liu,guiyong.wu,huahui.yang,shangyan.zhou,wei.shao。

 浙公網(wǎng)安備 33010602011771號(hào)
浙公網(wǎng)安備 33010602011771號(hào)