
LSM樹由來、設(shè)計思想以及應(yīng)用到HBase的索引
講LSM樹之前,需要提下三種基本的存儲引擎,這樣才能清楚LSM樹的由來:
- 哈希存儲引擎 是哈希表的持久化實現(xiàn),支持增、刪、改以及隨機(jī)讀取操作,但不支持順序掃描,對應(yīng)的存儲系統(tǒng)為key-value存儲系統(tǒng)。對于key-value的插入以及查詢,哈希表的復(fù)雜度都是O(1),明顯比樹的操作O(n)快,如果不需要有序的遍歷數(shù)據(jù),哈希表就是your Mr.Right
- B樹存儲引擎是B樹(關(guān)于B樹的由來,數(shù)據(jù)結(jié)構(gòu)以及應(yīng)用場景可以看之前一篇博文)的持久化實現(xiàn),不僅支持單條記錄的增、刪、讀、改操作,還支持順序掃描(B+樹的葉子節(jié)點之間的指針),對應(yīng)的存儲系統(tǒng)就是關(guān)系數(shù)據(jù)庫(Mysql等)。
- LSM樹(Log-Structured Merge Tree)存儲引擎和B樹存儲引擎一樣,同樣支持增、刪、讀、改、順序掃描操作。而且通過批量存儲技術(shù)規(guī)避磁盤隨機(jī)寫入問題。當(dāng)然凡事有利有弊,LSM樹和B+樹相比,LSM樹犧牲了部分讀性能,用來大幅提高寫性能。
通過以上的分析,應(yīng)該知道LSM樹的由來了,LSM樹的設(shè)計思想非常樸素:將對數(shù)據(jù)的修改增量保持在內(nèi)存中,達(dá)到指定的大小限制后將這些修改操作批量寫入磁盤,不過讀取的時候稍微麻煩,需要合并磁盤中歷史數(shù)據(jù)和內(nèi)存中最近修改操作,所以寫入性能大大提升,讀取時可能需要先看是否命中內(nèi)存,否則需要訪問較多的磁盤文件。極端的說,基于LSM樹實現(xiàn)的HBase的寫性能比Mysql高了一個數(shù)量級,讀性能低了一個數(shù)量級。
LSM樹原理把一棵大樹拆分成N棵小樹,它首先寫入內(nèi)存中,隨著小樹越來越大,內(nèi)存中的小樹會flush到磁盤中,磁盤中的樹定期可以做merge操作,合并成一棵大樹,以優(yōu)化讀性能。
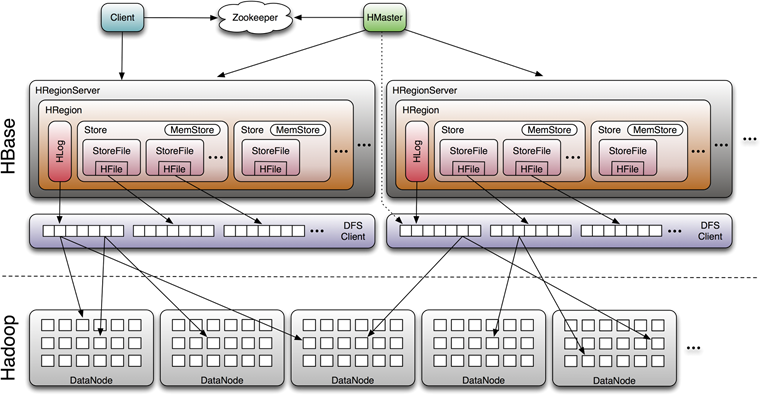
以上這些大概就是HBase存儲的設(shè)計主要思想,這里分別對應(yīng)說明下:
- 因為小樹先寫到內(nèi)存中,為了防止內(nèi)存數(shù)據(jù)丟失,寫內(nèi)存的同時需要暫時持久化到磁盤,對應(yīng)了HBase的MemStore和HLog
- MemStore上的樹達(dá)到一定大小之后,需要flush到HRegion磁盤中(一般是Hadoop DataNode),這樣MemStore就變成了DataNode上的磁盤文件StoreFile,定期HRegionServer對DataNode的數(shù)據(jù)做merge操作,徹底刪除無效空間,多棵小樹在這個時機(jī)合并成大樹,來增強讀性能。
關(guān)于LSM Tree,對于最簡單的二層LSM Tree而言,內(nèi)存中的數(shù)據(jù)和磁盤你中的數(shù)據(jù)merge操作,如下圖

圖來自lsm論文
lsm tree,理論上,可以是內(nèi)存中樹的一部分和磁盤中第一層樹做merge,對于磁盤中的樹直接做update操作有可能會破壞物理block的連續(xù)性,但是實際應(yīng)用中,一般lsm有多層,當(dāng)磁盤中的小樹合并成一個大樹的時候,可以重新排好順序,使得block連續(xù),優(yōu)化讀性能。
hbase在實現(xiàn)中,是把整個內(nèi)存在一定閾值后,flush到disk中,形成一個file,這個file的存儲也就是一個小的B+樹,因為hbase一般是部署在hdfs上,hdfs不支持對文件的update操作,所以hbase這么整體內(nèi)存flush,而不是和磁盤中的小樹merge update,這個設(shè)計也就能講通了。內(nèi)存flush到磁盤上的小樹,定期也會合并成一個大樹。整體上hbase就是用了lsm tree的思路。

 浙公網(wǎng)安備 33010602011771號
浙公網(wǎng)安備 33010602011771號