
一、什么是Logstash
Logstash是一款輕量級的日志搜集處理框架,可以方便的把分散的、多樣化的日志搜集起來,并進行自定義的處理,然后傳輸?shù)街付ǖ奈恢茫热缒硞€服務器或者文件。
Logstash是一個開源的、接受來自多種數(shù)據(jù)源(input)、過濾數(shù)據(jù)源的數(shù)據(jù)(filter)、存儲到其他設備的日志管理程序。Logstash包含三個基本插件input\filter\output,一個基本的logstash服務必須包含input和output.
Logstash如何工作:
Logstash數(shù)據(jù)處理有三個階段,input–>filter–>output:input生產(chǎn)數(shù)據(jù),filter根據(jù)定義的規(guī)則修改數(shù)據(jù),output將數(shù)據(jù)輸出到你定義的存儲位置。
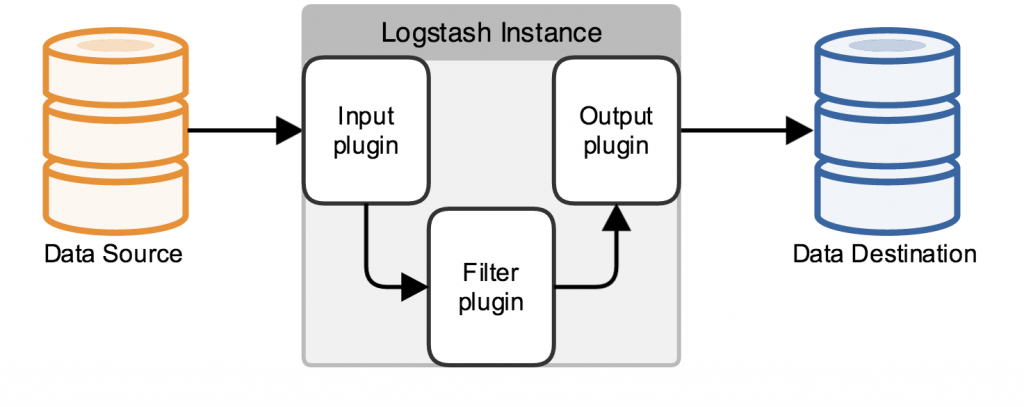
Inputs:
數(shù)據(jù)生產(chǎn)商,包含以下幾個常用輸出:
-
file: 從文件系統(tǒng)中讀取文件,類似使用tail -0F
-
syslog: syslog服務,監(jiān)聽在514端口使用RFC3164格式
-
redis: 從redis服務讀取,使用redis管道和列表。
-
beats: 一種代理,自己負責收集好數(shù)據(jù)然后轉(zhuǎn)發(fā)給Logstash,常用的如filebeat.
Filters:
filters相當一個加工管道,它會一條一條過濾數(shù)據(jù)根據(jù)你定義的規(guī)則,常用的filters如下:
-
grok: 解析無規(guī)則的文字并轉(zhuǎn)化為有結(jié)構(gòu)的格式。
-
mutate: 豐富的基礎類型處理,包括類型轉(zhuǎn)換、字符串處理、字段處理等。
-
drop: 丟棄一部分events不進行處理,例如: debug events
-
clone: 負責一個event,這個過程中可以添加或刪除字段。
-
geoip: 添加地理信息(為前臺kibana圖形化展示使用)
Outputs:
-
elasticserache elasticserache接收并保存數(shù)據(jù),并將數(shù)據(jù)給kibana前端展示。
-
output 標準輸出,直接打印在屏幕上。
二、Logstash的工作原理
Logstash使用管道方式進行日志的搜集處理和輸出。有點類似*NIX系統(tǒng)的管道命令 xxx | ccc | ddd,xxx執(zhí)行完了會執(zhí)行ccc,然后執(zhí)行ddd。
在logstash中,包括了三個階段:
輸入input --> 處理filter(不是必須的) --> 輸出output

每個階段都由很多的插件配合工作,比如file、elasticsearch、redis等等。
每個階段也可以指定多種方式,比如輸出既可以輸出到elasticsearch中,也可以指定到stdout在控制臺打印。
由于這種插件式的組織方式,使得logstash變得易于擴展和定制。
三、Logstash的安裝配置
Logstash運行僅僅依賴java運行環(huán)境(jre),JDK版本1.8以上即可。直接從ELK官網(wǎng)下載Logstash:https://www.elastic.co/cn/logstash/
3.1 選擇需要的版本下載:https://www.elastic.co/cn/downloads/past-releases#logstash
# 下載logstash wget https://artifacts.elastic.co/downloads/logstash/logstash-7.16.3-linux-x86_64.tar.gz # 創(chuàng)建目錄 mkdir -p /usr/local/logstash # 復制安裝包到指定目錄 cp logstash-7.16.3-linux-x86_64.tar.gz /usr/local/logstash # 解壓 cd /usr/local/logstash tar -zxvf logstash-7.16.3-linux-x86_64.tar.gz
3.2 啟動測試
# 進入安裝包目錄
cd /usr/local/logstash/logstash-7.16.3
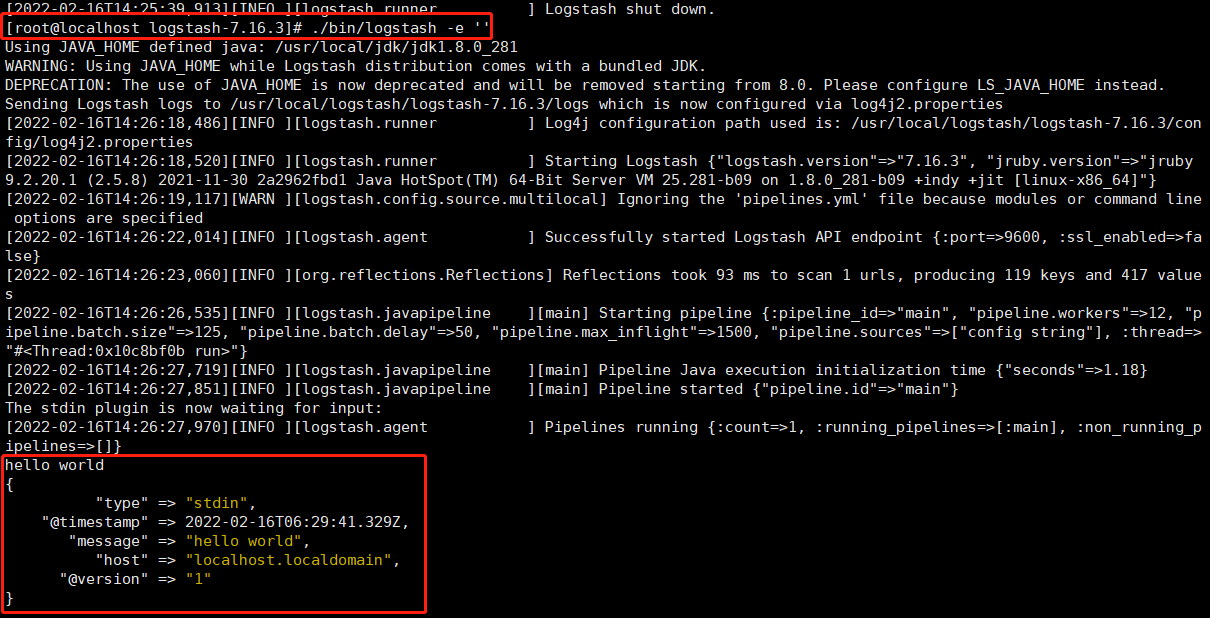
3.2.1 ./bin/logstash -e ''
[root@localhost logstash-7.16.3]# ./bin/logstash -e ''
我們現(xiàn)在可以在命令行下輸入一些字符,然后我們將看到logstash的輸出內(nèi)容:
hello world { "type" => "stdin", "@timestamp" => 2022-02-16T06:29:41.329Z, "message" => "hello world", "host" => "localhost.localdomain", "@version" => "1" }
3.2.2 ./bin/logstash -e 'input { stdin { } } output { stdout {} }'
[root@localhost logstash-7.16.3]# ./bin/logstash -e 'input { stdin { } } output { stdout {} }'
我們現(xiàn)在可以在命令行下輸入一些字符,然后我們將看到logstash的輸出內(nèi)容:
hello world { "message" => "hello world", "@version" => "1", "@timestamp" => 2022-02-16T06:33:37.052Z, "host" => "localhost.localdomain" }
3.2.3 ./bin/logstash -e 'input { stdin { } } output { stdout { codec => rubydebug } }'
[root@localhost logstash-7.16.3]# ./bin/logstash -e 'input { stdin { } } output { stdout { codec => rubydebug } }'
我們現(xiàn)在可以在命令行下輸入一些字符,然后我們將看到logstash的輸出內(nèi)容:
hello world
{
"message" => "hello world",
"@version" => "1",
"@timestamp" => 2022-02-16T06:33:37.052Z,
"host" => "localhost.localdomain"
}
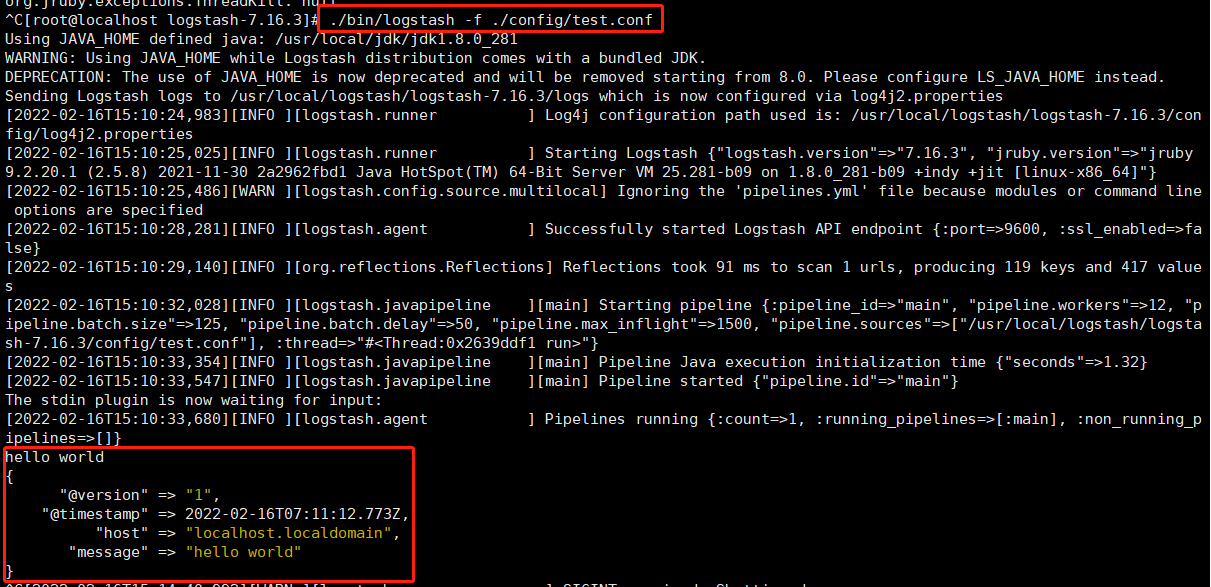
3.2.4 ./bin/logstash -f 配置文件
配置文件:
vim ./config/test.conf
# 配置內(nèi)容
input {
stdin{
}
}
output {
stdout{
}
}
啟動:
[root@localhost logstash-7.16.3]# ./bin/logstash -f ./config/test.conf
我們現(xiàn)在可以在命令行下輸入一些字符,然后我們將看到logstash的輸出內(nèi)容:
hello world { "@version" => "1", "@timestamp" => 2022-02-16T07:11:12.773Z, "host" => "localhost.localdomain", "message" => "hello world" }
以上例子我們在運行l(wèi)ogstash中,定義了一個叫”stdin”的input還有一個”stdout”的output,無論我們輸入什么字符,Logstash都會按照某種格式來返回我們輸入的字符。
類似的我們可以通過在你的配置文件中添加或者修改inputs、outputs、filters,就可以使隨意的格式化日志數(shù)據(jù)成為可能,從而訂制更合理的存儲格式為查詢提供便利。
前面已經(jīng)說過Logstash必須有一個輸入和一個輸出,上面的例子表示從終端上輸入并輸出到終端。
四、命令行中常用的命令
-e:后面跟著字符串,該字符串可以被當做logstash的配置(如果是""則默認使用stdin作為輸入,stdout作為輸出)
-f:通過這個命令可以指定Logstash的配置文件,根據(jù)配置文件配置logstash
-t:測試配置文件是否正確,然后退出
-l:日志輸出的地址(默認就是stdout直接在控制臺中輸出)
4.3. 配置文件說明
前面介紹過logstash基本上由三部分組成,input、output以及用戶需要才添加的filter,因此標準的配置文件格式如下:
input {...}
filter {...}
output {...}
在每個部分中,也可以指定多個訪問方式,例如我想要指定兩個日志來源文件,則可以這樣寫:
input {
file { path =>"/var/log/messages" type =>"syslog"}
file { path =>"/var/log/apache/access.log" type =>"apache"}
}
類似的,如果在filter中添加了多種處理規(guī)則,則按照它的順序一一處理,但是有一些插件并不是線程安全的。
比如在filter中指定了兩個一樣的的插件,這兩個任務并不能保證準確的按順序執(zhí)行,因此官方也推薦避免在filter中重復使用插件。
說完這些,簡單的創(chuàng)建一個配置文件的小例子看看:
input {
file {
#指定監(jiān)聽的文件路徑,注意必須是絕對路徑
path => "E:/software/logstash-1.5.4/logstash-1.5.4/data/test.log"
start_position => beginning
}
}
filter {
}
output {
stdout {}
}
日志大致如下:注意最后有一個空行。
1 hello,this is first line in test.log!
2 hello,my name is xingoo!
3 goodbye.this is last line in test.log!
4
執(zhí)行命令得到如下信息:
5. 最常用的input插件——file。
這個插件可以從指定的目錄或者文件讀取內(nèi)容,輸入到管道處理,也算是logstash的核心插件了,大多數(shù)的使用場景都會用到這個插件,因此這里詳細講述下各個參數(shù)的含義與使用。
5.1. 最小化的配置文件
在Logstash中可以在 input{} 里面添加file配置,默認的最小化配置如下:
input {
file {
path => "E:/software/logstash-1.5.4/logstash-1.5.4/data/*"
}
}
filter {
}
output {
stdout {}
}
當然也可以監(jiān)聽多個目標文件:
input {
file {
path => ["E:/software/logstash-1.5.4/logstash-1.5.4/data/*","F:/test.txt"]
}
}
filter {
}
output {
stdout {}
}
5.2. 其他的配置
另外,處理path這個必須的項外,file還提供了很多其他的屬性:
input {
file {
#監(jiān)聽文件的路徑
path => ["E:/software/logstash-1.5.4/logstash-1.5.4/data/*","F:/test.txt"]
#排除不想監(jiān)聽的文件
exclude => "1.log"
#添加自定義的字段
add_field => {"test"=>"test"}
#增加標簽
tags => "tag1"
#設置新事件的標志
delimiter => "\n"
#設置多長時間掃描目錄,發(fā)現(xiàn)新文件
discover_interval => 15
#設置多長時間檢測文件是否修改
stat_interval => 1
#監(jiān)聽文件的起始位置,默認是end
start_position => beginning
#監(jiān)聽文件讀取信息記錄的位置
sincedb_path => "E:/software/logstash-1.5.4/logstash-1.5.4/test.txt"
#設置多長時間會寫入讀取的位置信息
sincedb_write_interval => 15
}
}
filter {
}
output {
stdout {}
}
其中值得注意的是:
1 path
是必須的選項,每一個file配置,都至少有一個path
2 exclude
是不想監(jiān)聽的文件,logstash會自動忽略該文件的監(jiān)聽。配置的規(guī)則與path類似,支持字符串或者數(shù)組,但是要求必須是絕對路徑。
3 start_position
是監(jiān)聽的位置,默認是end,即一個文件如果沒有記錄它的讀取信息,則從文件的末尾開始讀取,也就是說,僅僅讀取新添加的內(nèi)容。對于一些更新的日志類型的監(jiān)聽,通常直接使用end就可以了;相反,beginning就會從一個文件的頭開始讀取。但是如果記錄過文件的讀取信息,這個配置也就失去作用了。
4 sincedb_path
這個選項配置了默認的讀取文件信息記錄在哪個文件中,默認是按照文件的inode等信息自動生成。其中記錄了inode、主設備號、次設備號以及讀取的位置。因此,如果一個文件僅僅是重命名,那么它的inode以及其他信息就不會改變,因此也不會重新讀取文件的任何信息。類似的,如果復制了一個文件,就相當于創(chuàng)建了一個新的inode,如果監(jiān)聽的是一個目錄,就會讀取該文件的所有信息。
5 其他的關(guān)于掃描和檢測的時間,按照默認的來就好了,如果頻繁創(chuàng)建新的文件,想要快速監(jiān)聽,那么可以考慮縮短檢測的時間。
//6 add_field
#這個技術(shù)感覺挺六的,但是其實就是增加一個字段,例如:
file {
add_field => {"test"=>"test"}
path => "D:/tools/logstash/path/to/groksample.log"
start_position => beginning
}
6. Kafka與Logstash的數(shù)據(jù)采集對接
基于Logstash跑通Kafka還是需要注意很多東西,最重要的就是理解Kafka的原理。
6.1. Logstash工作原理
由于Kafka采用解耦的設計思想,并非原始的發(fā)布訂閱,生產(chǎn)者負責產(chǎn)生消息,直接推送給消費者。而是在中間加入持久化層——broker,生產(chǎn)者把數(shù)據(jù)存放在broker中,消費者從broker中取數(shù)據(jù)。這樣就帶來了幾個好處:
1 生產(chǎn)者的負載與消費者的負載解耦
2 消費者按照自己的能力fetch數(shù)據(jù)
3 消費者可以自定義消費的數(shù)量
另外,由于broker采用了主題topic-->分區(qū)的思想,使得某個分區(qū)內(nèi)部的順序可以保證有序性,但是分區(qū)間的數(shù)據(jù)不保證有序性。這樣,消費者可以以分區(qū)為單位,自定義讀取的位置——offset。
Kafka采用zookeeper作為管理,記錄了producer到broker的信息,以及consumer與broker中partition的對應關(guān)系。因此,生產(chǎn)者可以直接把數(shù)據(jù)傳遞給broker,broker通過zookeeper進行l(wèi)eader-->followers的選舉管理;消費者通過zookeeper保存讀取的位置offset以及讀取的topic的partition分區(qū)信息。
由于上面的架構(gòu)設計,使得生產(chǎn)者與broker相連;消費者與zookeeper相連。有了這樣的對應關(guān)系,就容易部署logstash-->kafka-->logstash的方案了。
接下來,按照下面的步驟就可以實現(xiàn)logstash與kafka的對接了。
6.2. 啟動kafka
##啟動zookeeper:
$zookeeper/bin/zkServer.sh start
##啟動kafka:
$kafka/bin/kafka-server-start.sh $kafka/config/server.properties &
6.3. 創(chuàng)建主題
#創(chuàng)建主題:
$kafka/bin/kafka-topics.sh --zookeeper 127.0.0.1:2181 --create --topic hello --replication-factor 1 --partitions 1
#查看主題:
$kafka/bin/kafka-topics.sh --zookeeper 127.0.0.1:2181 --describe
6.4. 測試環(huán)境
#執(zhí)行生產(chǎn)者腳本:
$kafka/bin/kafka-console-producer.sh --broker-list 10.0.67.101:9092 --topic hello
#執(zhí)行消費者腳本,查看是否寫入:
$kafka/bin/kafka-console-consumer.sh --zookeeper 127.0.0.1:2181 --from-beginning --topic hello
6.5. 向kafka中輸出數(shù)據(jù)
input{
stdin{}
}
output{
kafka{
topic_id => "hello"
bootstrap_servers => "192.168.0.4:9092,172.16.0.12:9092"
# kafka的地址
batch_size => 5
codec => plain {
format => "%{message}"
charset => "UTF-8"
}
}
stdout{
codec => rubydebug
}
}
6.6. 從kafka中讀取數(shù)據(jù)
logstash配置文件:
input{
kafka {
codec => "plain"
group_id => "logstash1"
auto_offset_reset => "smallest"
reset_beginning => true
topic_id => "hello"
zk_connect => "192.168.0.5:2181"
}
}
output{
stdout{
codec => rubydebug
}
}
7. Filter
7.1. 過濾插件grok組件
#日志
55.3.244.1 GET /index.html 15824 0.043
bin/logstash -e '
input { stdin {} }
filter {
grok {
match => { "message" => "%{IP:client} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration}" }
}
}
output { stdout {codec => rubydebug} }'
7.2. 分割插件split
filter {
mutate {
split => { "message" => " " }
add_field => {
"event_type" => "%{message[3]}"
"current_map" => "%{message[4]}"
"current_X" => "%{message[5]}"
"current_y" => "%{message[6]}"
"user" => "%{message[7]}"
"item" => "%{message[8]}"
"item_id" => "%{message[9]}"
"current_time" => "%{message[12]}"
}
remove_field => [ "message" ]
}
}
四、 Kibana報表工具的安裝和使用
1. 簡介
Logstash 早期曾經(jīng)自帶了一個特別簡單的 logstash-web 用來查看 ES 中的數(shù)據(jù)。其功能太過簡單,于是產(chǎn)生了Kibana。不過是用PHP編寫,后來為了滿足更多的使用需求,懶人推動科技的進步嘛,并且Logstash使用ruby進行編寫,所以重新編寫Kibana,直到現(xiàn)在,Kibana因為重構(gòu),導致3,4某些情況下不兼容,所以出現(xiàn)了一山容二虎的情況,具體怎么選擇,可以根據(jù)業(yè)務場景進行實際分析
在Kibana眾多的優(yōu)秀特性中,我個人最喜歡的是這一個特性,我起名叫包容性
因為在官網(wǎng)介紹中,Kibana可以非常方便地把來自Logstash、ES-Hadoop、Beats或第三方技術(shù)的數(shù)據(jù)整合到Elasticsearch,支持的第三方技術(shù)包括Apache Flume、Fluentd等。這也就表明我在日常的開發(fā)工作中,對于技術(shù)選型和操作的時候,我可以有更多的選擇,在開發(fā)時也能找到相應的開發(fā)實例,節(jié)省了大量的開發(fā)時間
ps:有一次體現(xiàn)了官網(wǎng)的重要性,真的,有時候官網(wǎng)可以幫你解決大多數(shù)的問題,有時間可以去看一下官網(wǎng)啊,好了,話不多說,看正題
2. 安裝
下載安裝包后解壓
編輯文件config/kibana.yml ,配置屬性:
[root@H32 ~]# cd kibana/config/
[root@H32 config]# vim kibana.yml
//添加:
server.host: "192.168.80.32"
elasticsearch.url: "http://172.16.0.14:9200"
先啟動ES,然后再啟動
cd /usr/local/kibana530bin/kibana
注意:
1、kibana必須是在root下運行,否則會報錯,啟動失敗
2、下載解壓安裝包,一定要裝與ES相同的版本
3. 導入數(shù)據(jù)
我們將使用莎士比亞全集作為我們的示例數(shù)據(jù)。要更好的使用 Kibana,你需要為自己的新索引應用一個映射集(mapping)。我們用下面這個映射集創(chuàng)建"莎士比亞全集"索引。實際數(shù)據(jù)的字段比這要多,但是我們只需要指定下面這些字段的映射就可以了。注意到我們設置了對 speaker 和 play_name 不分析。原因會在稍后講明。
在終端運行下面命令:
curl -XPUT http://localhost:9200/shakespeare -d '
{
"mappings" : {
"_default_" : {
"properties" : {
"speaker" : {"type": "string", "index" : "not_analyzed" },
"play_name" : {"type": "string", "index" : "not_analyzed" },
"line_id" : { "type" : "integer" },
"speech_number" : { "type" : "integer" }
}
}
}
}
我們這就創(chuàng)建好了索引。現(xiàn)在需要做的時導入數(shù)據(jù)。莎士比亞全集的內(nèi)容我們已經(jīng)整理成了 elasticsearch 批量 導入所需要的格式,你可以通過shakeseare.json下載。
用如下命令導入數(shù)據(jù)到你本地的 elasticsearch 進程中。
curl -XPUT localhost:9200/_bulk --data-binary @shakespeare.json
4. 訪問 Kibana 界面
打開瀏覽器,訪問已經(jīng)發(fā)布了 Kibana 的本地服務器。
如果你解壓路徑無誤(譯者注:使用 github 源碼的讀者記住發(fā)布目錄應該是 kibana/src/ 里面),你已經(jīng)就可以看到上面這個可愛的歡迎頁面。點擊 Sample Dashboard 鏈接
好了,現(xiàn)在顯示的就是你的 sample dashboard!如果你是用新的 elasticsearch 進程開始本教程的,你會看到一個百分比占比很重的餅圖。這里顯示的是你的索引中,文檔類型的情況。如你所見,99% 都是 lines,只有少量的 acts 和scenes。
在下面,你會看到一長段 JSON 格式的莎士比亞詩文。
5. 第一次搜索
Kibana 允許使用者采用 Lucene Query String 語法搜索 Elasticsearch 中的數(shù)據(jù)。請求可以在頁面頂部的請求輸入框中書寫。
在請求框中輸入如下內(nèi)容。然后查看表格中的前幾行內(nèi)容。
friends, romans, countrymen
6. 配置另一個索引
目前 Kibana 指向的是 Elasticsearch 一個特殊的索引叫 _all。 _all 可以理解為全部索引的大集合。目前你只有一個索引, shakespeare,但未來你會有更多其他方面的索引,你肯定不希望 Kibana 在你只想搜《麥克白》里心愛的句子的時候還要搜索全部內(nèi)容。
配置索引,點擊右上角的配置按鈕:
在這里,你可以設置你的索引為 shakespeare ,這樣 Kibana 就只會搜索 shakespeare 索引的內(nèi)容了。
這是因為 ES1.4 增強了權(quán)限管理。你需要在 ES 配置文件 elasticsearch.yml 中添加下列配置并重啟服務后才能正常訪問:
http.cors.enabled: true
http.cors.allow-origin: "*"
記住 kibana3 頁面也要刷新緩存才行。
此外,如果你可以很明確自己 kibana 以外沒有其他 http 訪問,可以把 kibana 的網(wǎng)址寫在http.cors.allow-origin 參數(shù)的值中。比如:
http.cors.allow-origin: "/https?:\/\/kbndomain/"
好了,到這里就結(jié)束了。
[root@localhost logstash-7.16.3]# ./bin/logstash -f ./config/test.conf

 浙公網(wǎng)安備 33010602011771號
浙公網(wǎng)安備 33010602011771號