
pandas缺失值處理之——如何消去Nan值對數(shù)字型字符串?dāng)?shù)據(jù)類型的影響,讓數(shù)字型字符串保持原始str類型,而不會自動變?yōu)閒loat類型?
在利用pandas處理表格時,往往有時我們用表格做的測試用例往往會設(shè)計考一些必填項*故意賦值為空(代表不輸入)的測試用例,
比如說我們的手機號、身份證號碼、社會統(tǒng)一信用代碼等都是數(shù)字型字符串。如下所示:

pandas讀取表格,會把表格中的空單元格置為float類型的Nan值,會導(dǎo)致數(shù)字型字符串列的數(shù)據(jù)類型從原始的str類型自動轉(zhuǎn)換為float類型,如下圖所示:
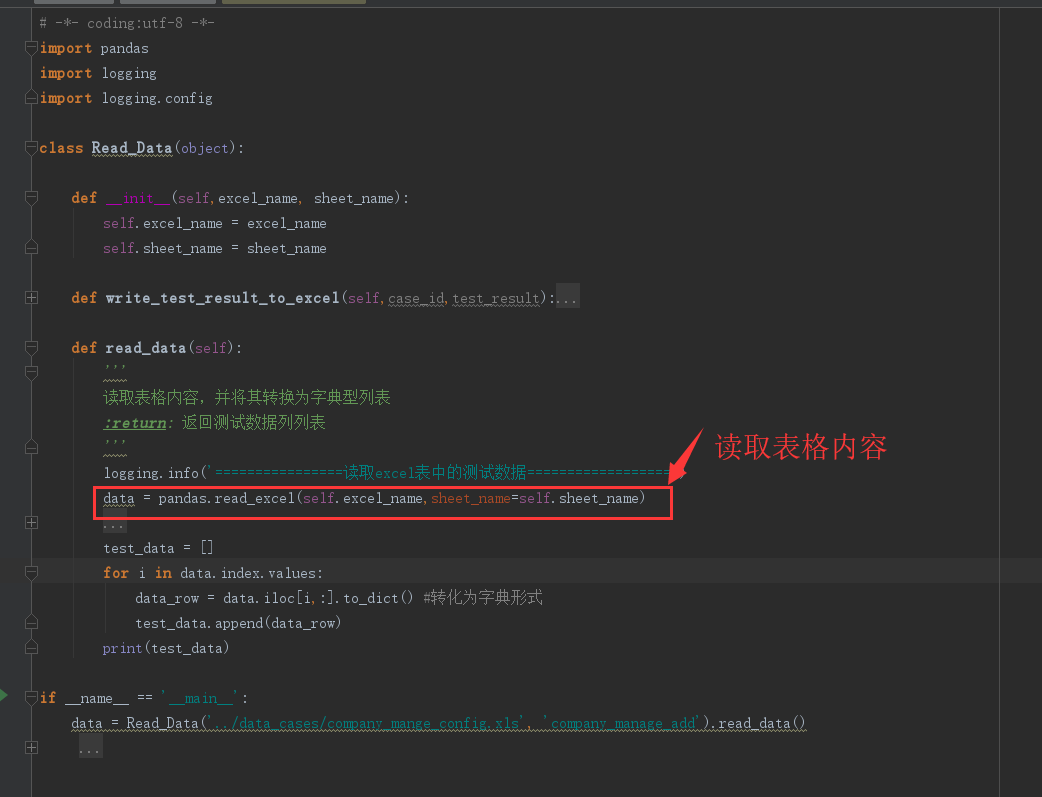
讀取的效果:


從上圖可看出,pandas讀取excel時,遇到空白單元格會自動置為nan值,float型。
導(dǎo)致原始表格中的文本類型的social_code(社會信用代碼)和 telno(手機號)從原始的本文str類型轉(zhuǎn)變?yōu)榱薴loat類型,導(dǎo)致數(shù)據(jù)顯示錯誤,不是我們想要的結(jié)果。
那如何將nan值全部置為空,并且還不會影響原始表格中的數(shù)字型字符串呢???
我們可以在讀取表格時,就以字符串型讀取,如下圖所示:
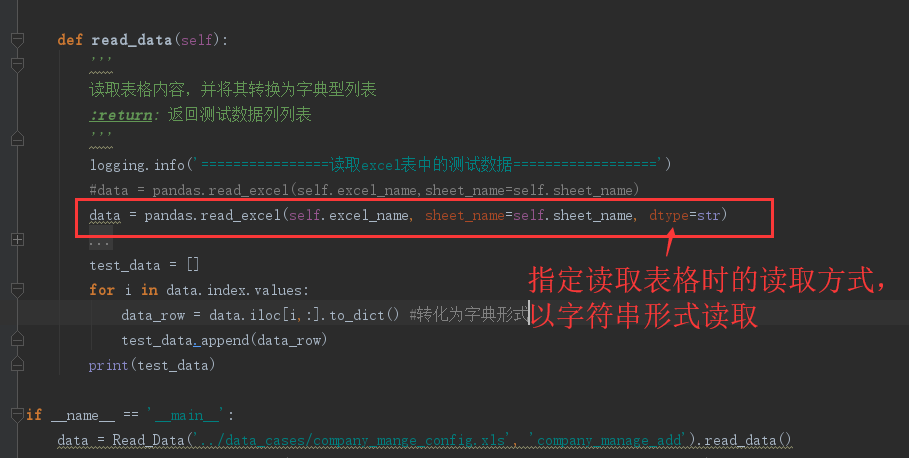
效果如下:


這時,原始的數(shù)字型字符串?dāng)?shù)據(jù)就不會受到nan值的影響了。
如果需要對nan值進行替換,直接采用fillna()填充即可。

替換、填充效果:

這樣就完成了~~~~


 浙公網(wǎng)安備 33010602011771號
浙公網(wǎng)安備 33010602011771號