
通過Python交互式控制臺理解Conv1d
 面向PyTorch初學者,通過在Python交互式控制臺一步步執行代碼,驗證詳細Conv1d的計算過程.
面向PyTorch初學者,通過在Python交互式控制臺一步步執行代碼,驗證詳細Conv1d的計算過程.
以前在語音合成項目第一次接觸PyTorch中的Conv1d函數時,作為一個初學者,我對它的參數和工作機制感到很困惑。
原本以為既然是1維卷積,那輸入輸出應該都是簡單的1維張量。然而實際上,輸入必須是一個3維張量,這讓我頗感意外。
后來因為工作緣故,我有一段時間沒接觸深度學習了。后來再次遇到Conv1d函數時,我又陷入了同樣的困惑。
因此,我決定寫下自己的理解過程,幫助可能遇到類似情況的讀者(包括未來的我自己)。
本文使用的工具版本是Python 3.13.3,PyTorch 2.7.1。
Python的版本號可用python -V命令確認。
> python -V
Python 3.13.3
PyTorch的版本號可用pip show torch命令確認。
> pip show torch
Name: torch
Version: 2.7.1
...
或者也可以像下面這樣進入Python交互式控制臺確認。
> python
Python 3.13.3 (tags/v3.13.3:6280bb5, Apr 8 2025, 14:47:33) [MSC v.1943 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> import torch
>>> torch.__version__
'2.7.1+cpu'
理解Conv1d輸入輸出形狀的關鍵在于,我們必須考慮深度學習中的批次(batch)和通道(channel)概念。
下面通過在Python交互式控制臺里一步步執行代碼來理解這一點。
第一步:創建Conv1d實例
使用Conv1d首先需要創建一個實例。實例化時需要指定三個主要參數:
- in_channels:輸入通道數。例如,1表示單聲道音頻,2表示立體聲音頻。
- out_channels:卷積后的輸出通道數,代表卷積濾波器的數量。
- kernel_size:卷積濾波器的大小。
創建一個具有2個輸入通道、3個輸出通道和濾波器大小為5的Conv1d實例:
>>> from torch import nn
>>> conv1d = nn.Conv1d(2, 3, 5)
第二步:查看權重和偏置
創建實例時,卷積操作使用的權重(weight)和偏置(bias)會自動初始化。
在機器學習過程中,這些值會在訓練過程中被逐步優化。
>>> conv1d.weight.shape
torch.Size([3, 2, 5])
>>> conv1d.weight
Parameter containing:
tensor([[[ 0.2076, 0.1669, -0.0984, 0.0040, -0.0094],
[-0.0277, -0.0257, -0.3107, 0.2883, 0.2560]],
[[ 0.0501, -0.2257, 0.0464, -0.0605, 0.1463],
[-0.1195, 0.1820, 0.0764, 0.2922, -0.2718]],
[[ 0.2699, -0.2734, 0.1698, 0.2720, -0.2554],
[-0.0706, -0.2028, -0.2554, -0.1495, 0.2460]]], requires_grad=True)
>>> conv1d.bias
Parameter containing:
tensor([-0.1664, -0.0393, 0.2074], requires_grad=True)
conv1d.weight表示每個濾波器的權重,形狀為(輸出通道數, 輸入通道數, 濾波器大小)conv1d.bias表示每個濾波器的偏置,形狀為(輸出通道數)
第三步:準備輸入數據
Conv1d的輸入數據必須是3維張量:
- 第1維:批次大小(
batch_size),表示一次處理的數據樣本數量 - 第2維:輸入通道數,必須與創建
Conv1d實例時指定的in_channels一致 - 第3維:單個數據樣本的長度。對于音頻數據,通常是幀數
>>> x = torch.rand(4, 2, 6) # 隨機數據:批次大小4,2個輸入通道,長度6
>>> x
tensor([[[0.5487, 0.5584, 0.7142, 0.6534, 0.2741, 0.9281],
[0.8480, 0.2020, 0.3171, 0.4146, 0.8032, 0.4344]],
[[0.6481, 0.6134, 0.9704, 0.5787, 0.1803, 0.1568],
[0.6690, 0.8022, 0.2466, 0.2352, 0.2962, 0.2569]],
[[0.7968, 0.8019, 0.4341, 0.4369, 0.5804, 0.2109],
[0.8624, 0.1870, 0.9518, 0.7393, 0.3436, 0.4962]],
[[0.5005, 0.9210, 0.0010, 0.9487, 0.0381, 0.5954],
[0.5601, 0.9394, 0.3438, 0.5394, 0.6369, 0.4937]]])
第四步:執行卷積操作
將輸入數據x傳遞給conv1d并查看結果:
>>> y = conv1d(x)
>>> y.shape
torch.Size([4, 3, 2])
>>> y
tensor([[[ 0.1683, 0.1969],
[-0.2416, 0.1589],
[ 0.3856, -0.0863]],
[[ 0.0034, 0.1147],
[-0.0358, -0.2050],
[ 0.2556, 0.0671]],
[[ 0.0630, -0.0035],
[ 0.0246, 0.0918],
[-0.1203, 0.1590]],
[[ 0.2665, 0.0337],
[-0.1590, 0.1789],
[ 0.0974, 0.2275]]], grad_fn=<ConvolutionBackward0>)
輸出y是一個3維張量,形狀為(批次大小, 輸出通道數, 輸出長度)。
第五步:理解計算過程
卷積操作遵循以下原則:
- 濾波器在輸入數據上滑動
- 計算元素乘積的和
- 加上偏置
每個輸出元素的計算公式為:
y[批次索引, 輸出通道索引, 數據位置] =
sum(x[批次索引, 輸入通道0, (數據位置):(數據位置+濾波器大小)] @ conv1d.weight[輸出通道索引, 輸入通道0]) +
sum(x[批次索引, 輸入通道1, (數據位置):(數據位置+濾波器大小)] @ conv1d.weight[輸出通道索引, 輸入通道1]) +
... +
conv1d.bias[輸出通道索引]
其中@表示點積操作,A @ B等同于A.dot(B)。
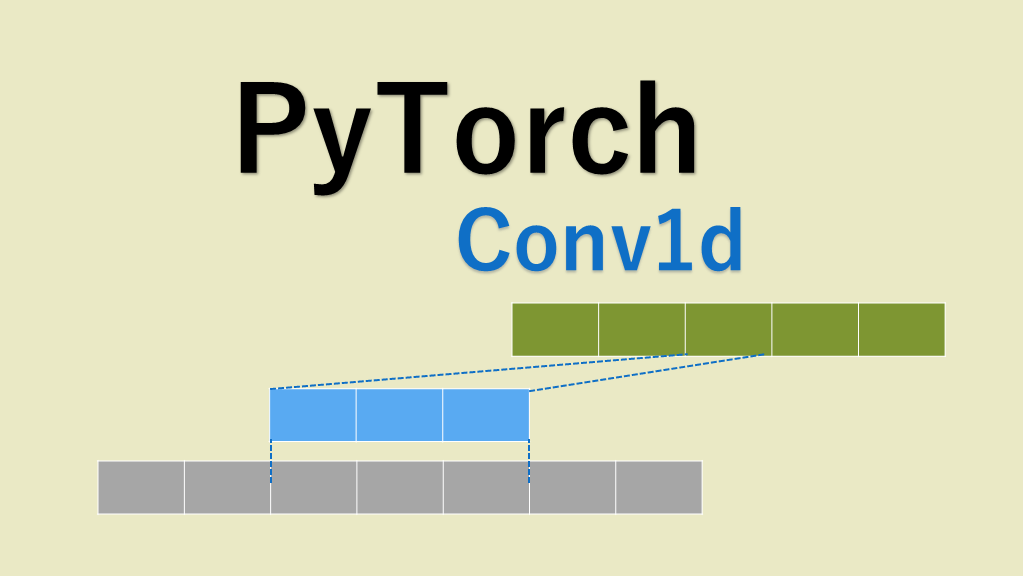
輸出長度可以通過以下公式計算:
輸出長度 = (輸入長度 - 濾波器大小 + 1)
例如,我們可以驗證y[0,0,0]的計算:
>>> y[0,0,0] # 第0個數據樣本,第0個輸出通道,第0個輸出數據位置
tensor(0.1683, grad_fn=<SelectBackward0>)
>>> x[0,0,0:5] @ conv1d.weight[0,0] + x[0,1,0:5] @ conv1d.weight[0,1] + conv1d.bias[0]
tensor(0.1683, grad_fn=<AddBackward0>)
同樣,我們可以計算y[0, 0, 1]:
>>> y[0,0,1] # 第0個數據樣本,第0個輸出通道,第1個輸出數據位置
tensor(0.1969, grad_fn=<SelectBackward0>)
>>> x[0,0,1:6] @ conv1d.weight[0,0] + x[0,1,1:6] @ conv1d.weight[0,1] + conv1d.bias[0]
tensor(0.1969, grad_fn=<AddBackward0>)
如上所示,Conv1d通過對輸入數據x進行卷積操作生成新的特征量y。
特征量y可用于音頻識別、自然語言處理等各種1維(單通道或多通道)數據的處理任務。
總結
- 輸入必須是3維張量:(批次大小, 輸入通道數, 數據長度)
- 輸出也是3維張量:(批次大小, 輸出通道數, 輸出長度)
- 輸出長度由公式
輸入長度 - 濾波器大小 + 1決定 - 每個輸出元素是輸入數據與濾波器權重的點積加上偏置

 浙公網安備 33010602011771號
浙公網安備 33010602011771號