

目錄
什么是索引
概念
一種幫助 MySQL 提高查詢效率的數據結構
優缺點
優點:
- 大大加快查詢速度
缺點:
- 維護索引需要消耗數據庫資源
- 索引需要占據磁盤空間
- 對表進行增、刪、改的時候,因為需要維護索引,速度會受到影響
索引的分類
InnoDB
主鍵索引
設定為主鍵后數據庫會自動建立索引,InnoDB 為聚簇索引
創建表的時候會有一個主鍵(primary key),這個主鍵就是索引
單值索引
也叫單列索引、普通索引
一個索引只包含單個列,一個表可以有多個單列索引
除了主鍵以外,為其他列創建索引,叫單值索引;
比如一個表中,有 age,name,id,假如 id 為主鍵索引,那么可以為 name 創建單值索引。
唯一索引
索引列的值必須唯一,但允許有空值;
主鍵索引不能未 null,而唯一索引可以為 null。
復合索引
即一個索引包含多個列
比如有一個表,id,name,age,復合索引就是用 name 和 age 組合作為索引;
如果查詢 where age = 18 或者是 where name = ‘逍遙’,可以用單值索引;
如果是查詢 where name = 18 and age = ’逍遙‘,此時用復合索引就會更快,常用 name 和 age 查詢的話就可以使用 name + age 共同創建的復合索引。
MyISAM
Full Text 全文索引
全文索引類型為 FULL TEXT,在定義索引的列上支持值的全文查找,允許在這些索引列中插入重復值和空值。全文索引可以在 CHAR、VARCHAR 、TEXT 類型列創建。MySQL 只有 MyISAM 存儲引擎支持全文索引。
索引的創建方式
主鍵索引是在建表后自動創建的
建表時創建
-- 主鍵索引和普通索引
create table [表名](id varchar(20) primary key, name varchar(20),key(name));
-- 唯一索引
create table [表名](id varchar(20) primary key, name varchar(20),unique(name));
-- 符合索引
create table [表名](id varchar(20) primary key, name varchar(20),age int ,unique(name,age));
建表后創建
-- 普通索引
create index [列名] on [表面](列名);
-- 唯一索引
create unique index [列名] on [表面](列名);
-- 復合索引
create index [列名] on [表面](列名1,列名2);
創建復合索引 age,name,bir,只能利用 最左前綴原則 查詢,也就是說,只能根據
- age
- age ,name
- age ,name, bir
- age,bir
這三條查詢
由于 MySQL 優化,在查詢過程中動態調整查詢字段順序以便利用索引,因此可以查詢
- age,bir,name
- bir,age,name
- bir,name,age
…也就是說,有 age 就可以查詢!
查看索引是否創建
select index form [表名]

索引原理
B+ 樹
建表,插入數據并查找
create table user(id int primary key, name varchar(20), age int);
insert into user values(3,'d',15);
insert into user values(5,'a',23);
insert into user values(2,'c',22);
insert into user values(6,'b',13);
insert into user values(1,'f',24);
insert into user values(4,'e',11);
insert into user values(9,'h',20);
insert into user values(8,'g',19);
select * from user;
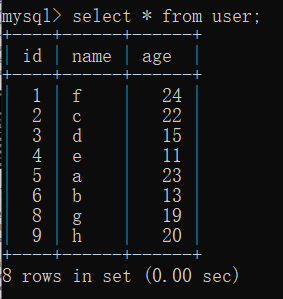
可以發現,插入 id、name、age 是無序的,但是插入過后,數據是按照 id 排序的,而把 id 設置為主鍵,主鍵默認是索引的。
因此 MySQL 底層第一步就是對插入的數據按照索引排序;
那為什么要排序呢?
當然是方便查找;

當數據量很大的時候,這樣類似鏈表的結構就不方便查找了,因此 MySQL 底層又做了進一步的改善
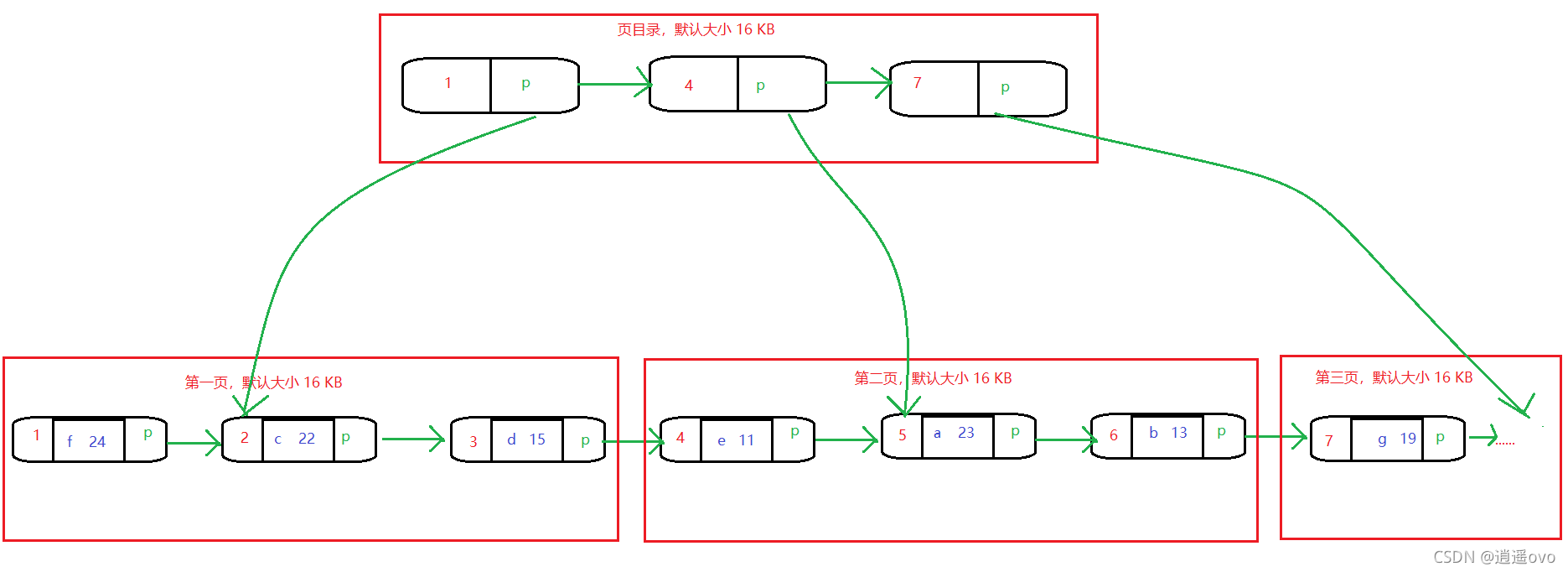
也就是出現了頁目錄的概念,葉子節點存儲所有信息,而目錄只存儲索引以及下一個節點的地址信息;
B+ 樹和 B 樹的區別
- B 樹所有節點都存儲全部數據,B + 樹只有葉子節點存儲全部數據
- 所有葉子節點之間都有一個指針;
- 數據記錄都都存放在葉子節點中。
MySQL 底層原理
- 存儲數據的時候首先根據主鍵排序,用指針串起來
- 基于 B+ 樹的結構,對數據進行分頁存儲,默認大小為 16 KB,一個三層的 B+ 樹大概能存 10 億數據,頂層目錄是常駐內存,也就是說查詢需要1 - 2 次查詢。
聚簇索引與非聚簇索引
聚簇索引:將數據存儲與數據放在一塊,索引結構的葉子節點保存了行數據;
非聚簇索引:將數據與索引分開存儲,索引結構的葉子節點指向了數據對應的位置。
InnoDB
不需要二次查找,直接對 B+ 樹進行查找
MyISAM
需要二次查找,先利用非聚簇索引查找主鍵,然后回表,對聚簇索引的 B+ 樹查詢。
聚簇索引的優勢
- 由于行數據和聚簇索引的葉子節點存儲在一起,同一頁中會有多行數據,訪問同一頁不同數據時,已經把同一頁的數據加載到緩沖器中,后續查詢不必重新訪問磁盤,
- 輔助索引存儲的是主鍵值,減少輔助索引占用空間大小;
- 不使用聚簇索引如果發送節點的增、刪、改,就會導致需要維護索引樹。
使用聚簇索引時需要注意什么
- 使用主鍵作為聚簇索引時,不要使用 uuid,uuid 太過于離散,不適合排序,如果出現新增記錄,肯能會插入到索引中間,消耗過多的資源和時間。
為什么主鍵通常使用自增 id
聚簇索引的數據的物理存放順序與索引存放順序是一致的,也就是說,只要索引是相鄰的,那么對應的數據一定也是相鄰存放在磁盤上,如果不是自增,那么存放時就會不斷調整數據的物理位置等;如果是自增,只需要一頁一頁的寫,索引結構相對緊湊,磁盤碎片少,效率也高。
什么情況下無法使用索引
- 查詢關鍵字中 like 關鍵字
使用 like 關鍵字查詢時,如果第一個就是 %,那么就無法利用索引,如果 % 不在第一個位置,那么就可以成功利用索引;
- 查詢過程中使用多列索引
多列索引是在表的多個字段創建一個索引,如果查詢條件中使用了第一個字段,才能利用索引;
- 查詢過程中使用 or 關鍵字
查詢語句只有 or 時,如果 or 前后兩個條件都是索引,那么可以利用,其中有一個不是,就不能利用。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號