
JVM學習筆記(五)
上一張章學習了垃圾收集的幾種算法,其中包括了最基礎的“標記-清除”算法,復制算法,標記-整理算法,分代收集算法。以及這幾種算法的優缺點。這一章來學習垃圾收集器。
收集算法是內存回收的方法論,而垃圾收集器是內存回事的具體實現。。。
由于java虛擬機規范對垃圾收集器的實現沒有規定,不同廠商,不同版本的虛擬機提供的垃圾收集器也不同。這里學習討論用到的虛擬機是 HotSpot 1.6版本 update 22,
這個虛擬機包含的垃圾收集器如下圖。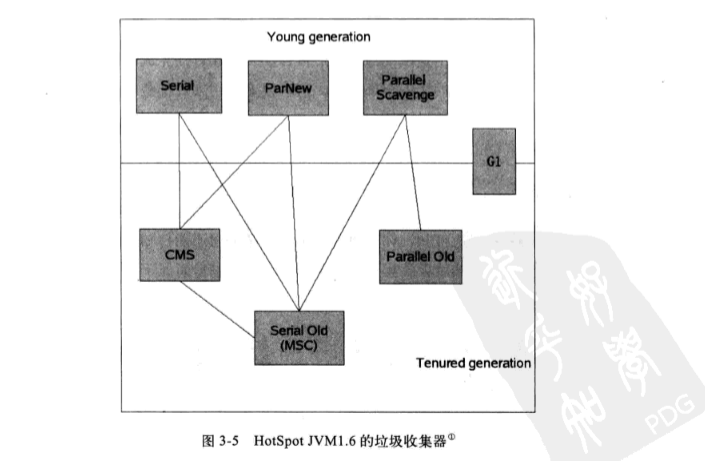
如果兩個收集器之間存在連線。說明他們可以配合使用。
1.Serial 收集器
Serial 收集器是最基本,年底最久遠的收集器,在jdk1.3之前是虛擬機新生代收集唯一的選擇。它是一個單線程的收集器。它的單線程不僅僅是說明只使用一個CPU
或一條收集線程去完成垃圾回收,更重要的是它進行垃圾回收時,必須暫停其他所有的工作線程,直到收集結束。相當于玩一個小時電腦。。停頓五分鐘。。
優點:簡單而高效(與其他收集的單線程相比),對應限定單個CPU的環境來說,serial收集器沒有線程交互的開銷,專心做垃圾收集,自己可以獲得最高的收集效率。
2.ParNew 收集器
ParNew 收集其實是Serial收集器的多線程版本,除了使用多線程進行垃圾收集之外,其余行為包括serial收集器可用的所有控制參數,收集算法,stop the world ,對象分配規則,
回收策略都跟serial 收集器是一樣的。pernew收集器除了多線程收集之外,其他地方與serial收集相比,并沒有創新的地方,但他卻是許多server模式下的虛擬機的新生代收集器的首先,根本
原因是:強大的CMS老年代收集器,只有 parNew收集器,serial收集器才能與之配合、
3.Parallel Scavenge 收集器
Parallel Scavenge 也是一個新生代收集器,使用的也是復制算法,也是并行的多線程收集器。看上去跟parnew收集器一樣,但是他關注的點與其他收集器不一樣。
他的目標的是達到一個可控制的吞吐量。(吞吐量:CPU用于運行用戶代碼的時間與CPU總消耗時間的總值,即吞吐量=運行用戶代碼時間/(運行用戶代碼時間+垃圾收集時間),虛擬機總運行花了
100分鐘,其中垃圾收集花了1分鐘,那么吞吐量就是99%)。
停頓時間越短,就越適合與用戶交互的程序,良好的響應時間能提升用戶體驗。
而高吞吐量則可以最高效率利用CPU時間,盡快完成程序的運算任務,主要適合在后臺運算而不需要太多交互的任務。
4.

 浙公網安備 33010602011771號
浙公網安備 33010602011771號