
一、重要算子
OCR分類器其實有很多,如下圖所示。但是通常mlp分類器效果較好,使用較多。
主要算子如下:
① append_ocr_trainf(Character, Image : : Class, TrainingFile : )
四個參數分別是:字符Region、字符Image、字符文本、OCR訓練的.trf文件路徑。
如果該路徑下不存在.trf文件,那么它會自動生成該文件。
該算子作用是將單個字符區域、單個字符圖像和對應的字符文本寫入TrainingFile 文件。
② read_ocr_trainf_names( : : TrainingFile : CharacterNames, CharacterCount)
查詢.trf訓練文件中存儲有哪些字符,以及每個字符在訓練器中的數量。
③ create_ocr_class_mlp(42, 67, 'constant', 'default', CharacterNames, NumHidden, 'none', 10, 42, OCRHandle)
最前面的兩個參數分別指字符的寬度和高度。NumHidden指隱藏層的層數,一般不宜過低。
④ trainf_ocr_class_mlp( : : OCRHandle, TrainingFile, MaxIterations, WeightTolerance, ErrorTolerance : Error, ErrorLog)
訓練神經網絡,通常參數用默認值即可。
⑤ write_ocr_class_mlp( : : OCRHandle, FileName : )
保存OCR的的.omc分類器到文件。
⑥ read_ocr_class_mlp( : : FileName : OCRHandle)
從文件中讀取OCR的.omc分類器。
一個典型的創建OCR分類器的過程通常是:
append_ocr_trainf → create_ocr_class_mlp → trainf_ocr_class_mlp → write_ocr_class_mlp
具體創建OCR分類器的方法,可以看這個例子:Halcon自動化訓練OCR分類器舉例
二、關鍵問題
1、create_ocr_class_mlp算子中,如何確定字符的寬度和高度?
同一種字體不同字符的寬度、高度是不一樣的(例如字母A和I),如何確定這兩個值?
有兩種方式:一是直接測量字符中較寬字符的寬度和高度,把它們作為 WidthCharacter和HeightCharacter ;二是使用OCR助手(助手——打開新的OCR)來分析得出這兩個值(推薦這種方式)。
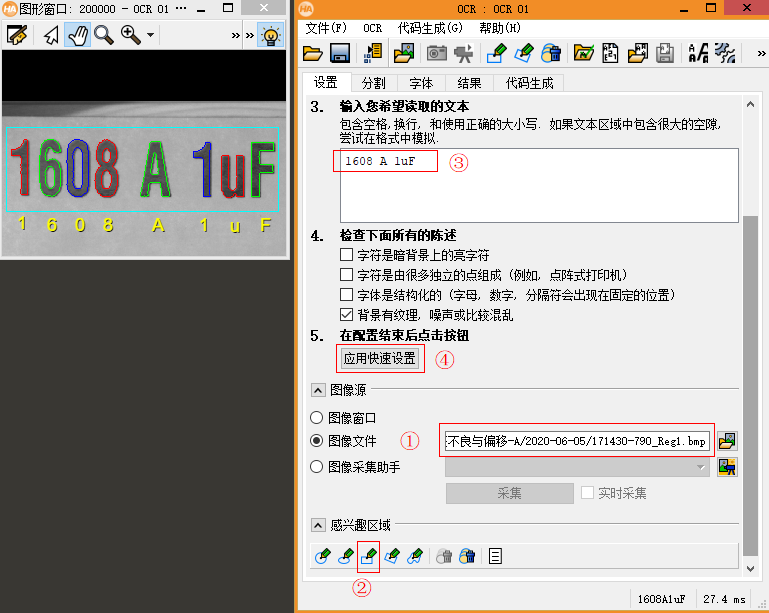
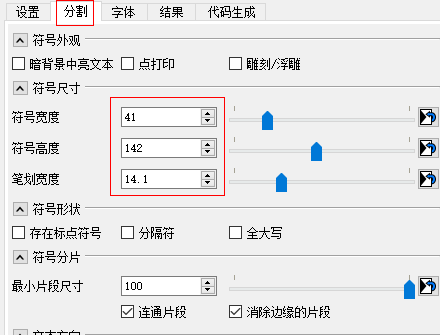
轉到“分割”頁面即可看到自動分析得出的“字符寬度”和“字符高度”等信息。
2、使用自己訓練的OCR分類器,還是使用Halcon自帶的分類器?
如果字體恰好合適的話,使用Halcon自帶的分類器,通常效果是極好的。但是缺點也很明顯:一是選擇有限,如果需要OCR的字體比較特殊,可能選不好合適的分類器;二是你很難對Halcon自帶的分類器進行優化,因為它只提供.omc文件,而不提供訓練用的.trf文件。
自己訓練的分類器也有優缺點。訓練和使用分類器主要使用下面幾個算子:
append_ocr_trainf、create_ocr_class_mlp、trainf_ocr_class_mlp、do_ocr_multi_class_mlp
缺點一是需要自己切割字符收集字庫,如下所示:

缺點二是可能自己訓練的分類器不如Halcon自帶的分類器效果好。(原因一方面因為字庫不夠豐富,另一方面可能對OCR的理解不夠深刻,導致訓練分類器時有些細節考慮不周全)
不過自己訓練分類器也有優點,最大的的優點是訓練過程可控,而且自己可以添加字符圖片,豐富字庫,即分類器可以不斷得到優化。這一點是Halcon自帶的分類器所不具備的。
3、如果使用Halcon自帶的分類器,如何選擇合適的?
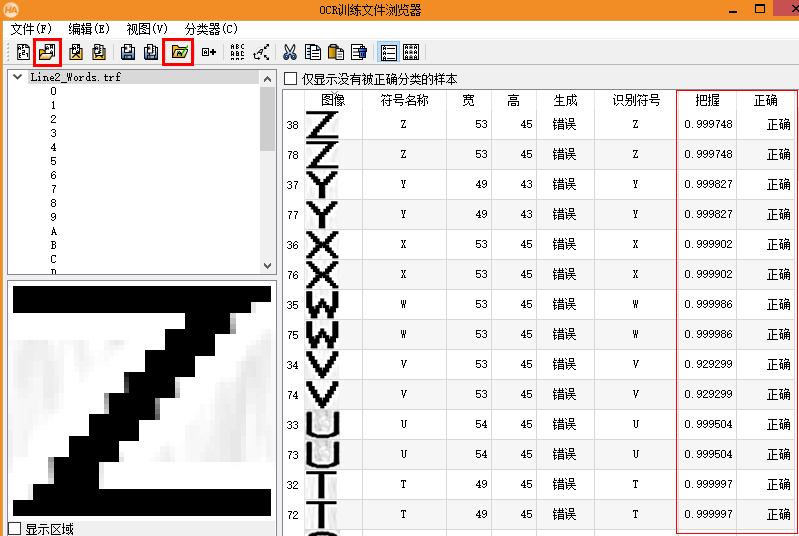
點擊OCR助手中的下圖中的紅框中的圖標即可。

先加載“訓練文件”(.trf),再加載“分類器”(.omc),即可看到識別結果及其把握度。當所有字符均識別正確,且把握度很高的時候,就說明這個分類器很合適。
4、如何準確分割出圖像中的字符區域?
OCR的過程實際是調用do_ocr_multi_class_mlp算子。
do_ocr_multi_class_mlp(Character, Image : : OCRHandle : Class, Confidence)
其中Character即是字符區域(Region),如下所示:

分割字符區域的思路有兩種:① 用形態學閾值分割;② 用find_text系列算子。
形態學分割算子大家比較熟悉,不需要多說,但是算子之間的組合比較靈活,思路比較重要。
find_text分割字符區域代碼舉例如下:(Characters即是字符區域Region)

注:如果自己訓練OCR分類器,create_text_model_reader就不需要傳入.omc文件路徑,例如:
create_text_model_reader ('manual', [], TextModel)
5、對于字符區域分割,形態學閾值分割和find_text方法,哪種更好?
通常來說,直接用find_text系列算子,很容易得到比較不錯的字符區域分割結果。因為它可以通過set_text_model_param算子設置很多字體的信息參數,例如:

這種方法的優點很明顯:就是很容易做到標準化。只需要設置幾個參數,就可以得到很好的分割效果。
但是這種方法的缺點也很明顯,它的自由度有點差,效果不理想時,繼續優化的辦法有限。如果該設的參數都設置了,分割字符區域效果還是不理想,該怎么辦呢?
因此,對于經驗豐富的視覺算法工程師,對于棘手的OCR項目,我仍然推薦使用形態學閾值分割來分割字符區域(Region),不過這個需要相當的技巧。
6、提高字符區域分割效果的技巧。
提高OCR準確率有兩條路子:① 訓練分類器時,盡量用豐富的字符圖片庫,訓練出良好的分類器;② 識別前,盡量分割出準確的字符區域,好利于識別。
訓練分類器的過程中,其實能玩出的花樣并不多。因此重點還是在分割字符區域這一步,建議如下:
(1)盡量把需要OCR的文字圖像轉正。
(2)可以用reduce_domain算子把需要OCR的圖像區域挖出來,排除圖像其他區域的干擾。
(3)分割之前可以增強圖像的對比度,例如使用scale_image_max和emphasize算子。
(4)改變圖像中字符筆畫寬度的算子gray_erosion_rect可嘗試使用,但是如果字符本身比較小,這個算子就不建議使用了,因為此時它對字符筆畫的寬度改變會很大。
(5)如果圖像光照情況基本一致,盡量使用threshold而不是binary_threshold這類自動閾值算子。因為threshold的結果是可預測的,而自動閾值的分割結果通常較難預測。
(6)閾值分割以后,可以使用select_shape算子限定一些篩選條件,篩選出真正的字符部分。
特別注意:訓練分類器的程序和正式識別字符的程序中,圖像預處理和閾值分割方式必須一致,這樣才能得到最好的OCR效果。
7、對于識別錯的“相似”字符的補救措施。
有些字符是很相似的,例如字母“Q”和“O”,字母“I”和數字“1”。

對于上圖的Q和O,如果容易識別混淆,那么如何判斷到底是Q還是O呢?
提供一種思路:可以求字母內部的空白區域,調用算子:convexity (CharRegion, Convexity)
這個算子可以獲得Q或者O內部區域的“凸度”,凸度極高的,說明這個字符是O,反之就是Q。
其他字符也可以用其他方法分別個性化判斷。
另外,對于OCR,可以觀察圖中字符的分布,例如某一塊區域只可能出現數字,但是識別出了形如“058I”這樣的結果,那么很可能就是把數字“1”錯判為了字母“I”。這時可以人為把字母“I”改成數字“1”作為后續補救措施。
至于其他未提到的OCR技巧,歡迎留言補充。
--------------------------------------------
本文系原創,轉載請注明出處。
如果文章對您有幫助,可以點擊下方的【好文要頂】或【關注我】;如果您想進一步表示感謝,可通過網頁右側的【打賞】功能進行打賞。
感謝您的支持,我會繼續寫出更多的相關文章!文章有不理解的地方歡迎跟帖交流,博主經常在線!^_^

 浙公網安備 33010602011771號
浙公網安備 33010602011771號