
第二次作業-肖大智
【第一部分】視頻學習心得及問題總結
由神經網絡模型創造的價值基本上都是基于監督式學習的。當數據量增大的時候,深度學習模型的效果會逐漸好于傳統機器學習算法。現在深度學習如此強大的原因歸結為三個因素:Data,Computation,Algorithms。其中,數據量的幾何級數增加,加上GPU出現、計算機運算能力的大大提升,使得深度學習能夠應用得更加廣泛。另外,算法上的創新和改進讓深度學習的性能和速度也大大提升。邏輯回歸模型一般用來解決二分類問題。二分類就是輸出y只有{0,1}兩個離散值。邏輯回歸問題可以看成是一個簡單的神經網絡,只包含一個神經元。邏輯回歸的損失函數,在設計好網絡模型后,w和b都是未知參數,需要反復訓練優化得到。因此,我們需要定義一個cost function,包含了參數w和b。通過優化cost function,當cost function取值最小時,得到對應的w和b。對于m個訓練樣本,我們通常使用上標來表示對應的樣本。最小化Cost function,讓Cost function盡可能地接近于零。梯度下降算法用來計算出合適的w和b值,從而最小化Cost function。梯度下降算法是先隨機選擇一組參數w和b值,然后每次迭代的過程中分別沿著w和b的梯度(偏導數)的反方向前進一小步,不斷修正w和b。每次迭代更新w和b后,都能讓J(w,b)更接近全局最小值。整個神經網絡的訓練過程實際上包含了兩個過程:正向傳播和反向傳播。正向傳播是從輸入到輸出,由神經網絡計算得到預測輸出的過程;反向傳播是從輸出到輸入,對參數w和b計算梯度的過程。反向傳播算法內容比較復雜。自編碼器是一個只有一個隱藏層的神經網絡,它先對輸入x進行編碼,再對編碼結果進行解碼,我們希望能夠得到和輸入x非常相似的輸出y(最理想情況就是輸入和輸出完全一樣)。則編碼所得到的結果就可以看作是該輸入數據的特征。對于該目標更新網絡參數,從而使其效果達到最優,這就構建了一個自解碼器。受限玻爾茲曼機的本質是一種自編碼器,它由可視層和隱藏層組成,可視層其實就是輸入層,只不過名稱不同。可視層和隱藏層之間的神經元采用對稱的全連接,而層內的神經元之間沒有連接。所有的神經元只有1和0兩種狀態,分別表示激活和未激活。
問題:1.什么樣的數據集適合節點數多的模型?
2.什么樣的數據集適合層數多的模型?
3.模型具體是怎么訓練的?
4.為什么加了ReLU激活函數之后,準確率大大提高?
【第二部分】代碼學習
1.

提示出錯,根據提示將v改為float型后成功運行。
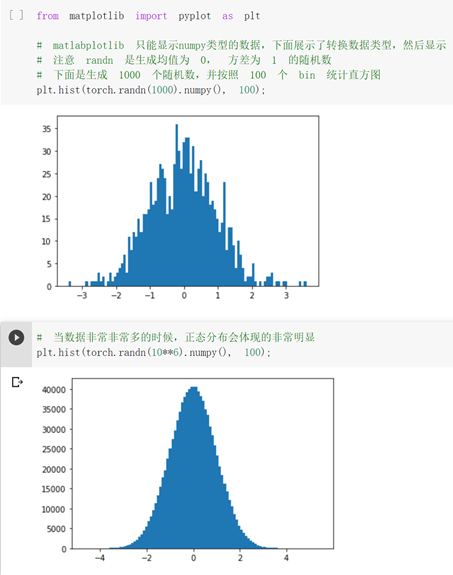
之前用c語言沒做過這種可視化的圖表,感覺很有意思,很厲害。
2.
2.1

1.不改動
訓練模型一:8s
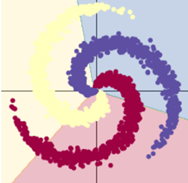
訓練模型二:9s
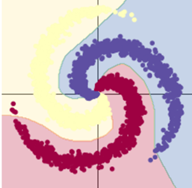
用了 Rule函數的模型訓練效果顯著提升。
2.樣本改為10000
訓練模型一:11s

訓練模型二:12s
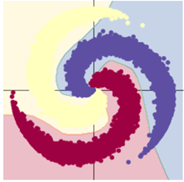
樣本點增加,訓練結果差別不大。
3.隱層節點改為1000
訓練模型一:9s
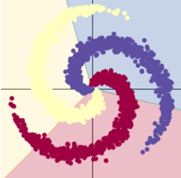
訓練模型二:10s
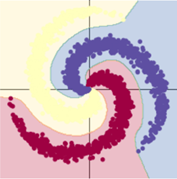
隱層節點增加,用了激活函數的模型效果顯著提升;而模型一基本不變。
總結:使用合適的激活函數、增加隱層節點可以提高訓練效果。同時會一定程度上增加訓練時間。
//樣本類別改為7還挺好看的

2.2
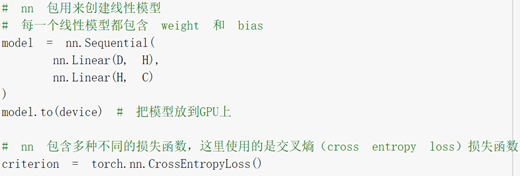
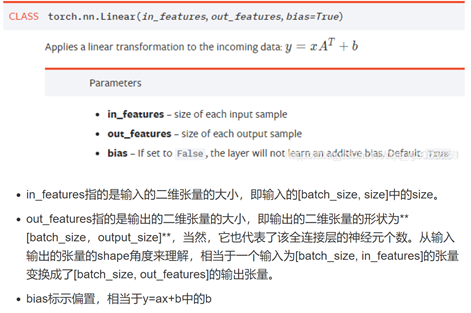
查了nn.linear()參數的意義,還是不理解函數做了什么。
Relu激活函數對訓練模型的改善極大。


 浙公網安備 33010602011771號
浙公網安備 33010602011771號