
C#發現之旅第一講 C#-XML開發
袁永福 2008-5-15
系列課程說明![]() 為了讓大家更深入的了解和使用C#,我們將開始這一系列的主題為“C#發現之旅”的技術講座。考慮到各位大多是進行WEB數據庫開發的,而所謂發現就是發現我們所不熟悉的領域,因此本系列講座內容將是C#在WEB數據庫開發以外的應用。目前規劃的主要內容是圖形開發和XML開發,并計劃編排了多個課程。在未來的C#發現之旅中,我們按照由淺入深,循序漸進的步驟,一起探索和發現C#的其他未知的領域,更深入的理解和掌握使用C#進行軟件開發,拓寬我們的視野,增強我們的軟件開發綜合能力。
為了讓大家更深入的了解和使用C#,我們將開始這一系列的主題為“C#發現之旅”的技術講座。考慮到各位大多是進行WEB數據庫開發的,而所謂發現就是發現我們所不熟悉的領域,因此本系列講座內容將是C#在WEB數據庫開發以外的應用。目前規劃的主要內容是圖形開發和XML開發,并計劃編排了多個課程。在未來的C#發現之旅中,我們按照由淺入深,循序漸進的步驟,一起探索和發現C#的其他未知的領域,更深入的理解和掌握使用C#進行軟件開發,拓寬我們的視野,增強我們的軟件開發綜合能力。
本系列課程配套的演示代碼下載地址為 https://files.cnblogs.com/xdesigner/cs_discovery.zip 。
本系列課程已發布的文章有
C#發現之旅第一講 C#-XML開發
C#發現之旅第二講 C#-XSLT開發
C#發現之旅第三講 使用C#開發基于XSLT的代碼生成器
C#發現之旅第四講 Windows圖形開發入門
C#發現之旅第五講 圖形開發基礎篇
C#發現之旅第六講 C#圖形開發中級篇
C#發現之旅第七講 C#圖形開發高級篇
C#發現之旅第八講 ASP.NET圖形開發帶超鏈接的餅圖
C#發現之旅第九講 ASP.NET驗證碼技術
C#發現之旅第十講 文檔對象模型
本課程介紹了使用C#進行XML開發。重點介紹使用System.Xml名稱空間來讀取,保存和處理XML文檔。
XML介紹 XML基礎規范XML全名是可擴展標記語言,是W3C國際標準組織規定的一種基于文本的數據存儲格式,它是從IBM的SGML技術派生的,HTML也是從SGML派生的。SGML內容非常復雜,而XML使用了SGML的20%的語法實現了SGML的80%的功能。
從軟件開發人員的角度看, XML語法主要有
- XML是國際標準,絕大部分軟件廠商,開發工具和編程語言都支持相同的基本XML規范。XML文檔可用于任何開發平臺上,這是XML技術最大的優勢。相對來說,JAVA這種非國際標準的技術跨平臺則是不太容易的。
- XML是基于純文本的,XML文檔中是不能包含二進制數據。而且存儲文件時會涉及到文本編碼格式的問題。
- XML文件具有層次結構,其中使用一對尖括號來定義一個XML元素,一個XML元素可以包含若干個屬性,而XML元素下面可以包含若干個子XML節點。
- 一個XML文檔只能而且必須定義一個根元素,不可多定義,也不能不定義。
- XML元素不能錯亂套嵌定義,比如“<a><b></a></b>”是錯誤的XML文檔。
- XML格式是為了各系統交流數據而設計的,其設計過程考慮了方便的數據的臨時存儲和交流,而不考慮數據的長期存儲,因此XML文檔比較冗余,文件體積大,因此不適合存儲大數據量,網絡傳輸效率低。在軟件開發中需要注意到這個問題。
XPath是W3C國際標準組織提出的在一個XML文檔中快速檢索和定位XML節點的標準。關于它將在下節課程詳細介紹。
XSLTXSLT也是W3C國際標準組織在XML標準的基礎上提出的XML文檔轉換的標準,它是一種非常重要的XML應用,它也是跨平臺的,受到眾多軟件廠商的支持。在下節課程將詳細介紹XSLT。
W3C此處多次提到W3C國際標準組織,那么到底什么是W3C國際標準組織呢?
W3C是大部分軟件企業聯合起來制定某些重要軟件業標準的國際組織。它的成員包括微軟,IBM,SUN等軟件巨頭。它制定和維護了HTML,XHTML,HTTP,XML,VML,XPath,XForm等軟件行業內重要的標準,絕大多數軟件廠商都支持W3C制定的標準,它制定的標準是真正的跨平臺的全球通用的。因此它對全球軟件業界,尤其是WEB軟件業界有著巨大的影響。它的網址是 http://www.w3c.org/,在它的網站上可以看到它所制定的上百個標準。大家若要開發具有國際水平的WEB應用系統,應當要好好學習W3C的某些標準。
國際標準的意義在這里說明一下國際標準的意義。
所謂國際標準就是某個權威的非營利性的國際組織,其立場中立,不代表某個具體的公司,而是代表整個業界。它針對某項普遍使用的技術出臺一些規范和標準。而各個具體的軟件廠商在運用這項技術時自覺遵守這套國際標準。這樣能方便各個系統之間交流數據,保障異構系統進行集成,并保持數據結構的長期穩定性和兼容性。這樣的國際組織有ISO,ECMA和W3C等等。
我們使用到的一些技術都已經成為國際標準,例如SQL,JavaScript,C#,HTML,XML,XSLT,HTTP等很多技術。
國際標準具有一些特點,首先是穩定性和連貫性,國際標準一旦正式發布,就保持了相當的穩定性,其內容只能慎重的增加而不能刪減,國際標準組織不會輕易修改已經正式發布的國際標準,而且在修改標準時會充分考慮到各種因素,保證向上和向下的兼容性,能最大程度的保障業界在舊標準上的投資。而且這些國際組織發布國際標準時有時會事先提出標準的修訂計劃。
其次國際標準是全球業界都遵守的,雖然沒有強制遵守的機制,但絕大多數軟件廠商都會遵守或者努力遵守這些國際標準。而且國際標準組織的成員有很多大軟件廠商,比如W3C的成員就有微軟,IBM,SUN等大公司。因此國際標準是代表了最廣大軟件業界的根本利益,代表了最先進的軟件生產力。
對于應用軟件開發商,充分的運用國際標準能很大程度的保護客戶在IT系統上的投資。由于國際標準具有相當的穩定性和連貫性,若客戶IT系統充分的使用了這些國際標準,則在升級到新標準時能獲得很好的兼容性。IT系統不用推倒重來,這樣能保護客戶在已有系統上的投資。
作為軟件開發人員,也應當了解這些國際標準,首先是能比較容易的實現異構系統的集成,并能獲得比較好的系統兼容性和可維護性。而且軟件開發人員在切換開發平臺,比如從Java轉移到.NET平臺上時,以前學習國際標準的投資就會得到保護,而遵守相同標準的源代碼的移植和翻譯也是低成本的。
DOT.NET框架對XML的支持.NET框架提供了對XML的強大支持,而且.NET框架本身也普遍采用XML格式來存儲各種配置信息。比如web.config文件。
在.NET類庫中,名稱空間System.Xml下面就包含了大量的操作XML文檔的類型。這些類型構成了兩種XML文檔的處理模型。
流式處理模型在流式處理模型中,我們將XML文檔做作一個數據流來進行處理,我們將逐個處理XML文檔中的數據,在這種模型下,我們可以只讀的快速讀取大體積的XML文檔,而且內存占用少,程序性能好。類型System.Xml.XmlReader就提供了流式處理模型,使用XmlReader就可以快速讀取XML文檔。
使用流式處理模型是有缺點的,首先是它只能讀取XML文檔,不能修改XML文檔;其次是檢索XML文檔內容不方便,不能使用XPath技術;而且編程接口比較簡單,處理XML文檔不夠方便。當程序需要比較簡單的從XML文檔讀取數據則可以采用流式處理模型。
DOM處理模型在DOM處理模型中,我們首先是使用文檔對象模型的思想解析整個XML文檔,在內存中生成一個對象樹來表述XML文檔。比如使用一個XmlElement對象來影射到XML文檔中的一個元素,使用XmlAttribute對象來影射到XML文檔中的一個屬性。這樣我們編程操作內存中的對象就影射為操作XML文檔。
使用DOM處理XML文檔具有相當大的優點,首先是處理方便,我們可以使用各種編程技巧來處理XML文檔對象樹狀結構,比如可以遞歸遍歷XML文檔的一部分或全部,可以向樹狀結構插入,修改或刪除XML元素,可以設置XML元素的屬性。
在DOM模式下,我們可以使用XPath技術在XML文檔樹狀結構中進行快速檢索和定位,這為處理XML文檔帶來比較大的方便。
在C#中,我們可以很簡單的使用DOM方式處理XML文檔。我們首先實例化一個System.Xml.XmlDocument類型,調用它的Load方法既可加載XML文檔并生成XML節點對象樹狀結構,然后我們就可以遍歷這個對象樹,新增修改和刪除節點,而且其中的任意一個節點都可以使用SelectNodes或SelectSingleNode方法通過XPath相對路徑快速查找其它的節點。
在名稱空間System.Xml下面大部分類型都是用來支持DOM處理模型的。其中很多類型配合起來共同組織成XMLDOM,XMLDOM是一種很典型的文檔對象模型的應用。文檔對象模型是一種比較高級的軟件設計模式,我會在今后的課程中詳細介紹文檔對象模型這種軟件設計模式。
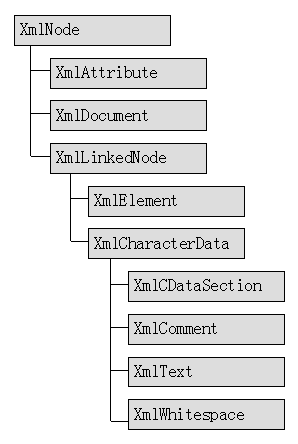 System.Xml名稱空間下的支持DOM的類型主要有
System.Xml名稱空間下的支持DOM的類型主要有
XmlNode 是DOM結構中的所有類型的基礎類型,它定義了所有XML節點的通用屬性和方法,是XMLDOM的基礎。它具有一個ChildNodes屬性,表示它所包含的子XML節點。
XmlAttribute 表示XML屬性,它只保存在XmlElement的Attributes 列表中。
XmlDocument表示XML文檔本身,是XMLDOM模型中的頂級對象,它用于對XML文檔進行整體的控制,并且是其它程序訪問XML文檔對象樹的唯一入口。
XmlLinkedNode在XmlNode的基礎上實現了訪問前后同級節點的方法。
XmlElement元素表示XML元素。是XMLDOM中使用最多的對象類型。它具有Attributes屬性可以處理它所擁有的屬性,可以使用ChildNodes屬性獲得它所有的子節點。并提供了一些添加和刪除子節點的方法。
XmlCharacterData表示XML文檔中的字符數據的基礎類型。字符文本數據是分布在各個XMLElement之間的純文本數據。XmlAttribute中的文本數據是不屬于XML文本塊的。
XmlCDataSection 表示XML文檔中CData節,CData數據是采用”<![CDATA[ ]]>”包括起來的純文本數據。由于XML采用尖括號進行標記,因此具有和HTML類似的轉義字符,在一般的XML純文本段中若遇到尖括號等特殊字符時需要使用轉義字符,當文本段中包含大量的這類特殊字符時,手工書寫和察看XML文檔將比較困難,為了改善XML文檔的可讀性,在此可以使用CDATA節。在CDATA節中,所有的字符,包括特殊字符都不需要轉義,這樣察看和修改XML文檔都比較方便。
XmlComment表示一段注釋,XML注釋和HTML注釋一樣,使用一對”<!-- -->”來包含起來。
XmlText表示一段純文本數據。
XmlWhitespace表示XML文檔中一段純粹由空白字符組成的文本塊,空白字符包括空格,制表符,換行和回車符,全角空格不屬于空白字符。XmlDocument在解析XML文檔時會處理空白字符,當XmlDocument對象的PreserveWhiitespace屬性為true時,會為XML文檔中的純空白文本塊生成XmlWhitespace對象,若該屬性為false時,則會忽略掉純空白文本,不會生成XmlWhitespace對象,好像原始的XML文檔中不存在這樣的空白文本塊一樣。
其它處理模型除了流式處理模型和DOM處理模型外,還存在一些比較另類的使用比較少的處理模型,在此簡單介紹一下
DBDOM
DBDOM是一種基于數據庫的XML文檔處理模型,它是一個開源項目。它采用大量的存儲過程和數據庫操作,將一個個XML元素,XML屬性等信息保存到數據庫的字段中。使用關系型數據庫來模擬實現XML的樹狀結構。我對這個模型也不甚了解,只是知道大概的原理。
BinaryXML
DOM方式處理XML文檔是需要消耗大量的內存的,在處理大型XML文檔時,DOM方式會比較大的影響應用系統的性能的。為此有人開始提出BinaryXML的處理模型。在這個模型中,XML文檔是當作二進制數據加載到內存中,然后解析文檔,使用大量的指針來指向XML文檔中的關鍵位置,通過指針可以快速定位XML文檔,能修改XML文檔,并能提供類似DOM的編程接口。這種方式能大大節省內存,所消耗的內存僅比XML文件大小稍微大些。但實際運行效果我也不清楚。
XML對WEB開發的意義XML技術對WEB開發具有重大意義。若要開發高水平的WEB系統,應當好好使用XML技術。
XML和HTMLXML和HTML都源自SGML,具有相同的來源,而且兩者都是采用尖括號的標記語言,兩者具有很大的相似性。使用XML完全可以模擬出HTML,而且W3C提出了現代WEB站點應當采用的XHTML標準就是XML和HTML的結合。
在使用ASP.NET開發WEB系統中,除了使用ASP.NET控件展示數據外,還需要由程序拼湊出大量的HTML代碼來展現數據。簡單的進行字符串連接操作來生成HTML頁面不是一種可持續性的軟件開發和維護的過程。程序代碼很容易雜亂無章,生成的HTML代碼可讀性不好。若在生成HTML代碼的過程借鑒XML技術則有助于改善這種問題,從而能更好的控制WEB軟件的開發過程,提高軟件質量。
XML和WebServiceWebService基礎就是XML,WebService的原理是將編程對象序列化成一個XML文檔,然后通過HTTP協議傳遞給客戶端,客戶端接受這個XML文檔,通過反序列化重現編程對象。因此WebService的基礎就是XML序列化技術。在開發和調試稍微復雜的WebService是需要一定的XML技術基礎。
Ajax技術的底層也是使用XML來傳遞數據的,可以看作一種特殊的WebService。可以這樣比喻,WebService是WEB系統的公開方法,而Ajax則是私有方法。
XML/XSLT提供一種全新的開發模式XML/XSLT兩項技術的配合可以提供一種全新的WEB系統開發模式。在這種模式下,頁面將需要顯示的純粹的數據組織生成一個XML文檔,并配上XSL轉換信息頭,然后發送到客戶端,在客戶端IE瀏覽器接受解析XML文檔,根據其中的XSL轉換頭信息再下載XSLT文檔,執行XSLT轉換,然后才顯示轉換的結果。此時WEB頁面既能正常的使用指定的格式顯示數據,而且本身就是一個可供其它程序調用的WebService。該頁面的輸出的源代碼就是XML文檔,而且只有IE等瀏覽器類型軟件才處理XSLT轉換信息頭,其他程序是會忽略掉這個信息的。此時頁面具有雙重功能,便于代碼的集成開發和維護。
關于XSLT下節課程將詳細介紹。
使用C#輸出XML接下來我們將使用C#進行實際的XML開發,由于XML技術對WEB開發特別有用,因此將使用ASP.NET來演示使用C#進行XML開發。此處演示程序已經寫好,現在對程序代碼進行詳細說明。
本程序是一個ASP.NET程序,大家獲得程序代碼后要在IIS中設置虛擬目錄,由于程序還需要訪問程序目錄下的一些文件,因此還需要進行一些權限的配置。程序目錄下的 demomdb.mdb 是程序使用的數據庫文件。
網站配置完畢后,我們在瀏覽器中輸入網站的地址即可打開它的默認頁面。可以看到默認頁面上有些程序內容的簡單說明。
首先我們看看 recordxml.aspx 頁面,我們看看 recordxml.aspx 的 HTML頁面代碼,可以看到該頁面HTML代碼很簡單,只有一行。因此該頁面的所有內容都是用C#代碼生成的。
我們切換到該頁面的C#代碼,可以看到在 Page_Load 函數里面添加了代碼輸出頁面內容。代碼內容為
| // 此處使用 XmlTextWriter 來快速輸出XML文檔內容.不構造XML文檔對象結構 this.Response.ContentEncoding = System.Text.Encoding.GetEncoding( 936 ); this.Response.ContentType = "text/xml"; // 連接數據庫 using( System.Data.OleDb.OleDbConnection conn = new System.Data.OleDb.OleDbConnection()) { conn.ConnectionString = @"Provider=Microsoft.Jet.OLEDB.4.0;Data Source=" + this.Server.MapPath("demomdb.mdb"); conn.Open(); // 查詢數據庫 using( System.Data.OleDb.OleDbCommand cmd = conn.CreateCommand()) { cmd.CommandText = "Select * From Customers"; System.Data.OleDb.OleDbDataReader reader = cmd.ExecuteReader(); // 獲得所有字段名 int FieldCount = reader.FieldCount ; string[] FieldNames = new string[ FieldCount ] ; for( int iCount = 0 ; iCount < FieldCount ; iCount ++ ) { FieldNames[ iCount ] = reader.GetName( iCount ); } // 生成一個XML文檔書寫器 System.Xml.XmlTextWriter xmlwriter = new System.Xml.XmlTextWriter( this.Response.Output ); xmlwriter.Indentation = 3 ; xmlwriter.IndentChar = ' '; xmlwriter.Formatting = System.Xml.Formatting.Indented ; // 開始輸出XML文檔 xmlwriter.WriteStartDocument(); // 輸出XSLT樣式表信息頭 string strXSLRef = this.Request.QueryString["xsl"] ; if( strXSLRef != null && strXSLRef.Length > 0 ) { xmlwriter.WriteProcessingInstruction( "xml-stylesheet" , "type='text/xsl' href='" + strXSLRef + "'"); } xmlwriter.WriteStartElement("Table"); while( reader.Read()) { // 輸出一條記錄 xmlwriter.WriteStartElement("Record"); for( int iCount = 0 ; iCount < FieldCount ; iCount ++ ) { // 輸出一個字段值 xmlwriter.WriteStartElement( FieldNames[ iCount ] ); object v = reader.GetValue( iCount ); if( v == null || DBNull.Value.Equals( v )) { xmlwriter.WriteAttributeString("Null" , "1"); } else { xmlwriter.WriteString( Convert.ToString( v )); } xmlwriter.WriteEndElement(); } xmlwriter.WriteEndElement(); }//while( reader.Read()) reader.Close(); xmlwriter.WriteEndElement(); xmlwriter.WriteEndDocument(); xmlwriter.Close(); }//using( System.Data.OleDb.OleDbCommand cmd = conn.CreateCommand()) }//using( System.Data.OleDb.OleDbConnection conn = new System.Data.OleDb.OleDbConnection()) |
Page_Load 函數的執行流程為
設置HTTP輸出類型首先設置HTTP的輸出類型,我們設置輸出的編碼格式為 GB2312,此處使用 GetEncoding(936 ) 就是獲得GB2312的編碼格式。
我們還設置 ContentType 來設置文檔的輸出格式。大家若了解一些HTTP傳輸協議的都知道,ContentType屬性描述了文檔輸出類型,當文檔傳遞到客戶端時,客戶端瀏覽器獲得ContentType屬性值,查詢注冊表和Windows中注冊的COM信息,獲得該屬性值確定的文件類型,然后使用相應的模式顯示文檔。比如若設置ContentType屬性為application/vnd.ms-excel ,則客戶端瀏覽器查詢注冊表得知對應的文件類型信息在注冊項目 HKEY_CLASS_ROOT\.xls下面,本地文件類型為”Excel.Sheet.8”,然后又根據其他信息轉而調用EXCEL的COM組件來顯示獲得的HTTP文檔。
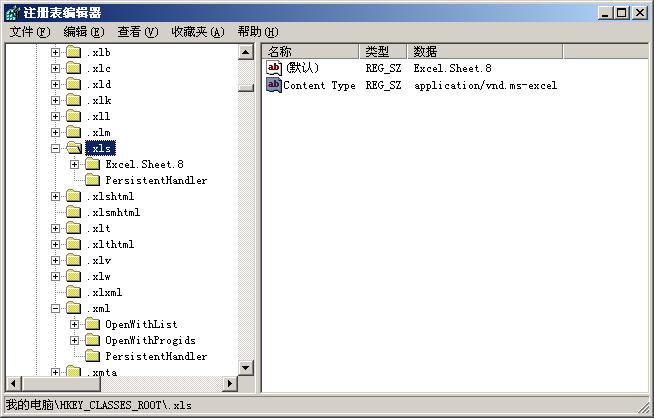
從ContentType屬性的說明我們可以了解,很深入的掌握WEB開發,有時候是需要了解一些Windows編程的知識,因為B/S系統的客戶端,也就是各種瀏覽器,特別是IE瀏覽器就是比較復雜的Windows程序。
查詢數據庫設置了HTTP文檔輸出模式后,我們開始輸出XML文檔內容,首先是連接數據庫,使用了程序目錄下的demomdb.mdb數據庫,執行一個SQL查詢,獲得一個數據讀取器reader。
使用XmlTextWriter輸出XML文檔查詢得到數據后,我們就可以遍歷查詢所得的數據庫記錄,開始輸出XML文檔,此處我們使用XmlTextWriter輸出文檔。
輸出XML文檔我們有兩種方式,一種是使用XmlTextWriter輸出,另外一種是從XmlDocument類型開始構造XML文檔對象結構,然后使用XmlDocument的Save方法輸出XML文檔。兩種方法有各自特點。
使用XmlTextWriter是只寫的向前的快速輸出XML文檔,而且輸出時不能訪問已經輸出的XML文檔內容,不能修改已經生成的XML文檔。這種方法速度快,占用內存少,但不夠靈活。
而使用XmlDocument類型構造XML文檔結構后再輸出XML文檔的方法比較靈活,我們可以隨時訪問和修改已經輸出的Xml文檔。這種方法速度慢,占用內存多,但很靈活。
在這里我們要嘗試使用XmlTextWriter來輸出XML文檔,在另外的一個頁碼使用XmlDocument輸出XML文檔。
我們首先在頁面輸出流上新建一個XmlTextWriter對象,設置它啟動縮進。它的Indentation,IndentChar和Formating就是控制縮進樣式,具體說明可以查看MSDN。XML文檔縮進是為了改善XML文檔的可讀性,有縮進的XML文檔便于人們直接閱讀和修改,但對應用程序來說,XML文檔是否有縮進是沒差別的。
XmlTextWriter是一個基于其他流的針對輸出XML文檔的包裝,它本身不能打開文件,因此在初始化XmlTextWriter時必須指明底層的輸出對象,輸出對象可以為流或者文本書寫器。理論上我們可以使用字符串拼湊來生成XML文檔,但實際開發中使用字符串拼湊XML文檔不是明智之舉,建議使用XmlTextWriter。
我們在web開發中有時會使用字符串拼湊來生成HTML文檔,由于HTML文檔沒有很嚴格的語法限制,IE瀏覽器能解釋劣質的HTML代碼,因此有時會有開發者這樣字符串拼湊HTML文檔,但這會導致代碼比較雜亂,可讀性不好。而XML文檔具有很嚴格的語法檢查,只要一個XML語法錯誤就會導致整個XML文檔解析錯誤,因此我們應當使用XmlTextWriter,因此它能幫助我們檢查基本的XML語法,確保我們能輸出合格的XML文檔。
我們調用WriteStartDocument來開始輸出XML文檔,XmlTextWriter提供了很多配對使用的成員,使用一個方法后需要使用另外一個配對的方法。比如WriteStartDocument和WriteEndDocument配對,WriteStartElement和WriteEndElement配對,配對的方法必須成對調用。此處我們使用WriteStartDocument開始書寫Xml文檔,我們就必須使用WriteEndDocument 來完成輸出XML文檔的。而且在使用XmlTextWriter輸出XML文檔的時候,WriteStartDocument必須是第一個調用的方法。
然后我們使用一個名稱為xsl的頁面參數來輸出XML文檔的xml-stylesheet信息頭,關于XSL下節課將詳細介紹,在本節課不管這個參數。
我們調用WriteStartElement 方法來輸出XML文檔的根節點,這里參數為字符串 “Table” , 則表示輸出的XML文檔的根節點名稱為Table。
然后我們使用數據庫數據讀取器的Read函數來遍歷所有的查詢的數據,對于每一條記錄,使用XML書寫器的WriteStartElement方法來輸出XML元素,這里參數為字符串”Record”,表示輸出的XML元素名為Record,而且這個節點添加到XML文檔的根節點下。
對于每一條記錄我們還遍歷其所有的字段值,對每一個字段值使用WriteStartElement新增一個XML元素,元素名稱就是各個字段的名稱。若字段值是空則使用WriteAttributeString輸出名為Null 的XML屬性,否則使用WriteString來輸出字段值的字符串表達值。
由于WriteStartElement和WriteEndElement配對使用,因此每輸出完一個XML元素后需要調用WriteEndElement來結束輸出XML元素。當所有的內容輸出完畢后我們調用WriteEndDocument來結束輸出整個XML文檔的。
使用XmlDocument輸出XML文檔頁面record.aspx功能和recordxml.aspx類似。但它使用 XmlDocument來構造XML文檔對象結構,然后輸出XML文檔。現對其過程進行說明。
打開record.aspx的HTML代碼,可以看到代碼非常簡單,只有一行,所有的頁面輸出都在程序代碼中實現。打開它的C#代碼,可以看到在Page_Load 方法中添加了代碼執行頁面輸出,其代碼為
| // 此處代碼動態構造 XmlDocument對象 來輸出XML文檔 System.Xml.XmlDocument XmlDoc = new System.Xml.XmlDocument(); XmlDoc.AppendChild( XmlDoc.CreateElement("Table")); // 連接數據庫 using( System.Data.OleDb.OleDbConnection conn = new System.Data.OleDb.OleDbConnection()) { conn.ConnectionString = @"Provider=Microsoft.Jet.OLEDB.4.0;Data Source=" + this.Server.MapPath("demomdb.mdb"); conn.Open(); // 查詢數據庫 using( System.Data.OleDb.OleDbCommand cmd = conn.CreateCommand()) { cmd.CommandText = "Select * From Customers"; System.Data.OleDb.OleDbDataReader reader = cmd.ExecuteReader(); // 獲得所有字段名 int FieldCount = reader.FieldCount ; string[] FieldNames = new string[ FieldCount ] ; for( int iCount = 0 ; iCount < FieldCount ; iCount ++ ) { FieldNames[ iCount ] = reader.GetName( iCount ); } while( reader.Read()) { // 輸出一條記錄 System.Xml.XmlElement RecordElement = XmlDoc.CreateElement("Record"); XmlDoc.DocumentElement.AppendChild( RecordElement ); for( int iCount = 0 ; iCount < FieldCount ; iCount ++ ) { // 輸出一個字段值 System.Xml.XmlElement FieldElement = XmlDoc.CreateElement( FieldNames[ iCount ] ); RecordElement.AppendChild( FieldElement ); object v = reader.GetValue( iCount ); if( v == null || DBNull.Value.Equals( v )) { FieldElement.SetAttribute("Null" , "1" ); } else { FieldElement.AppendChild( XmlDoc.CreateTextNode( Convert.ToString( v ))); } } }//while( reader.Read()) reader.Close(); }//using( System.Data.OleDb.OleDbCommand cmd = conn.CreateCommand()) }//using( System.Data.OleDb.OleDbConnection conn = new System.Data.OleDb.OleDbConnection()) string strXSLRef = this.Request.QueryString["xsl"] ; if( strXSLRef != null && strXSLRef.Length > 0 ) { // 根據頁面參數指定的XSLT樣式表名稱執行XSLT轉換 strXSLRef = this.Server.MapPath( strXSLRef ); System.Xml.Xsl.XslTransform transform = new System.Xml.Xsl.XslTransform(); transform.Load( strXSLRef ); transform.Transform( XmlDoc , null , this.Response.Output , null ); } else { // 直接輸出生成的XML文檔 this.Response.Write( XmlDoc.DocumentElement.OuterXml ); } |
現對該方法的執行過程進行說明。
首先是創建一個XmlDocument對象,XmlDocument創建時是一個空的XML文檔,沒有任何內容,沒有根元素,因此第一步就是使用文檔對象的AppendChild方法來添加根元素。在這里我們使用了文檔對象的CreateElement函數來創建一個名為Table的XMLElement元素對象。
各種類型的XML文檔對象,包括元素,屬性,文本塊,注釋等等,都不能直接實例化,只能使用XmlDocument的一系列以Create開頭的函數來創建對象實例。創建的XML文檔對象是一個個離散的對象,必須及時的添加到XML文檔對象結構中才能真正成為XML文檔的一部分。一般的使用XML文檔對象或元素對象的AppendChild方法將新創建的XML文檔對象添加到指定對象下面,如此才加入了XML文檔結構的大家庭中。
這種處理模式類似向DataTable添加新的數據行。DataRow本身不能直接實例化,我們首先得使用DataTable 的NewRow創建一個新的DataRow,然后使用DataTable的Rows屬性的Add方法向數據表添加剛剛創建的數據行。
初始化一個XML文檔對象后,我們連接數據庫,查詢數據庫獲得一個數據讀取器,然后遍歷查詢所得的數據庫記錄,輸出XML文檔。
對每一個數據庫記錄,首先創建一個RecordElement對象,添加到XML文檔的根節點下,然后遍歷數據庫記錄的每一個字段值,創建一個FieldElement對象并添加到RecordElement下面,若當前數據庫字段值為空,則調用FieldElement的SetAttribute 方法,設置名為Null的屬性值為1,否則向FieldElement添加一個XML文本節點。
完成生成XML文檔后,我們就向頁面輸出XML文檔的內容,若頁面參數中指定了XSLT轉換文檔名稱則執行XSLT轉換,并輸出轉換結果。關于XSLT下節課程將詳細說明。
若未指明XSLT轉換信息,則輸出XML文檔根節點的外圍XML字符串。
每一個XML文檔對象都具有InnerXml屬性和OuterXml屬性,這兩個屬性都直接返回表示該XML文檔片斷的不帶縮進的XML字符串,但兩者有差別。InnerXml返回表示該節點所有子孫節點的XML字符串。而OuterXml返回表示該節點本身和所有子孫節點的XML字符串。例如對于XML文檔”<a><b />123</a>”,則它的根節點的InnerXml就是”<b />123”,而它的根節點的OuterXml就是”<a><b />123</a>”。注意這個字符串是不帶縮進的。而XML文檔直接保存到指定名稱的文件中是帶縮進的。
在IE瀏覽器中查看該頁面,可以看到IE只是顯示XML文檔中的純文本內容,并不像顯示其他XML文檔時的那種帶縮進的顯示。這是因為該ASPX的代碼中沒有設置ContentType為XML格式,而是使用默認的HTML格式,因此IE瀏覽器接受該頁面文檔代碼,并把它當作HTML進行解析和顯示,由于Table,Record等XML名稱都不是HTML標簽,因此IE瀏覽器忽略掉這些XML標記,只顯示出其中的純文本內容。但你查看該頁面的源代碼,可以看出該文檔的內容仍然是標準的XML格式,這里的源代碼沒有縮進處理。
小結在本課程中,我們簡單介紹了XML的基本語法,說明了處理XML文檔的流式處理模式和DOM處理模式。還使用C#演示了輸出XML文檔。
XML是一項不簡單的技術,而且在其上面派生了很多其他的技術,作為當代的軟件開發人員,尤其是WEB開發人員,應當熟練掌握和使用XML技術及其某些派生技術,熟悉XML技術有助于開發者長期保持相當水平的軟件開發能力,也是學習其他先進生產力的重要基礎。大家應當好好學習XML技術。
posted on 2008-05-15 15:41 袁永福 電子病歷,醫療信息化 閱讀(24556) 評論(51) 收藏 舉報


 浙公網安備 33010602011771號
浙公網安備 33010602011771號