
容器:字符串str,列表list,元組tuple,字典dict
了解 集合set
使用引號(單引號,雙引號,三引號)引起來的內容
代碼實現
#1.使用單引號
str1='hello'
#2.使用雙引號
str2="hello"
#3.使用三引號
str3='''hello'''
str4="""hello"""
print(type(str1),type(str2),type(str3),type(str4))
定義字符串 I'm 小明, 字符串本身包含引號
如果字符串本身包含單引號,定義的時候不能使用 單引號,
如果字符串本身包含雙引號,定義的時候不能使用 雙引號,
代碼
str5 = "I'm 小明"
print(str5) # I'm 小明
# 5. 轉義字符 \n \t \' \"
str6 = 'I\'m 小明'
print(str6) # I'm 小明
# 6. I\'m 小明 \\ --> \
str7 = 'I\\\'m 小明'
print(str7) # I\'m 小明
原生字符串
在字符串的前邊 加上 r"", 字符串中的 \ 就不會進行轉義
str8 = r'I\'m 小明'
print(str8) # I\'m 小明
str7 = r'I\\\'m 小明'
print(str7) # I\\\'m 小明
1, 下標(索引), 是數據在容器(字符串, 列表, 元組)中的位置, 編號
2, 一般來說,使用的是正數下標, 從 0 開始
3, 作用: 可以通過下標來獲取具體位置的數據. 使用的語法為
容器[下標]
4, Python 中是支持負數下標, -1 表示最后一個位置的數據
1, 使用切片操作, 可以一次性獲取容器中的多個數據(多個數據之間存在一定的規律,數據的下標是 等差數列(相鄰的兩個數字之間的差值是一樣的))
2, 語法 容器[start:end:step]
2.1 start 表示開始位置的下標
2.2 end 表示結束位置的下標,但是 end 所對應的下標位置的數據是不能取到的
2.3 step 步長,表示的意思就是相鄰兩個坐標的差值
start, start+step, start+step*2, ...,end(取不到)
# 需求1 : 打印字符串中 abc 字符
my_str = 'abcdefg'
print(my_str[0:3:1]) # abc
#end取不到,所以一般end+1
# 1.1 如果步長是 1, 可以省略不寫
print(my_str[0:3]) # abc
# 1.2 如果 start 開始位置的下標為 0, 可以不寫,但是冒號不能少
print(my_str[:3]) # abc
print(my_str[-3:-1:]) #ef
# 特殊情況, 步長為 -1, 反轉(逆序) 字符串
print(my_str[::-1]) # gfedcba
num = len(數據)
適用類型: 字符串、列表、元組、字典
str_data = "hello python"
print(len(str_data)) # 12: 字符中字符個數(包含空格)
list_data = ["python", "java"]
print(len(list_data)) # 2: 列表中元素個數
tuple_data = ("admin", 123456, 8888)
print(len(tuple_data)) # 3: 元組中元素個數
dict_data = {"name": "tom", "age": 18, "gender": "男"}
print(len(dict_data)) # 3: 字典中鍵值對的個數
字符串.find(sub_str) # 在字符串中 查找是否存在 sub_str 這樣的字符串
返回值(這行代碼執行的結果):
1, 如果存在sub_str, 返回 第一次出現 sub_str 位置的下標
2, 如果不存在sub_str, 返回 -1
data = "黑馬程序員"
index = data.find("黑馬")
print(f"index={index}") #index=0
index1 = data.find("程序員")
print(f"index={index1}") #index=2
index2 = data.find("白馬")
print(f"index2={index2}") #index=-1
新字符串=字符串.replace(old, new, count) # 將字符串中的 old 字符串 替換為 new 字符串 然后賦值到 新字符串
- old 原字符串,被替換的字符串
- new 新字符串,要替換為的字符串
- count 一般不寫,表示全部替換, 可以指定替換的次數
- 返回: 會返回一個替換后的完整的字符串
- 注意: 原字符串不會改變的
my_str = 'good good study'
# 需求, 將 good 變為 GOOD
my_str1 = my_str.replace('good', 'GOOD')
print('my_str :', my_str) # my_str : good good study
print('my_str1:', my_str1) # my_str1: GOOD GOOD study
# 將第一個 good 替換為 Good
my_str2 = my_str.replace('good', 'Good', 1)
print('my_str2:', my_str2) # my_str2: Good good study
# 將第二個 good 替換為 Good
# 先整體替換為 Good, 再將替換后的 第一個Good 替換為 good
my_str3 = my_str.replace('good', 'Good').replace('Good', 'good', 1)
print('my_str3:', my_str3) # my_str2: Good good study
字符串.split(分割符) 按照指定字符來分割字符串
注意:
1. 方法執行完成后返回的數據類型為列表(list)
2. 不傳入分割符時,默認以空格(空白字符\t,\n)進行拆分
data = "hello Python and\titcast and itheima"
print(data.split("and")) # ['hello Python ', ' itcast ', ' itheima']--->按字符
print(data.split()) # ['hello', 'Python', 'and', 'itcast', 'and', 'itheima']--->按空白字符
print(data.split(" ")) # ['hello', 'Python', 'and\titcast', 'and', 'itheima']-->空格拆分,\t就不拆了
字符串.join(容器) # 容器一般是列表 (可以是字符串,元組), 將字符串插入到列表相鄰的兩個數據之間,組成新的字符串
注意點: 列表中的數據 必須都是字符串才可以
list1 = ['hello', 'Python', 'and', 'itcast', 'and', 'itheima']
str1 = ' '.join(list1)
print(str1) # hello Python and itcast and itheima
str2 = ','.join(list1)
print(str2) # hello,Python,and,itcast,and,itheima
str3 = '_*_'.join(list1)
print(str3) # hello_*_Python_*_and_*_itcast_*_and_*_itheima
1, 列表,list, 使用 []
2, 列表可以存放任意多個數據
3, 列表中可以存放任意類型的數據
4, 列表中數據之間 使用 逗號隔開
# 方式1, 使用類實例化的方式
# 1.1 定義空列表 變量 = list()
list1 = list()
print(type(list1), list1) # <class 'list'> []
# 1.2 定義非空列表 , 也稱為 類型轉換 list(可迭代類型) 可迭代類型,能夠使用 for 循環 就是 可迭代類型(比
如 容器)
# 將容器中的 每個數據 都作為列表中一個數據進行保存
list2 = list('abcd')
print(list2) # ['a', 'b', 'c', 'd']
# 方式2, 直接使用 [] 進行定義(使用較多)
# 2.1 定義空列表
list3 = []
print(list3)
# 2.2 定義非空列表
list4 = [1, 3.14, 'hello', False]
print(list4)
列表 支持下標 和 切片
index() 這個方法的作用和 字符串中的 find() 的作用是一樣
列表中是沒有 find() 方法的, 只有 index() 方法
字符串中 同時存在 find() 和 index() 方法
兩者區別:
1, 找到 返回下標
2, 沒有找到, 直接報錯
列表.count(數據) # 統計 指定數據在列表中出現的次數 返回值int類型
list1 = ['hello', 2, 3, 2, 3, 4]
# 查找 2 出現的下標
num = list1.index(2)
print(num)
# 統計數據 2 出現的次數
num1 = list1.count(2)
print(num1)
# 統計數據 20 出現的次數
num2 = list1.count(20)
print(num2) # 0
列表.append(數據) # 向列表的尾部添加數據
# 返回: None, 所以不用使用 變量 = 列表.append()
直接在原列表中添加數據, 不會生成新的列表,如果想要查看添加后的數據, 直接 print() 打印原列表
list1 = ['hello', 2, 3, 2, 3, 4]
print(list1.count(2))
list1.append(2) # 2
print(list1.count(2)) # 3
print(list1) # ['hello', 2, 3, 2, 3, 4, 2]
列表.pop(index) # 根據下標刪除列表中的數據
- index 下標可以不寫, 默認刪除在最后一個
- 返回, 刪除的數據
list1 = ['hello', 2, 3, 2, 3, 4]
print(f"被刪除的數據:{list1.pop()}") # 4
print(list1) # ['hello', 2, 3, 2, 3]
print(f"被刪除的數據:{list1.pop(0)}") # hello
print(list1) # [2, 3, 2, 3]
想要修改列表中的數據, 直接是所有下標即可
列表[下標] = 新數據 #指定的下標不存在,報錯(下標越界)
my_list = [1, 2]
my_list[0] = 10
print(my_list) # [10, 2]
my_list[-1] = 200
print(my_list) # [10, 200]
字符串 反轉 字符串[::-1]
列表 反轉
1. 列表[::-1] 得到一個新的列表, 原列表不會改動
2. 列表.reverse() 直接修改原列表的數據
my_list = ['a', 'b', 'c', 'd', 'e']
# 1. 切片 原列表不變,輸出新列表
my_list1 = my_list[::-1]
print('my_list :', my_list)
print('my_list1:', my_list1) # my_list1: ['e', 'd', 'c', 'b', 'a']
# 2. reverse 直接修改原列表的數據
my_list.reverse()
print('my_list :', my_list) # my_list : ['e', 'd', 'c', 'b', 'a']
# 前提: 列表中的數據要一樣
列表.sort() # 升序, 從小到大, 直接在原列表中進行排序
列表.sort(reverse=True) # 降序, 從大到下, 直接在原列表中進行排序
my_list = [1, 4, 7, 2, 5, 8, 3, 6, 9]
# 排序 升序------原列表中進行排序
my_list.sort()
print(my_list)
# 降序
my_list.sort(reverse=True)
print(my_list)
列表的嵌套 就是指 列表中的數據還是列表
student_list = [["張三", "18", "功能測試"], ["李四", "20", "自動化測試"], ["王五", "21", "自動化測試"]]
# 張三
print(student_list[0][0])
# 李四
print(student_list[1][0])
# 張三 的信息添加一個 性別 男 ---> 向張三所在的列表 添加數據
student_list[0].append('男')
print(student_list)
# 刪除 性別
student_list[0].pop()
print(student_list)
# 打印 所有人員的年齡
for info in student_list:
print(info[1])
1, 元組 tuple, 使用的 ()
2, 元組和列表非常相似, 都可以存儲多個數據, 都可以存儲任意類型的數據
3, 區別就是 元組中的數據不能修改,列表中可以修改
4, 因為元組中的數據不能修改,所以只能 查詢方法, 如 index, count ,支持下標和切片
5, 元組, 主要用于傳參和返回值
# 1. 類實例化方式
# 1.1 定義空元組(不用)--->不能修改,增加:沒有意義
tuple1 = tuple()
print(type(tuple1), tuple1) # <class 'tuple'> ()
# 1.2 -類型轉換-, 將列表(其他可迭代類型)轉換為元組
tuple2 = tuple([1, 2, 3])
print(tuple2)
# 2. 直接使用 () 定義
# 2.1 定義空元組
tuple3 = ()
# 2.2 非空元組
tuple4 = (1, 2, 'hello', 3.14, True)
print(tuple4)
print(tuple4[2]) # hello
# 2.3 定義只有一個數據的元組, 數據后必須有一個逗號
tuple5 = (10,)
print(tuple5)
交換兩個變量的值【面試題】
a = 10
b = 20
c = b, a # 組包
print(c) # (20, 10) -->tuple
a, b = c # 拆包 a=20 b=10 --> int
print(a, b)
#結論??
a, b = b, a
print(a, b)
x, y, z = 'abc'
print(y) # b
1, 字典 dict, 使用 {} 表示
2, 字典是由鍵(key)值(value)對組成的, key: value
3, 一個鍵值對是一組數據, 多個鍵值對之間使用 逗號隔開
4, 在一個字典中, 字典的鍵 是不能重復的
5, 字典中的鍵 主要使用 字符串類型, 可以是數字
6, 字典中沒有下標
# 1, 類實例化的方式
my_dict1 = dict()
print(type(my_dict1), my_dict1) # <class 'dict'> {}
# 2, 直接使用 {} 定義
# 2.1 定義空字典
my_dict2 = {}
print(my_dict2)
# 2.2 定義非空字典, 姓名, 年齡, 身高, 性別
my_dict = {"name": "小明", "age": 18, "height": 1.78, "isMen": True}
print(my_dict)
字典['鍵'] = 值
# 1, 鍵 存在, 修改
# 2, 鍵 不存在, 添加
data2 = {'name': 'python', 'age': 19}
print(data2)
data2["name"] = "java" #修改name鍵的值為java
print(data2)
data2["phone"] = "13856236458" #增加phone鍵和值
print(data2)

字典的刪除是根據字典的鍵 -->刪除鍵值對
字典.pop('鍵')
data2 = {'name': 'python', 'age': 19}
data2["phone"] = "13856236458" #增加phone鍵和值
data2.pop("phone") #刪除鍵值對phone
print(data2)
根據字典的key鍵,來獲取對應的value值。
方法一:
字典['鍵'] #鍵不存在,會報錯
方法二:
字典.get(鍵) #鍵不存在,會返回None
data2 = {'name': 'python', 'age': 19}
data2["phone"] = "13856236458" #增加phone鍵和值
print(data2.get("phone"))
print(data2["phone"])
data2.pop("phone") #刪除鍵值對phone
print(data2.get("phone")) # None
print(data2["phone"]) #報錯,keyError:'phone'

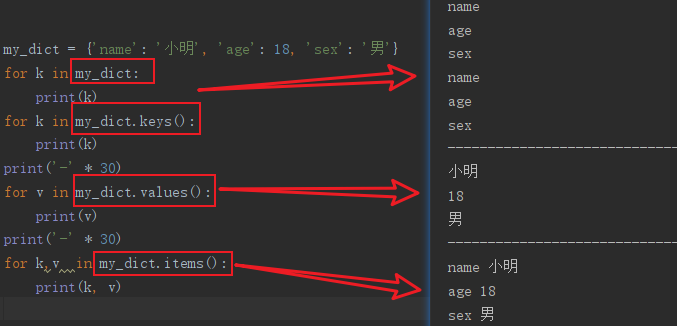
字典存在 鍵(key), 值(value) , 遍歷分為三種情況
遍歷字典的鍵
# 方式一
for 變量 in 字典:
print(變量)
# 方式二
for 變量 in 字典.keys(): # 字典.keys() 可以獲取字典所有的鍵
print(變量)
遍歷字典的值
for 變量 in 字典.values(): # 字典.values() 可以獲取字典中是所有的值
print(變量)
遍歷字典的鍵和值
# 變量1 就是 鍵, 變量2 就是值
for 變量1, 變量2 in 字典.items(): # 字典.items() 獲取的是字典的鍵值對
print(變量1, 變量2)
代碼實現:
my_dict = {'name': '小明', 'age': 18, 'sex': '男'}
for k in my_dict:
print(k)
for k in my_dict.keys():
print(k)
print('-' * 30)
for v in my_dict.values():
print(v)
print('-' * 30)
for k,v in my_dict.items():
print(k, v)


 浙公網安備 33010602011771號
浙公網安備 33010602011771號