
數據分析之漏斗模型
什么是漏斗?
提起漏斗,讓我首先想到的是它的 形狀:圓錐形的、頂部寬底部窄;其次是它的 功能:過濾雜質,如生了蟲的白面、炸過豆腐的油等。
形狀
如下圖形狀才能夠有效的行使它的功能職責 — 過濾。

功能
過濾雜質
生了蟲的白面
小時候的農村,夏天雨水較多,家里比較潮濕,缸里的面經常會有蟲子光顧。
那個時候物質匱乏,不舍的扔掉,會把蟲子以及結塊的面粉經過篩子(篩子及漏斗)給過濾掉,然后繼續吃過篩的面粉。
炸過豆腐的油
過年的時候,會炸幾片豆腐,俗稱過油豆腐。然后炸過豆腐的油,里邊會有一些豆腐渣子殘留,為了重復利用油,會拿油漏把豆腐渣子給過濾掉,然后漏下的油在下次炒菜的時候繼續用。
什么是漏斗模型?
漏斗我們知道了,那什么是模型呢?
模型一般是指對事物、規律等進行抽象后的一種形式化表達方式。
大部分的模型都是由三部分組成的,即目標、變量和關系。
漏斗模型就是對漏斗的形狀和功能進行抽象后的一種形式化表達方式,通過目標、變量和關系對數據進行分析。
目標
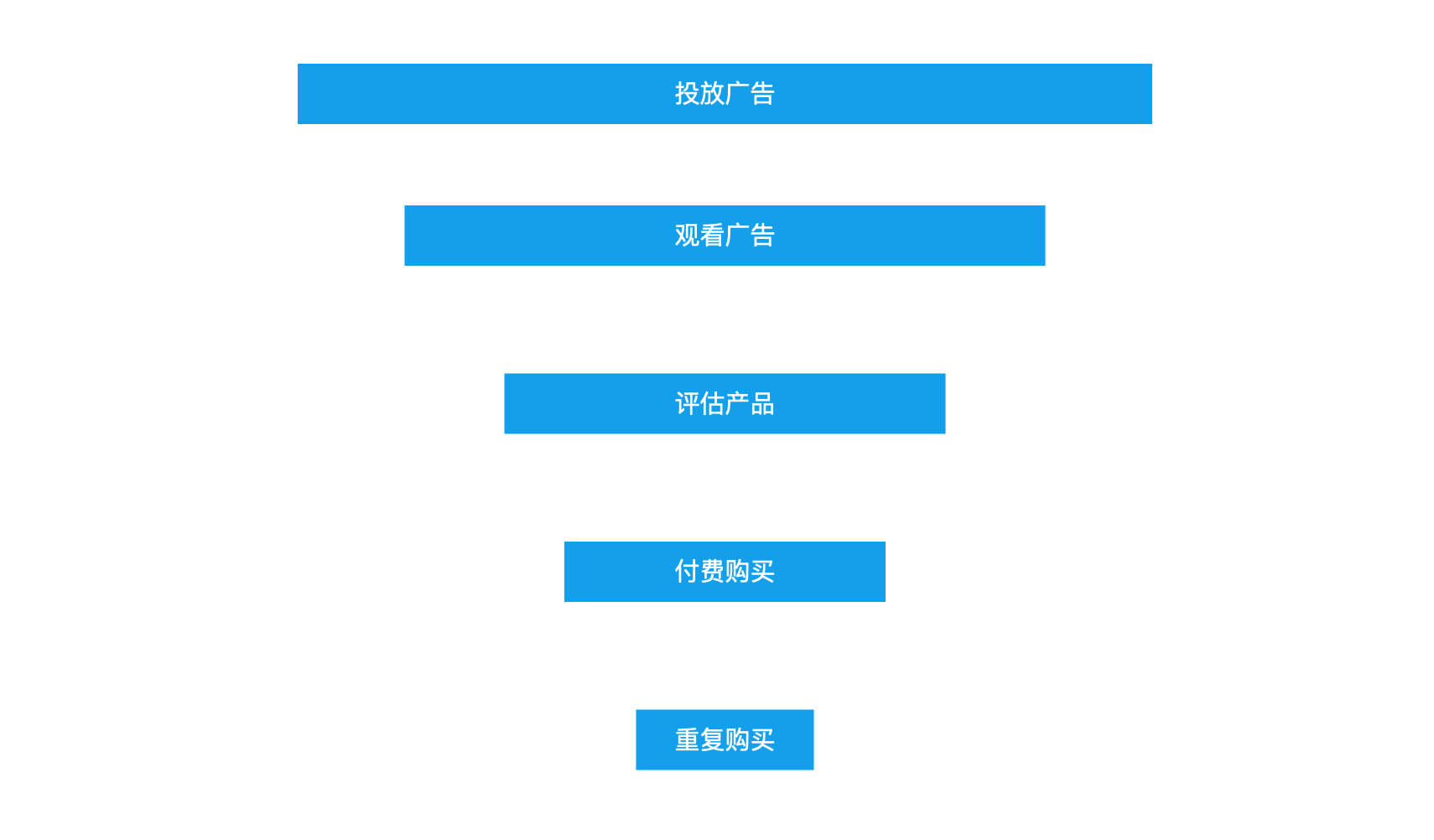
在使用漏斗模型進行分析之前,首先需要明確目標,知道需要做什么。比如傳統漏斗模型,最早起源于傳統行業的商業營銷活動中,目標就是商業變現。
- 投放廣告,提高用戶對品牌的認知,占領用戶的心智;
- 觀看廣告,提高用戶對產品的興趣;
- 評估產品,用戶會根據對品牌認證和產品興趣來決定是否購買;
- 付費購買,用戶會對評估完后感興趣的產品進行購買,達成交易;
- 重復購買,部分用戶會持續重復購買,也可能推薦給親戚朋友。
以上是傳統的金典的漏斗模型,是一種收縮型思維,每一步之間都可能會因為各種不確定變量而被過濾掉。
變量
在明確了漏斗模型的目標以后,才能進一步確定影響目標的各關鍵變量。
變量又分為自變量、因變量和中介變量。
因變量 在組織行為學中就是所要測量的行為反應,而 自變量 則是影響因變量的變量。
如上邊傳統漏斗模型,因變量是廣告觀看率、商品付費率、重復購買率等,那么廣告的投放渠道(如電視、報紙雜志、地鐵、門戶網站等)、觀看廣告的用戶年齡層次、用戶所在的區域、用戶的興趣愛好、用戶的經濟條件等就是影響因變量的自變量。
中介變量 又稱為干擾變量,它會削弱自變量對因變量的影響。中介變量的存在會使自變量與因變量之間的關系更加復雜。
中介變量也就是我們需要介入的變量,需要我們去無限的進行解構,來影響自變量。比如從 A 到 R (獲客 - 盈利)的轉換問題,我們可以把 A 拆分為 A1、A2、A3,再看哪一步對自變量的影響比較大,假設是 A2,那么再把 A2拆開,再看其中的主要問題。
如上邊傳統的漏斗模型,假設我們的品牌為高端奢侈品,那么我們需要對投放渠道、用戶年齡層次、投放區域等進行拆分。然后發現我們的投放區域覆蓋面太多,成本比較高。然后我們對投放地區進行拆分,發現偏遠地區投放占比比較高,那么這個時候,我們是否找到了問題呢?我們可以收縮投放區域,有針對性的在北上廣深等這樣的大城市集中投放會不會效果更好一些呢?
最理想的狀態是,我們能夠解構到唯一變量的顆粒度。然后我們就能夠精準定位并且解決這個問題,從而帶來增長。
如果我們用的漏斗是一個很粗略的漏斗,是無法解決問題的。需要一步步解構、定位問題,然后去解決,這樣才能帶來有效的增長。
關系
確定了目標,確定了影響目標的各種變量之后,還需要進一步研究各變量之間的關系。在確定變量之間的關系時,對何者為因、何者為果的判斷,應持謹慎態度。不能因為兩個變量之間存在著統計上的關系,就簡單地認為他們之間存在著因果關系。對變量間因果關系的判斷不能輕率。
用戶增長漏斗轉化
很多時候我們談增長,更多的是在談獲客,而沒有考慮如何提升現有用戶的轉化率、激活率。我們需要考慮如何才能讓用戶變成忠誠用戶,只有忠誠用戶才不會流失,才能帶來更多的收益。

通過漏斗分析可以從前到后還原用戶轉化的路徑,分析每一個轉化節點的效率。
- 從開始到結尾,整體的轉化率是多少?
- 每一步的轉率是多少?
- 哪一步流失最多,原因是什么?流失的用戶符合哪些特征?
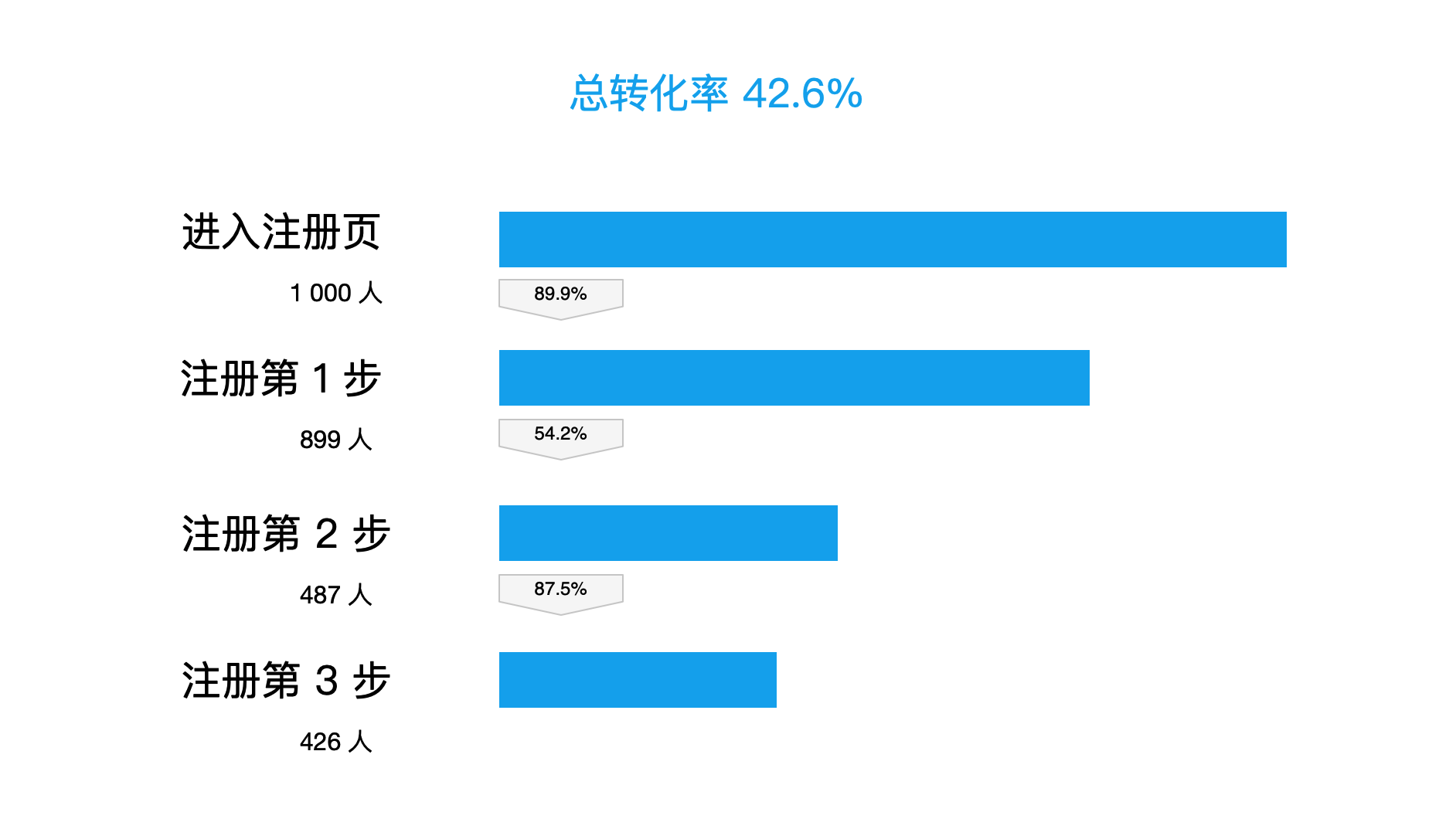
上圖中注冊流程分為 3 個步驟,總體轉化率為 42.6%,也就是說有 1000 個用戶來到注冊頁面,其中 426 個成功完成了注冊。
但是我們不難發現注冊第 2 步的轉化率是 54.2%,明顯低于注冊第 1 步的 89.9% 和 第三步的 87.5%,可以推測注冊第 2 步流程存在問題。
顯而易見注冊第 2 步的提升空間是最大的,投入回報比肯定不低;如果要提高注冊轉化率,我們應該優先解決注冊第 2 步。
請關注公眾號:白胡子海盜


 浙公網安備 33010602011771號
浙公網安備 33010602011771號