

MySQL查詢性能優(yōu)化
一、MySQL查詢執(zhí)行基礎(chǔ)
1. MySQL查詢執(zhí)行流程原理
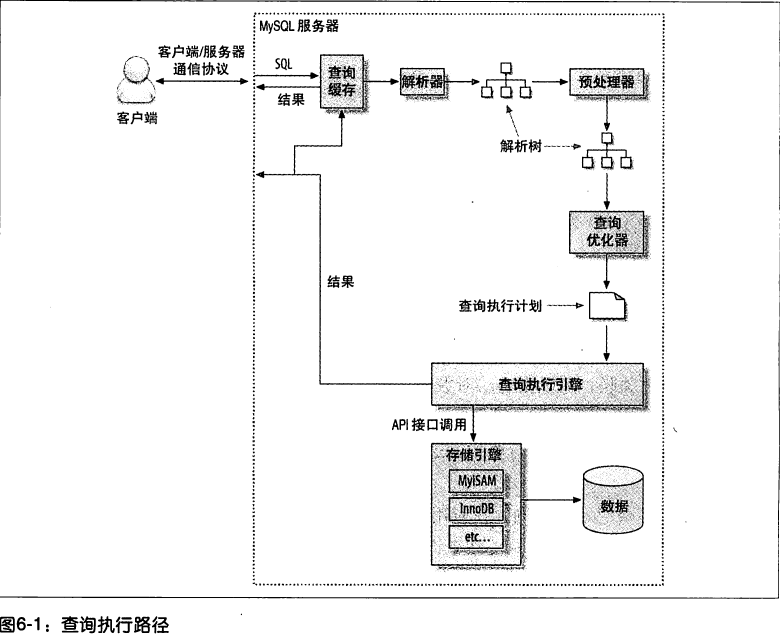
<1> 客戶端發(fā)送一條查詢給服務(wù)器。
<2> 服務(wù)器先檢查查詢緩存,如果命中了緩存,則立刻返回存儲在緩存中的結(jié)果。否則進入下一階段。
<3> 服務(wù)器進行SQL解析、預(yù)處理,再由優(yōu)化器生成對應(yīng)的執(zhí)行計劃。
<4> MySQL根據(jù)優(yōu)化器生成的執(zhí)行計劃,調(diào)用存儲引擎的API來執(zhí)行查詢。
<5> MySQL將結(jié)果返回給客戶端,同時保存一份到查詢緩存中。
2. MySQL客戶端/服務(wù)器通信協(xié)議
<1> 協(xié)議類型:半雙工。
<2> Mysql通常需要等所有的數(shù)據(jù)都已經(jīng)發(fā)送給客戶端才能釋放這條查詢所占用的資源。
<3> 在PHP函數(shù)中,mysql_query()會將整個查詢的結(jié)果集緩存到內(nèi)存中,而mysql_unbuffered_query()則不會緩存結(jié)果,直接從mysql服務(wù)器獲取結(jié)果。當(dāng)結(jié)果集很大時,使用后者能減少內(nèi)存的消耗,但服務(wù)器的資源會被這個查詢占用比較長的時間。
3. 查詢狀態(tài)
可以使用命令來查詢mysql當(dāng)前查詢的狀態(tài):show full processlist。返回結(jié)果中的“State”鍵對應(yīng)的值就表示查詢的狀態(tài),主要有以下幾種:
<1> Sleep:線程正在等待客戶端發(fā)送新的請求。
<2> Query:線程正在執(zhí)行查詢或正在將結(jié)果發(fā)送給客戶端。
<3> Locked:在MySQL服務(wù)器層,該線程正在等待表鎖。(在沒行鎖的引擎出現(xiàn))
<4> Analyzing and statistics:線程正在收集存儲引擎的統(tǒng)計信息,并生成查詢的執(zhí)行計劃。
<5> Copying to tmp [on disk]:線程正在執(zhí)行查詢,并且將其結(jié)果集都復(fù)制到一個臨時表中,這種狀態(tài)要么是在做group by操作,要么是文件排序操作,或者是union操作。
<6> Sorting result:線程正在對結(jié)果集進行排序。
<7> Sending data:表示多種請況,線程可能在多個狀態(tài)之間傳送數(shù)據(jù),或者在生成結(jié)果集,或者在向客戶端返回數(shù)據(jù)。
4. 查詢緩存
<1> 這個檢查是通過一個對大小寫敏感的哈希查找實現(xiàn)的。
<2> 命中查詢緩存之后,檢查用戶權(quán)限,直接從緩存中返回數(shù)據(jù)給客戶端,不需要解析查詢。
5. 查詢優(yōu)化處理
語法解析器和預(yù)處理:
<1> 通過關(guān)鍵字對SQL語句進行解析,生成一棵“解析樹”。
<2> 解析器使用MySQL語法規(guī)則驗證和解析查詢(關(guān)鍵字是否正確...)。
<3> 預(yù)處理器根據(jù)一些MySQL規(guī)則進一步檢查解析樹是否合法(表、列是否存在...)。
<4> 預(yù)處理器驗證權(quán)限。
查詢優(yōu)化器:
MySQL使用基于成本的優(yōu)化器。它將嘗試預(yù)測一個查詢使用各種執(zhí)行計劃時的成本,并選擇其中成本最小的一個。其中,成本是根據(jù)存儲引擎提供的數(shù)據(jù)和引擎的統(tǒng)計信息計算得來的,可以通過查詢當(dāng)前會話的Last_query_cost的值來得知MySQL計算的當(dāng)前查詢的成本。優(yōu)化器在評估成本的時候并不考慮任何層面的緩存,它假設(shè)讀取任何數(shù)據(jù)都需要一次磁盤I/O。有很多原因會導(dǎo)致MySQL優(yōu)化器選擇并不是最優(yōu)的執(zhí)行計劃。MySQL能處理的優(yōu)化類型:重新定義關(guān)聯(lián)表的順序、將外連接轉(zhuǎn)化成內(nèi)連接、使用等價變換規(guī)則、優(yōu)化count()、min()和max()、預(yù)估并轉(zhuǎn)化為常數(shù)表達(dá)式、覆蓋索引掃描、子查詢優(yōu)化、提前終止查詢、等值傳播、列表in()的比較等等。
數(shù)據(jù)和索引的統(tǒng)計信息:
統(tǒng)計信息由存儲引擎實現(xiàn)。Mysql查詢優(yōu)化器在生成查詢的執(zhí)行計劃時需要向存儲引擎獲取相應(yīng)的統(tǒng)計信息。
MySQL如何執(zhí)行關(guān)聯(lián)查詢:
<1> MySQL認(rèn)為任何一個查詢都是一次關(guān)聯(lián),對任何關(guān)聯(lián)都執(zhí)行嵌套循環(huán)關(guān)聯(lián)操作,從一個表開始一直嵌套循環(huán)、回溯完成所有表關(guān)聯(lián)。
<2> Union查詢:先將一系列的單個查詢結(jié)果放到一個臨時表中,然后再重新讀出臨時表數(shù)據(jù)來完成union查詢。(臨時表沒有任何索引)
<3> MySQL在執(zhí)行子查詢的時候也是先將子查詢的結(jié)果放到一個臨時表中。
<4> 遇到右連接的時候mysql會將其改寫成等價的左連接。
<5> 將所有的查詢類型都轉(zhuǎn)換成類似的執(zhí)行計劃。。
<6> 并不是所有的查詢都可以通過嵌套循環(huán)和回溯的方式完成,例如全外連接,所以Mysql并不支持全外連接。
執(zhí)行計劃:
對某個查詢執(zhí)行explain extended后再執(zhí)行show warnings就可以看到重構(gòu)出的查詢。因為mysql執(zhí)行查詢采用的總是嵌套循環(huán)關(guān)聯(lián)操作,所以mysql的執(zhí)行計劃總是一棵左側(cè)深度優(yōu)先的樹。
關(guān)聯(lián)查詢優(yōu)化器:
MySQL優(yōu)化器最重要的一部分就是關(guān)聯(lián)查詢優(yōu)化。關(guān)聯(lián)優(yōu)化器通過評估多個表的不同關(guān)聯(lián)順序的成本來選擇一個代價最小的關(guān)聯(lián)順序,如果可能,優(yōu)化器會遍歷每一個表然后逐個做嵌套循環(huán)計算每一棵可能的執(zhí)行計劃樹的成本,最后返回最優(yōu)的一個執(zhí)行計劃。但是當(dāng)關(guān)聯(lián)表的數(shù)量比較多的時候,這樣做的成本太高,當(dāng)需要關(guān)聯(lián)的表數(shù)量超過optimizer_search_depth參數(shù)值的時候,優(yōu)化器會選擇使用“貪婪”搜索的方式查找“最優(yōu)”關(guān)聯(lián)順序。有時候優(yōu)化器給出的不是最優(yōu)關(guān)聯(lián)順序,這時如果不希望關(guān)聯(lián)優(yōu)化器改變表的關(guān)聯(lián)順序的話,可以使用straight_join來強制表的連接順序。
排序優(yōu)化:
<1> 排序是一個成本很高的操作,應(yīng)盡可能避免排序操作。
<2> Mysql的兩種排序算法:
兩次傳輸排序(舊版本使用):讀取行指針和需要排序的字段,對其進行排序,然后再根據(jù)排序結(jié)果讀取所需要的數(shù)據(jù)行。
單次傳輸排序(新版本使用):先讀取查詢所需要的所有列,然后在根據(jù)給定列的值進行排序,最后直接返回結(jié)果。
兩個算法各有優(yōu)缺點,當(dāng)查詢需要所有列的總長度不超過參數(shù)max_length_for_sort的值時,mysql使用單次傳輸排序。
<3> 如果關(guān)聯(lián)查詢需要排序,MySQL會分兩種情況來處理文件排序:
如果order by子句中的所有列都來自關(guān)聯(lián)的第一個表,那么MySQL在關(guān)聯(lián)處理第一個表的時候就進行文件排序(Explain結(jié)果Extra字段“Using filesort”),否則,MySQL都會先將關(guān)聯(lián)的結(jié)果存放到一個臨時表中,然后在所有的關(guān)聯(lián)都結(jié)束后再進行文件排序(Explain結(jié)果Extra字段“Using temporary;Using filesort”)。
二、MySQL查詢優(yōu)化器的局限性
1. 關(guān)聯(lián)子查詢
MySQL的子查詢實現(xiàn)非常糟糕,最糟糕的一類查詢是where條件中包含IN()的子查詢語句。MySQL會將相關(guān)的外層表壓到子查詢中進行關(guān)聯(lián)查詢。
包含In的子查詢優(yōu)化:
<1> 使用group_concat()在in()中構(gòu)造一個由逗號分隔的列表。
<2> 改寫成關(guān)聯(lián)查詢或使用exists代替。
2. Union的限制
有時,MySQL無法將限制條件從外層“下推”到內(nèi)層,使得原本能夠限制部分返回結(jié)果的條件無法應(yīng)用到內(nèi)層查詢的優(yōu)化上。在union的各個子句中分別使用order by和limit,可以減少臨時表中的數(shù)據(jù),但想獲取正確的順序還需加上一個全局的order by和limit操作。
3. 索引合并優(yōu)化
在5.0和更新的版本中,當(dāng)where子句中包含多個復(fù)雜條件的時候,mysql能夠訪問單個表的多個索引以合并和交叉過濾的方式來定位需要查找的行。
4. 等值傳遞
Mysql優(yōu)化器會將In()列表復(fù)制應(yīng)用到關(guān)聯(lián)的各個表中。
5. 并行執(zhí)行
Mysql無法利用多核特性來并行執(zhí)行查詢。
6. 哈希關(guān)聯(lián)
可以通過創(chuàng)建一個哈希索引來曲線實現(xiàn)哈希關(guān)聯(lián)。
7. 松散索引掃描
Mysql并不支持松散索引掃描。
8. 最大值和最小值優(yōu)化
在需要取最大/最小值的字段上創(chuàng)建索引,然后在查詢語句中加入“use index”語句強制使用索引,當(dāng)MySQL讀到第一條滿足條件的記錄的時候就是我們需要找的最大/最小值了。
優(yōu)化示例:
優(yōu)化前:
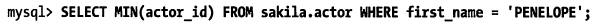
優(yōu)化后:

9. 在同一張表上查詢和更新
MySQL不允許對同一張表同時進行查詢和更新。可以通過使用生成表的形式來繞過這個限制,因為MySQL只會把這個表當(dāng)成臨時表來處理。
優(yōu)化示例:
優(yōu)化前:

優(yōu)化后:

10. 查詢優(yōu)化器的提示
可以在查詢語句中加入一些提示來控制查詢的執(zhí)行計劃。
三、優(yōu)化特定類型的查詢
1. 優(yōu)化count()查詢
如果在count()的括號中指定了列或者列的表達(dá)式,那么統(tǒng)計的是這個表達(dá)式有值的結(jié)果數(shù)(不包含NULL)。統(tǒng)計行數(shù)使用count(*)意義更清晰,性能也會更好。
MyISAM執(zhí)行沒有任何where條件的count(*)非常快,因為可以利用存儲引擎的特性直接獲得這個值。如果mysql知道某個列col不可能為null值會將count(col)表達(dá)式優(yōu)化為count(*)。可以利用MyISAM的這個特性來優(yōu)化加速一些特定條件的count()查詢。優(yōu)化示例:
優(yōu)化前(需要掃描很多的數(shù)據(jù)行):

優(yōu)化后(將需要掃描的數(shù)據(jù)行減少到5以內(nèi)):
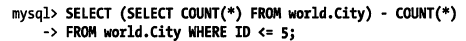
(在查詢優(yōu)化階段會將其中的子查詢直接當(dāng)做一個常數(shù)來處理)
在對精確值要求不高的情況下,可以通過一些途徑取得近似值來達(dá)到優(yōu)化查詢的目的:
<1> 使用explain出來的優(yōu)化器估算的行數(shù)來替代count(*),不需要真正去執(zhí)行查詢。
<2> 去除一些對總數(shù)影響很小的where條件。
<3> 刪除distinct約束避免文件排序。
<4> 更復(fù)雜的優(yōu)化:使用匯總表、使用緩存系統(tǒng)等。
2. 優(yōu)化關(guān)聯(lián)查詢
<1> 確保on或using子句中的列上有索引,只需要在關(guān)聯(lián)順序中的第二個表的相應(yīng)列上創(chuàng)建索引。
<2> 確保任何的group by和order by中的表達(dá)式只涉及到一個表中的列,這樣MySQL才有可能使用索引來優(yōu)化這個過程。
<3> 當(dāng)升級MySQL的時候需要注意,關(guān)聯(lián)語法、運算符優(yōu)先級等其他可能會發(fā)生變化的地方。
3. 優(yōu)化子查詢
盡量使用關(guān)聯(lián)查詢替代(并不絕對,如果使用的是MySQL5.6或更新版本或MariaDB的話)。
4. 優(yōu)化group by和distinct
優(yōu)化這兩種查詢最有效的方法是使用索引來優(yōu)化。
當(dāng)無法使用索引的時候,group by使用臨時表或文件排序來做分組,可以通過提示SQL_BIG_RESULT和SQL_SMALL_RESULT來讓優(yōu)化器按照我們希望的方式運行。如果需要對關(guān)聯(lián)查詢做分組,通常采用查找表的標(biāo)識列分組的效率會比其他列更高。但如果查詢語句無法寫成在select中直接使用非分組列的形式或當(dāng)前sql_mode禁止這樣做的話(ONLY_FULL_GROUP_BY的sql_mode會返回錯誤),可以使用min(),max()函數(shù)來繞過這種限制。
如果沒有通過order by子句顯式指定排序列,當(dāng)查詢使用group by子句的時候結(jié)果集會自動按照分組的字段進行排序,可以在其后面直接使用asc或desc關(guān)鍵字指定排序方向。若不需要進行排序,可以加上order by null讓MySQL不在進行文件排序,提高查詢性能。
5. 優(yōu)化group by width rollup
使用超級聚合的查詢不夠優(yōu)化,可以在from子句中嵌套使用子查詢來替代超級聚合,或者是通過一個臨時表存放中間數(shù)據(jù),然后和臨時表執(zhí)行union操作來得到最終結(jié)果。但最好的辦法還是盡可能將width rollup功能轉(zhuǎn)移到應(yīng)用程序中進行處理。
6. 優(yōu)化limit分頁
在使用limit子句的查詢中,如果沒有對應(yīng)字段的索引,當(dāng)偏移量很大的時候,mysql需要查詢大量數(shù)據(jù)行但是只返回一小部分?jǐn)?shù)據(jù),對這種情況進行優(yōu)化的方法有:
<1> 使用索引覆蓋掃描,然后再做一次關(guān)聯(lián)操作返回所需的列。
<2> 想辦法將limit查詢轉(zhuǎn)化為已知位置的查詢。
7. 優(yōu)化union查詢
Mysql總是通過創(chuàng)建并填充臨時表的方式來執(zhí)行union查詢,經(jīng)常需要手工將where、limit、order by等子句“下推”到union的各個子查詢中進行優(yōu)化。除非確實需要服務(wù)器消除重復(fù)的行,否則一定要使用union all,不然mysql會給臨時表加上distinct選項,這會導(dǎo)致對整個臨時表的數(shù)據(jù)做唯一性檢查。
8.優(yōu)化select *查詢
當(dāng)使用select * from tbl_name語句進行查詢的時候,mysql服務(wù)器會先從數(shù)據(jù)表中解析出全部字段名稱,替換掉查詢語句中的"*",然后緩存解析替換之后的查詢語句,最后再將解析替換之后的查詢語句進行執(zhí)行,并且以后遇到select * from tbl_name語句都會直接使用緩存中的包含數(shù)據(jù)表全部字段的語句進行查詢。所以使用"*"而不指定字段名稱有以下弊端:
(1)會增加SQL的解析成本;
(2)如果不是全部字段都有用的話,查詢非必需字段還會造成資源浪費甚至影響服務(wù)器性能;
(3)無法利用索引覆蓋查詢,不利于查詢的性能優(yōu)化;
(4)若是數(shù)據(jù)表結(jié)構(gòu)修改之后還使用緩存中的語句進行查詢,還會發(fā)生字段映射錯誤問題。
9. 使用用戶自定義變量優(yōu)化查詢
使用用戶自定義變量的查詢無法使用查詢緩存,生命周期只在一個連接中有效,是一個動態(tài)類型,賦值符號:=優(yōu)先級很低,賦值表達(dá)式應(yīng)該使用括號。
優(yōu)化排名語句:

(演過最多電影的前10名演員,使用子查詢生成一個中間的臨時表來解決自定義變量賦值時間和我們預(yù)料不同的問題)
避免重復(fù)查詢剛剛更新的數(shù)據(jù):
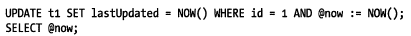
統(tǒng)計更新和插入的數(shù)量:
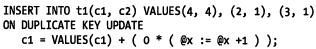
編寫偷懶的union:
第一個子查詢作為分支條件先執(zhí)行,如果找到了匹配的行,則跳過第二個分支。

(將“熱”數(shù)據(jù)和“冷”數(shù)據(jù)分別放在兩個不同的表,使用union去查詢)
有時優(yōu)化器會把變量當(dāng)作一個編譯時常量對待而不是對其進行賦值,將函數(shù)放在類似least()這樣的函數(shù)中通常可以避免這樣的問題。

 浙公網(wǎng)安備 33010602011771號
浙公網(wǎng)安備 33010602011771號