
Qwen多模態(tài)系列模型筆記—Qwen2-VL
方法
Qwen2-VL系列包含三種體量的模型,分別是Qwen2-VL-2B, Qwen2-VL-7B, Qwen2-VL-72B。表1列舉出這些模型的超參數(shù)和重要信息。值得注意的是,這三個模型視覺編碼器始終都采用675M參數(shù)量的ViT,沒有因模型而改變。此舉是為了確保ViT部分的計算量保持常量,沒有因?yàn)椴捎酶篌w量的LLM,ViT也采用更多參數(shù)量。
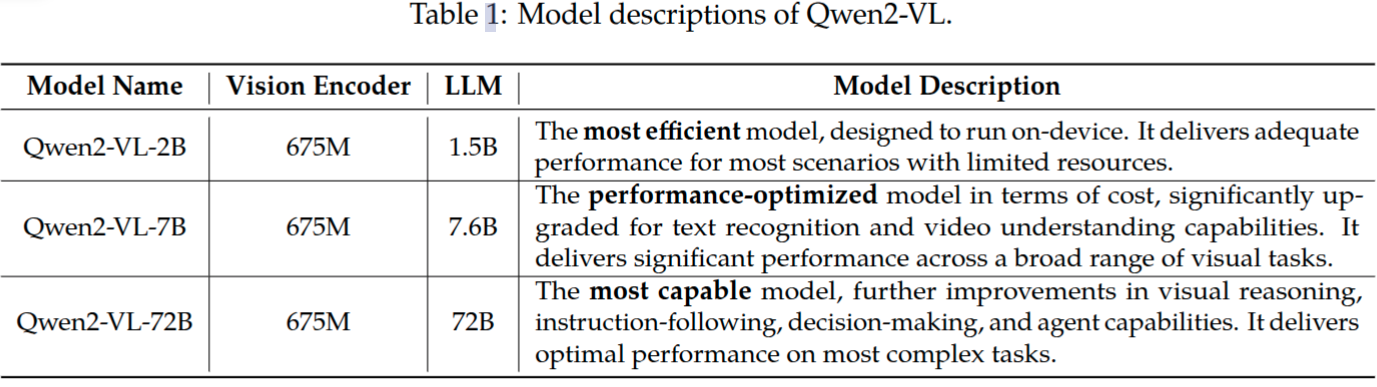
模型結(jié)構(gòu)
圖2展示了Qwen2-VL模型的完整的結(jié)構(gòu)圖。由視覺編碼器、大語言模型這兩部分構(gòu)成。
Qwen2-VL模型沒有像之前大多數(shù)的VL模型,采用視覺-語言適配器,而是丟棄掉這個模塊。為什么Qwen2-VL采用這種做法呢?
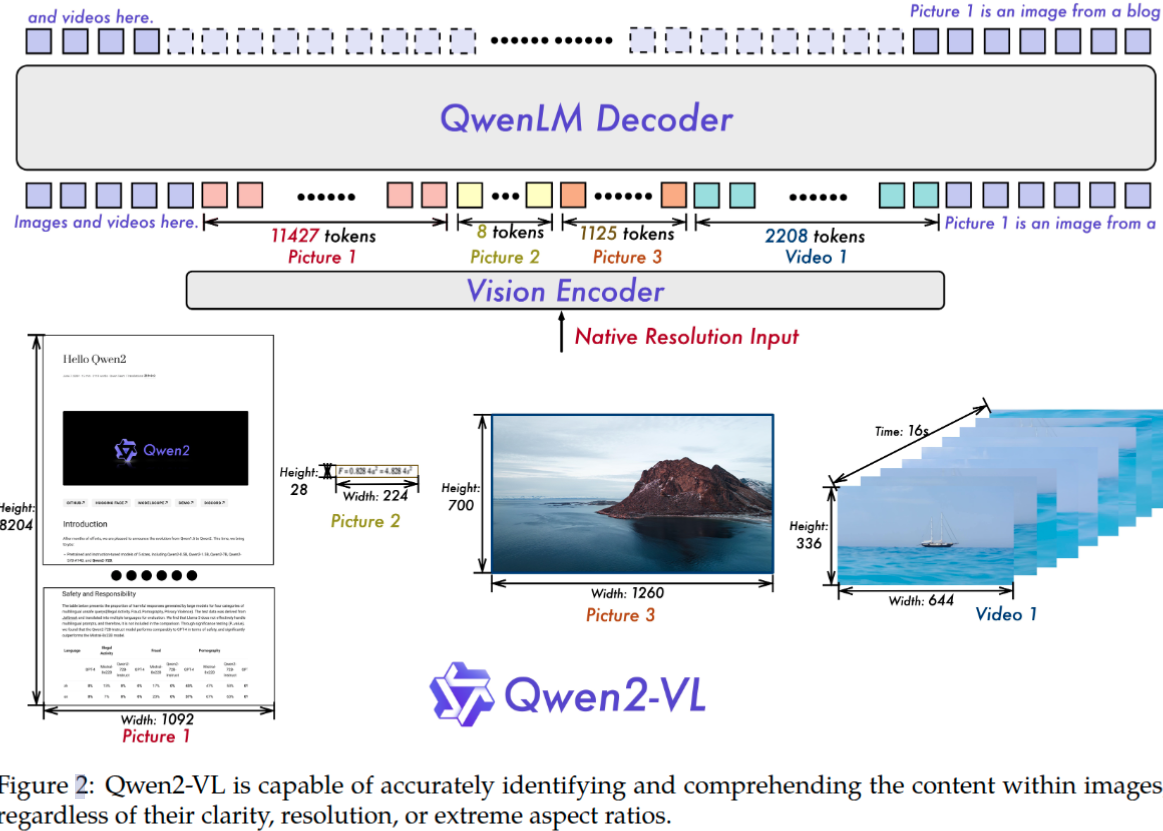
除了采用更強(qiáng)大的Qwen2系列語言模型,論文還通過如下幾個方面升級來進(jìn)一步增強(qiáng)對圖像和視頻的感知和理解能力。
動態(tài)分辨率 Qwen2-VL模型的一項(xiàng)關(guān)鍵改進(jìn)就是引入了動態(tài)分辨率支持。不同于Qwen-VL將圖片先預(yù)處理為固定尺寸x再提取特征,Qwen2-VL能處理任意分辨率的圖像,動態(tài)地將圖片轉(zhuǎn)換為不同數(shù)量的視覺token。為了實(shí)現(xiàn)這個功能,不再采用原始的絕對位置編碼,而采用2D-RoPE來獲取圖像的兩個維度上的位置信息。在推理過程中,不同分辨率的圖像提取完特征后要再打包為一個特征序列,當(dāng)然特征序列的長度不能無限長,取決于GPU內(nèi)存大小。為了更進(jìn)一步減少圖片的視覺token數(shù)量,使用一個簡單的MLP層將相鄰的2x2 tokens壓縮為一個token。并在壓縮后的視覺token序列前后分別添加2個特殊的token:<|vision_start|>,<|vision_end|> 已標(biāo)記視覺token的位置。比如224x224分辨率的圖片,patch_size=14的情況下,如果不壓縮將產(chǎn)生16x16=256個token,經(jīng)過壓縮后就變成了64個token,如果再添加上用于視覺標(biāo)識的2個特征token,這樣最終就是66個token了。
疑問:VIT提取視覺特征是一個token序列,已經(jīng)失去了圖像原有的二維空間幾何關(guān)系,怎么這里是使用MLP層將相鄰的2x2 tokens壓縮為1個token呢? 原始VIT論文是將圖像切分按patch_size 不重疊地切分\(N=\frac{HW}{patch_size^2}\)個圖像塊,每個圖像塊映射為一個長度為D維的特征向量,并將這些特征向量按照對應(yīng)圖像塊從上到下從左到右序列排列。然后得到N個特征向量,這N個特征向量添加位置編碼特征,再經(jīng)過transfomer結(jié)構(gòu)得到最終的特征序列。這個token序列在序列中的位置,其實(shí)是隱含了剛才patch塊二維空間位置信息,通過reshape就可以將token序列變成形式上的二維。這樣就可以使用MLP層將2x2 tokens壓縮為1個token。
M-RoPE 多模態(tài)旋轉(zhuǎn)位置編碼(M-RoPE)是另一項(xiàng)關(guān)鍵的架構(gòu)改進(jìn)。與傳統(tǒng)大語言模型中僅能編碼一維位置信息的1D-RoPE不同,M-RoPE能夠有效建模多模態(tài)輸入的位置信息。其實(shí)現(xiàn)方式是將原始的旋轉(zhuǎn)位置編碼分解為三個組成部分:時間維度(temporal)、高度維度(height)和寬度維度(width)。對于文本輸入,這三個組成部分使用相同的位置ID,使得M-RoPE在功能上等價于1D-RoPE。在處理圖像時,每個視覺token的時間維度ID保持不變,而高度和寬度維度則根據(jù)該token在圖像中的空間位置分別賦予不同的ID。對于視頻(被視為幀序列),時間維度ID隨每一幀遞增,而高度和寬度維度的ID分配方式則與圖像處理相同。當(dāng)模型輸入包含多種模態(tài)時,每種模態(tài)的位置編號從上一種模態(tài)的最大位置ID加一后開始初始化。圖3展示了M-RoPE的示意圖。M-RoPE不僅增強(qiáng)了對位置信息的建模能力,還降低了圖像和視頻所對應(yīng)的位置ID數(shù)值,從而使模型在推理階段能夠更好地外推至更長的序列。 如圖3所示。
統(tǒng)一圖像和視頻理解 Qwen2-VL采用了融合圖像和視頻數(shù)據(jù)的混合訓(xùn)練策略,以確保模型在圖像理解和視頻理解方面都具有出色的能力。為了盡可能保留完整的視頻信息,每個視頻每秒采樣2幀。另外使用2層的3D卷積來預(yù)處理視頻輸入,使得模型能夠處理3D數(shù)據(jù),同時也可以處理更多的視頻幀而不增加token序列長度。為了保持一致性,每張圖片看作是2個相同的幀參與計算。為了平衡長視頻處理的計算開銷和整個訓(xùn)練效率,訓(xùn)練過程中動態(tài)調(diào)整視頻的尺寸,限制視頻的總token數(shù)量不超過16384。

訓(xùn)練
Qwen2-VL訓(xùn)練與Qwen-VL三階段訓(xùn)練保持一致,具體參考Qwen多模態(tài)系列模型筆記—Qwen-VL
Qwen-VL中關(guān)于訓(xùn)練集構(gòu)成進(jìn)行了詳細(xì)說明,而Qwen2-VL論文則沒有詳細(xì)說明其構(gòu)成,僅定性描述了一下。從論文零散的地方可以看出不同于Qwen-VL的部分。
- Qwen2-VL相比Qwen-VL增加對視頻的分析理解能力,數(shù)據(jù)集必然包括視頻為中心的數(shù)據(jù)
- 引言中提到了,Qwen2-VL定位服務(wù)全球,不僅限于中文和英文。數(shù)據(jù)集擴(kuò)充多語種數(shù)據(jù),包括大多數(shù)歐洲語言、日文、韓文、阿拉伯文、越南文等。
- 從表1中,Qwen2-VL-7B顯著提升了OCR識別能力。由此推測Qwen2-VL擴(kuò)充了OCR識別相關(guān)數(shù)據(jù)集。但這種能力提升也可能是采取動態(tài)分辨率帶來的,不像Qwen-VL采用固定低分辨448x448。尤其是整頁包含大量文本/公式這樣大圖片,采用動態(tài)分辨率方式能有效降低采取固定分辨率帶來的損失。
數(shù)據(jù)格式
與Qwen-VL一樣,仍然需要對圖像視頻、坐標(biāo)、文本中指代這些使用特殊標(biāo)記它們的開始和結(jié)束,但是具體的標(biāo)識符改變了。
| 模型 | 圖像標(biāo)識符 | 視頻標(biāo)識符 | 坐標(biāo)框標(biāo)識符 | 指代標(biāo)識符 | 對話標(biāo)識符 |
|---|---|---|---|---|---|
| Qwen-VL | <img>, <\img> |
/ | <box>, <\box> |
<ref>, <\ref> |
<im_start>,<im_end> |
| Qwen2-VL | <|vision_start|>,<|vision_end|> |
<|vision_start|>,<|vision_end|> |
<|box_start|>,<|box_end|> |
<|object_ref_start|>,<|object_ref_end|> |
<|im_start|>,<|im_end|> |


消融實(shí)驗(yàn)
動態(tài)分辨率 論文對動態(tài)分辨率和固定分辨率的性能進(jìn)行了對比。這里提到的固定分辨率并不是像Qwen-VL那樣將輸入圖片尺寸調(diào)整為固定的224x224或者448x448尺寸,而是調(diào)整圖像的尺度以便經(jīng)過VIT后得到固定長度的token序列。這種方式就不會破壞原始圖像的縱橫比參考Table7。可以看到圖像特征序列長度有64,576,1600,3136這4種,這4種長度,如果是方圖,則依次對應(yīng)224x224, 672x672, 1120x1120, 1568x1568這4種圖像分辨率。可以看出隨著圖像特征序列長度增加,在InfoVQA, REalWorldQA, OCRBench這3個測試集上,指標(biāo)值有明顯提升。說明了輸入較大尺寸的圖片,是可以達(dá)到更好的模型指標(biāo)。而采用動態(tài)分辨率技術(shù),使得使用平均較短的特征序列能達(dá)到采用更大輸出尺寸相當(dāng)?shù)哪P椭笜?biāo)。這表明了動態(tài)分辨率技術(shù)具有更大的優(yōu)勢,相當(dāng)?shù)哪P椭笜?biāo)下,計算量更小。
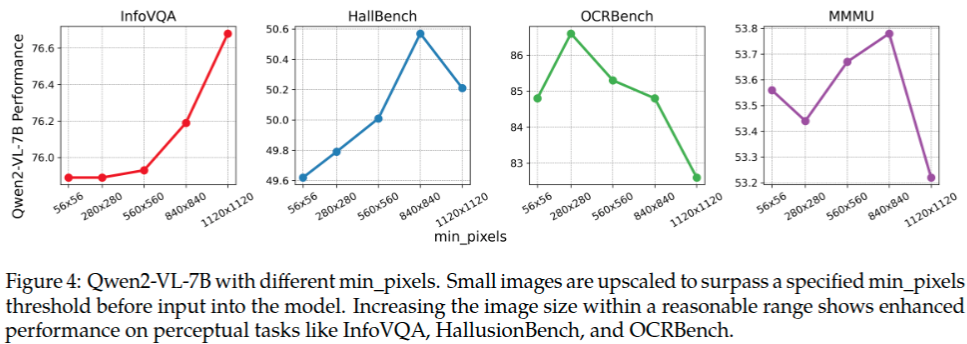
動態(tài)分辨率模式下,設(shè)置了最小和最大像素數(shù)量。\(min pixels=100 \times 28 \times 28\), \(max pixels=16384 \times 28 \times 28\),如果是方形圖像,那么就對應(yīng)著 \(280 \times 280\), \(3584 \times 3584\) 這兩個分辨率。大多數(shù)圖片像素總量也都落在這個范圍了,這也是為什么如此設(shè)置的原因。圖4列出了,最小圖片像素對模型性能的影響。可以看出將最小圖片像素閾值逐漸增大,并沒有顯著地提升模型的性能。這說明了小尺寸的圖片沒有必要上采樣更大的尺寸,原始是小尺寸圖片就采用原始的分辨率進(jìn)行后續(xù)VIT特征提取,也能達(dá)到較好的模型性能。最終驗(yàn)證了動態(tài)分辨率方案的優(yōu)越性。

關(guān)于Qwen2-VL能處理視頻長度的問題。下面4段是論文原話,第1段說可以處理20分鐘即1200秒左右的視頻;第2段說每秒提取2幀,那么推理得到可以Qwen2-VL可以處理最大2400幀。第3,4段限制視頻最大token數(shù)量是16384,而Qwen2-VL處理單張最小的圖片得到100個token,那么最多是163幀。這樣就產(chǎn)生了矛盾,163幀 vs 2400幀,無法處理20分鐘的視頻。猜測:如果要處理這么長的視頻,就不能采用每秒采樣2幀,而是每隔幾秒種采樣一幀才能實(shí)現(xiàn)。比如24分鐘分辨率280x280的視頻,每隔12秒采樣一幀,那么總的視頻token數(shù)量就是\(\frac{24 \times 60 \times 100}{12}=12000\),沒有超過16384.
Comprehension of extended-duration videos (20 min+): Qwen2-VL is capable of understanding videos over 20 minutes in length, enhancing its ability to perform high-quality video-based question answering, dialogue, content creation, and more.
To preserve video information as completely as possible, we sampled each video at two frames per second.
For consistency, each image is treated as two identical frames. To balance the computational demands of long video processing with overall training efficiency, we dynamically adjust the resolution of each video frame, limiting the total number of tokens per video to 16384.
For dynamic resolution, we only set min_pixels= 100 × 28 × 28 and max_pixels= 16384 × 28 × 28, allowing the number of image tokens depend primarily on the image's native resolution.

 浙公網(wǎng)安備 33010602011771號
浙公網(wǎng)安備 33010602011771號