C# 深度學習:對抗生成網(wǎng)絡(GAN)訓練頭像生成模型
通過生成對抗網(wǎng)絡(GAN)訓練和生成頭像
說明
https://torch.whuanle.cn
電子書倉庫:https://github.com/whuanle/cs_pytorch
Maomi.Torch 項目倉庫:https://github.com/whuanle/Maomi.Torch
本文根據(jù) Pytorch 官方文檔的示例移植而來,部分文字內(nèi)容和圖片來自 Pytorch 文檔,文章后面不再單獨列出引用說明。
官方文檔地址:
https://pytorch.org/tutorials/beginner/dcgan_faces_tutorial.html
社區(qū)中文翻譯版本:https://pytorch.ac.cn/tutorials/beginner/dcgan_faces_tutorial.html
Pytorch 示例項目倉庫:
https://github.com/pytorch/examples
對應 Python 版本示例:https://github.com/pytorch/tutorials/blob/main/beginner_source/dcgan_faces_tutorial.py
本文項目參考 dcgan 項目:https://github.com/whuanle/Maomi.Torch/tree/main/examples/dcgan
簡介
本教程將通過一個示例介紹生成對抗網(wǎng)絡(DCGAN),在教程中,我們將訓練一個生成對抗網(wǎng)絡 (GAN) 模型來生成新的名人頭像。這里的大部分代碼來自 pytorch/examples 中的 DCGAN 實現(xiàn),然后筆者通過 C# 移植了代碼實現(xiàn),本文檔將對該實現(xiàn)進行詳盡的解釋,并闡明該模型的工作原理和原因,閱讀本文不需要 GAN 的基礎知識,原理部分比較難理解,不用將精力放在這上面,主要是根據(jù)代碼思路走一遍即可。
生成式對抗網(wǎng)絡,簡單來說就像筆者喜歡攝影,但是攝影水平跟專業(yè)攝影師有差距,然后不斷苦練技術(shù),每拍一張照片就讓朋友判斷是筆者拍的還是專業(yè)攝影師拍的,如果朋友一眼就發(fā)現(xiàn)是我拍的,說明水平還不行。然后一直練,一直拍,直到朋友區(qū)分不出照片是筆者拍的,還是專業(yè)攝影師拍的,這就是生成式對抗網(wǎng)絡。
設計生成式對抗網(wǎng)絡,需要設計生成網(wǎng)絡和判斷網(wǎng)絡,生成網(wǎng)絡讀取訓練圖片并訓練轉(zhuǎn)換生成輸出結(jié)果,然后由判斷器識別,檢查生成的圖片和訓練圖片的差異,如果判斷器可以區(qū)分出生成的圖片和訓練圖片的差異,說明還需要繼續(xù)訓練,直到判斷器區(qū)分不出來。
什么是 GAN
GANs 是一種教深度學習模型捕捉訓練數(shù)據(jù)分布的框架,這樣我們可以從相同的分布生成新的數(shù)據(jù)。GANs 由 Ian Goodfellow 于 2014 年發(fā)明,并首次在論文 Generative Adversarial Nets 中描述。它們由兩個不同的模型組成,一個是生成器,另一個是判別器。生成器的任務是生成看起來像訓練圖像的“假”圖像。判別器的任務是查看圖像,并輸出它是否是真實訓練圖像或來自生成器的假圖像。在訓練期間,生成器不斷嘗試通過生成越來越好的假圖像來欺騙判別器,而判別器則努力成為一名更好的偵探,正確分類真實圖像和假圖像。這場博弈的平衡點是生成器生成完美的假圖像,看起來似乎直接來自訓練數(shù)據(jù),而判別器總是以 50% 的置信度猜測生成器的輸出是真實的還是假的。
現(xiàn)在,讓我們定義一些將在整個教程中使用的符號,從判別器開始。設 \(x\) 為表示圖像的數(shù)據(jù)。\(D(x)\) 是判別器網(wǎng)絡,輸出 \(x\) 來自訓練數(shù)據(jù)而不是生成器的(標量)概率。這里,由于我們處理的是圖像,\(D(x)\) 的輸入是 CHW 尺寸為 3x64x64 的圖像。直觀上,當 \(x\) 來自訓練數(shù)據(jù)時,\(D(x)\) 應該是高的,而當 \(x\) 來自生成器時,\(D(x)\) 應該是低的。\(D(x)\) 也可以視為傳統(tǒng)的二分類器。
對于生成器的符號,設 \(z\) 為從標準正態(tài)分布中采樣的潛在空間向量。\(G(z)\) 表示將潛在向量 \(z\) 映射到數(shù)據(jù)空間的生成器函數(shù)。\(G\) 的目標是估計訓練數(shù)據(jù)來自的分布 (\(p_{data}\)),以便從該估計分布中生成假樣本 (\(p_g\))。
因此,\(D(G(z))\) 是生成器輸出 \(G\) 為真實圖像的概率(標量)。如 Goodfellow 的論文 中所描述,\(D\) 和 \(G\) 進行一個極小極大博弈,其中 \(D\) 盡量最大化它正確分類真實和假的概率 (\(logD(x)\)),而 \(G\) 盡量最小化 \(D\) 預測其輸出為假的概率 (\(log(1-D(G(z)))\))。在這篇論文中,GAN 損失函數(shù)為
理論上,這個極小極大博弈的解是 \(p_g = p_{data}\),而判別器隨機猜測輸入是真實的還是假的。然而,GANs 的收斂理論仍在積極研究中,實際上模型并不總是能夠訓練到這一點。
什么是 DCGAN
DCGAN 是上述 GAN 的直接擴展,不同之處在于它在判別器和生成器中明確使用了卷積層和反卷積層。Radford 等人在論文《利用深度卷積生成對抗網(wǎng)絡進行無監(jiān)督表示學習》中首次描述了這種方法。判別器由步幅卷積層、批量歸一化層以及LeakyReLU激活函數(shù)組成。輸入是一個 3x64x64 的輸入圖像,輸出是一個標量概率,表示輸入是否來自真實的數(shù)據(jù)分布。生成器由反卷積層、批量歸一化層和ReLU激活函數(shù)組成。輸入是從標準正態(tài)分布中抽取的潛在向量 \(z\),輸出是一個 3x64x64 的 RGB 圖像。步幅的反卷積層允許將潛在向量轉(zhuǎn)換為具有與圖像相同形狀的體積。在論文中,作者還提供了一些如何設置優(yōu)化器、如何計算損失函數(shù)以及如何初始化模型權(quán)重的建議,這些將在后續(xù)章節(jié)中解釋。
然后引入依賴并配置訓練參數(shù):
using dcgan;
using Maomi.Torch;
using System.Diagnostics;
using TorchSharp;
using TorchSharp.Modules;
using static TorchSharp.torch;
// 使用 GPU 啟動
Device defaultDevice = MM.GetOpTimalDevice();
torch.set_default_device(defaultDevice);
// Set random seed for reproducibility
var manualSeed = 999;
// manualSeed = random.randint(1, 10000) # use if you want new results
Console.WriteLine("Random Seed:" + manualSeed);
random.manual_seed(manualSeed);
torch.manual_seed(manualSeed);
Options options = new Options()
{
Dataroot = "E:\\datasets\\celeba",
// 設置這個可以并發(fā)加載數(shù)據(jù)集,加快訓練速度
Workers = 10,
BatchSize = 128,
};
稍后講解如何下載圖片數(shù)據(jù)集。
用于訓練的人像圖片數(shù)據(jù)集大概是 22萬張,不可能一次性全部加載,所以需要設置 BatchSize 參數(shù)分批導入、分批訓練,如果讀者的 GPU 性能比較高,則可以設置大一些。
參數(shù)說明
前面提到了 Options 模型類定義訓練模型的參數(shù),下面給出每個參數(shù)的詳細說明。
注意字段名稱略有差異,并且移植版本并不是所有參數(shù)都用上。
dataroot- 數(shù)據(jù)集文件夾根目錄的路徑。我們將在下一節(jié)中詳細討論數(shù)據(jù)集。workers- 用于使用DataLoader加載數(shù)據(jù)的工作線程數(shù)。batch_size- 訓練中使用的批大小。DCGAN 論文使用 128 的批大小。image_size- 用于訓練的圖像的空間大小。此實現(xiàn)默認為 64x64。如果需要其他大小,則必須更改 D 和 G 的結(jié)構(gòu)。有關(guān)更多詳細信息,請參閱 此處。nc- 輸入圖像中的顏色通道數(shù)。對于彩色圖像,此值為 3。nz- 潛在向量的長度。ngf- 與通過生成器傳遞的特征圖的深度有關(guān)。ndf- 設置通過判別器傳播的特征圖的深度。num_epochs- 要運行的訓練 epoch 數(shù)。訓練時間越長可能會帶來更好的結(jié)果,但也會花費更長的時間。lr- 訓練的學習率。如 DCGAN 論文中所述,此數(shù)字應為 0.0002。beta1- Adam 優(yōu)化器的 beta1 超參數(shù)。如論文中所述,此數(shù)字應為 0.5。ngpu- 可用的 GPU 數(shù)量。如果此值為 0,則代碼將在 CPU 模式下運行。如果此數(shù)字大于 0,則它將在那幾個 GPU 上運行。
首先定義一個全局參數(shù)模型類,并設置默認值:
public class Options
{
/// <summary>
/// Root directory for dataset
/// </summary>
public string Dataroot { get; set; } = "data/celeba";
/// <summary>
/// Number of workers for dataloader
/// </summary>
public int Workers { get; set; } = 2;
/// <summary>
/// Batch size during training
/// </summary>
public int BatchSize { get; set; } = 128;
/// <summary>
/// Spatial size of training images. All images will be resized to this size using a transformer.
/// </summary>
public int ImageSize { get; set; } = 64;
/// <summary>
/// Number of channels in the training images. For color images this is 3
/// </summary>
public int Nc { get; set; } = 3;
/// <summary>
/// Size of z latent vector (i.e. size of generator input)
/// </summary>
public int Nz { get; set; } = 100;
/// <summary>
/// Size of feature maps in generator
/// </summary>
public int Ngf { get; set; } = 64;
/// <summary>
/// Size of feature maps in discriminator
/// </summary>
public int Ndf { get; set; } = 64;
/// <summary>
/// Number of training epochs
/// </summary>
public int NumEpochs { get; set; } = 5;
/// <summary>
/// Learning rate for optimizers
/// </summary>
public double Lr { get; set; } = 0.0002;
/// <summary>
/// Beta1 hyperparameter for Adam optimizers
/// </summary>
public double Beta1 { get; set; } = 0.5;
/// <summary>
/// Number of GPUs available. Use 0 for CPU mode.
/// </summary>
public int Ngpu { get; set; } = 1;
}
數(shù)據(jù)集處理
本教程中,我們將使用 Celeb-A Faces 數(shù)據(jù)集 來訓練模型,可以從鏈接網(wǎng)站或在 Google Drive 下載。
數(shù)據(jù)集官方地址:https://mmlab.ie.cuhk.edu.hk/projects/CelebA.html
可以通過 Google 網(wǎng)盤或百度網(wǎng)盤下載:
https://pan.baidu.com/s/1CRxxhoQ97A5qbsKO7iaAJg
提取碼:
rp0s
注意,本文只需要用到圖片,不需要用到標簽,不用下載所有文件,只需要下載 CelebA/Img/img_align_celeba.zip 即可。下載后解壓到一個空目錄中,其目錄結(jié)構(gòu)示例:
/path/to/celeba
-> img_align_celeba
-> 188242.jpg
-> 173822.jpg
-> 284702.jpg
-> 537394.jpg
...
然后在 Options.Dataroot 參數(shù)填寫 /path/to/celeba 即可,導入數(shù)據(jù)集時會自動搜索該目錄下的子目錄,將子目錄作為圖像的分類名稱,然后向子目錄加載所有圖像文件。
這是一個重要步驟,因為我們將使用 ImageFolder 數(shù)據(jù)集類,該類要求數(shù)據(jù)集根文件夾中有子目錄。現(xiàn)在,我們可以創(chuàng)建數(shù)據(jù)集,創(chuàng)建數(shù)據(jù)加載器,設置運行設備,并最終可視化一些訓練數(shù)據(jù)。
// 創(chuàng)建一個 samples 目錄用于輸出訓練過程中產(chǎn)生的輸出效果
if(Directory.Exists("samples"))
{
Directory.Delete("samples", true);
}
Directory.CreateDirectory("samples");
// 加載圖像并對圖像做轉(zhuǎn)換處理
var dataset = MM.Datasets.ImageFolder(options.Dataroot, torchvision.transforms.Compose(
torchvision.transforms.Resize(options.ImageSize),
torchvision.transforms.CenterCrop(options.ImageSize),
torchvision.transforms.ConvertImageDtype(ScalarType.Float32),
torchvision.transforms.Normalize(new double[] { 0.5, 0.5, 0.5 }, new double[] { 0.5, 0.5, 0.5 }))
);
// 分批加載圖像
var dataloader = torch.utils.data.DataLoader(dataset, batchSize: options.BatchSize, shuffle: true, num_worker: options.Workers, device: defaultDevice);
var netG = new dcgan.Generator(options).to(defaultDevice);
在設置好輸入?yún)?shù)并準備好數(shù)據(jù)集后,我們現(xiàn)在可以進入實現(xiàn)部分。我們將從權(quán)重初始化策略開始,然后詳細討論生成器、判別器、損失函數(shù)和訓練循環(huán)。
權(quán)重初始化
根據(jù) DCGAN 論文,作者指出所有模型權(quán)重應從均值為 0,標準差為 0.02 的正態(tài)分布中隨機初始化。weights_init 函數(shù)以已初始化的模型為輸入,重新初始化所有卷積層、轉(zhuǎn)置卷積層和批量歸一化層以滿足此標準。此函數(shù)在模型初始化后立即應用于模型。
static void weights_init(nn.Module m)
{
var classname = m.GetType().Name;
if (classname.Contains("Conv"))
{
if (m is Conv2d conv2d)
{
nn.init.normal_(conv2d.weight, 0.0, 0.02);
}
}
else if (classname.Contains("BatchNorm"))
{
if (m is BatchNorm2d batchNorm2d)
{
nn.init.normal_(batchNorm2d.weight, 1.0, 0.02);
nn.init.zeros_(batchNorm2d.bias);
}
}
}
網(wǎng)絡模型會有多層結(jié)構(gòu),模型訓練時到不同的層時會自動調(diào)用 weights_init 函數(shù)初始化,作用對象不是模型本身,而是網(wǎng)絡模型的層。
生成器
生成器 \(G\) 旨在將潛在空間向量 ( \(z\) ) 映射到數(shù)據(jù)空間。由于我們的數(shù)據(jù)是圖像,將 \(z\) 轉(zhuǎn)換為數(shù)據(jù)空間意味著最終要創(chuàng)建一個與訓練圖像具有相同大小的 RGB 圖像 (即 3x64x64)。在實踐中,這是通過一系列步幅為二維的卷積轉(zhuǎn)置層來實現(xiàn)的,每一層都配有一個 2d 批量規(guī)范化層和一個 relu 激活函數(shù)。生成器的輸出通過一個 tanh 函數(shù)返回到輸入數(shù)據(jù)范圍 \([-1,1]\) 。值得注意的是在 conv-transpose 層之后存在批量規(guī)范化函數(shù),因為這是 DCGAN 論文的重要貢獻之一。這些層有助于訓練期間梯度的流動。下圖顯示了 DCGAN 論文中的生成器。
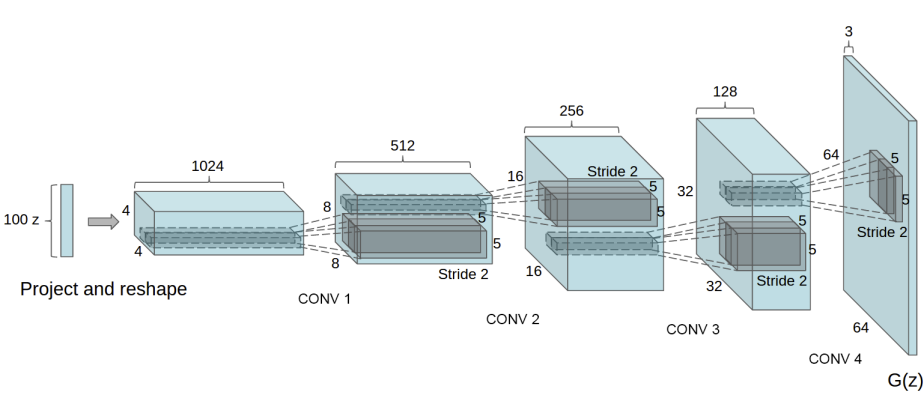
請注意,我們在輸入部分設置的輸入(nz,ngf,和 nc)如何影響代碼中生成器的架構(gòu)。nz 是 z 輸入向量的長度,ngf 與在生成器中傳播的特征圖的大小有關(guān),而 nc 是輸出圖像中的通道數(shù)(對于 RGB 圖像設置為 3)。下面是生成器的代碼。
定義圖像生成的網(wǎng)絡模型:
public class Generator : nn.Module<Tensor, Tensor>, IDisposable
{
private readonly Options _options;
public Generator(Options options) : base(nameof(Generator))
{
_options = options;
main = nn.Sequential(
// input is Z, going into a convolution
nn.ConvTranspose2d(options.Nz, options.Ngf * 8, 4, 1, 0, bias: false),
nn.BatchNorm2d(options.Ngf * 8),
nn.ReLU(true),
// state size. (ngf*8) x 4 x 4
nn.ConvTranspose2d(options.Ngf * 8, options.Ngf * 4, 4, 2, 1, bias: false),
nn.BatchNorm2d(options.Ngf * 4),
nn.ReLU(true),
// state size. (ngf*4) x 8 x 8
nn.ConvTranspose2d(options.Ngf * 4, options.Ngf * 2, 4, 2, 1, bias: false),
nn.BatchNorm2d(options.Ngf * 2),
nn.ReLU(true),
// state size. (ngf*2) x 16 x 16
nn.ConvTranspose2d(options.Ngf * 2, options.Ngf, 4, 2, 1, bias: false),
nn.BatchNorm2d(options.Ngf),
nn.ReLU(true),
// state size. (ngf) x 32 x 32
nn.ConvTranspose2d(options.Ngf, options.Nc, 4, 2, 1, bias: false),
nn.Tanh()
// state size. (nc) x 64 x 64
);
RegisterComponents();
}
public override Tensor forward(Tensor input)
{
return main.call(input);
}
Sequential main;
}
初始化模型:
var netG = new dcgan.Generator(options).to(defaultDevice);
netG.apply(weights_init);
Console.WriteLine(netG);
判別器
如前所述,判別器 \(D\) 是一個二分類網(wǎng)絡,它以圖像為輸入并輸出一個標量概率,即輸入圖像是真實的(而非偽造的)的概率。這里,\(D\) 接受一個 3x64x64 的輸入圖像,通過一系列的 Conv2d、BatchNorm2d 和 LeakyReLU 層進行處理,并通過 Sigmoid 激活函數(shù)輸出最終的概率。根據(jù)問題的需要,可以擴展這一架構(gòu)以包含更多層數(shù),但使用跨步卷積、BatchNorm 和 LeakyReLUs 是有意義的。DCGAN 論文提到,使用跨步卷積而非池化來進行下采樣是一個好習慣,因為它使網(wǎng)絡能夠?qū)W習其自己的池化函數(shù)。此外,批量規(guī)范化和 leaky relu 函數(shù)促進了健康的梯度流動,這對 \(G\) 和 \(D\) 的學習過程至關(guān)重要。
定義判別器網(wǎng)絡模型:
public class Discriminator : nn.Module<Tensor, Tensor>, IDisposable
{
private readonly Options _options;
public Discriminator(Options options) : base(nameof(Discriminator))
{
_options = options;
main = nn.Sequential(
// input is (nc) x 64 x 64
nn.Conv2d(options.Nc, options.Ndf, 4, 2, 1, bias: false),
nn.LeakyReLU(0.2, inplace: true),
// state size. (ndf) x 32 x 32
nn.Conv2d(options.Ndf, options.Ndf * 2, 4, 2, 1, bias: false),
nn.BatchNorm2d(options.Ndf * 2),
nn.LeakyReLU(0.2, inplace: true),
// state size. (ndf*2) x 16 x 16
nn.Conv2d(options.Ndf * 2, options.Ndf * 4, 4, 2, 1, bias: false),
nn.BatchNorm2d(options.Ndf * 4),
nn.LeakyReLU(0.2, inplace: true),
// state size. (ndf*4) x 8 x 8
nn.Conv2d(options.Ndf * 4, options.Ndf * 8, 4, 2, 1, bias: false),
nn.BatchNorm2d(options.Ndf * 8),
nn.LeakyReLU(0.2, inplace: true),
// state size. (ndf*8) x 4 x 4
nn.Conv2d(options.Ndf * 8, 1, 4, 1, 0, bias: false),
nn.Sigmoid()
);
RegisterComponents();
}
public override Tensor forward(Tensor input)
{
var output = main.call(input);
return output.view(-1, 1).squeeze(1);
}
Sequential main;
}
初始化模型:
var netD = new dcgan.Discriminator(options).to(defaultDevice);
netD.apply(weights_init);
Console.WriteLine(netD);
損失函數(shù)和優(yōu)化器
設置好 \(D\) 和 \(G\) 后,我們可以通過損失函數(shù)和優(yōu)化器指定它們的學習方式。我們將使用二元交叉熵損失函數(shù)(BCELoss),它在 PyTorch 中定義如下:
請注意,這個函數(shù)提供了目標函數(shù)中兩個對數(shù)分量,即 \(log(D(x))\) 和 \(log(1-D(G(z)))\) 的計算。我們可以通過 \(y\) 輸入來指定使用 BCE 方程的哪一部分。這將在即將到來的訓練循環(huán)中完成,但是了解我們可以通過改變 \(y\)(即 GT 標簽)選擇希望計算的分量非常重要。
接下來,我們將真實標簽定義為 1,假的標簽定義為 0。這些標簽將在計算 \(D\) 和 \(G\) 的損失時使用,這也是原始 GAN 論文中使用的約定。最后,我們設置兩個獨立的優(yōu)化器,一個用于 \(D\),另一個用于 \(G\)。根據(jù) DCGAN 論文的規(guī)定,兩者都是 Adam 優(yōu)化器,學習率為 0.0002,Beta1 = 0.5。為了追蹤生成器的學習進展,我們將生成一個從高斯分布中抽取的固定批次的潛在向量(即 fixed_noise)。在訓練循環(huán)中,我們將定期將這個 fixed_noise 輸入 \(G\),并且在迭代過程中,我們將看到圖像從噪聲中形成。
var criterion = nn.BCELoss();
var fixed_noise = torch.randn(new long[] { options.BatchSize, options.Nz, 1, 1 }, device: defaultDevice);
var real_label = 1.0;
var fake_label = 0.0;
var optimizerD = torch.optim.Adam(netD.parameters(), lr: options.Lr, beta1: options.Beta1, beta2: 0.999);
var optimizerG = torch.optim.Adam(netG.parameters(), lr: options.Lr, beta1: options.Beta1, beta2: 0.999);
訓練
最后,在我們定義了GAN框架的所有部分之后,我們可以開始訓練它了。請注意,訓練GANs在某種程度上是一門藝術(shù),因為不正確的超參數(shù)設置會導致模式崩潰,并且很難解釋出了什么問題。在這里,我們將緊密遵循 Goodfellow的論文 中的算法1,同時遵循一些在ganhacks中顯示的最佳實踐。具體來說,我們將“為真實和虛假的圖像構(gòu)建不同的小批量”,并調(diào)整G的目標函數(shù)以最大化 \(log(D(G(z)))\) 。訓練分為兩個主要部分:第一部分更新判別器,第二部分更新生成器。
第1部分 - 訓練判別器
回顧一下,訓練判別器的目標是最大化正確分類給定輸入為真實或虛假的概率。根據(jù)Goodfellow的說法,我們希望“通過上升隨機梯度來更新判別器”。實際上,我們希望最大化 \(log(D(x)) + log(1-D(G(z)))\) 。根據(jù) ganhacks 的獨立小批量建議,我們將分兩步計算這一點。首先,我們將從訓練集中構(gòu)建一個真實樣本的小批量,前向傳遞通過 \(D\),計算損失 ( \(log(D(x))\) ) ,然后反向傳遞計算梯度。其次,我們將使用當前的生成器構(gòu)建一個虛假樣本的小批量,將此批次前向傳遞通過 \(D\),計算損失 ( \(log(1-D(G(z)))\) ),并通過反向傳遞累積梯度。現(xiàn)在,隨著從全真和全假批次累積的梯度,我們調(diào)用判別器優(yōu)化器的一步。
第2部分 - 訓練生成器
如原論文所述,我們希望通過最小化 \(log(1-D(G(z)))\) 來訓練生成器,以便生成更好的虛假樣本。如前所述,Goodfellow 顯示這在學習過程中尤其是早期不會提供足夠的梯度。作為解決方案,我們希望最大化 \(log(D(G(z)))\) 。在代碼中,我們通過以下方法實現(xiàn)這一點:使用判別器對第1部分生成器的輸出進行分類,使用真實標簽作為GT計算G的損失,在反向傳遞中計算G的梯度,最后用優(yōu)化器一步更新G的參數(shù)。使用真實標簽作為損失函數(shù)的GT標簽可能看起來違反直覺,但這允許我們使用 BCELoss 的 \(log(x)\) 部分(而不是 \(log(1-x)\) 部分),這正是我們所需要的。
最后,我們將進行一些統(tǒng)計報告,并且在每個epoch結(jié)束時,我們將通過生成器推送我們的固定噪聲批次,以便直觀地跟蹤G的訓練進度。報告的訓練統(tǒng)計數(shù)據(jù)包括:
- Loss_D - 判別器損失,計算為全真和全假批次損失的總和 ( \(log(D(x)) + log(1 - D(G(z)))\) )。
- Loss_G - 生成器損失,計算為 \(log(D(G(z)))\)
- D(x) - 判別器對全真批次的平均輸出(跨批次)。這應該從接近 1 開始,然后在G變好時理論上收斂到 0.5。想想這是為什么。
- D(G(z)) - 判別器對全假批次的平均輸出。第一個數(shù)字是 D 更新之前的,第二個數(shù)字是 D 更新之后的。這些數(shù)字應該從接近0開始,并在 G 變好時收斂到 0.5。想想這是為什么。
注意: 這一步可能需要一段時間,具體取決于你運行了多少個epochs以及是否從數(shù)據(jù)集中刪除了一些數(shù)據(jù)。
var img_list = new List<Tensor>();
var G_losses = new List<double>();
var D_losses = new List<double>();
Console.WriteLine("Starting Training Loop...");
Stopwatch stopwatch = new();
stopwatch.Start();
int i = 0;
// For each epoch
for (int epoch = 0; epoch < options.NumEpochs; epoch++)
{
foreach (var item in dataloader)
{
var data = item[0];
netD.zero_grad();
// Format batch
var real_cpu = data.to(defaultDevice);
var b_size = real_cpu.size(0);
var label = torch.full(new long[] { b_size }, real_label, dtype: ScalarType.Float32, device: defaultDevice);
// Forward pass real batch through D
var output = netD.forward(real_cpu);
// Calculate loss on all-real batch
var errD_real = criterion.call(output, label);
// Calculate gradients for D in backward pass
errD_real.backward();
var D_x = output.mean().item<float>();
// Train with all-fake batch
// Generate batch of latent vectors
var noise = torch.randn(new long[] { b_size, options.Nz, 1, 1 }, device: defaultDevice);
// Generate fake image batch with G
var fake = netG.call(noise);
label.fill_(fake_label);
// Classify all fake batch with D
output = netD.call(fake.detach());
// Calculate D's loss on the all-fake batch
var errD_fake = criterion.call(output, label);
// Calculate the gradients for this batch, accumulated (summed) with previous gradients
errD_fake.backward();
var D_G_z1 = output.mean().item<float>();
// Compute error of D as sum over the fake and the real batches
var errD = errD_real + errD_fake;
// Update D
optimizerD.step();
////////////////////////////
// (2) Update G network: maximize log(D(G(z)))
////////////////////////////
netG.zero_grad();
label.fill_(real_label); // fake labels are real for generator cost
// Since we just updated D, perform another forward pass of all-fake batch through D
output = netD.call(fake);
// Calculate G's loss based on this output
var errG = criterion.call(output, label);
// Calculate gradients for G
errG.backward();
var D_G_z2 = output.mean().item<float>();
// Update G
optimizerG.step();
// ex: [0/25][4/3166] Loss_D: 0.5676 Loss_G: 7.5972 D(x): 0.9131 D(G(z)): 0.3024 / 0.0007
Console.WriteLine($"[{epoch}/{options.NumEpochs}][{i%dataloader.Count}/{dataloader.Count}] Loss_D: {errD.item<float>():F4} Loss_G: {errG.item<float>():F4} D(x): {D_x:F4} D(G(z)): {D_G_z1:F4} / {D_G_z2:F4}");
// 每處理 100 批,輸出一次圖片效果
if (i % 100 == 0)
{
real_cpu.SaveJpeg("samples/real_samples.jpg");
fake = netG.call(fixed_noise);
fake.detach().SaveJpeg("samples/fake_samples_epoch_{epoch:D3}.jpg");
}
i++;
}
netG.save("samples/netg_{epoch}.dat");
netD.save("samples/netd_{epoch}.dat");
}
最后打印訓練結(jié)果和輸出:
Console.WriteLine("Training finished.");
stopwatch.Stop();
Console.WriteLine("Training Time: {stopwatch.Elapsed}");
netG.save("samples/netg.dat");
netD.save("samples/netd.dat");
按照官方示例推薦進行 25 輪訓練,由于筆者使用使用 4060TI 8G 機器訓練,訓練 25 輪大概時間:
Training finished.
Training Time: 00:49:45.6976041
每輪訓練結(jié)果的圖像:
第一輪訓練生成:

第 25 輪生成的:

雖然還是有些抽象,但生成結(jié)果比之前好一些了。
在 dcgan_out 項目中開業(yè)看到,使用 5 輪訓練結(jié)果輸出的模型,生成圖像:
Device defaultDevice = MM.GetOpTimalDevice();
torch.set_default_device(defaultDevice);
// Set random seed for reproducibility
var manualSeed = 999;
// manualSeed = random.randint(1, 10000) # use if you want new results
Console.WriteLine("Random Seed:" + manualSeed);
random.manual_seed(manualSeed);
torch.manual_seed(manualSeed);
Options options = new Options()
{
Dataroot = "E:\\datasets\\celeba",
Workers = 10,
BatchSize = 128,
};
var netG = new dcgan.Generator(options);
netG.to(defaultDevice);
netG.load("netg.dat");
// 生成隨機噪聲
var fixed_noise = torch.randn(64, options.Nz, 1, 1, device: defaultDevice);
// 生成圖像
var fake_images = netG.call(fixed_noise);
fake_images.SaveJpeg("fake_images.jpg");
雖然還是有些抽象,但確實還行。


 浙公網(wǎng)安備 33010602011771號
浙公網(wǎng)安備 33010602011771號