機(jī)器學(xué)習(xí)基本介紹
1、人工智能概述
人工智能發(fā)展必備三要素:
- 數(shù)據(jù)
- 算法
- 計(jì)算力
- CPU,GPU,TPU
計(jì)算力之CPU、GPU對(duì)比:
-
CPU主要適合I\O密集型的任務(wù)
-
GPU主要適合計(jì)算密集型任務(wù)
1.1、人工智能、機(jī)器學(xué)習(xí)和深度學(xué)習(xí)的關(guān)系

人工智能和機(jī)器學(xué)習(xí),深度學(xué)習(xí)的關(guān)系:
-
機(jī)器學(xué)習(xí)是人工智能的一個(gè)實(shí)現(xiàn)途徑
-
深度學(xué)習(xí)是機(jī)器學(xué)習(xí)的一個(gè)方法發(fā)展而來
1.2、人工智能發(fā)展歷程
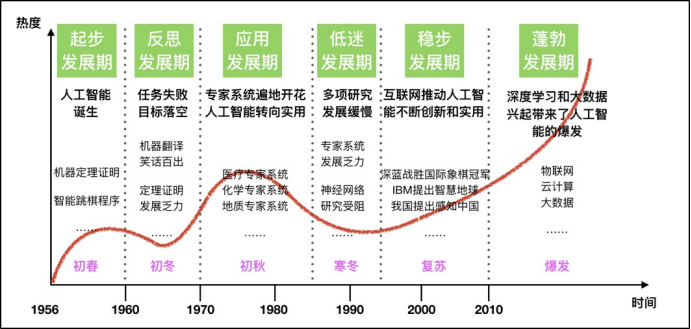
人工智能的起源:圖靈測試。即測試者與被測試者(一個(gè)人和一臺(tái)機(jī)器)隔開的情況下,通過一些裝置(如鍵盤)向被測試者隨意提問。多次測試(一般為5min之內(nèi)),如果有超過30%的測試者不能確定被測試者是人還是機(jī)器,那么這臺(tái)機(jī)器就通過了測試,并被認(rèn)為具有人類智能。
人工智能充滿未知的探索道路曲折起伏。如何描述人工智能自1956年以來60余年的發(fā)展歷程,學(xué)術(shù)界可謂仁者見仁、智者見智。我們將人工智能的發(fā)展歷程劃分為以下6個(gè)階段:
1.3、人工智能主要分支
通訊、感知與行動(dòng)是現(xiàn)代人工智能的三個(gè)關(guān)鍵能力,在這里我們將根據(jù)這些能力/應(yīng)用對(duì)這三個(gè)技術(shù)領(lǐng)域進(jìn)行介紹:
- 計(jì)算機(jī)視覺(CV)
- 自然語言處理(NLP)
- 在 NLP 領(lǐng)域中,將覆蓋文本挖掘/分類、機(jī)器翻譯和語音識(shí)別。
- 機(jī)器人
-
計(jì)算機(jī)視覺
計(jì)算機(jī)視覺(CV)是指機(jī)器感知環(huán)境的能力。這一技術(shù)類別中的經(jīng)典任務(wù)有圖像形成、圖像處理、圖像提取和圖像的三維推理。物體檢測和人臉識(shí)別是其比較成功的研究領(lǐng)域。
當(dāng)前階段:計(jì)算機(jī)視覺現(xiàn)已有很多應(yīng)用,這表明了這類技術(shù)的成就,也讓我們將其歸入到應(yīng)用階段。隨著深度學(xué)習(xí)的發(fā)展,機(jī)器甚至能在特定的案例中實(shí)現(xiàn)超越人類的表現(xiàn)。但是,這項(xiàng)技術(shù)離社會(huì)影響階段還有一定距離,那要等到機(jī)器能在所有場景中都達(dá)到人類的同等水平才行(感知其環(huán)境的所有相關(guān)方面)。
發(fā)展歷史:

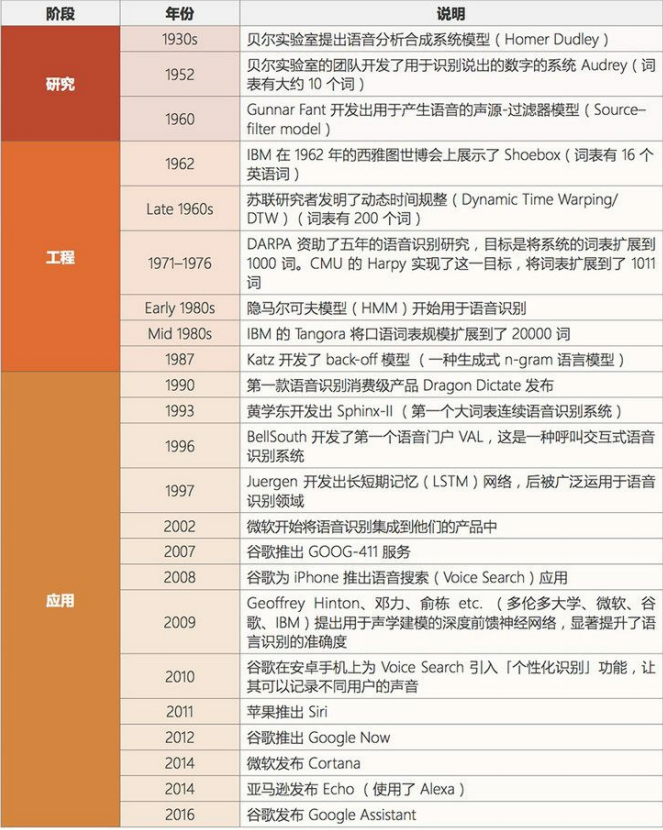
- 語音識(shí)別
語音識(shí)別是指識(shí)別語音(說出的語言)并將其轉(zhuǎn)換成對(duì)應(yīng)文本的技術(shù)。相反的任務(wù)(文本轉(zhuǎn)語音/TTS)也是這一領(lǐng)域內(nèi)一個(gè)類似的研究主題。
當(dāng)前階段:語音識(shí)別已經(jīng)處于應(yīng)用階段很長時(shí)間了。最近幾年,隨著大數(shù)據(jù)和深度學(xué)習(xí)技術(shù)的發(fā)展,語音識(shí)別進(jìn)展頗豐,現(xiàn)在已經(jīng)非常接近社會(huì)影響階段了。語音識(shí)別領(lǐng)域仍然面臨著聲紋識(shí)別和「雞尾酒會(huì)效應(yīng)」等一些特殊情況的難題。現(xiàn)代語音識(shí)別系統(tǒng)嚴(yán)重依賴于云,在離線時(shí)可能就無法取得理想的工作效果。
發(fā)展歷史:
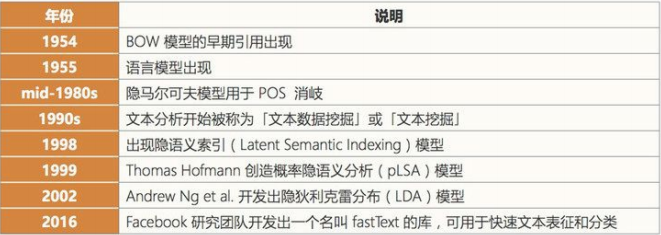
- 文本挖掘/分類
這里的文本挖掘主要是指文本分類,該技術(shù)可用于理解、組織和分類結(jié)構(gòu)化或非結(jié)構(gòu)化文本文檔。其涵蓋的主要任務(wù)有句法分析、情緒分析和垃圾信息檢測。
當(dāng)前階段:我們將這項(xiàng)技術(shù)歸類到應(yīng)用階段,因?yàn)楝F(xiàn)在有很多應(yīng)用都已經(jīng)集成了基于文本挖掘的情緒分析或垃圾信息檢測技術(shù)。文本挖掘技術(shù)也在智能投顧的開發(fā)中有所應(yīng)用,并且提升了用戶體驗(yàn)。文本挖掘和分類領(lǐng)域的一個(gè)瓶頸出現(xiàn)在歧義和有偏差的數(shù)據(jù)上。
發(fā)展歷史:
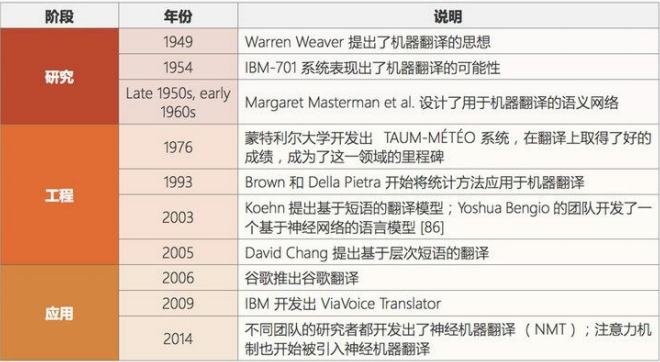
- 機(jī)器翻譯
機(jī)器翻譯(MT)是利用機(jī)器的力量自動(dòng)將一種自然語言(源語言)的文本翻譯成另一種語言(目標(biāo)語言)。
當(dāng)前階段:機(jī)器翻譯是一個(gè)見證了大量發(fā)展歷程的應(yīng)用領(lǐng)域。該領(lǐng)域最近由于神經(jīng)機(jī)器翻譯而取得了非常顯著的進(jìn)展,但仍然沒有全面達(dá)到專業(yè)譯者的水平;但是,我們相信在大數(shù)據(jù)、云計(jì)算和深度學(xué)習(xí)技術(shù)的幫助下,機(jī)器翻譯很快就將進(jìn)入社會(huì)影響階段。在某些情況下,俚語和行話等內(nèi)容的翻譯會(huì)比較困難(受限詞表問題)。專業(yè)領(lǐng)域的機(jī)器翻譯(比如醫(yī)療領(lǐng)域)表現(xiàn)通常不好。
發(fā)展歷史:
- 機(jī)器人
機(jī)器人學(xué)(Robotics)研究的是機(jī)器人的設(shè)計(jì)、制造、運(yùn)作和應(yīng)用,以及控制它們的計(jì)算機(jī)系統(tǒng)、傳感反饋和信息處理。
機(jī)器人可以分成兩大類:固定機(jī)器人和移動(dòng)機(jī)器人。固定機(jī)器人通常被用于工業(yè)生產(chǎn)(比如用于裝配線)。常見的移動(dòng)機(jī)器人應(yīng)用有貨運(yùn)機(jī)器人、空中機(jī)器人和自動(dòng)載具。機(jī)器人需要不同部件和系統(tǒng)的協(xié)作才能實(shí)現(xiàn)最優(yōu)的作業(yè)。其中在硬件上包含傳感器、反應(yīng)器和控制器;另外還有能夠?qū)崿F(xiàn)感知能力的軟件,比如定位、地圖測繪和目標(biāo)識(shí)別。
當(dāng)前階段:
自上世紀(jì)「Robot」一詞誕生以來,人們已經(jīng)為工業(yè)制造業(yè)設(shè)計(jì)了很多機(jī)器人。工業(yè)機(jī)器人是增長最快的應(yīng)用領(lǐng)域,它們在 20 世紀(jì) 80 年代將這一領(lǐng)域帶入了應(yīng)用階段。在安川電機(jī)、Fanuc、ABB、庫卡等公司的努力下,我們認(rèn)為進(jìn)入 21 世紀(jì)之后,機(jī)器人領(lǐng)域就已經(jīng)進(jìn)入了社會(huì)影響階段,此時(shí)各種工業(yè)機(jī)器人已經(jīng)主宰了裝配生產(chǎn)線。此外,軟體機(jī)器人在很多領(lǐng)域也有廣泛的應(yīng)用,比如在醫(yī)療行業(yè)協(xié)助手術(shù)或在金融行業(yè)自動(dòng)執(zhí)行承銷過程。但是,法律法規(guī)和「機(jī)器人威脅論」可能會(huì)妨礙機(jī)器人領(lǐng)域的發(fā)展。還有設(shè)計(jì)和制造機(jī)器人需要相對(duì)較高的投資。
發(fā)展歷史:
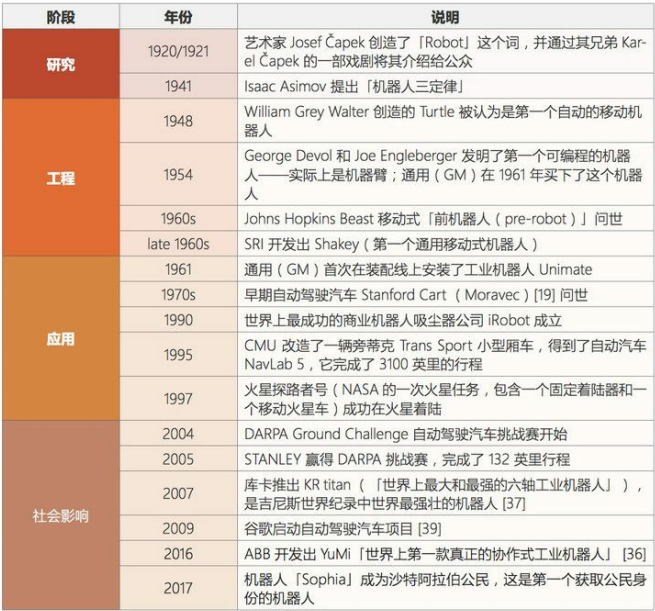
總的來說,人工智能領(lǐng)域的研究前沿正逐漸從搜索、知識(shí)和推理領(lǐng)域轉(zhuǎn)向機(jī)器學(xué)習(xí)、深度學(xué)習(xí)、計(jì)算機(jī)視覺和機(jī)器人領(lǐng)域。大多數(shù)早期技術(shù)至少已經(jīng)處于應(yīng)用階段了,而且其中一些已經(jīng)顯現(xiàn)出了社會(huì)影響力。一些新開發(fā)的技術(shù)可能仍處于工程甚至研究階段,但是我們可以看到不同階段之間轉(zhuǎn)移的速度變得越來越快。
2、機(jī)器學(xué)習(xí)基本介紹
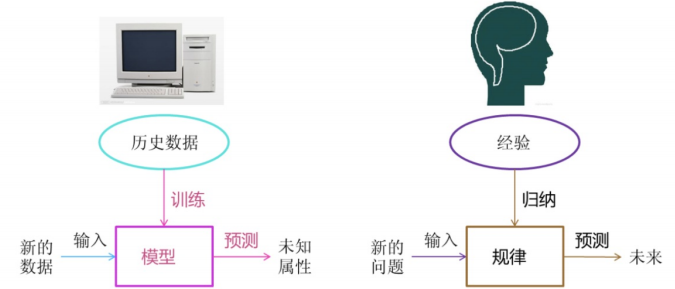
機(jī)器學(xué)習(xí)是從數(shù)據(jù)中自動(dòng)分析獲得模型,并利用模型對(duì)未知數(shù)據(jù)進(jìn)行預(yù)測。
2.1、機(jī)器學(xué)習(xí)工作流程

機(jī)器學(xué)習(xí)工作流程總結(jié)
- 獲取數(shù)據(jù)
- 數(shù)據(jù)基本處理
- 特征工程
- 機(jī)器學(xué)習(xí)(模型訓(xùn)練)
- 模型評(píng)估
結(jié)果達(dá)到要求,上線服務(wù);沒有達(dá)到要求,重新上面步驟。
2.1.1、數(shù)據(jù)集介紹
在數(shù)據(jù)集中一般:
- 一行數(shù)據(jù)我們稱為一個(gè)樣本
- 一列數(shù)據(jù)我們成為一個(gè)特征
- 有些數(shù)據(jù)有目標(biāo)值(標(biāo)簽值),有些數(shù)據(jù)沒有目標(biāo)值(如上表中,電影類型就是這個(gè)數(shù)據(jù)集的目標(biāo)值)
數(shù)據(jù)類型構(gòu)成:
- 數(shù)據(jù)類型一:特征值+目標(biāo)值(目標(biāo)值是連續(xù)的和離散的)
- 數(shù)據(jù)類型二:只有特征值,沒有目標(biāo)值
數(shù)據(jù)分割:
- 機(jī)器學(xué)習(xí)一般的數(shù)據(jù)集會(huì)劃分為兩個(gè)部分:
- 訓(xùn)練數(shù)據(jù):用于訓(xùn)練,構(gòu)建模型
- 測試數(shù)據(jù):在模型檢驗(yàn)時(shí)使用,用于評(píng)估模型是否有效
- 劃分比例:
- 訓(xùn)練集:70% 80% 75%
- 測試集:30% 20% 25%
2.1.2、數(shù)據(jù)基本處理
即對(duì)數(shù)據(jù)進(jìn)行缺失值、去除異常值等處理
2.1.3、特征工程
特征工程是使用專業(yè)背景知識(shí)和技巧處理數(shù)據(jù),使得特征能在機(jī)器學(xué)習(xí)算法上發(fā)揮更好的作用的過程。意義:會(huì)直接影響機(jī)器學(xué)習(xí)的效果
機(jī)器學(xué)習(xí)領(lǐng)域的大神Andrew Ng(吳恩達(dá))老師說“Coming up with features is difficult, time-consuming, requires expert knowledge.“Applied machine learning” is basically feature engineering. ” 譯:業(yè)界廣泛流傳:數(shù)據(jù)和特征決定了機(jī)器學(xué)習(xí)的上限,而模型和算法只是逼近這個(gè)上限而已。
特征工程包含內(nèi)容:
- 特征提取:將任意數(shù)據(jù)(如文本或圖像)轉(zhuǎn)換為可用于機(jī)器學(xué)習(xí)的數(shù)字特征。
- 特征預(yù)處理:通過一些轉(zhuǎn)換函數(shù)將特征數(shù)據(jù)轉(zhuǎn)換成更加適合算法模型的特征數(shù)據(jù)過程
- 特征降維:指在某些限定條件下,降低隨機(jī)變量(特征)個(gè)數(shù),得到一組“不相關(guān)”主變量的過程
2.1.4、機(jī)器學(xué)習(xí)
2.1.5、模型評(píng)估
2.2、獨(dú)立同分布
定義:
- 獨(dú)立:指數(shù)據(jù)集中的每個(gè)樣本都是相互獨(dú)立的,即一個(gè)樣本的出現(xiàn)不會(huì)影響其他樣本的出現(xiàn)概率。例如,在預(yù)測天氣的模型中,今天的天氣狀況與明天的天氣狀況在統(tǒng)計(jì)上是相互獨(dú)立的,今天是晴天并不影響明天是雨天的概率。
- 同分布:意味著所有樣本都服從相同的概率分布。例如,在手寫數(shù)字識(shí)別任務(wù)中,訓(xùn)練集中的所有數(shù)字圖像都來自于同一個(gè)總體分布,即它們具有相似的特征和統(tǒng)計(jì)特性,如數(shù)字的筆畫結(jié)構(gòu)、書寫風(fēng)格等。
作用:
- 簡化模型訓(xùn)練:獨(dú)立同分布假設(shè)使得機(jī)器學(xué)習(xí)算法可以更方便地對(duì)數(shù)據(jù)進(jìn)行處理和分析。在訓(xùn)練模型時(shí),由于每個(gè)樣本都是獨(dú)立的,我們可以將數(shù)據(jù)集看作是一個(gè)由多個(gè)獨(dú)立事件組成的集合,從而可以使用一些基于概率統(tǒng)計(jì)的方法來估計(jì)模型的參數(shù)。例如,在樸素貝葉斯算法中,就假設(shè)了特征之間是相互獨(dú)立的,這大大簡化了計(jì)算過程,使得模型能夠快速訓(xùn)練和預(yù)測。
- 提高模型泛化能力:當(dāng)數(shù)據(jù)滿足獨(dú)立同分布時(shí),模型在訓(xùn)練集上學(xué)習(xí)到的規(guī)律可以更好地推廣到未知的測試集上。因?yàn)橛?xùn)練集和測試集來自于同一個(gè)分布,所以模型在訓(xùn)練集上擬合的特征和模式也適用于測試集。如果數(shù)據(jù)不滿足獨(dú)立同分布,例如訓(xùn)練集和測試集的分布存在差異,那么模型可能會(huì)在訓(xùn)練集上表現(xiàn)良好,但在測試集上出現(xiàn)過擬合或性能下降的情況。
3、機(jī)器學(xué)習(xí)算法分類
根據(jù)數(shù)據(jù)集組成不同,可以把機(jī)器學(xué)習(xí)算法分為:
- 監(jiān)督學(xué)習(xí)
- 無監(jiān)督學(xué)習(xí)
- 半監(jiān)督學(xué)習(xí)
- 強(qiáng)化學(xué)習(xí)
3.1、監(jiān)督學(xué)習(xí)(Supervised Learning)
概念:監(jiān)督學(xué)習(xí)是一種機(jī)器學(xué)習(xí)方法,它使用標(biāo)記數(shù)據(jù)進(jìn)行訓(xùn)練,即數(shù)據(jù)集中的每個(gè)樣本都有一個(gè)對(duì)應(yīng)的標(biāo)簽或目標(biāo)值。模型通過學(xué)習(xí)輸入特征與輸出標(biāo)簽之間的映射關(guān)系,來對(duì)新的、未見過的數(shù)據(jù)進(jìn)行預(yù)測。
- 圖像識(shí)別:如識(shí)別手寫數(shù)字、識(shí)別照片中的物體類別等。通過大量標(biāo)注好的圖像數(shù)據(jù)訓(xùn)練模型,讓模型學(xué)習(xí)到不同圖像特征與物體類別的對(duì)應(yīng)關(guān)系,從而對(duì)新的圖像進(jìn)行分類。
- 語音識(shí)別:將語音信號(hào)轉(zhuǎn)換為文字或執(zhí)行語音指令。監(jiān)督學(xué)習(xí)模型可以學(xué)習(xí)語音特征與文字或指令之間的映射,實(shí)現(xiàn)語音到文本的轉(zhuǎn)換和語音交互功能。
- 醫(yī)療診斷:根據(jù)患者的癥狀、檢查結(jié)果等特征,預(yù)測疾病的類型或患者的病情嚴(yán)重程度。幫助醫(yī)生進(jìn)行輔助診斷,提高診斷的準(zhǔn)確性和效率。
- 金融風(fēng)險(xiǎn)預(yù)測:根據(jù)客戶的財(cái)務(wù)狀況、信用記錄等特征,預(yù)測客戶的違約風(fēng)險(xiǎn)或欺詐可能性。幫助金融機(jī)構(gòu)做出更明智的貸款和風(fēng)險(xiǎn)管理決策。
3.2、無監(jiān)督學(xué)習(xí)(Unsupervised Learning)
概念:無監(jiān)督學(xué)習(xí)使用未標(biāo)記的數(shù)據(jù),算法需要自己發(fā)現(xiàn)數(shù)據(jù)中的結(jié)構(gòu)和模式。
無監(jiān)督學(xué)習(xí)是一種機(jī)器學(xué)習(xí)方法,它處理的是未標(biāo)記的數(shù)據(jù)。在無監(jiān)督學(xué)習(xí)中,沒有給定明確的輸出標(biāo)簽或目標(biāo)值來指導(dǎo)模型的學(xué)習(xí)。相反,模型需要自己從數(shù)據(jù)的結(jié)構(gòu)、分布和模式中發(fā)現(xiàn)有價(jià)值的信息。例如,想象有一堆形狀、顏色各異的石頭,無監(jiān)督學(xué)習(xí)就像是在沒有任何預(yù)先定義的類別(如 “圓形石頭”“方形石頭”)的情況下,嘗試去找出這些石頭可能存在的分組規(guī)律或者其他內(nèi)在模式。
- 聚類算法:
- K - 均值聚類(K - Means Clustering):將數(shù)據(jù)劃分為 K 個(gè)簇。首先隨機(jī)選擇 K 個(gè)中心點(diǎn),然后將每個(gè)數(shù)據(jù)點(diǎn)分配到距離最近的中心點(diǎn)所在的簇,接著更新中心點(diǎn),重復(fù)這個(gè)過程直到簇的劃分不再變化。例如,將用戶根據(jù)消費(fèi)行為聚類為不同的群體。
- 層次聚類(Hierarchical Clustering):構(gòu)建一個(gè)聚類層次結(jié)構(gòu),有凝聚式(從每個(gè)數(shù)據(jù)點(diǎn)作為一個(gè)單獨(dú)的簇開始,逐步合并)和分裂式(從所有數(shù)據(jù)點(diǎn)在一個(gè)簇開始,逐步分裂)兩種方式。可以用于生物分類等領(lǐng)域
- 降維算法:
3.3、半監(jiān)督學(xué)習(xí)(Semi - supervised Learning)
概念:介于監(jiān)督學(xué)習(xí)和無監(jiān)督學(xué)習(xí)之間,同時(shí)使用少量的標(biāo)記數(shù)據(jù)和大量的未標(biāo)記數(shù)據(jù)來訓(xùn)練模型。例如,在圖像分類任務(wù)中,只有少量圖像有準(zhǔn)確的類別標(biāo)簽,結(jié)合大量未標(biāo)記圖像來提高模型的性能。
算法示例:半監(jiān)督支持向量機(jī)(Semi - supervised SVM),它利用未標(biāo)記數(shù)據(jù)來幫助構(gòu)建更好的決策邊界,提高分類的準(zhǔn)確性。
3.4、強(qiáng)化學(xué)習(xí)(Reinforcement Learning)
概念:智能體(agent)在環(huán)境(environment)中采取一系列行動(dòng)(action),根據(jù)環(huán)境反饋的獎(jiǎng)勵(lì)(reward)信號(hào)來學(xué)習(xí)最優(yōu)的行為策略。
算法示例:
- Q - 學(xué)習(xí)(Q - Learning):智能體通過學(xué)習(xí)一個(gè) Q - 函數(shù)來估計(jì)在某個(gè)狀態(tài)下采取某個(gè)行動(dòng)的長期獎(jiǎng)勵(lì)。例如,在機(jī)器人導(dǎo)航中,機(jī)器人通過不斷嘗試不同的移動(dòng)路徑,根據(jù)是否到達(dá)目標(biāo)位置獲得獎(jiǎng)勵(lì),從而學(xué)習(xí)最佳的導(dǎo)航策略。
- 深度 Q - 網(wǎng)絡(luò)(Deep Q - Network,DQN):結(jié)合了深度學(xué)習(xí)和 Q - 學(xué)習(xí),使用神經(jīng)網(wǎng)絡(luò)來近似 Q - 函數(shù),用于處理高維的狀態(tài)空間和復(fù)雜的決策問題,如游戲中的智能角色控制。
4、機(jī)器學(xué)習(xí)模型評(píng)估
定義:模型評(píng)估是指在機(jī)器學(xué)習(xí)和數(shù)據(jù)分析領(lǐng)域,使用各種定量和定性的方法來衡量模型性能的過程。其目的是了解模型在給定任務(wù)(如分類、回歸、聚類等)上的有效性、準(zhǔn)確性、穩(wěn)定性和泛化能力等諸多方面的表現(xiàn)。
重要性:通過模型評(píng)估,可以確定模型是否達(dá)到了預(yù)期的性能標(biāo)準(zhǔn),是否適合部署到實(shí)際應(yīng)用場景中。同時(shí),評(píng)估結(jié)果還可以為模型的選擇、調(diào)整和優(yōu)化提供依據(jù),幫助開發(fā)人員和數(shù)據(jù)科學(xué)家提高模型的質(zhì)量。
按照數(shù)據(jù)集的目標(biāo)值不同,可以把模型評(píng)估分為分類模型評(píng)估、回歸模型評(píng)估。
4.1、分類模型評(píng)估
分類模型的評(píng)估指標(biāo)包括:準(zhǔn)確率(Accuracy)、精確率(Precision)、召回率(Recall)、F1 - 分?jǐn)?shù)(F1 - Score)
4.2、回歸模型評(píng)估
回歸模型的評(píng)估指標(biāo)包括:均方誤差(Mean Squared Error,MSE)、均方根誤差(Root Mean Squared Error,RMSE)、平均絕對(duì)誤差(Mean Absolute Error,MAE)
4.3、模型評(píng)價(jià)
模型評(píng)估用于評(píng)價(jià)訓(xùn)練好的的模型的表現(xiàn)效果,其表現(xiàn)效果大致可以分為兩類:過擬合、欠擬合。
4.3.1、欠擬合
4.3.2、過擬合
5、深度學(xué)習(xí)基本介紹
深度學(xué)習(xí)是機(jī)器學(xué)習(xí)的一個(gè)分支領(lǐng)域,它是一種基于對(duì)數(shù)據(jù)進(jìn)行表征學(xué)習(xí)的方法。通過構(gòu)建具有很多層(包括輸入層、隱藏層和輸出層)的神經(jīng)網(wǎng)絡(luò)模型,自動(dòng)從大量的數(shù)據(jù)中學(xué)習(xí)復(fù)雜的模式和特征表示。例如,在圖像識(shí)別中,深度學(xué)習(xí)模型可以從大量的圖像數(shù)據(jù)中學(xué)習(xí)到不同物體的特征,如貓的形狀、顏色、紋理等,從而能夠準(zhǔn)確地判斷一張新圖像中是否有貓。
- 核心概念

 浙公網(wǎng)安備 33010602011771號(hào)
浙公網(wǎng)安備 33010602011771號(hào)