TIDB執行計劃
1、explain
使用 EXPLAIN 可查看 TiDB 執行某條語句時選用的執行計劃。也就是說,TiDB 在考慮上數百或數千種可能的執行計劃后,最終認定該執行計劃消耗的資源最少、執行的速度最快。EXPLAIN 實際不會執行查詢,EXPLAIN ANALYZE 可用于實際執行查詢并顯示執行計劃,如果 TiDB 所選的執行計劃非最優,可用 EXPLAIN 或 EXPLAIN ANALYZE 來進行診斷。
2、EXPLAIN返回結果介紹
EXPLAIN SELECT /*+ INL_JOIN(t2) */ * FROM t1 JOIN t2 ON t1.a = t2.a;
+---------------------------------+----------+-----------+-----------------------+-----------------------------------------------------------------------------------------------------------------+ | id | estRows | task | access object | operator info | +---------------------------------+----------+-----------+-----------------------+-----------------------------------------------------------------------------------------------------------------+ | IndexJoin_12 | 12487.50 | root | | inner join, inner:IndexLookUp_11, outer key:test.t1.a, inner key:test.t2.a, equal cond:eq(test.t1.a, test.t2.a) | | ├─TableReader_24(Build) | 9990.00 | root | | data:Selection_23 | | │ └─Selection_23 | 9990.00 | cop[tikv] | | not(isnull(test.t1.a)) | | │ └─TableFullScan_22 | 10000.00 | cop[tikv] | table:t1 | keep order:false, stats:pseudo | | └─IndexLookUp_11(Probe) | 12487.50 | root | | | | ├─Selection_10(Build) | 12487.50 | cop[tikv] | | not(isnull(test.t2.a)) | | │ └─IndexRangeScan_8 | 12500.00 | cop[tikv] | table:t2, index:ia(a) | range: decided by [eq(test.t2.a, test.t1.a)], keep order:false, stats:pseudo | | └─TableRowIDScan_9(Probe) | 12487.50 | cop[tikv] | table:t2 | keep order:false, stats:pseudo | +---------------------------------+----------+-----------+-----------------------+-----------------------------------------------------------------------------------------------------------------+
EXPLAIN 的返回結果包含以下字段:
id:為算子名,或執行 SQL 語句需要執行的子任務。estRows:為顯示 TiDB 預計會處理的行數。該預估數可能基于字典信息(例如訪問方法基于主鍵或唯一鍵),或基于CMSketch或直方圖等統計信息估算而來。task:顯示算子在執行語句時的所在位置。access-object:顯示被訪問的表、分區和索引。顯示的索引為部分索引。尤其是在有組合索引的情況下,該字段顯示的信息很有參考意義。operator info:顯示訪問表、分區和索引的其他信息。
2.1、算子(id)
算子是為返回查詢結果而執行的特定步驟。真正執行掃表(讀盤或者讀 TiKV Block Cache)操作的算子有如下幾類:
- TableFullScan:全表掃描。
- TableRangeScan:帶有范圍的表數據掃描。
- TableRowIDScan:TableRowIDScan 是一種數據掃描算子,在 TiDB 等數據庫中用于直接通過行 ID 來獲取表中的數據行,這種方式比全表掃描或者通過復雜的索引查找更加直接和高效
- RowID:在 TiDB 中,行 ID(Row ID)是用于唯一標識表中每一行數據的標識符。它類似于主鍵的作用,是數據庫內部用于管理和定位行數據的重要依據。每一行都有一個唯一的行 ID,這個 ID 在整個表的范圍內是獨一無二的,就像每個人都有一個獨一無二的身份證號碼一樣。行 ID 通常是由數據庫系統自動生成的,并不是表中的某個字段。行 ID 最重要的作用是能夠實現對數據行的快速定位。
- IndexFullScan(可相對提升效率):另一種“全表掃描”,掃的是索引數據,不是表數據。
- IndexRangeScan:帶有范圍的索引數據掃描操作。
TiDB 會匯聚 TiKV/TiFlash 上掃描的數據或者計算結果,這種“數據匯聚”算子目前有如下幾類:
- TableReader:TableReader 是一種用于讀取表數據的操作。TableReader 通常會和其他操作(如TableFullScan、TableRangeScan 、IndexScan、Selection 等)協同工作。它可以接收來自其他操作的數據請求,例如,在經過 IndexScan 獲取了一些索引相關的數據后,如果還需要獲取表中的其列他數據(可能涉及回表操作),TableReader 就會被調用,從表中讀取完整的數據行。
- IndexReader(可相對提升效率):將 TiKV 上底層掃表算子 IndexFullScan 或 IndexRangeScan 得到的數據進行匯總。
- IndexLookUp(通常與回表有關):在 TiDB 執行計劃中,IndexLookUp 算子用于通過索引查找數據,并獲取相關的行記錄。它結合了索引掃描和根據索引結果獲取完整數據行的操作。IndexLookUp 算子在執行過程中常常會觸發回表,導致帶來額外的開銷,影響性能。當通過索引掃描找到滿足條件的索引項后,如果查詢需要獲取除索引列之外的其他列信息,就會根據索引項中的主鍵值或其他行標識信息回到表中獲取完整的行記錄,這個過程就是回表。
- 例如,在一個 “員工表” 中有 “部門名稱” 二級索引,執行查詢
SELECT * FROM employees WHERE department_name = 'IT'時,IndexLookUp 會先通過 “部門名稱” 索引找到符合條件的索引項(包含部門名稱和對應的員工主鍵),然后因為查詢要求獲取所有列(*),所以需要回表,根據主鍵獲取員工姓名、工資等其他列的信息。
- 例如,在一個 “員工表” 中有 “部門名稱” 二級索引,執行查詢
- IndexMerge:和
IndexLookupReader類似,可以看做是它的擴展,可以同時讀取多個索引的數據,有多個 Build 端,一個 Probe 端。執行過程也很類似,先匯總所有 Build 端 TiKV 掃描上來的 RowID,再去 Probe 端上根據這些 RowID 精確地讀取 TiKV 上的數據。Build 端是IndexFullScan或IndexRangeScan類型的算子,Probe 端是TableRowIDScan類型的算子。 Point_Get和Batch_Point_Get:TiDB 直接從主鍵或唯一鍵檢索數據時會使用Point_Get或Batch_Point_Get算子。這兩個算子比IndexLookup更有效率。
其他算子說明:
- Projection:在 TiDB 的執行計劃中,Projection 算子(投影算子)主要用于選擇查詢結果中的列,并且可以對這些列進行一些簡單的表達式計算或者重命名操作。它的作用是確定最終返回給用戶的列集合。
- Top:TOP 算子用于從查詢結果的頂部獲取指定數量的行。它主要用于限制結果集的大小,返回最符合條件的前面若干行數據。例如,在一個銷售數據表中,想要獲取銷售額最高的前 10 名員工的記錄,就可以使用類似 TOP 算子的功能。
- Limit:LIMIT 算子的主要優點是能夠有效地控制返回給用戶的數據量,這在分頁查詢等場景中非常有用。LIMIT 算子不僅可以實現類似 TOP 算子獲取前面若干行的功能(當偏移量為 0 時),還能實現從中間某一行開始獲取指定行數的功能。
- HashJoin:HashJoin 是一種數據庫中用于表連接(JOIN)的操作算法。它主要是基于哈希(Hash)原理來高效地合并兩個表中的數據。包括Build階段和Probe階段,Build階段會選擇驅動表并構建哈希表,Probe階段會掃描被驅動表,將兩張表進行連接。
- Selection(篩選):篩選操作,會以上一步得到的數據作為輸入,根據給定的條件(如
WHERE子句)進一步篩選數據。
2.2、task
目前 TiDB 的計算任務分為兩種不同的 task:cop task(TIKV執行)、root task(TIDB執行)和 tiflash。Cop task 是指使用 TiKV 中的 Coprocessor 執行的計算任務,root task 是指在 TiDB 中執行的計算任務。
SQL 優化的目標之一是將計算盡可能地下推到 TiKV 中執行,避免在 root 中執行計算。TiKV 中的 Coprocessor 能支持大部分 SQL 內建函數(包括聚合函數和標量函數)、SQL LIMIT 操作、索引掃描和表掃描。
2.3、operator info
EXPLAIN 返回結果中 operator info 列可顯示諸如條件下推等信息。operator info 結果各字段解釋如下:
range: [1,1]表示查詢的WHERE字句 (a = 1) 被下推到了 TiKV,對應的 task 為cop[tikv]。keep order:false表示該查詢的語義不需要 TiKV 按順序返回結果。如果查詢指定了排序(例如SELECT * FROM t WHERE a = 1 ORDER BY id),該字段的返回結果為keep order:true。stats:pseudo表示estRows顯示的預估數可能不準確。
3、算子的執行順序
算子的結構是樹狀的,在查詢執行過程中,一般都是子節點先執行。在 TiDB 執行計劃的樹形結構中,數據通常是從葉子節點(子節點)向根節點(父節點)流動的。這意味著子節點的操作會先執行,其產生的結果作為輸入傳遞給父節點進行后續處理。
這種從子節點到父節點的執行順序也是為了優化查詢執行過程。通過先在子節點進行局部的數據篩選、排序等操作,可以減少傳遞給父節點的數據量,從而提高整個查詢的效率。例如,在一個復雜的多表查詢中,子節點的選擇(Selection)和投影(Projection)操作可以預先過濾掉不需要的數據,使得后續的連接操作(父節點)在較小的數據量上進行,降低了計算資源的消耗和執行時間。
3.1、Build和Probe操作
Build 總是先于 Probe 執行,并且 Build 總是出現在 Probe 前面。即如果一個算子有多個子節點,子節點 ID 后面有 Build 關鍵字的算子總是先于有 Probe 關鍵字的算子執行。TiDB 在展現執行計劃的時候,Build 端總是第一個出現,接著才是 Probe 端。
- Build操作:在 Hash Join 的執行計劃中,Build 操作主要是構建一個哈希表。這個哈希表的構建基于連接操作中的一張表(通常是較小的表,也稱為驅動表)。
- 例如,在一個簡單的查詢
SELECT * FROM table1 JOIN table2 ON table1.custId= table2.custId中,如果選擇 table1 作為 Build 表,TiDB 會先掃描 table1 的數據,根據連接鍵(custId)的值,通過特定的哈希函數計算哈希值。然后,將custId以及對應的table1表中的行數據(或者行數據的引用)存儲到哈希表中。這個哈希表的結構有助于后續快速查找匹配的行。
- 例如,在一個簡單的查詢
- Probe操作:Probe 階段是在 Build 階段構建好哈希表之后才開始的。Probe 操作主要是針對連接操作中的另一張表(被驅動表,在上述例子中是 table2)。TiDB 會掃描 table2 的數據,對于每一行中的連接鍵(custId)的值,使用相同的哈希函數計算哈希值,在 Build 階段構建的哈希表中進行查找,如果找到匹配的鍵值,就將兩行數據(來自 table1 和 table2)進行連接組合,生成連接后的結果。所以,Probe 操作依賴于 Build 階段構建的哈希表,必須在 Build 之后才能執行。
4、統計信息的健康度
EXPLAIN ANALYZE 執行時的 actRows 可能跟 estRows 差別很大,即跟實際值差別很大,可以先執行 ANALYZE TABLE 再執行 EXPLAIN ANALYZE,預估數與實際數會更接近。
ANALYZE TABLE xxx;
當在執行計劃中看到 stats:pseudo,即表示統計信息健康程度不夠,就可執行 anlyze table xxx語句了。
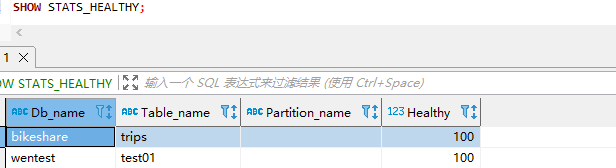
除 ANALYZE TABLE 外,達到 tidb_auto_analyze_ratio 閾值后,TiDB 會自動在后臺重新生成統計數據。若要查看 TiDB 有多接近該閾值(即 TiDB 判斷統計數據有多健康),可執行 SHOW STATS_HEALTHY 語句。
4、MPP模式(切分為多個 MPP片段進行查詢)
TiDB 支持使用 MPP 模式來執行查詢,TiDB 的 MPP(Massively Parallel Processing)模式是一種大規模并行處理架構,旨在通過多個節點并行執行任務來提高數據處理和查詢的性能與效率。
架構原理:
- 分布式存儲與計算:TiDB 采用分布式架構,數據分散存儲在多個 TiKV 節點上。在 MPP 模式下,當執行查詢或其他數據處理任務時,TiDB 會將任務分解并分發到多個節點上并行執行。每個節點負責處理一部分數據,然后將結果匯總返回。
- 數據分片與并行處理:數據在 TiKV 節點上通過 Region 進行分片,每個 Region 包含一定范圍的數據。TiDB 根據查詢條件確定需要訪問的 Region,并將查詢任務發送到對應的 TiKV 節點。這些節點可以同時處理各自負責的 Region 數據,實現并行計算。
注意,MPP 模式通常只會對有 TiFlash 副本的表生效。(在某些特定的場景或配置下,即使沒有 TiFlash 副本,TiDB 也可能會嘗試使用類似 MPP 的執行方式。例如在執行一些分布式的 JOIN 操作或者 UNION ALL 操作時,TiDB 可能會在 TiKV 節點之間進行數據的交換和并行處理,但這種情況與嚴格意義上基于 TiFlash 的 MPP 模式有所不同,其并行處理的程度和效果可能會受到一定限制。)
示例:
ALTER TABLE t1 set tiflash replica 1; ANALYZE TABLE t1; SET tidb_allow_mpp = 1;
7、Optimizer Hints控制執行計劃
TiDB 支持 Optimizer Hints 語法,它基于 MySQL 5.7 中介紹的類似 comment 的語法,例如 /*+ HINT_NAME(t1, t2) */,當 TiDB 優化器選擇的不是最優查詢計劃時,可以使用 Optimizer Hints 指定使用哪個執行計劃。
7.1、語法
Optimizer Hints 不區分大小寫,通過 /*+ ... */ 注釋的形式跟在 SELECT、UPDATE 或 DELETE 關鍵字的后面,如果注釋不是跟在指定的關鍵字后,會被當作是普通的 MySQL comment,注釋不會生效。INSERT 關鍵字后不支持 Optimizer Hints。多個不同的 Hint 之間需用逗號隔開。
示例:
SELECT /*+ USE_INDEX(t1, idx1), HASH_AGG(), HASH_JOIN(t1) */ count(*) FROM t t1, t t2 WHERE t1.a = t2.b;
如果 Optimizer Hints 包含語法錯誤或不完整,查詢語句不會報錯,而是按照沒有 Optimizer Hints 的情況執行。如果 Hint 不適用于當前語句,TiDB 會返回 Warning,用戶可以在查詢結束后通過 Show Warnings 命令查看具體信息。
7.2、 Hint分類
TiDB 目前支持的 Optimizer Hints 根據生效范圍的不同可以劃分為兩類:
- 第一類是在查詢塊范圍生效的 Hint,例如
/*+ HASH_AGG() */; - 第二類是在整個查詢范圍生效的 Hint,例如
/*+ MEMORY_QUOTA(1024 MB)*/。
每條語句中每一個查詢和子查詢都對應著一個不同的查詢塊,每個查詢塊有自己對應的名字。以下面這條語句為例:
SELECT * FROM (SELECT * FROM t) t1, (SELECT * FROM t) t2;
該查詢語句有 3 個查詢塊,最外面一層 SELECT 所在的查詢塊的名字為 sel_1,兩個 SELECT 子查詢的名字依次為 sel_2 和 sel_3。其中數字序號根據 SELECT 出現的位置從左到右計數。TIDB規定 select 查詢塊以 sel 開頭,DELETE 和 UPDATE 分別以 del、upd 開頭,如果分別用 DELETE 和 UPDATE 查詢替代上述第一個 SELECT 查詢,則對應的查詢塊名字分別為 del_1 和 upd_1。
7.2.1、塊范圍生效的 Hint
這類 Hint 可以跟在查詢語句中任意 SELECT、UPDATE 或 DELETE 關鍵字的后面。通過在 Hint 中使用查詢塊名字可以控制 Hint 的生效范圍,以及準確標識查詢中的每一個表(有可能表的名字或者別名相同),方便明確 Hint 的參數指向。若不顯式地在 Hint 中指定查詢塊,Hint 默認作用于當前查詢塊。以如下查詢為例:
SELECT /*+ HASH_JOIN(@sel_1 t1@sel_1, t3) */ * FROM (SELECT t1.a, t1.b FROM t t1, t t2 WHERE t1.a = t2.a) t1, t t3 WHERE t1.b = t3.b;
該 Hint 在 sel_1 這個查詢塊中生效,參數分別為 sel_1 中的 t1 表(sel_2 中也有一個 t1 表)和 t3 表。
如上例所述,在 Hint 中使用查詢塊名字的方式有兩種:
- 第一種是作為 Hint 的第一個參數,與其他參數用空格隔開。除
QB_NAME外,本節所列的所有 Hint 除自身明確列出的參數外都有一個隱藏的可選參數@QB_NAME,通過使用這個參數可以指定該 Hint 的生效范圍; - 第二種在 Hint 中使用查詢塊名字的方式是在參數中的某一個表名后面加
@QB_NAME,如上面的 t1@sel_1 用法,用以明確指出該參數是哪個查詢塊中的表。
7.3、QB_NAME(指定查詢塊的名稱)
當查詢語句是包含多層嵌套子查詢的復雜語句時,識別某個查詢塊的序號和名字很可能會出錯,Hint QB_NAME 可以方便我們使用查詢塊。QB_NAME 是 Query Block Name 的縮寫,用于為某個查詢塊指定新的名字,同時查詢塊原本默認的名字依然有效。例如:
SELECT /*+ QB_NAME(QB1) */ * FROM (SELECT * FROM t) t1, (SELECT * FROM t) t2;
這條 Hint 將最外層 SELECT 查詢塊的命名為 QB1,此時 QB1 和默認名稱 sel_1 對于這個查詢塊來說都是有效的。(注意,如果指定的 QB_NAME 為 sel_2,并且不給原本 sel_2 對應的第二個查詢塊指定新的 QB_NAME,則第二個查詢塊的默認名字 sel_2 會失效。)

 浙公網安備 33010602011771號
浙公網安備 33010602011771號