ElasticSearch的基本操作
1、索引相關操作(類似數據庫)
1.1、創建索引
對比關系型數據庫,創建索引就等同于創建數據庫。
向 ES 服務器發 PUT 請求 :http://127.0.0.1:9200/shopping,shopping 即為索引名。
請求后,服務器返回響應如下:

說明如下:
{
"acknowledged"【響應結果】: true, # true 操作成功
"shards_acknowledged"【分片結果】: true, # 分片操作成功
"index"【索引名稱】: "shopping"
}
# 注意:創建索引庫的分片數默認 1 片,在 7.0.0 之前的 Elasticsearch 版本中,默認 5 片
如果重復添加索引,會返回錯誤信息,如下:

1.2、查詢索引
1.2.1、查詢所有索引
這里請求路徑中的_cat 表示查看的意思,indices 表示索引,所以整體含義就是查看當前 ES 服務器中的所有索引,就好像 MySQL 中的 show tables 的感覺。
當 ES服務器中沒有索引時,響應結果如下:

在成功創建索引后,再查詢所有索引,可以看到以下示例結果:

1.2.2、查詢單個索引

返回結果說明如下:
{
"shopping"【索引名】: {
"aliases"【別名】: {},
"mappings"【映射】: {},
"settings"【設置】: {
"index"【設置 - 索引】: {
"creation_date"【設置 - 索引 - 創建時間】: "1614265373911",
"number_of_shards"【設置 - 索引 - 主分片數量】: "1",
"number_of_replicas"【設置 - 索引 - 副分片數量】: "1",
"uuid"【設置 - 索引 - 唯一標識】: "eI5wemRERTumxGCc1bAk2A",
"version"【設置 - 索引 - 版本】: {
"created": "7080099"
},
"provided_name"【設置 - 索引 - 名稱】: "shopping"
}
}
}
}
1.3、刪除索引


2、文檔相關操作(類似行)
2.1、創建文檔
這里的文檔可以類比為關系型數據庫中的表數據,添加的數據格式為 JSON 格式。
創建文檔,并添加數據,向 ES 服務器發 POST 請求 :http://127.0.0.1:9200/shopping/_doc,shopping 指的是索引名。如果在創建文檔時,該索引不存在,ES 會默認幫你新建索引。
請求體內容為:
{
"title":"小米手機",
"category":"小米",
"images":"http://www.gulixueyuan.com/xm.jpg",
"price":3999.00
}

(此處發送請求的方式必須為 POST,不能是 PUT,否則會報錯。)

結果說明如下:
{
"_index"【索引】: "shopping",
"_type"【類型-文檔】: "_doc",
"_id"【唯一標識】: "Xhsa2ncBlvF_7lxyCE9G", #可以類比為 MySQL 中的主鍵,隨機生成
"_version"【版本】: 1,
"result"【結果】: "created", #這里的 create 表示創建成功
"_shards"【分片】: {
"total"【分片 - 總數】: 2,
"successful"【分片 - 成功】: 1,
"failed"【分片 - 失敗】: 0
},
"_seq_no": 0,
"_primary_term": 1
}

2.2、查看文檔
2.2.1、查詢指定id文檔
查看文檔時,可以指明文檔的唯一性標識,類似于 MySQL 中數據的主鍵查詢。向 ES 服務器發 GET 請求 :http://127.0.0.1:9200/shopping/_doc/1001,響應結果如下:

2.2.2、查詢所有文檔
向 ES 服務器發 GET 請求 :http://127.0.0.1:9200/shopping/_search,響應結果如下:

2.3、修改文檔
2.3.1、全量修改
修改文檔和新增文檔的 URL 地址一樣,如果請求體變化,會將原有的數據內容全部覆蓋。向 ES 服務器發 POST 請求 :http://127.0.0.1:9200/shopping/_doc/1001,請求體內容為:
{ "title":"華為手機", "category":"華為", "images":"http://www.gulixueyuan.com/hw.jpg", "price":4999.00 }

響應結果如下:

修改后再次查詢該文檔內容,可以發現,文檔已經被修改。
2.3.2、局部修改(修改部分字段)
修改數據時,也可以只修改某一給條數據的局部信息,向 ES 服務器發 POST 請求 :http://127.0.0.1:9200/shopping/_update/1001,請求體內容為:
{ "doc": { "title": "修改后title", "price":3000.00 } }

響應結果如下:

修改后再次查詢該文檔內容,可以發現,該文檔對應的字段已經被修改成功。
2.4、刪除文檔
2.4.1、刪除指定id文檔
刪除文檔向 ES 服務器發 DELETE 請求 :http://127.0.0.1:9200/shopping/_doc/1001,響應結果如下:

響應結果說明如下:
刪除后再查詢當前文檔信息,響應結果如下:

如果刪除一個不存在的文檔,結果會提示not found。
2.4.2、根據條件刪除文檔
一般刪除數據都是根據文檔的唯一性標識進行刪除,實際操作時,也可以根據條件對多條數據進行刪除。
比如有以下多個文檔:
{
"title":"小米手機",
"category":"小米",
"images":"http://www.gulixueyuan.com/xm.jpg",
"price":4000.00
}
{
"title":"華為手機",
"category":"華為",
"images":"http://www.gulixueyuan.com/hw.jpg",
"price":4000.00
}
向 ES 服務器發 POST 請求 :http://127.0.0.1:9200/shopping/_delete_by_query,請求體內容為:
{
"query":{
"match":{
"price":4000.00
}
}
}
刪除成功后,服務器響應結果:

響應結果說明如下:
{
"took"【耗時】: 175,
"timed_out"【是否超時】: false,
"total"【總數】: 2,
"deleted"【刪除數量】: 2,
"batches": 1,
"version_conflicts": 0,
"noops": 0,
"retries": {
"bulk": 0,
"search": 0
},
"throttled_millis": 0,
"requests_per_second": -1.0,
"throttled_until_millis": 0,
"failures": []
}
3、映射關系(mapping)
3.1、默認映射(動態映射 Dynamic mapping)
在Elasticsearch中,動態映射是指 Elasticsearch 根據數據自動創建字段和類型的過程。默認情況下,當你索引一個文檔,Elasticsearch會檢查文檔的字段,并相應地更新映射。
動態映射可以通過以下方式進行控制:
1)使用dynamic參數:
true(默認值):允許動態添加新字段。false:不允許動態添加新字段,但會繼續索引現有字段。strict:如果嘗試動態添加新字段,則索引操作將失敗。
2)使用dynamic_templates可自定義動態添加字段和映射的規則。
示例,以下是一個索引設置,它禁止動態添加新字段,但允許現有字段被動態映射:
PUT my_index { "mappings": { "dynamic": false, "properties": { "name": { "type": "text" }, "date": { "type": "date" } } } }
以下是使用dynamic_templates的例子,以下配置指定了對所有字符串字段使用keyword子字段的動態映射:
PUT my_index { "mappings": { "dynamic_templates": [ { "strings_as_keywords": { "match_mapping_type": "string", "mapping": { "type": "keyword" } } } ], "properties": { "name": { "type": "text" }, "date": { "type": "date" } } } }
如果你嘗試索引一個新的文檔,并且文檔中包含了沒有在映射中定義的字段,Elasticsearch將使用默認的規則或你自定義的規則來確定字段的類型并創建映射。如果你想要改變這些默認的映射行為,可以在創建索引時指定該索引的映射關系。
3.2、創建映射關系
創建mapping映射類似于我們創建表結構(規定字段什么類型,多長等基本信息),而映射關系會規定索引中的字段是否可以分詞、是否可以索引查詢等信息。
映射數據說明:
- 字段名
- type:類型,Elasticsearch 中支持的數據類型非常豐富,說幾個關鍵的:
- String 類型,又分兩種:1)text:可分詞;2)keyword:不可分詞,數據會作為完整字段進行匹配
- Numerical:數值類型,分兩類基本數據類型:long、integer、short、byte、double、float、half_float。浮點數的高精度類型:scaled_float
- Date:日期類型
- Array:數組類型
- Object:對象
- index:是否索引,即該字段是否可被搜索出來。默認為 true,也就是說默認所有字段都會被索引。true:字段會被索引,則可以用來進行搜索,false:字段不會被索引,不能用來搜索
- store:是否將數據進行獨立存儲,默認為 false。原始的文本會存儲在_source 里面,默認情況下其他提取出來的字段都不是獨立存儲的,是從_source 里面提取出來的。當然你也可以獨立的存儲某個字段,只要設置"store": true 即可,獲取獨立存儲的字段要比從_source 中解析快得多,但是也會占用更多的空間,所以要根據實際業務需求來設置。
- analyzer:分詞器
示例,先創建索引 PUT http://127.0.0.1:9200/user,然后發出帶 json 請求體的 put 請求創建映射關系 PUT http://127.0.0.1:9200/user/_mapping,請求體如下:
{ "properties":{ "name":{ "type":"text", // text 文本 可以分詞 "index":true // 可以索引查詢 }, "sex":{ "type":"keyword", // 不可以分詞 "index":true }, "tel":{ "type":"keyword", // 不可以分詞 "index":false //不可以索引查詢 } } }
創建示例文檔 POST http://127.0.0.1:9200/user/_doc/1001
{ "name":"小花", "sex":"男", "tel":"123456" }
此時我們做下查詢,GET http://127.0.0.1:9200/user/_search ,請求體:
{ "query":{ "match":{ "sex":"男的" } } }
會發現沒有查到數據,因為 mapping 限制的 sex 為 keyword,所以 sex 查詢條件不會被分詞也就匹配不到文檔數據。
再發出請求 GET http://127.0.0.1:9200/user/_search,請求體:
{ "query":{ "match":{ "tel":"123456" } } }
響應如下:
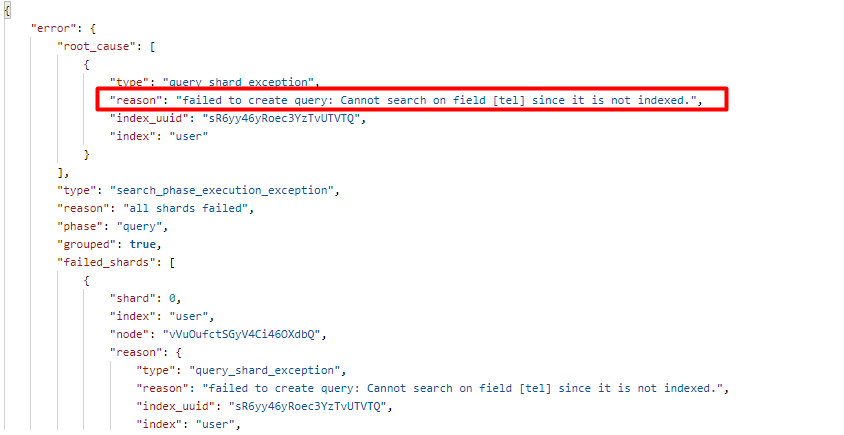
可以發信息查詢報錯了,因為映射關系中配置 tel 的 index 為 false,即沒有索引不支持查詢。
3.2.1、ES設置字段既可以精準查詢又可以分詞查詢
在ES中,精準查詢的字段必須不為text類型,因為text類型的字段在查詢中時可以被es進行分詞查詢的,這與精準查詢矛盾。
如果一個字段我們既想要可以精準查詢,又想要可以分詞查詢,此時我們可以通過定義不同的字段類型來實現同一個字段既可以精準查詢又可以分詞查詢。具體來說,你可以使用keyword子字段配合文本字段來實現這一需求。
以下是一個創建索引的例子,其中展示了如何定義一個可精準查詢同時也可以分詞查詢的字段:
PUT my_index { "mappings": { "properties": { "my_field": { "type": "text", "fields": { "keyword": { "type": "keyword", "ignore_above": 256 } } } } } }
在這個例子中,my_field是一個文本字段,可以進行分詞查詢。同時,它還有一個my_field.keyword的子字段,這個子字段是keyword類型,可以進行精準查詢。
精準查詢示例(精確匹配整個詞匯):
GET my_index/_search { "query": { "term": { "my_field.keyword": { "value": "exactValue" } } } }
分詞查詢示例(分析詞匯進行匹配):
GET my_index/_search { "query": { "match": { "my_field": "part of value" } } }
這樣,同一個字段my_field既可以進行精確查詢,也可以進行分詞查詢。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號