數(shù)據(jù)庫的相關(guān)概念
1、數(shù)據(jù)庫的基本概念
1.1、數(shù)據(jù)庫的基本概念
數(shù)據(jù)庫(Database,簡(jiǎn)稱DB)是按照數(shù)據(jù)結(jié)構(gòu)來組織、存儲(chǔ)和管理數(shù)據(jù)的倉庫。我們也可以將數(shù)據(jù)存儲(chǔ)在文件中或者是內(nèi)存中,但是內(nèi)存存儲(chǔ)的數(shù)據(jù)都是臨時(shí)的,在服務(wù)器關(guān)機(jī)后就會(huì)被清除,而文件的讀寫數(shù)據(jù)速度相對(duì)較慢。所以,我們更多的是使用數(shù)據(jù)庫來存儲(chǔ)數(shù)據(jù)。其實(shí)數(shù)據(jù)庫就是一個(gè)文件系統(tǒng)。
2、數(shù)據(jù)庫的三種模型(關(guān)系模型、層次模型、網(wǎng)狀模型)
數(shù)據(jù)庫按照數(shù)據(jù)結(jié)構(gòu)來組織、存儲(chǔ)和管理數(shù)據(jù),實(shí)際上,數(shù)據(jù)庫一共有三種模型:
- 層次模型
- 網(wǎng)狀模型
- 關(guān)系模型
層次模型就是以“上下級(jí)”的層次關(guān)系來組織數(shù)據(jù)的一種方式,層次模型的數(shù)據(jù)結(jié)構(gòu)看起來就像一顆樹:
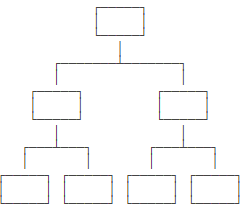
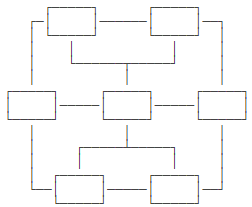
網(wǎng)狀模型把每個(gè)數(shù)據(jù)節(jié)點(diǎn)和其他很多節(jié)點(diǎn)都連接起來,它的數(shù)據(jù)結(jié)構(gòu)看起來就像很多城市之間的路網(wǎng):
關(guān)系模型把數(shù)據(jù)看作是一個(gè)二維表格,任何數(shù)據(jù)都可以通過行號(hào)+列號(hào)來唯一確定,它的數(shù)據(jù)模型看起來就是一個(gè)Excel表:

相比層次模型和網(wǎng)狀模型,關(guān)系模型理解和使用起來最簡(jiǎn)單并且也最流行。
3、關(guān)系型數(shù)據(jù)庫
所謂的關(guān)系型數(shù)據(jù)庫,是建立在關(guān)系模型基礎(chǔ)上的數(shù)據(jù)庫,借助于集合代數(shù)等數(shù)學(xué)概念和方法來處理數(shù)據(jù)庫中的數(shù)據(jù)。我們可以使用關(guān)系型數(shù)據(jù)庫管理系統(tǒng)(RDBMS)來存儲(chǔ)和管理大數(shù)據(jù)量。
RDBMS 即關(guān)系型數(shù)據(jù)庫管理系統(tǒng)(Relational Database Management System)的特點(diǎn):
- 1.數(shù)據(jù)以表格的形式出現(xiàn)
- 2.每行為各種記錄名稱
- 3.每列為記錄名稱所對(duì)應(yīng)的數(shù)據(jù)域
- 4.許多的行和列組成一張表單
- 5.若干的表單組成database
一個(gè)關(guān)系型數(shù)據(jù)是由一個(gè)個(gè)關(guān)系表組成的,對(duì)于一個(gè)關(guān)系表,除了定義每一列的名稱外,還需要定義每一列的數(shù)據(jù)類型。關(guān)系數(shù)據(jù)庫支持的標(biāo)準(zhǔn)數(shù)據(jù)類型包括數(shù)值、字符串、時(shí)間等:
| 名稱 | 類型 | 說明 |
|---|---|---|
| INT | 整型 | 4字節(jié)整數(shù)類型,范圍約+/-21億 |
| BIGINT | 長整型 | 8字節(jié)整數(shù)類型,范圍約+/-922億億 |
| REAL | 浮點(diǎn)型 | 4字節(jié)浮點(diǎn)數(shù),范圍約+/-1038 |
| DOUBLE | 浮點(diǎn)型 | 8字節(jié)浮點(diǎn)數(shù),范圍約+/-10308 |
| DECIMAL(M,N) | 高精度小數(shù) | 由用戶指定精度的小數(shù),例如,DECIMAL(20,10)表示一共20位,其中小數(shù)10位,通常用于財(cái)務(wù)計(jì)算 |
| CHAR(N) | 定長字符串 | 存儲(chǔ)指定長度的字符串,例如,CHAR(100)總是存儲(chǔ)100個(gè)字符的字符串 |
| VARCHAR(N) | 變長字符串 | 存儲(chǔ)可變長度的字符串,例如,VARCHAR(100)可以存儲(chǔ)0~100個(gè)字符的字符串 |
| BOOLEAN | 布爾類型 | 存儲(chǔ)True或者False |
| DATE | 日期類型 | 存儲(chǔ)日期,例如,2018-06-22 |
| TIME | 時(shí)間類型 | 存儲(chǔ)時(shí)間,例如,12:20:59 |
| DATETIME | 日期和時(shí)間類型 | 存儲(chǔ)日期+時(shí)間,例如,2018-06-22 12:20:59 |
上面的表中列舉了最常用的數(shù)據(jù)類型。很多數(shù)據(jù)類型還有別名,例如,REAL又可以寫成FLOAT(24)。還有一些不常用的數(shù)據(jù)類型,例如,TINYINT(范圍在0~255)。各數(shù)據(jù)庫廠商還會(huì)支持特定的數(shù)據(jù)類型,例如JSON。
選擇數(shù)據(jù)類型的時(shí)候,要根據(jù)業(yè)務(wù)規(guī)則選擇合適的類型。通常來說,BIGINT能滿足整數(shù)存儲(chǔ)的需求,VARCHAR(N)能滿足字符串存儲(chǔ)的需求,這兩種類型是使用最廣泛的。
3.1、主流關(guān)系數(shù)據(jù)庫
目前,主流的關(guān)系數(shù)據(jù)庫主要分為以下幾類:
- 商用數(shù)據(jù)庫,例如:Oracle,SQL Server,DB2等;
- 開源數(shù)據(jù)庫,例如:MySQL,PostgreSQL等;
- 桌面數(shù)據(jù)庫,以微軟Access為代表,適合桌面應(yīng)用程序使用;
- 嵌入式數(shù)據(jù)庫,以Sqlite為代表,適合手機(jī)應(yīng)用和桌面程序。
4、關(guān)系模型
關(guān)系數(shù)據(jù)庫是建立在關(guān)系模型上的。而關(guān)系模型本質(zhì)上就是若干個(gè)存儲(chǔ)數(shù)據(jù)的二維表,可以把它們看作很多Excel表。表的每一行稱為記錄(Record),記錄是一個(gè)邏輯意義上的數(shù)據(jù)。表的每一列稱為字段(Column),同一個(gè)表的每一行記錄都擁有相同的若干字段。字段定義了數(shù)據(jù)類型(整型、浮點(diǎn)型、字符串、日期等),以及是否允許為NULL。注意NULL表示字段數(shù)據(jù)不存在。一個(gè)整型字段如果為NULL不表示它的值為0,同樣的,一個(gè)字符串型字段為NULL也不表示它的值為空串''。
和Excel表有所不同的是,關(guān)系數(shù)據(jù)庫的表和表之間需要建立“一對(duì)多”,“多對(duì)一”和“一對(duì)一”的關(guān)系,這樣才能夠按照應(yīng)用程序的邏輯來組織和存儲(chǔ)數(shù)據(jù)。
例如,班級(jí)表和學(xué)生表的關(guān)系:一個(gè)班級(jí)表的每一行對(duì)應(yīng)著一個(gè)班級(jí),而一個(gè)班級(jí)又對(duì)應(yīng)著多個(gè)學(xué)生,所以班級(jí)表和學(xué)生表就是“一對(duì)多”的關(guān)系。反過來,如果我們先在學(xué)生表中定位了一行記錄,要確定他的班級(jí),只需要根據(jù)這條記錄的“班級(jí)ID”對(duì)應(yīng)的值找到班級(jí)表中相同ID對(duì)應(yīng)的記錄即可確定班級(jí)。所以,學(xué)生表和班級(jí)表是“多對(duì)一”的關(guān)系。
在關(guān)系數(shù)據(jù)庫中,關(guān)系是通過主鍵和外鍵來維護(hù)的。
5、約束(Constraints)
約束是在表中定義的用于維護(hù)數(shù)據(jù)庫完整性的一些規(guī)則,用于限制加入表的列的數(shù)據(jù),可以防止將錯(cuò)誤的數(shù)據(jù)插入表中。約束是用來保證數(shù)據(jù)的正確性、有效性和完整性的。若某個(gè)約束條件只作用于單獨(dú)的列,可以將其定義為列約束也可定義為表約束;若某個(gè)約束條件作用域多個(gè)列,則必須定義為表約束。
SQL Server中的約束用來確保系統(tǒng)的完整性。一般約束可以分為:主鍵約束、非空約束、唯一約束、外鍵約束、檢查約束、默認(rèn)約束。
約束可以在創(chuàng)建表時(shí)規(guī)定(通過 CREATE TABLE 語句),也可以在表創(chuàng)建之后再規(guī)定(通過 ALTER TABLE 語句)。
示例:
CREATE TABLE students2( id INT, NAME VARCHAR(20) NOT NULL -- 非空約束 ) ALTER TABLE students NAME VARCHAR(20) NOT NULL; -- 在表創(chuàng)建之后再通過 ddl 語句添加約束也行
5.1、非空約束(NOT NULL)
非空約束即定義某個(gè)字段不能為空,如果一條記錄該字段為空則無法添加成功。
5.1.1、創(chuàng)建非空約束
非空約束的創(chuàng)建語法:
CREATE TABLE students2( id INT, NAME VARCHAR(20) NOT NULL -- 非空約束 ) ALTER TABLE students MODIFY NAME VARCHAR(20) NOT NULL; -- 在表創(chuàng)建之后再通過DDL語句添加約束也行
5.1.2、刪除非空約束
刪除非空約束只需通過 DDL 語句修改表字段結(jié)構(gòu),不添加非空約束即可
ALTER TABLE students MODIFY NAME VARCHAR(20);
5.2、唯一約束(unique)
唯一約束即定義某個(gè)字段的值不能重復(fù),如果一條記錄的該字段跟其他記錄的值重復(fù),則無法添加成功。
5.2.1、創(chuàng)建唯一約束
唯一約束的創(chuàng)建語法:
CREATE TABLE students2( id INT, phone VARCHAR(20) UNIQUE ) alter table students modify phone varchar(20) unique;
注意,MySQL 中唯一約束的字段可以是 null,而且多個(gè)記錄的該字段可以同時(shí)為 null 值,并不會(huì)提示重復(fù)。
5.2.2、刪除唯一約束
刪除唯一約束的語法:
ALTER TABLE students DROP INDEX phone;
5.3、主鍵約束(primary key)
主鍵約束:非空且唯一。
對(duì)于關(guān)系表,有個(gè)很重要的約束,就是任意兩條記錄不能重復(fù)。不能重復(fù)不是指兩條記錄不完全相同,而是指能夠通過某個(gè)字段唯一區(qū)分出不同的記錄,這個(gè)字段被稱為主鍵。
由于主鍵的作用十分重要,如何選取主鍵會(huì)對(duì)業(yè)務(wù)開發(fā)產(chǎn)生重要影響。比如我們以身份證號(hào)作為主鍵,但是,身份證號(hào)也是一種業(yè)務(wù)場(chǎng)景,如果身份證號(hào)升位了,或者需要變更,作為主鍵,不得不修改的時(shí)候,就會(huì)對(duì)業(yè)務(wù)產(chǎn)生嚴(yán)重影響。所以,選取主鍵的一個(gè)基本原則是:不使用任何業(yè)務(wù)相關(guān)的字段作為主鍵。因此,身份證號(hào)、手機(jī)號(hào)、郵箱地址這些看上去可以唯一的字段,均不可用作主鍵。
作為主鍵最好是完全業(yè)務(wù)無關(guān)的字段,我們一般把這個(gè)字段命名為id。常見的可作為id字段的類型有:
-
自增整數(shù)類型:數(shù)據(jù)庫會(huì)在插入數(shù)據(jù)時(shí)自動(dòng)為每一條記錄分配一個(gè)自增整數(shù),這樣我們就完全不用擔(dān)心主鍵重復(fù),也不用自己預(yù)先生成主鍵;
-
全局唯一GUID類型:使用一種全局唯一的字符串作為主鍵,類似
8f55d96b-8acc-4636-8cb8-76bf8abc2f57。GUID算法通過網(wǎng)卡MAC地址、時(shí)間戳和隨機(jī)數(shù)保證任意計(jì)算機(jī)在任意時(shí)間生成的字符串都是不同的,大部分編程語言都內(nèi)置了GUID算法,可以自己預(yù)算出主鍵。
對(duì)于大部分應(yīng)用來說,通常自增類型的主鍵就能滿足需求。我們?cè)?code>students表中定義的主鍵也是BIGINT NOT NULL AUTO_INCREMENT類型。(如果使用INT自增類型,那么當(dāng)一張表的記錄數(shù)超過2147483647(約21億)時(shí),會(huì)達(dá)到上限而出錯(cuò)。使用BIGINT自增類型則可以最多約922億億條記錄)
5.3.1、聯(lián)合主鍵(不建議使用)
關(guān)系數(shù)據(jù)庫實(shí)際上還允許通過多個(gè)字段唯一標(biāo)識(shí)記錄,即將兩個(gè)或更多的字段都設(shè)置為主鍵,這種主鍵被稱為聯(lián)合主鍵。對(duì)于聯(lián)合主鍵,允許一列有重復(fù),只要不是所有主鍵列都重復(fù)即可。
沒有必要的情況下,我們盡量不使用聯(lián)合主鍵,因?yàn)樗o關(guān)系表帶來了復(fù)雜度的上升。
5.3.2、創(chuàng)建主鍵
創(chuàng)建主鍵的語法:
CREATE TABLE stu( id int PRIMARY KEY, -- 創(chuàng)建表時(shí)指定主鍵。可以通過 auto_increment 關(guān)鍵字來指定主鍵自增長:id int PRIMARY KEY AUTO_INCREMENT, name VARCHAR(20) ) ALTER TABLE stu MODIFY id INT PRIMARY KEY; --先創(chuàng)建表,后面再添加主鍵
5.3.3、刪除主鍵
刪除主鍵的語法:
ALTER TABLE stu DROP PRIMARY KEY;
5.4、外鍵約束(foreign key)
在一個(gè)表中,通過某個(gè)字段,可以把數(shù)據(jù)與另一張表關(guān)聯(lián)起來,這個(gè)字段就稱為外鍵。比如在students表中,通過class_id的字段可以關(guān)聯(lián)到classes表,可以確定某個(gè)學(xué)生屬于哪個(gè)班級(jí),那么 class_id 就可以稱為外鍵。
關(guān)系數(shù)據(jù)庫通過外鍵可以實(shí)現(xiàn)一對(duì)多、多對(duì)多和一對(duì)一的關(guān)系。外鍵既可以通過數(shù)據(jù)庫語法來進(jìn)行定義設(shè)置,也可以不設(shè)置約束,僅依靠應(yīng)用程序的邏輯來保證,這樣速度會(huì)更快。
5.4.1、創(chuàng)建外鍵
比如:student 表

classes 表:

我們希望 student 表能和 classes 表關(guān)聯(lián)起來。可以將 student 表中的 class_id 定義為外鍵,關(guān)聯(lián) classes 表中的主鍵 id。
通過定義外鍵約束,關(guān)系數(shù)據(jù)庫可以保證無法插入無效的數(shù)據(jù)。即如果classes表不存在id=99的記錄,students表就無法插入class_id=99的記錄。同樣的,如果 classes 表中 id= 99 有被 student表的一些記錄關(guān)聯(lián)到,則 classes 表中的 id=99 這條數(shù)據(jù)無法被刪除,只有先全部刪除 student 表中關(guān)聯(lián)到 classes 的 id=99 的數(shù)據(jù)后,才能刪除 classes 表的 id=99 的記錄。外鍵不能是關(guān)聯(lián)的主鍵所沒有的值,但外鍵可以是 null。
定義外鍵的語法:
create table 表名( id int, 外鍵列 int, ..., constraint 外鍵名稱 foreign key(外鍵列) references 其他表(其他表的列) ) ALTER TABLE 表名 ADD CONSTRAINT 外鍵名稱 FOREIGN KEY (外鍵列) REFERENCES 其他表(其他表的列); -- 先建表,后添加外鍵
外鍵約束的名稱可以任意定義,通過 foreign key 可以指定某個(gè)字段作為外鍵,references 其他名(字段名) 指定這個(gè)外鍵將關(guān)聯(lián)到另一個(gè)表的某列(一般是另一個(gè)表的主鍵)。
需要設(shè)置外鍵的表一般稱為外鍵表,被關(guān)聯(lián)的表稱為主鍵表(因?yàn)橐话闶顷P(guān)聯(lián)主鍵)。
代碼示例:
CREATE TABLE stu( id INT PRIMARY KEY, name VARCHAR(20), class_id INT, CONSTRAINT stu_class_fk FOREIGN KEY (class_id) REFERENCES classes(id) -- 定義 class_id 為外鍵,并且關(guān)聯(lián) classes 表的 id 字段 )
由于外鍵約束會(huì)降低數(shù)據(jù)庫的性能,大部分互聯(lián)網(wǎng)應(yīng)用程序?yàn)榱俗非笏俣龋⒉辉O(shè)置外鍵約束,而是僅靠應(yīng)用程序自身來保證邏輯的正確性。這種情況下,class_id僅僅是一個(gè)普通的列,只是它起到了外鍵的作用而已。
有一些應(yīng)用會(huì)把一個(gè)大表拆成兩個(gè)一對(duì)一的表,目的是把經(jīng)常讀取和不經(jīng)常讀取的字段分開,以獲得更高的性能。例如,把一個(gè)大的用戶表分拆為用戶基本信息表user_info和用戶詳細(xì)信息表user_profiles,大部分時(shí)候,只需要查詢user_info表,并不需要查詢user_profiles表,這樣就提高了查詢速度。
5.4.2、刪除外鍵
要?jiǎng)h除一個(gè)外鍵約束,也是通過ALTER TABLE實(shí)現(xiàn)的:
ALTER TABLE students DROP FOREIGN KEY stu_class_fk;
注意:刪除外鍵約束并沒有刪除外鍵這一列。刪除列是通過DROP COLUMN ...實(shí)現(xiàn)的。
5.4.3、級(jí)聯(lián)更新(on update cascade)
當(dāng)我們?cè)O(shè)置了外鍵,即在外檢表中將某個(gè)字段設(shè)置為外鍵,并且關(guān)聯(lián)主鍵表中的主鍵,如果此時(shí)我們修改主鍵表中和外鍵表進(jìn)行關(guān)聯(lián)的字段(一般是主鍵表的主鍵,mssql好像必須是主鍵),如果我們沒有設(shè)置級(jí)聯(lián)更新,那么這個(gè)時(shí)候會(huì)提示不能更新,因?yàn)橥怄I表還有數(shù)據(jù)正在和這條數(shù)據(jù)進(jìn)行關(guān)聯(lián),但是如果設(shè)置了級(jí)聯(lián)更新,那么外鍵表的數(shù)據(jù)會(huì)自動(dòng)幫我們更新。
ALTER TABLE stu ADD CONSTRAINT stu_classes_fk FOREIGN KEY (class_id) REFERENCES classes(id) on update cascade; -- 外鍵級(jí)聯(lián)更新
此時(shí)如果更新 classes 表中的 id 字段,那么 stu 表中的 class_id 字段會(huì)自動(dòng)隨之更新。
5.4.4、級(jí)聯(lián)刪除(on delete cascade)
當(dāng)我們沒有對(duì)鍵加級(jí)聯(lián)刪除的時(shí)候,刪除主鍵表中的數(shù)據(jù)(外鍵表有引用的數(shù)據(jù))時(shí),會(huì)報(bào)錯(cuò),不能刪除,必須先把相關(guān)聯(lián)的外鍵數(shù)據(jù)刪除了,才能刪除主鍵表的數(shù)據(jù),但如果新建外鍵的時(shí)候設(shè)置了級(jí)聯(lián)刪除,那么當(dāng)我們刪除主鍵表的數(shù)據(jù)時(shí),數(shù)據(jù)庫就會(huì)自動(dòng)幫我們把相關(guān)聯(lián)的外鍵表數(shù)據(jù)刪除掉。
ALTER TABLE stu ADD CONSTRAINT stu_classes_fk FOREIGN KEY (class_id) REFERENCES classes(id) on delete cascade; -- 級(jí)聯(lián)刪除。可以同時(shí)使用級(jí)聯(lián)更新和刪除:on update cascade on delete cascade
此時(shí)如果刪除 classes 表中的某個(gè)記錄(即刪除了一個(gè) id 值),那么 stu 表中所有 class_id 是被刪除的 id 值的記錄都會(huì)被自動(dòng)刪除掉。
定義級(jí)聯(lián)操作后,修改一條記錄可能導(dǎo)致多條記錄被修改,所以需要謹(jǐn)慎使用。
6、索引(INDEX)
在關(guān)系數(shù)據(jù)庫中,如果有上萬甚至上億條記錄,在查找記錄的時(shí)候,想要獲得非常快的速度,就需要使用索引。索引是關(guān)系數(shù)據(jù)庫中對(duì)某一列或多個(gè)列的值進(jìn)行預(yù)排序的數(shù)據(jù)結(jié)構(gòu)。通過使用索引,可以讓數(shù)據(jù)庫系統(tǒng)不必掃描整個(gè)表,而是直接定位到符合條件的記錄,這樣就大大加快了查詢速度。
例如,如果要經(jīng)常根據(jù) student 表的 score 列進(jìn)行查詢,就可以對(duì) score 列創(chuàng)建索引:
ALTER TABLE students ADD INDEX idx_score (score); -- 使用列score創(chuàng)建一個(gè)名稱為idx_score的索引。索引的名稱是任意的 ALTER TABLE students ADD INDEX idx_name_score (name, score); -- 索引如果有多列,可以在括號(hào)里依次寫上
索引的效率取決于索引列的值是否散列,即該列的值如果越互不相同,那么索引效率越高。反過來,如果某列存在大量相同重復(fù)的值,那么對(duì)該列創(chuàng)建索引也沒有什么意義。
可以對(duì)一張表創(chuàng)建多個(gè)索引。索引的優(yōu)點(diǎn)是提高了查詢效率,缺點(diǎn)是在插入、更新和刪除記錄時(shí),需要同時(shí)修改索引,因此,索引越多,插入、更新和刪除記錄的速度就越慢。
對(duì)于主鍵,關(guān)系數(shù)據(jù)庫會(huì)自動(dòng)對(duì)其創(chuàng)建主鍵索引。使用主鍵索引的效率是最高的,因?yàn)橹麈I會(huì)保證絕對(duì)唯一。
數(shù)據(jù)庫索引對(duì)于用戶和應(yīng)用程序來說都是透明的,即無論是否創(chuàng)建索引,對(duì)于用戶和應(yīng)用程序來說,使用關(guān)系數(shù)據(jù)庫不會(huì)有任何區(qū)別。當(dāng)我們?cè)跀?shù)據(jù)庫中查詢時(shí),如果有相應(yīng)的索引可用,數(shù)據(jù)庫系統(tǒng)就會(huì)自動(dòng)使用索引來提高查詢效率,如果沒有索引,查詢也能正常執(zhí)行,只是速度會(huì)變慢。因此,索引可以在使用數(shù)據(jù)庫的過程中再逐步優(yōu)化。
6.1、唯一索引
在設(shè)計(jì)關(guān)系數(shù)據(jù)表的時(shí)候,看上去唯一的列,例如身份證號(hào)、郵箱地址等,因?yàn)樗麄兙哂袠I(yè)務(wù)含義,因此不宜作為主鍵。但是,這些列根據(jù)業(yè)務(wù)要求,又具有唯一性約束:即不能出現(xiàn)兩條記錄存儲(chǔ)了同一個(gè)身份證號(hào)。這個(gè)時(shí)候,就可以給該列添加一個(gè)唯一索引。
例如,我們假設(shè)students表的name不能重復(fù):
ALTER TABLE students ADD UNIQUE INDEX uni_name (name); -- 添加唯一索引
7、多表關(guān)系設(shè)計(jì)
在設(shè)計(jì)表時(shí),應(yīng)該把該表本身的基本字段考慮進(jìn)去,然后再考慮和其他表之間的關(guān)系,考慮是否需要建立外鍵或者建中間表。
多表之間的關(guān)系有:一對(duì)一、一對(duì)多、多對(duì)多,不同關(guān)系在設(shè)計(jì)表時(shí)的思路如下:
- 在設(shè)計(jì)一對(duì)一關(guān)系時(shí),只需在任意一方建立外鍵,且該外鍵需建立唯一約束,然后指向另一方的主鍵即可。比如:學(xué)生和身份證表,一個(gè)學(xué)生只有一個(gè)身份證,一個(gè)身份證也只屬于一個(gè)學(xué)生,此時(shí)在任意一方比如學(xué)生建立外鍵且在該外鍵添加唯一約束,然后指向身份證表的主鍵即可。一對(duì)一關(guān)系用的比較少,因?yàn)閷?shí)際上可以合成一張表。
- 在設(shè)計(jì)一對(duì)多關(guān)系時(shí),我們可以在“多”的一方建立外鍵,關(guān)聯(lián)“一”的一方的主鍵。比如:?jiǎn)T工和部門表,一個(gè)員工只屬于一個(gè)部門,一個(gè)部門有多個(gè)員工,此時(shí)我們可以在員工表建立 “部門ID” 字段作為外鍵,指向部門表的主鍵。
- 在設(shè)計(jì)多對(duì)多關(guān)系時(shí),我們應(yīng)該建立一個(gè)中間表,這個(gè)中間表應(yīng)該至少包含兩個(gè)字段,且這兩個(gè)字段作為外鍵分別指向多表關(guān)系中兩張表的主鍵。比如學(xué)生和課程表,一個(gè)學(xué)生可以選多門課程,一門課程也可以被多個(gè)學(xué)生選擇,此時(shí)我們可以建立一個(gè)中間表,該表有兩個(gè)字段,分別指向?qū)W生表和課程表的主鍵。
一般我們?cè)O(shè)計(jì)表時(shí),可以先考慮表中的必要字段,然后再考慮表和表之間的關(guān)系,添加外鍵等其他字段。

 浙公網(wǎng)安備 33010602011771號(hào)
浙公網(wǎng)安備 33010602011771號(hào)