
Ai復習
1、目前比較好的向量模型是openAI的收費的,開源好用的Qwen3 embedding模型。


MTEB是一個公共的embedding測試集合
向量庫:chroma,Milvus,F(xiàn)aiss, Weaviate

2、向量基于雙塔模型訓練

3、向量怎么計算

4、rag系統(tǒng)基本模型

5、改進切 文本的方式 nltk庫

醫(yī)療的文檔經(jīng)驗

6、文本切割的方式

7、有時候最合適的答案不一定排在前面,需要使用打分模型

打分模型:

8、混合檢索
同時使用傳統(tǒng)的es和向量檢索,融合兩次的召回結果做RRF排序。

9、工具

10、知識圖譜(一般用不上)

11、配置Ak/SK

12、langchain和llamaindex的區(qū)別。

13、反向傳播算法(Backpropagation algorithm,簡稱BP算法)
是一種用于訓練多層神經(jīng)網(wǎng)絡的監(jiān)督學習算法,通過梯度下降法和鏈式法則計算并調(diào)整網(wǎng)絡參數(shù)(權重和偏置),以最小化預測輸出與真實值之間的誤差,從而優(yōu)化網(wǎng)絡性能。
(模型實際輸出-預期值)的平方為loss。損失函數(shù)。目前l(fā)oss一般1.5就會有效果經(jīng)驗。提升acc(準確率),lr(學習率)

14、模型本身就是矩陣
訓練模型本身是進行特征提取,通過數(shù)據(jù)線性代數(shù)里的概率分布來表達的。
15、模型訓練數(shù)據(jù)集合大小比例。
訓練集合:驗證集:測試集=8:1:1 假如分類模型,如果是分類任務,要保證訓練集每個分類均衡
比如以下分類,類別不均衡,一般做不到補齊數(shù)據(jù),只能按照合理范圍舍棄數(shù)據(jù)。可以在將標簽都控制在1.7左右。
比較牛逼是yolo方式去處理樣本方式不均勻。

16、訓練注意點
l訓練oss損失逐漸上升,不保存過擬合的參數(shù)
17、大語 言大小

18 、使用配置更新模型的toke_maxlength長度,處理超長文本訓練。
方式一:直接加載預訓練模型。
方法二:config對象初始化模型。

改了模型矩陣需要,先驗就失效了,需要把原模型數(shù)據(jù)一塊加進來。

19、部署gpt2訓練中文
vacab詞典21128個詞,生成文章原理每次是從這21128個詞里面選,根據(jù)概率來,同一個模型,dosample為false,每次都是選取概率最大的,為true則會隨機選前幾個。

20、訓練bert和訓練gpt2區(qū)別
bert二分類模型只需要理解,所以是增量微調(diào),gpt2只能全量微調(diào)。
21、訓練模型時候
pytorch和cuda和python版本都要對應上,有的最高只能支持3.10

22、學習率優(yōu)化器 AdamW,自動優(yōu)化學習率,
學習率過大,好處:loss下降的快,壞處:不易收斂
學習率過小:好處:容易收斂,壞處:loss下降的慢

產(chǎn)生震蕩。

23、eval()使用pytorch需要調(diào)用,transformer內(nèi)部已經(jīng)調(diào)用了eval(),所以使用transformer用模型生成文本,不要使用eval()
24、一般AI只負責創(chuàng)作,格式由程序控制。
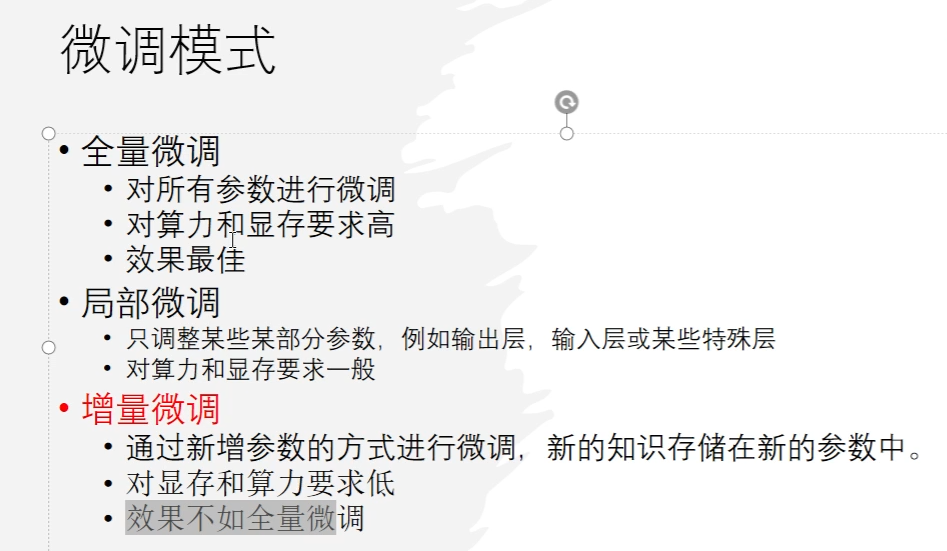
25、微調(diào)的方式,微調(diào)有時候不是最終解,針對10B以上的模型,不適合微調(diào),可能微調(diào)后的模型不如之前的模型。現(xiàn)階段都是使用局部微調(diào)。
微調(diào)都是針對百億參數(shù)以下。
26 lammaryfactory評分標準,BLEU 就是生成詞跟預測詞的重疊度 ROUGE基于召回率



重疊度為4

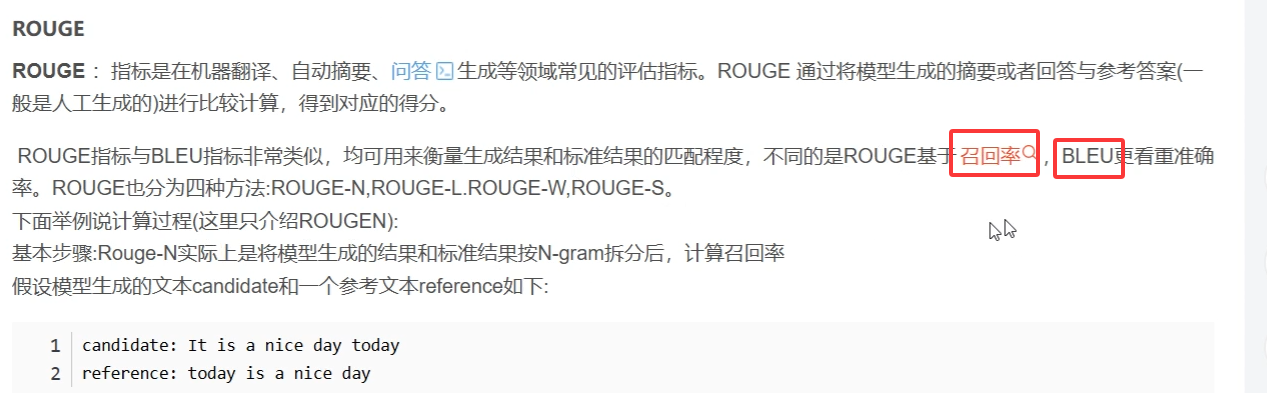
27、opencompass評估大模型,原理也是根據(jù)bleu(對話)和rouge(段落)

一般不要選基座模型,因為數(shù)據(jù)集是沒有人工梳理的,會涉及敏感信息。選擇模型一般選帶chat的版本,或者instruct(人類偏好對齊)
安裝好compass后,直接通過命令評估,也可以在線評估模型。


 浙公網(wǎng)安備 33010602011771號
浙公網(wǎng)安備 33010602011771號