
海量數據去重的Hash與BloomFilter
今天我們談論一下散列表,我之前的兩個博文寫的都是關于平衡二叉樹的
平衡二叉樹
增刪改查時間復雜度為log2n
平衡的目的是增刪改以后,保證下次搜索能穩定排除一半的數據;
總結:通過比較保證有序,通過每次排除一半的元素達到快速索引的目的;
散列表
根據KEY計算KEy在表中的位置的數據結構;是key和其所在存儲地址的映射關系;
hash沖突
映射函數hash(key)=addr;HASH函數可能會把兩個或兩個以上的不同的KEY映射到同一個地址,這種情況稱之為沖突(或者hash碰撞)
選擇hash
- 計算速度快
- 強隨機分布(等概率、均勻地分布在整個地址空間)
- murmurhash1,murmurhash2,murmurhash3,siphash
( redis6.0 當中使用,rust 等大多數語言選用的 hash 算法來實
現 hashmap),cityhash 都具備強隨機分布性;測試地址如
下:
https://github.com/aappleby/smhasher - siphash 主要解決字符串接近的強隨機分布性;
負載因子
- 數組存儲的元素的個數/數據長度;用來形容散列表的存儲密度;負載因子越小,沖突越小,負載因子越大,沖突越大;
沖突處理
鏈表法
引用鏈表來處理哈希沖突;也就是將沖突元素用鏈表鏈接起來;這也是常用的處理沖突的方式;但是可能出現一種極端情況,沖突元素比較多,該沖突鏈表過長,這個時候可以將這個鏈表轉換為紅黑樹時間復雜O(log2n);那么判斷該鏈表過長的依據是多少?可以采用256(經驗值)個節點的時候將鏈表結構轉換為紅黑樹或堆結構。
開放尋址法
將所有的元素都存放在哈希表的數組中,不使用額外的數據結構;一般使用線性探查的思路解決;1. 當插入新元素的時候,使用哈希函數在哈希表中定位元素位置;2. 檢查數組中該槽位索引是否存在元素。如果該槽位為空,則插入,否則3;3. 在2檢測的槽位索引上加一定步長為一下幾種: (1) i+1,i+2,i+3,i+4,...,i+n (2)i-12,1-22,i-33,1+42,...這兩種都會導致同類hash聚集;也就是近似值它的hash值也近似,那么它的數組槽位也靠近,形成hash聚集;第一種同類聚集沖突在前,第二種只是將聚集沖突延后;另外還可以使用雙重哈希來解決上面出現的hash聚集現象:
在.net HashTable類的hash函數Hk定義如下:
Hk(key) = [GetHash(key) + k * (1 +
(((GetHash(key) >> 5) + 1) %
(hashsize – 1)))] % hashsize
在此 (1 + (((GetHash(key) >> 5) + 1) %
(hashsize – 1))) 與 hashsize
互為素數(兩數互為素數表示兩者沒有共同的質因?);
執?了 hashsize 次探查后,哈希表中的每?個位置都有
且只有?次被訪問到,也就是
說,對于給定的 key,對哈希表中的同?位置不會同時使?
Hi 和 Hj;
布隆過濾器
背景
布隆過濾器是一種概率性數據結構,它的特點是高效地插入和查詢,能確定某個字符串一點不存在或者可能存在;
布隆過濾器不存儲具體數據,所以占用空間小,查詢結構存在誤差,但是誤差可控,同時不支持刪除操作。
構成
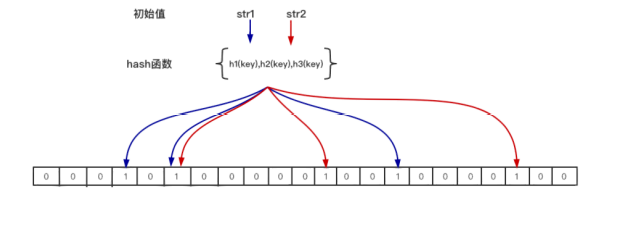
位圖(BIT數組)+n個hash函數
m%2n=m&(2n-1)

原理
當一個元素位圖時,通過K個HASH函數將這個元素映射到位圖的K個點,并把它們置為1;當檢索時,再通過K個hash函數運算檢測位圖的K個點是否都是為1;如果有不為1的點,那么認為該key不存在;如果全部為1,則可能存在;
為什么不支持刪除操作?
- 在位圖中每個槽位值有兩種狀態(0或者1),一個槽位被設置為1狀態,但不確定它被設置了多少次;也就是不知道被多個key哈希映射而來以及是被具體哪個hash函數映射而來;
應用場景
布隆過濾器通常用于判斷某個KEY一定不存在的場景,允許判斷存在時有誤差的情況;
常見處理場景:(1)緩存穿透的解決;(2)熱key限流;

- 描述緩存場景,為了減輕數據庫(mysql)的訪問壓力,在server端與數據庫(mysql)之間加入緩存用來存儲熱點數據。
- 描述緩存穿透,server端請求數據時,緩存和數據庫都不包含該數據,最終請求壓力全部涌向數據庫;
- 數據請求步驟,如圖所示
- 發生原因:黑客利用漏洞偽造數據攻擊或內部業務BUG造成大量重復請求不存在的數據;
- 解決方案:如果圖中所示;
應用分析
在實際應用中,該選擇多少個hash函數?要分配多少空間的位圖?預期存儲多少元素?如何控制誤差?
公式如下:
n -- 預期布隆過濾器中元素的個數,如上圖 只有str1和str2 兩
個元素 那么 n=2
p -- 假陽率,在0-1之間 0.000000
m -- 位圖所占空間
k -- hash函數的個數
公式如下:
n = ceil(m / (-k / log(1 - exp(log(p) / k))))
p = pow(1 - exp(-k / (m / n)), k)
m = ceil((n * log(p)) / log(1 / pow(2, log(2))));
k = round((m / n) * log(2));
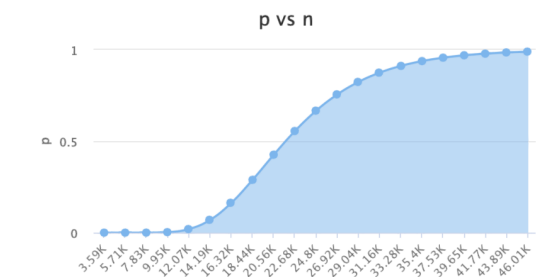
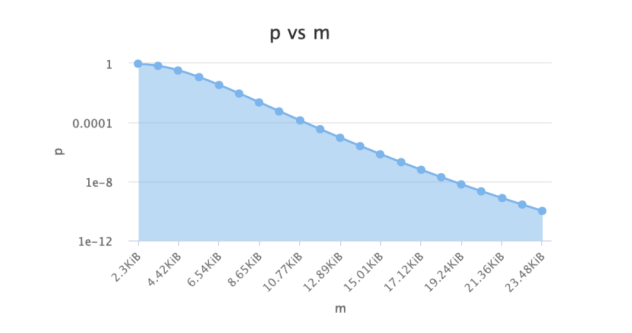
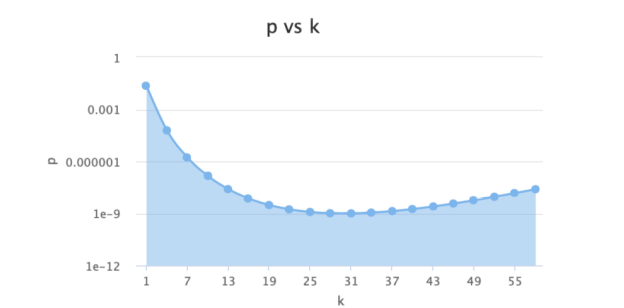
變量關系
假定4個初始值:
n=4000
p=0.000000001
m=172532
k=30
面試百度hash函數實現過程當中 為什么會出現i*31?
- i * 31 = i * (32-1) = i * (1<<5 -1) = i << 5 - i;
*31 質數,hash 隨機分布性是最好的;
確定n和p
在時間使用布隆過濾器時候,首先確定n和p,通過上面的運算得出m和k;
通常可以在下面這個網站上選出合適的值;
https://hur.st/bloomfilter
推薦一個零聲學院免費教程,個人覺得老師講得不錯,
分享給大家:[Linux,Nginx,ZeroMQ,MySQL,Redis,
fastdfs,MongoDB,ZK,流媒體,CDN,P2P,K8S,Docker,
TCP/IP,協程,DPDK等技術內容,點擊立即學習:
服務器
音視頻
dpdk
Linux內核

 浙公網安備 33010602011771號
浙公網安備 33010602011771號