
jmeter軟件指標和硬件指標(16.5)
一、性能插件的效果:
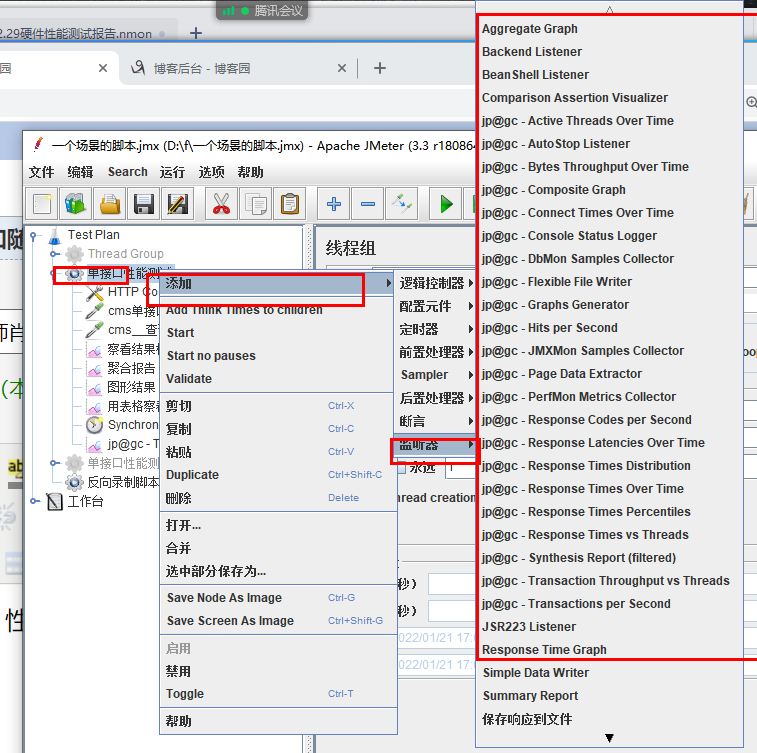
二、安裝一下插件
1、下載一下兩個包

2、存放路徑
(1)E:\dcs\two\jmeter(14)\apache-jmeter-3.3\lib\ext
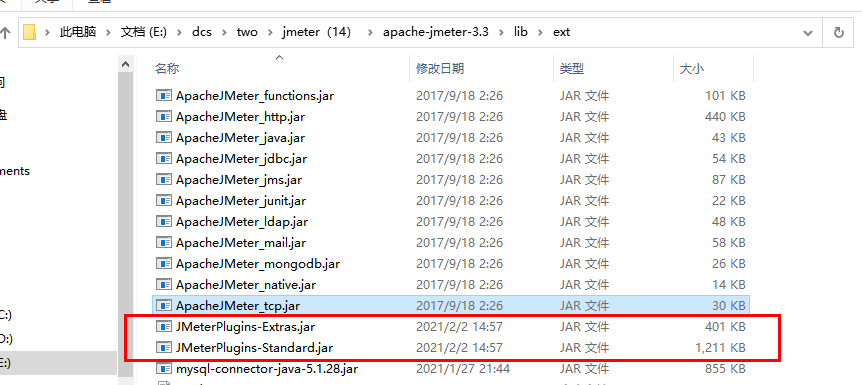
(2)解壓這個包

(3)startagent.bat

(4)點擊startagent.bat,后進界面
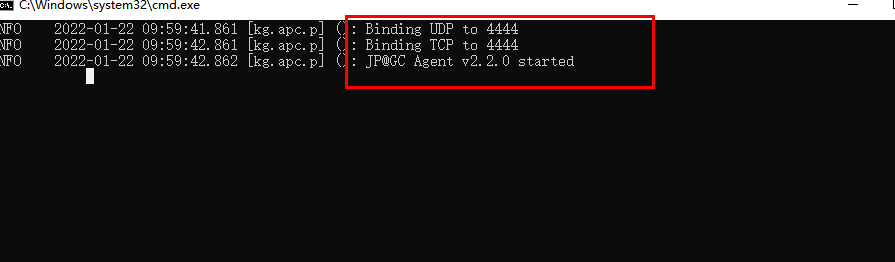
(5)再重啟jmeter 查看監聽器中的插件

=====================================
常用的性能指標插件
- jp@gc - Bytes Throughput Over Time:不同時間吞吐量展示(圖表) 聚合報告里,Throughput是按請求個數來展示的,比如說1.9c,就是每s發送1.9個請求;而這里的展示是按字節Bytes來展示的圖表
- jp@gc - Composite Graph: 混合圖表 在它的Graphs里面可以設置多少個圖表一起展示,它可以同時展示多個圖表
- jp@gc - Hits per Second:每秒點擊量
- jp@gc - PerfMon Metrics Collector:服務器性能監測控件,包括CPU,Memory,Network,I/O等等
- jp@gc - Reponse Latencies Over Time:記錄客戶端發送請求完成后,服務器端返回請求之前這段時間
- jp@gc - Reponse Times Distribution: 顯示測試的響應時間分布,X軸顯示由時間間隔分組的響應時間,Y軸包含每個區間的樣本數
- jp@gc - Transactions per Second: 每秒事務數,服務器每秒處理的事務數

========================================
硬件指標
采集數據
1、下載nmon包

2、將nmon上傳到linux中

3、解壓nmom包

4、將一下包修改權限nmon_x86_sles11 包

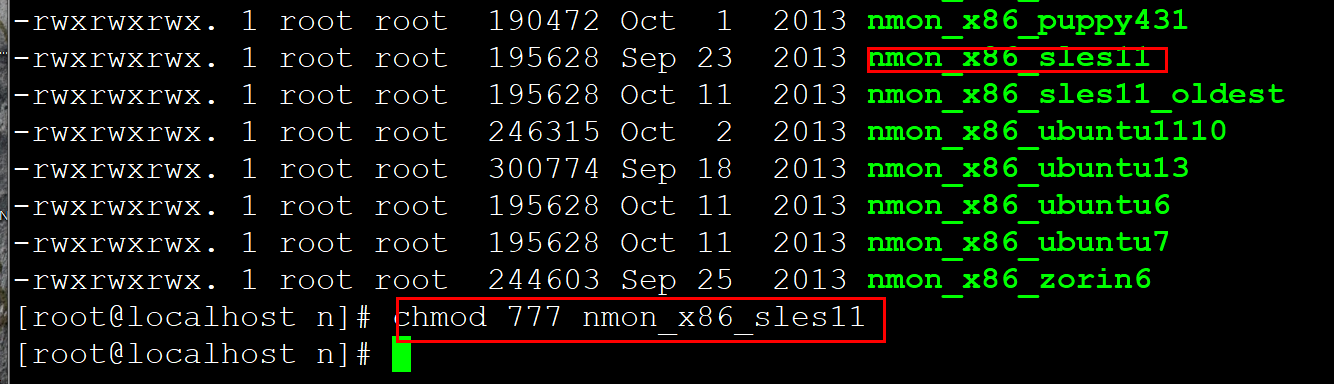
5.修改啟動文件的名字

6、啟動nmon文件

7、nmon的主界面
妻、與子偕老(391875264) 10:47:27
nmon的使用
Nmon 操作
Nmon 啟動后可以顯示 Linux 系統 CPU、內存、進程信息,包括了 CPU 的用戶、系統、等待和空閑狀態值,可用內存、緩存大小以及進程的 CPU 消耗等詳細指標。該種方式顯示信息實時性強,能夠及時掌握系統承受壓力下的運行情況,每顆 CPU 利用率是多少、內存使用多少、網絡流量多少、磁盤讀寫……這些數據均是實時刷新,一目了然。

===============
快捷鍵:
q : 停止并退出 Nmon
h : 查看幫助
c : 查看 CPU 統計數據
m : 查看內存統計數據
d : 查看硬盤統計數據
k : 查看內核統計數據
n : 查看網絡統計數據
N : 查看 NFS 統計數據
j : 查看文件系統統計數據
t : 查看高耗進程
V : 查看虛擬內存統計數據
v : 詳細模式
h : 查看幫助
c : 查看 CPU 統計數據

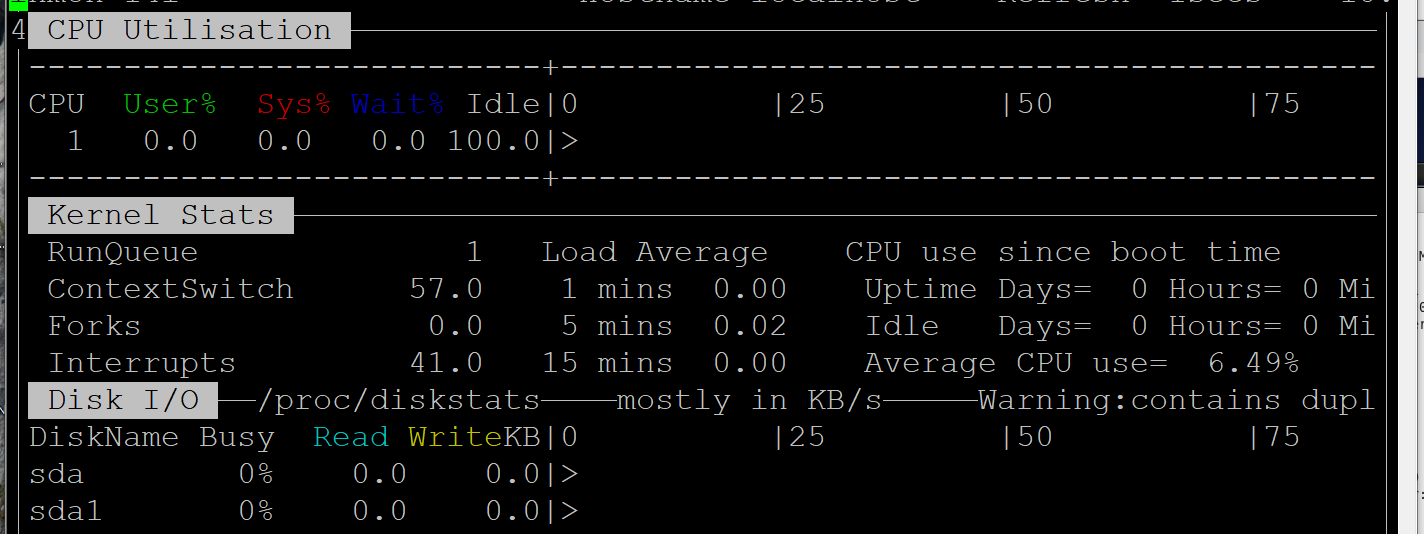
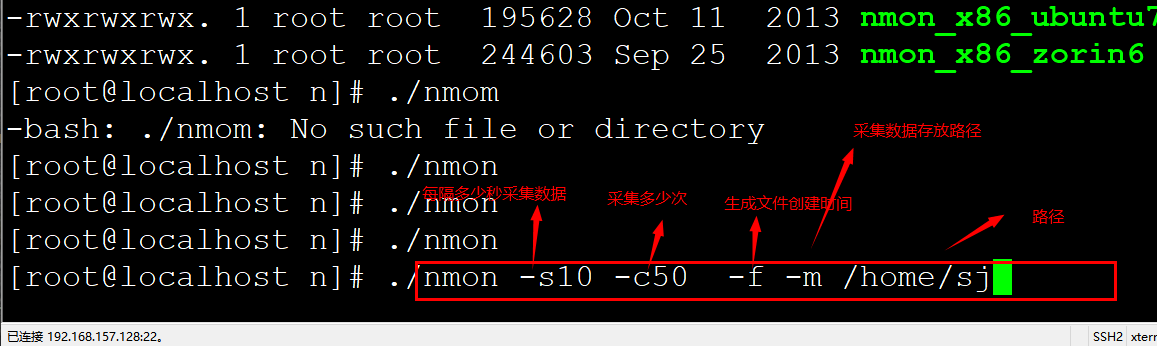
8、采集數據
./nmon -s10 -c50 -f -m /home/sj
9、生成一個nmon采集數據報告

10、將數據報告導出

11、將nmon_analyzer 解壓 ,


12、啟用宏

13、導入采集的數據

@--

===========================================
軟件性能指標
1、響應時間(RT)
響應時間是一個系統最重要的指標之一,它的數值大小直接反應了系統的快慢。響應時間是指執行一個請求從開始到最后收到響應數據所花費的總體時間。
響應時間=發起請求網絡傳輸時間+服務器處理時間+返回響應網絡傳輸時間
2、平均響應時間、百分位響應時間
平均響應時間指的是所有請求平均花費的時間,如果有100個請求,其中 98 個耗時為 1ms,其他兩個為 100ms。那么平均響應時間為 (98 * 1 + 2 * 100) / 100.0 = 2.98ms 。
百分位數( Percentile - Wikipedia )是一個統計學名詞。以響應時間為例, 99% 的百分位響應時間 ,指的是 99% 的請求響應時間,都處在這個值以下。
拿上面的響應時間來說,其整體平均響應時間雖然為 2.98ms,但 99% 的百分位響應時間卻是 100ms。
相對于平均響應時間來說,百分位響應時間通常更能反映服務的整體效率。現實世界中用的較多的是 98% 的百分位響應時間,比如 GitHub System Status 中就有一條 98TH PERC. WEB RESPONSE TIME 曲線。
平均響應時間: 所有請求的平均響應時間,取的平均值
95%percentile : 統計學術語,如果將一組數據從小到大排序,并計算相應的累計百分位,則某一百分位所對應數據的值就稱為這一百分位的百分位數。可表示為:一組n個觀測值按數值大小排列。如,處于p%位置的值稱第p百分位數。
例如有100個請求, 每個請求的響應時間分別是 1-100 平均分布
平均響應時間: 1-100 的平均值,即 50.5
95% percentile : 按從小到大排序,累計第95百分位,也就是 95 (即樣本里95% 的數據都不高于這個值)
3、并發用戶數 (最大并發數,最佳并發數)
并發:
狹義:指同一時間點,執行相同請求的操作(秒殺) ======集合點
廣義:同一時間點,向服務器發起的請求(更多用于真正的性能測試)
并發數:
并發數是指系統同時能處理的請求數量,這個也是反應系統的負載能力
并發用戶數:
同一時間點,執行請求的用戶數
系統用戶數:所有注冊用戶
在線用戶數:在線用戶,可能發起請求,可能沒有發起請求
并發用戶數(Jmeter中的線程數):在線,發起請求用戶
如,10個人發起了20個請求
最佳并發用戶數:當系統的負載等于最佳并發用戶數時,系統的整體效率最高,沒有資源被浪費,用戶也不需要等待
最大并發用戶數:系統的負載一直持續,有些用戶在處理而有的用戶在自己最大的等待時間內等待的時候我們需要保證
1、最佳并發用戶數需大于系統的平均負載
2、系統的最大并發用戶數要大于系統需要承受的峰值負載
4、TPS和HPS的區別
TPS(Transaction per second) 是估算應用系統性能的重要依據。其意義是應用系統每秒鐘處理完成的交易數量。
一般的,評價系統性能均以每秒鐘完成的技術交易的數量來衡量。 系統整體處理能力取決于處理能力最低模塊的TPS 值。依據經驗,應用系統的處理能力一般要求在10-100左右。不同應用系統的TPS有著十分大的差別,一般需要通過性能測試進行準確估算。
HPS(Hits per Second)是指在一秒鐘的時間內用戶對Web頁面的鏈接、提交按鈕等點擊總和。 它一般和TPS成正比關系,是B/S系統中非常重要的性能指標之一。
throughput:分為網絡吞吐量和事務吞吐量,當作為事務吞吐量時,采用TPS來衡量。
當作為網絡吞吐量時(LR分析器中的throughput統計圖是網絡吞吐量),與HPS有一定的聯系,但是不是必然的正比關系。
當然在發送的報文或請求的大小一定的情況下,HPS越高,Throughput也相應的越大。
一般情況下,發送報文或請求較大時的HPS會比發送報文或請求較小時的HPS小,但較大報文或請求的Throughput不一定比較小報文或請求的Throughput小
點擊數HPS (每秒點擊次數):是指發起請求時, 服務端對請求進行響應的頁面資源對應的請求數量.
注意:
-
日常操作中, 對頁面的點擊動作不是這里說的點擊數
-
該指標只在 Web 項目中需要注意
5、吞吐量 、吞吐率
吞吐量:單位時間內處理的請求數量(事務/s)(衡量網絡)
吞吐量是指單位時間內系統能處理的請求數量,體現系統處理請求的能力,這是目前最常用的性能測試指標。
QPS(每秒查詢數)、TPS(每秒事務數)是吞吐量的常用量化指標,另外還有HPS(每秒HTTP請求數)。注,網絡沒有瓶頸的時候,服務器每秒處理的事物數應該等于吞吐量數值
跟吞吐量有關的幾個重要是:并發數、響應時間。
QPS(TPS),并發數、響應時間它們三者之間的關系是:
QPS(TPS)= 并發數/平均響應時間
吞吐率:單位時間內通過的數據的平均速率(kB/s)
如,請求數據多少k,這個數據在網絡中需要傳輸的時間
6、事務
指一個客戶機向服務器發送請求然后服務器做出反應的過程。
Jmeter中默認一個接口請求就是一個事務。
Jmeter中也支持多個接口整體作為一個事務。
7、TPS/QPS(每秒事務數) (重點)
TPS:服務器每秒處理的事物數(衡量服務器處理能力的綜合體現+最主要指標)
TPS是單位時間內處理事務的數量,從代碼角度來說,一段代碼或多段代碼可以組成一個事務.單位時間內完成的事務數越多,服務器的性能越好
QPS:每秒查詢率(如登錄,可能會查詢是否用戶已存在,是否已登錄,密碼是否正確等)
TPS和QPS的區別?
TPS(transaction per second)是單位時間內處理事務的數量,QPS(query per second)是單位時間內請求的數量。TPS代表一個事務的處理,可以包含了多次請求。很多公司用QPS作為接口吞吐量的指標,也有很多公司使用TPS作為標準,兩者都能表現出系統的吞吐量的大小,TPS的一次事務代表一次用戶操作到服務器返回結果,QPS的一次請求代表一個接口的一次請求到服務器返回結果。當一次用戶操作只包含一個請求接口時,TPS和QPS沒有區別。當用戶的一次操作包含了多個服務請求時,這個時候TPS作為這次用戶操作的性能指標就更具有代表性了。
個人理解如下:
1、Tps即每秒處理事務數,包括了
1)用戶請求服務器
2)服務器自己的內部處理
3)服務器返回給用戶
這三個過程,每秒能夠完成N個這三個過程,Tps也就是N;
2、Qps基本類似于Tps,但是不同的是,對于一個頁面的一次訪問,形成一個Tps;但一次頁面請求,可能產生多次對服務器的請求,服務器對這些請求,就可計入“Qps”之中。
例如:訪問一個頁面會請求服務器3次,一次訪問,產生一個“T”,產生3個“Q”
8、點擊率、點擊量
“吞吐率”圖和“點擊率”圖的區別:
“吞吐率”圖,是每秒服務器處理的HTTP申請數。
“點擊率”圖,是客戶端每秒從服務器獲得的總數據量。
點擊數:是衡量Web服務器處理能力的一個重要指標。它的統計是客戶端向Web服務器發了多少次HTTP請求計算的。通常我們也用每秒點擊次數(Hits per Second)指標來衡量Web服務器的處理能力。
9、錯誤率
定義: 錯誤率指系統在負載情況下,失敗交易的概率。
錯誤率 = (失敗交易數/交易總數)*100%
注意:
-
大多系統都會要求無限接近于 100% 成功率, 因此, 錯誤率一般都非常低
-
相對穩定的系統產生的錯誤率又稱超時率(由網絡傳輸導致的)
10、資源的利用率(包含cpu、內存、磁盤I/O等):
定義: 系統資源(CPU/內存/磁盤/網絡)使用占比(使用量/總量*100%)
利用率指標:(沒有特殊要求情況下)
-
CPU 不超過 75%-85%
-
內存不超過 80%
-
硬盤不超過 90%(容量占有率/讀寫時間比)
CPU進行判斷和處理,能反應系統的繁忙程度,一般分系統CPU與用戶CPU
Load Average:指一段時間內,CPU正在處理和等待CPU處理的任務,即CPU使用隊列的長度統計信息
Memory:數據從內存上讀取要比從磁盤上讀取的速度要快,而內存經常出現內存泄露或內存溢出的現象
隊列:隊列較長,說明處理能力達到了極限或者遇到阻塞
IO:與磁盤交互
網絡:重點關注網絡流量,看是否存在網絡帶寬瓶頸
注:一般要求資源利用率不超過80%
硬件性能:
cpu
內存
磁盤(disk I/O)
網絡(NETWORK I/0)
1、CPU
定義:
CPU指標主要指的CPU利用率,包括用戶態(user)、系統態(sys)、等待態(wait)、空閑態(idle)。
參考標準
CPU 利用率要低于業界警戒值范圍之內,即小于或者等于75%;
CPU sys%小于或者等于30%;
CPU wait%小于或者等于5%;
2、內存
定義:
內存是計算機中重要的部件之一,它是與CPU進行溝通的橋梁。計算機中所有程序的運行都是在內存中進行的,因此內存的性能對計算機的影響非常大
參考標準
現在的操作系統為了最大利用內存,在內存中存放了緩存,因此內存利用率100%并不代表內存有瓶頸,衡量系統內存是否有瓶頸主要靠SWAP(與虛擬內存交換)交換空間利用率,一般情況下,SWAP交換空間利用率要低于70%,太多的交換將會引起系統性能低下。
3、磁盤
定義:
定義和解釋:磁盤吞吐量簡稱為Disk Throughput,是指在無磁盤故障的情況下單位時間內通過磁盤的數據量。
參考標準
磁盤指標主要有每秒讀寫多少兆,磁盤繁忙率,磁盤隊列數,平均服務時間,平均等待時間,空間利用率。其中磁盤繁忙率是直接反映磁盤是否有瓶頸的的重要依據,一般情況下,磁盤繁忙率要低于70%。
4、網絡
定義:
網絡吞吐量簡稱為Network Throughput,是指在無網絡故障的情況下單位時間內通過的網絡的數據數量。單位為Byte/s。網絡吞吐量指標用于衡量系統對于網絡設備或鏈路傳輸能力的需求。當網絡吞吐量指標接近網絡設備或鏈路最大傳輸能力時,則需要考慮升級網絡設備。
參考標準
網絡吞吐量指標主要有每秒有多少兆流量進出,一般情況下不能超過設備或鏈路最大傳輸能力的70%。
CPU對數據進行判斷以及邏輯處理,本身不能存儲數據;這時cpu從內存取數據進行邏輯計算,如果內存沒有數據,才會從硬盤讀數據到內存,再對數據進行處理
就像人吃飯一樣,cpu就是人,內存就是碗,硬盤就是飯鍋!
當cpu進程等待,會造成內存開銷的增加,內存不夠用的時候會用到虛擬內存,導致虛擬內存的增加,這時磁盤IO開銷就會增加,系統態sy%提升,cpu開銷增加;內存里數據不夠用,才用磁盤中取數據。
===========================================
1、自己整理一份性能指標(整理文檔)
2、cms 壓測500用戶數,將軟件指標,硬件指標修改成中文都截圖整理成一個word。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號