
基礎排序算法(四)堆排序
一 堆排序
堆排序是一種非常高效且獨特的排序算法,它巧妙地將數據結構中的“堆”應用于排序過程。
1.1 特性介紹
堆排序特性總結
| 特性 | 說明 |
|---|---|
| 核心思想 | 利用堆這種數據結構進行選擇排序。將待排序列構造成一個大頂堆(或小頂堆),從而不斷將堆頂元素(最大值或最小值)與序列末尾元素交換,并調整堆結構,最終得到有序序列 |
| 時間復雜度 | 建堆:O(n);排序過程:O(n log n)。總體時間復雜度為 O(n log n),且最好、最壞、平均情況均如此 |
| 空間復雜度 | O(1),是原地排序算法,只需要常數級別的額外空間用于元素交換 |
| 穩定性 | 不穩定。因交換堆頂和末尾元素時,可能改變相等元素的原始相對順序 |
| 主要優勢 | 時間復雜度穩定,不會出現像快速排序那樣的最壞O(n2)情況;原地排序,空間效率高 |
| 主要劣勢 | 常數因子較大,通常比平均情況下的快速排序慢;對小規模數據排序效率相對不高;不穩定 |
1.2 算法工作原理
堆排序的運作過程清晰地分為“建堆”和“排序”兩大階段。下圖以數組 [12, 11, 13, 5, 6, 7]為例,展示了構建大頂堆以及后續排序的關鍵步驟:
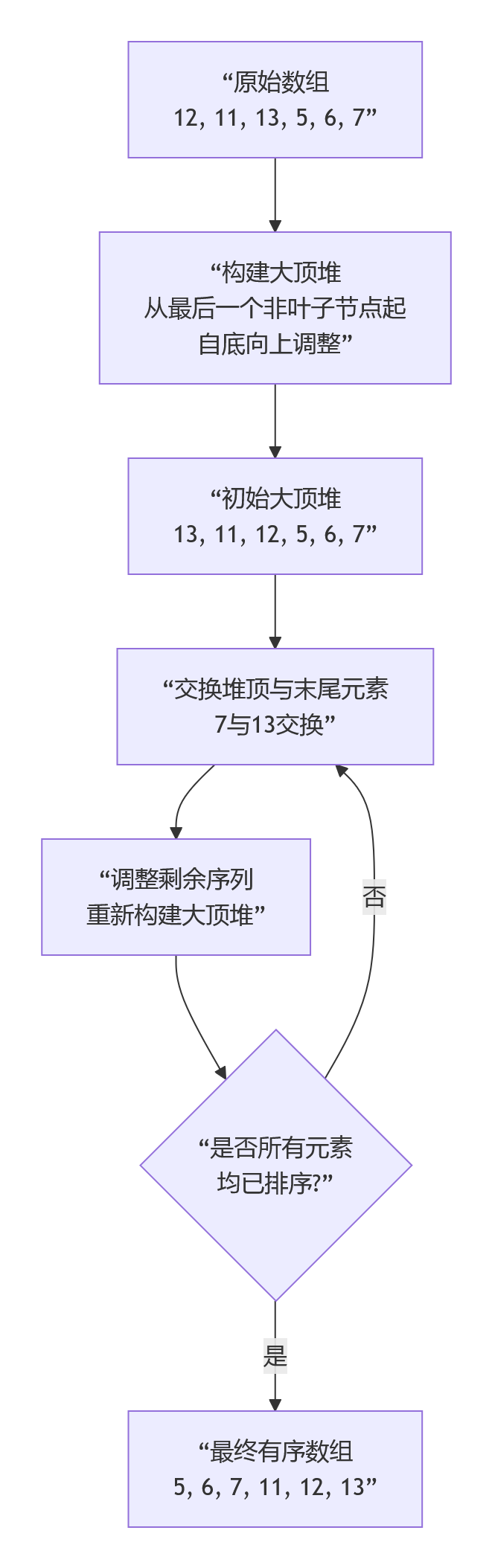
1.2.1 構建堆(Heapify)??
這是堆排序的第一步,目標是將一個無序的完全二叉樹調整成一個??大頂堆??(對于升序排序)。大頂堆的性質是:每個節點的值都??大于或等于??其左右子節點的值。
- 通常從??最后一個非葉子節點??開始(索引為 n/2 - 1,其中 n是數組長度),依次向前遍歷每個非葉子節點。
- 對每個非葉子節點,執行“向下調整”操作:比較該節點與其左右子節點的值,如果子節點中有值更大的,則交換它們的位置,并遞歸地對被交換的子節點進行同樣的調整,確保以該節點為根的子樹滿足堆的性質。
1.2.2 排序??
一旦大頂堆構建完成,堆頂元素(根節點)就是整個序列中的最大值。
- 交換與調整??:將堆頂元素與堆中最后一個元素交換。此時,最大值就位于數組的末尾,可以視為已排序部分。
- 縮小堆范圍??:將堆的大小減一(即忽略最后一個已排序的元素)。
- ??重新調整堆??:由于新的堆頂元素可能破壞堆的性質,因此需要對剩余的未排序序列(從新的根節點開始)再次進行向下調整,使其重新成為大頂堆。
- 重復上述“交換-調整-縮小”步驟,直到堆的大小變為1,此時整個數組就有序了。
1.3 復雜度分析
1.3.1 時間復雜度 O(n log n) 的由來??:
- ??建堆階段??:雖然需要調整n/2個節點,但由于二叉樹的結構特性,大部分調整操作在較低的層進行。建堆操作的時間復雜度經分析為 ??O(n)??。
- ??排序階段??:需要進行n-1次交換和調整。每次調整堆(向下調整)的時間復雜度與當前堆的高度相關,即 ??O(log n)??。因此,排序階段的總時間復雜度為 ??O(n log n)??。
堆排序的整體時間復雜度為 ??O(n log n)??,并且這個性能在最好、最壞和平均情況下都保持一致,非常穩定。
1.3.2 ??空間復雜度 O(1) 的由來??:
堆排序的所有操作(交換、調整)都是在原數組上進行的,只需要固定數量的額外變量(如用于交換的臨時變量 temp),因此是??原地排序??,空間復雜度為 ??O(1)??。
1.4 使用場景
堆排序在以下場景中表現出色:
??需要穩定的最壞情況性能??:當無法承受快速排序最壞情況下O(n2)的時間復雜度時,堆排序的O(n log n)最壞情況性能是可靠的選擇。
??內存空間受限??:由于是原地排序,空間復雜度為O(1),非常適合嵌入式系統等內存緊張的環境。
??尋找Top K元素??:不需要完全排序整個序列,只需找出最大或最小的K個元素。可以構建一個大小為K的小頂堆(找最大K個)或大頂堆(找最小K個),然后遍歷剩余元素進行調整,效率很高。
??實時數據流處理??:堆結構適合處理不斷產生新數據的場景,可以動態維護當前數據的極值或特定順序。
然而,對于??小規模數據??,簡單排序如??插入排序??可能因常數因子更小而實際更快。若??需要穩定性??(保持相等元素的原始順序),則應選擇??歸并排序??等穩定算法。
1.5 代碼實現
1.5.1 c 語言實現
以下是堆排序的一個典型C語言實現,包含了關鍵的堆調整(heapify)函數和排序主函數。
#include <stdio.h>
// 交換數組中兩個元素的值
void swap(int *a, int *b) {
int temp = *a;
*a = *b;
*b = temp;
}
// 堆調整函數(大頂堆)
// arr: 待調整的數組
// n: 當前堆的大小(即需要調整的數組長度)
// i: 待調整的根節點索引
void heapify(int arr[], int n, int i) {
int largest = i; // 初始化最大元素為根節點
int left = 2 * i + 1; // 左子節點索引
int right = 2 * i + 2; // 右子節點索引
// 如果左子節點存在且大于根節點
if (left < n && arr[left] > arr[largest])
largest = left;
// 如果右子節點存在且大于當前最大節點
if (right < n && arr[right] > arr[largest])
largest = right;
// 如果最大元素不是根節點,則需要交換并遞歸調整被破壞的子堆
if (largest != i) {
swap(&arr[i], &arr[largest]);
heapify(arr, n, largest); // 遞歸調整受影響的子樹
}
}
// 堆排序主函數
void heapSort(int arr[], int n) {
// 1. 構建初始大頂堆
// 從最后一個非葉子節點開始向上調整
for (int i = n / 2 - 1; i >= 0; i--)
heapify(arr, n, i);
// 2. 逐個從堆頂提取元素
for (int i = n - 1; i > 0; i--) {
// 將當前堆頂元素(最大值)與末尾元素交換
swap(&arr[0], &arr[i]);
// 交換后,調整剩余的元素(從0到i-1),使其重新成為大頂堆
heapify(arr, i, 0);
}
}
// 打印數組函數
void printArray(int arr[], int n) {
for (int i = 0; i < n; i++)
printf("%d ", arr[i]);
printf("\n");
}
// 主函數測試
int main() {
int arr[] = {12, 11, 13, 5, 6, 7};
int n = sizeof(arr) / sizeof(arr[0]);
printf("排序前的數組: \n");
printArray(arr, n);
heapSort(arr, n);
printf("排序后的數組: \n");
printArray(arr, n);
return 0;
}
1.5.2 關鍵點解釋
- heapify函數:這是堆排序的核心。它確保以節點 i為根的子樹滿足大頂堆的性質。通過比較根節點與其左右子節點,找到最大值,并在需要時進行交換和遞歸調整。
- heapSort函數:
- ??建堆循環??:for (int i = n / 2 - 1; i >= 0; i--)從最后一個非葉子節點開始,自底向上地調用 heapify,最終構建出整個大頂堆。
- ?排序循環??:for (int i = n - 1; i > 0; i--)每次循環將堆頂(最大值)與當前未排序序列的最后一個元素交換,然后對新的堆頂調用 heapify來調整剩余元素,使其恢復成大頂堆。
1.6 與常見排序算法比較
排序算法比較
| 算法 | 平均時間復雜度 | 最壞時間復雜度 | 空間復雜度 | 穩定性 | 主要特點與適用場景 |
|---|---|---|---|---|---|
| 堆排序 | O(n log n) | O(n log n) | O(1) | 不穩定 | 最壞性能穩定,原地排序,適合內存受限和需要穩定最壞情況性能的場景 |
| 快速排序 | O(n log n) | O(n2) | O(log n) | 不穩定 | 平均性能極佳,是許多標準庫的實現選擇,但對初始數據敏感,最壞情況性能差 |
| 歸并排序 | O(n log n) | O(n log n) | O(n) | 穩定 | 性能穩定,是穩定的O(n log n)排序,但需要O(n)額外空間,適合外部排序和對穩定性有要求的場景 |
| 插入排序 | O(n2) | O(n2) | O(1) | 穩定 | 對小規模或基本有序數據效率很高,常作為快速排序或歸并排序的輔助排序 |
1.7 總結
總的來說,堆排序是一種基于??堆數據結構??的高效排序算法,其??時間復雜度穩定在O(n log n)??,并且是??原地排序??,空間復雜度為O(1)。雖然在實際應用中可能不如快速排序快速,且是??不穩定??排序,但在??需要保證最壞情況性能、內存空間有限或需要解決Top K問題??等特定場景下,它依然是一個非常有價值的選擇。理解堆排序對于深入掌握數據結構和算法設計思想具有重要意義。
posted on 2025-10-31 11:33 weiwei2021 閱讀(3) 評論(0) 收藏 舉報

 浙公網安備 33010602011771號
浙公網安備 33010602011771號