Hadoop集群搭建(完全分布式)
一,Hadoop集群簡(jiǎn)介
1.1 Hadoop集群整體概述
- Hadoop集群包括兩個(gè)集群:HDFS集群、YARN集群
- 兩個(gè)集群邏輯上分離、通常物理上在一起
- 兩個(gè)集群都是標(biāo)準(zhǔn)的主從架構(gòu)集群
Hadoop兩種集群內(nèi)容:
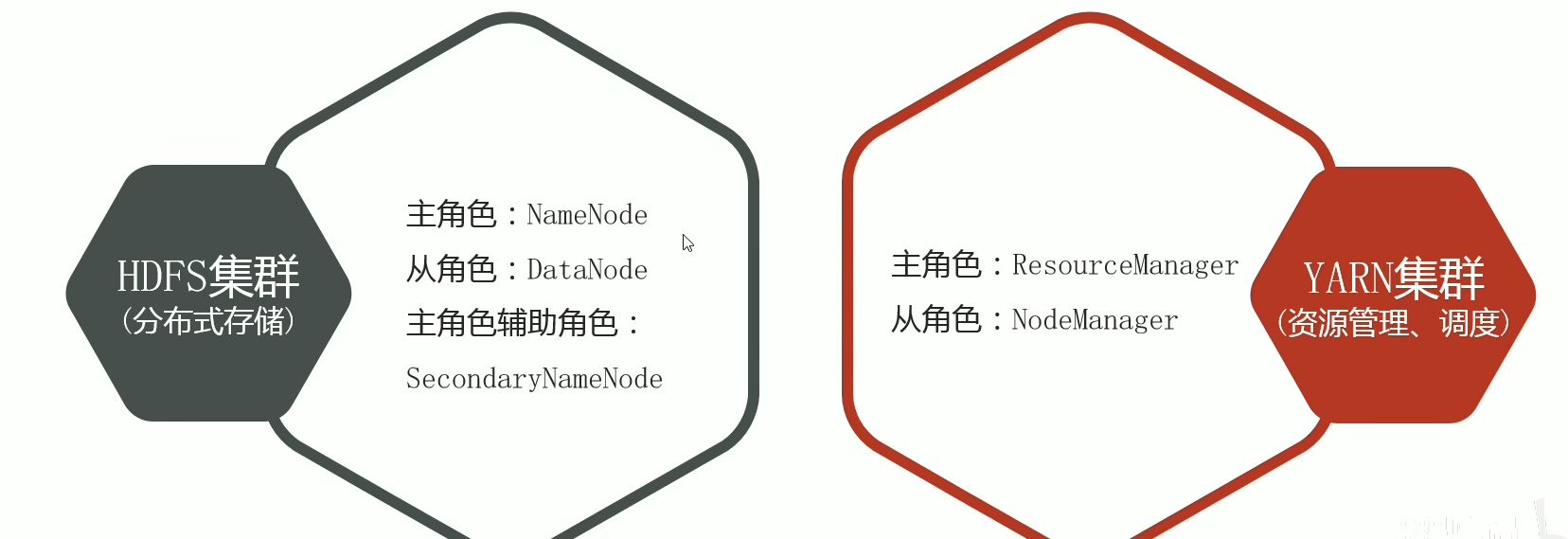
邏輯上分離,物理上合并的理解:
- 邏輯上分離:兩個(gè)集群互相之間沒(méi)有依賴(lài)、互不影響
- 物理上合并:某些角色進(jìn)程往往部署在同一臺(tái)物理服務(wù)器上
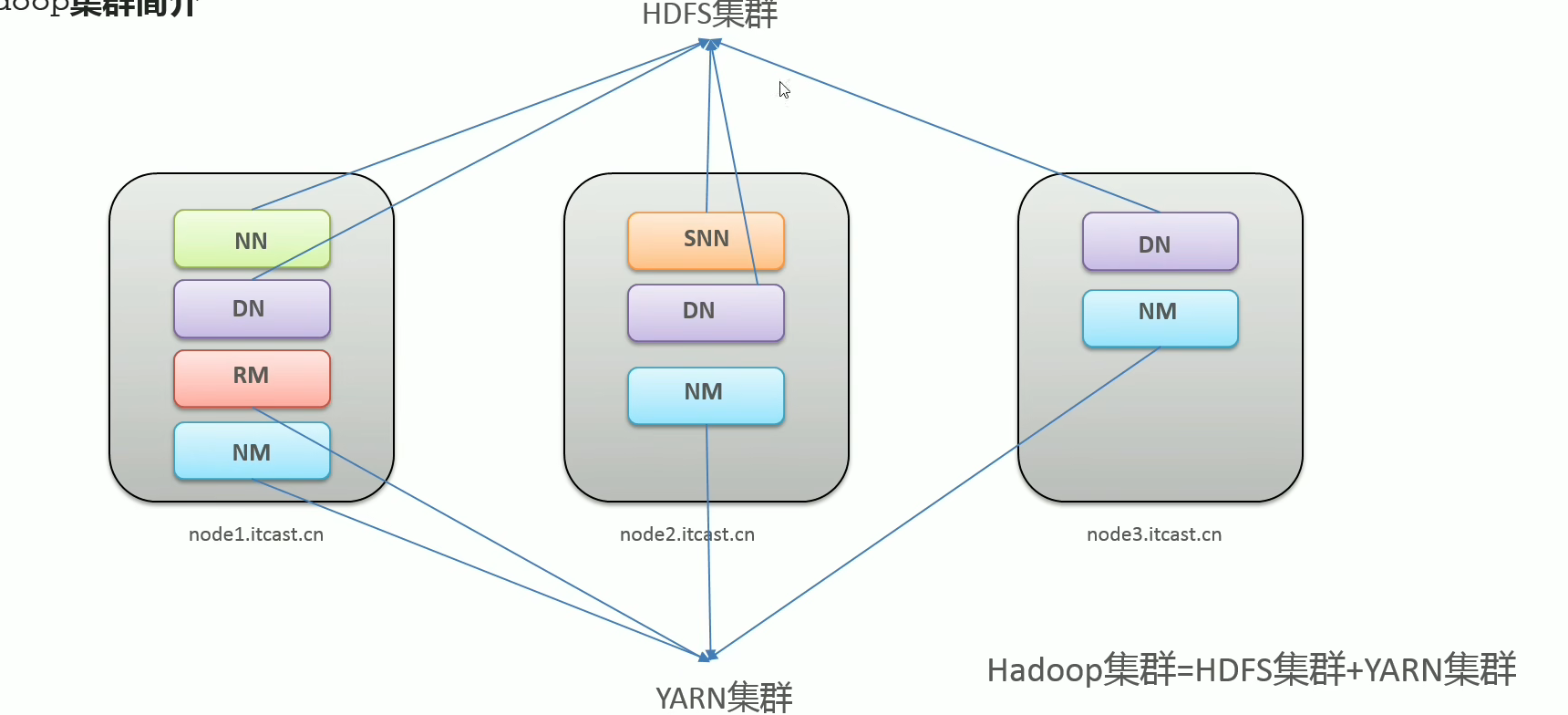
注:MapReduce是計(jì)算框架、代碼層面的組件 沒(méi)有集群之說(shuō)
二,Hadoop集群模式安裝(Cluster mode)
2.1 安裝地址
-
安裝包,源碼包下載地址:https://archive.apache.org/dist/hadoop/common/hadoop-3.3.0/

-
為什么要重新編譯Hadoop源碼?
匹配不同操作系統(tǒng)本地庫(kù)環(huán)境,Hadoop某些操作比如壓縮、IO需要調(diào)用系統(tǒng)本地庫(kù)(.sod11),修改源碼、重構(gòu)源碼
最好是使用源碼包,在本地重新編譯一遍,這樣會(huì)運(yùn)行的更加穩(wěn)定,可以使用docker快速編譯。
2.2 集群角色規(guī)劃
-
角色規(guī)劃的準(zhǔn)責(zé)
根據(jù)軟件工作特性和服務(wù)器硬件資源情況合理分配,比如依賴(lài)內(nèi)存工作的NameNode部署在大內(nèi)存機(jī)器上。
-
角色規(guī)劃注意事項(xiàng)
資源上有搶奪沖突的,盡量不要部署在一起。
工作上需要配合的,盡量部署在一起。
以三臺(tái)虛擬機(jī)舉例:

2.3 服務(wù)器基礎(chǔ)環(huán)境準(zhǔn)備工作
-
給主機(jī)修改主機(jī)名
vim /etc/hostname
-
Host映射
vim /etc/hosts192.168.237.11 master.normaling.cn master 192.168.237.12 Slave1.normaling.cn Slave1 192.168.237.13 Slave2.normaling.cn Slave2 -
關(guān)閉防火墻
systemctl stop firewalld.service #關(guān)閉防火墻 systemctl disable firewalld.service #禁止防火墻開(kāi)機(jī)自啟 -
配置ssh免密登錄
-
集群時(shí)間同步
yum -y install ntpdate ntpdate ntp4.aliyun.com -
創(chuàng)建統(tǒng)一工作目錄
mkdir -p /usr/local/hadoop/data/ #數(shù)據(jù)存儲(chǔ)路徑 mkdir -p /usr/local/hadoop #安裝包存放路徑 -
安裝jdk1.8并配置好環(huán)境。
-
上傳解壓Hadoop安裝包(Master機(jī)器)
cd /usr/local/hadoop/software/ #這個(gè)需要我們先把hadoop安裝包上傳到這個(gè)位置 tar -zxvf hadoop-3.3.6.tar.gz -
遠(yuǎn)程拷貝文件到其他機(jī)器上(master機(jī)器)
scp -r /usr/local/hadoop/hadoop-3.3.6 root@Slave1:/usr/local/hadoop/ scp -r /usr/local/hadoop/hadoop-3.3.6 root@Slave2:/usr/local/hadoop/
2.4 Hadoop安裝包目錄結(jié)結(jié)構(gòu)

2.5 修改hadoop配置文件
-
官網(wǎng)文檔:https://hadoop.apache.org/docs/r3.3.0/
-
配置文件分為三類(lèi):
第一類(lèi)1個(gè):hadoop-env.sh
第二類(lèi)4個(gè):
- xxxx-site.xml,site表示的是用戶(hù)定義的配置,會(huì)覆蓋default中的默認(rèn)配置。
- core-site.xml,核心模塊配置
- hdfs-site.xml,hdfs文件系統(tǒng)模塊配置
- mapred-site.xml,MapReduce模塊配置
- yarn-site.xml yarn模塊配置
-
第三類(lèi)1個(gè):worker
注:這些配置文件在hadoop目錄下的./etc/hadoop里面
簡(jiǎn)單使用所需修改的地方:(只需要修改master主機(jī)即可,后續(xù)通過(guò)scp命令覆蓋)
-
hadoop-env.sh文件
export JAVA_HOME=/export/server/jdk8 #文件最后添加 export HDFS_NAMENODE_USER=root export HDFS_DATANODE_USER=root export HDFS_SECONDARYNAMENODE_USER=root export YARN_RESOURCEMANAGER_USER=root export YARN_NODEMANAGER_USER=root -
core-site.xml
<configuration> <!-- 設(shè)置默認(rèn)使用的文件系統(tǒng) Hadoop支持file、HDFS、GFS、ali|Amazon云等文件系統(tǒng) --> <property> <name>fs.defaultFS</name> <value>hdfs://master:8020</value> </property> <!-- 設(shè)置Hadoop本地保存數(shù)據(jù)路徑 --> <property> <name>hadoop.tmp.dir</name> <value>/usr/local/hadoop/data</value> </property> <!-- 設(shè)置HDFS web UI用戶(hù)身份 --> <property> <name>hadoop.http.staticuser.user</name> <value>root</value> </property> <!-- 整合hive 用戶(hù)代理設(shè)置 --> <property> <name>hadoop.proxyuser.root.hosts</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.root.groups</name> <value>*</value> </property> <!-- 垃圾桶文件保存時(shí)間 --> <property> <name>fs.trash.interval</name> <value>1440</value> </property> </configuration> -
hdfs-site.xml
<configuration> <!-- 設(shè)置SNN進(jìn)程運(yùn)行機(jī)器位置信息 --> <property> <name>dfs.namenode.secondary.http-address</name> <value>Slave1:9868</value> </property> </configuration> -
mapred-site.xml
<configuration> <!-- 設(shè)置MR程序默認(rèn)運(yùn)行模式: yarn集群模式 local本地模式 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <!-- MR程序歷史服務(wù)器端地址 --> <property> <name>mapreduce.jobhistory.address</name> <value>master:10020</value> </property> <!-- 歷史服務(wù)器web端地址 --> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>master:19888</value> </property> <property> <name>yarn.app.mapreduce.am.env</name> <value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value> </property> <property> <name>mapreduce.map.env</name> <value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value> </property> <property> <name>mapreduce.reduce.env</name> <value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value> </property> </configuration> -
yarn-site.xml
<configuration> <!-- 設(shè)置YARN集群主角色運(yùn)行機(jī)器位置 --> <property> <name>yarn.resourcemanager.hostname</name> <value>master</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- 是否將對(duì)容器實(shí)施物理內(nèi)存限制 --> <property> <name>yarn.nodemanager.pmem-check-enabled</name> <value>false</value> </property> <!-- 是否將對(duì)容器實(shí)施虛擬內(nèi)存限制。 --> <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property> <!-- 開(kāi)啟日志聚集 --> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <!-- 設(shè)置yarn歷史服務(wù)器地址 --> <property> <name>yarn.log.server.url</name> <value>http://master:19888/jobhistory/logs</value> </property> <!-- 保存的時(shí)間7天 --> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>604800</value> </property> </configuration> -
workers
master Slave1 Slave2 -
分發(fā)同步hadoop安裝包
cd /export/server scp -r hadoop-3.3.0 root@Slave1:$PWD scp -r hadoop-3.3.0 root@Slave2:$PWD -
將hadoop添加到環(huán)境變量(3臺(tái)機(jī)器)
vim /etc/profile export HADOOP_HOME=/usr/local/hadoop/hadoop-3.3.6 export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin source /etc/profile #別忘了scp給其他兩臺(tái)機(jī)器哦cl hadoop #驗(yàn)證是否配置成功
2.6 Hadoop格式化操作
-
首次啟動(dòng)HDFS時(shí),必須對(duì)其進(jìn)行格式化操作!
-
只有第一次才會(huì)執(zhí)行,如果多次執(zhí)行就相當(dāng)于多次初始化了!!!
-
只需要在整個(gè)Hadoop集群中的一臺(tái)機(jī)器上執(zhí)行一次
-
format本質(zhì)是初始化工作,進(jìn)行HDFS清理和準(zhǔn)備工作。
-
命令:
hdfs namenode -format
三,Hadoop集群?jiǎn)⑼C?WEB UI
官方提供了兩種方式:
-
手動(dòng)逐個(gè)進(jìn)程啟停:每臺(tái)機(jī)器上每次手動(dòng)啟動(dòng)關(guān)閉一個(gè)角色進(jìn)程,可以精準(zhǔn)控制每個(gè)進(jìn)程啟停,避免群起群停。
-
HDFS集群
#hadoop2.x版本命會(huì) hadoop-daemonsh start stop namenode datanode secondarynamenode #hadoop3x版本命今 hdfs --daemon start stop namenodeldatanodelsecondarynamenode -
YARN集群
#hadoop2.x版本命今 yarn-daemon.sh startstop resourcemanagernodemanager #hadoop3x版本命令 yamn --daemon start stop resourcemanagernodemanager
-
-
腳本一鍵啟停
在master上,使用軟件自帶的shell腳本一鍵啟動(dòng)。前提:配置好機(jī)器之間的SSH免密登錄和workers文件。
-
HDFS集群
start-dfs.sh stop-dfs.sh -
YARN集群
start-yarn.sh stop-yarn.sh -
Hadoop集群
start-all.sh stop-all.sh
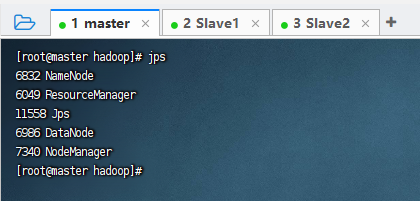
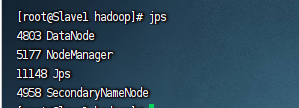
驗(yàn)證是否啟動(dòng)成功:
jps啟動(dòng)成功效果圖:
-
master:
-
Slave1:
-
Slave2:
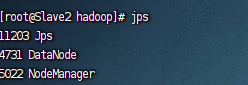
如果沒(méi)有出現(xiàn)上述效果,去/usr/local/hadoop/hadoop-3.3.1/logs/文件夾中查看啟動(dòng)日志,哪個(gè)進(jìn)程沒(méi)有啟動(dòng)就去看哪個(gè)日志即可。
或者在每個(gè)虛擬機(jī)上面都執(zhí)行一遍啟動(dòng)命令
-
-
查看hdfs集群的web UI
配置:hdfs-site.xml里面的dfs.namenode.http-address
默認(rèn)訪問(wèn)地址:http://namenode的ip:50070
192.168.237.11:9870 -
YARN集群的WEB UI
配置:yarn-site.xml里面的yarn.resourcemanager.webapp.address
默認(rèn)訪問(wèn)地址:http://resource manager的ip:8088
192.168.237.11:8088 -
secondary namenode的WEB UI
配置:hdfs-site.xml里面的dfs.namenode.secondary.http-address
默認(rèn)訪問(wèn)地址:http://namenode的ip:50090
192.168.237.12:9868
四,Hadoop功能
-
Shell命令操作:
hadoop fs -mkdir /normaling #創(chuàng)建一個(gè)normaling在/目錄下 hadoop fs -put zookeeper.out /normaling #從本地上傳/normaling文件夾 hadoop fs -ls / #顯示hdfs的文件夾 -
WEB UI
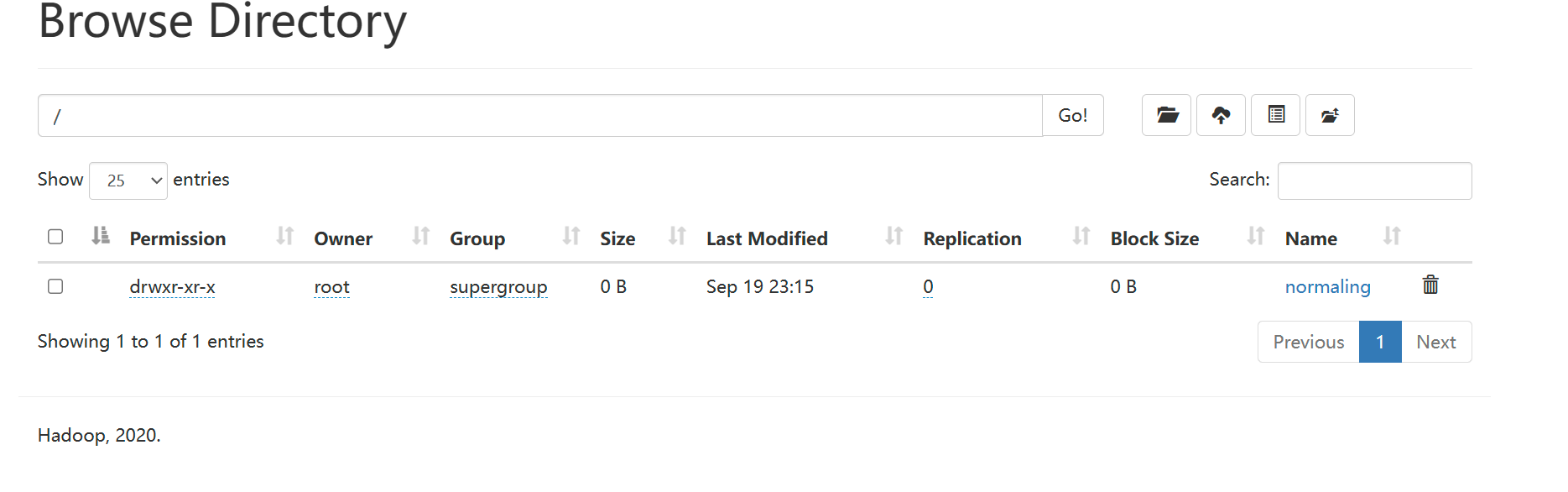
HDFS本質(zhì)就是一個(gè)文件系統(tǒng),有目錄樹(shù)結(jié)構(gòu),和Linux類(lèi)似,分文件,文件夾。

 浙公網(wǎng)安備 33010602011771號(hào)
浙公網(wǎng)安備 33010602011771號(hào)