
【ACL Review】消極想法的認(rèn)知重建:通過人類與語言模型的交互
1.論文背景
本論文是一篇ACL 2023的論文《Cognitive Reframing of Negative Thoughts through Human-Language Model Interaction》,主要講的是一個(gè)人類-語言模型交互的工具。
本文(這篇筆記)的組織形式是順讀文章,從頭到尾捋一遍邏輯,作為一片筆記。
2.內(nèi)容分析
2.1 摘要

直接翻譯:克服消極想法的一種行之有效的治療技術(shù)是用更有希望的“重構(gòu)想法”取代它們。
Reframing看起來不是很好理解,翻譯為“重構(gòu)”。therapy是療法。
簡(jiǎn)單來講,文中是提出了一種方法,幫助人們修正自己的認(rèn)知和想法。最后的結(jié)論是跟預(yù)想的一樣,更高的同情或者積極的重構(gòu),比過度積極的想法更能讓人接受。
看到這里,如果是計(jì)算機(jī)類的同學(xué)可能又要嘀咕:這又是沒什么技巧的心靈雞湯吧。確實(shí),第一感覺,ACL確實(shí)無愧于故事會(huì)的調(diào)侃。
但是既然是一個(gè)會(huì)議,應(yīng)該也要允許不同人呈現(xiàn)的價(jià)值。兼容并包是科研人必備的胸懷。例如本文之中到底是怎么量化一個(gè)指標(biāo)的?
往下看
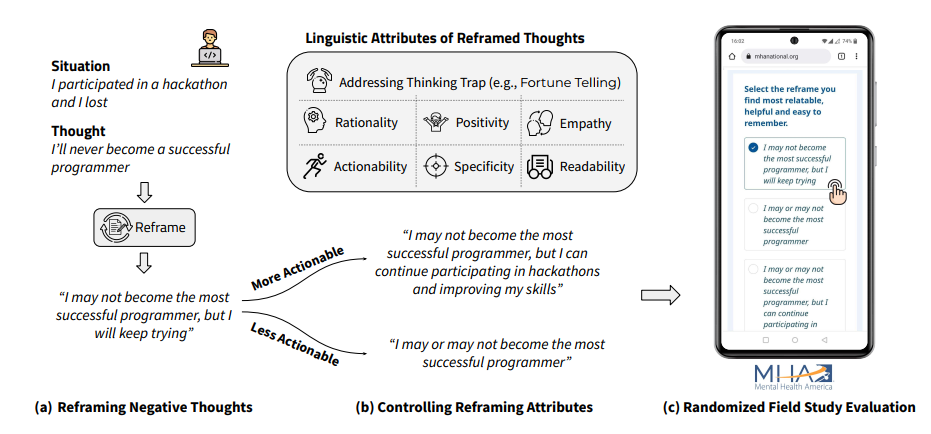
這里給了個(gè)圖,比較直觀,在一個(gè)場(chǎng)景下和人的內(nèi)心活動(dòng)下,把內(nèi)心活動(dòng)改寫陳述,以使得人們有更好的認(rèn)知。
為了量化這個(gè)指標(biāo),定義了六個(gè)屬性/指標(biāo)。重新生成新的語句,并評(píng)估它在六個(gè)屬性下的效果。
Q: 這里的指標(biāo)有點(diǎn)拍腦袋想出來的,不過本來也是比較主觀的研究,所以我們看看下面是不是有在主觀下的量化。
想要判定哪些因素會(huì)影響重構(gòu),語言模型是怎么幫助人們的。
2.2 問題和定義
定義了文本內(nèi)容的行動(dòng)力,理智,積極性,同情度,明確度,可讀性六個(gè)方面。

認(rèn)知陷阱。如:設(shè)想其他人的想法;極端化;最差預(yù)估;預(yù)測(cè)未來等。這個(gè)指標(biāo)的含義是用了評(píng)價(jià)一個(gè)想法是否陷入了認(rèn)知陷阱,陷入程度越高,顯然越不好。
數(shù)據(jù)集的標(biāo)記,是收集了原始語句,和reframe過的語句,打上相應(yīng)的標(biāo)簽。它是自己構(gòu)建的數(shù)據(jù)集。
Q: 事實(shí)上,自己構(gòu)建數(shù)據(jù)集應(yīng)該是ok的,但是在一篇文章里又做了收集數(shù)據(jù),又加了自己做了一些標(biāo)記,那重點(diǎn)可能就容易分散了。而且從數(shù)據(jù)集合來看,規(guī)模是相當(dāng)小的。
招募的人群是通過華盛頓大學(xué)的相關(guān)機(jī)構(gòu)發(fā)布公告而來的。
Q:評(píng)估的人群應(yīng)該是美國(guó)的,對(duì)于不同文化背景和社會(huì)心理的其他國(guó)家,是不是有相同的分析過程和結(jié)論也需要打個(gè)問號(hào)。
數(shù)據(jù)的收集是從人群中訪問并得到的,數(shù)據(jù)量級(jí)不超過1000。數(shù)據(jù)的格式是場(chǎng)景(Situation)和想法(Thought)。給出的輸出是R(Reframe)。
2.3 度量方法
回顧一下1+6個(gè)指標(biāo):認(rèn)知陷阱,理智性,積極性,同情度,行動(dòng)力,明確度,可讀性
1)認(rèn)知陷阱:用多標(biāo)簽分類任務(wù),這些數(shù)據(jù)是專家標(biāo)記的,并用來微調(diào)GPT-3模型。這是一個(gè)心理學(xué)類的研究,所以心理學(xué)家的知識(shí)會(huì)派上用場(chǎng)。當(dāng)然這里說心理學(xué)家,并沒有說專家一定有多么神奇,但是在一個(gè)研究領(lǐng)域有過訓(xùn)練的
人會(huì)遵循類似的研究規(guī)范,也容易和其他人以類似的語言進(jìn)行交流和溝通。
2)理智性:根據(jù)場(chǎng)景和陳述,多次遞歸地生成解釋(如解釋的解釋),用一個(gè)論證強(qiáng)度的度量公式判斷解釋跟事實(shí)的復(fù)合程度;推理強(qiáng)度的公式RS沒有給出具體的計(jì)算公式(在附錄里)。
思路是根據(jù)給GPT類模型兩種prompt,用以估計(jì)假設(shè)合理或不合理的概率。
Q: 這里RS讓人看不懂,如果有進(jìn)一步的解釋就好了。而且注意到利用了GPT-3預(yù)測(cè)單詞的方式來給出分類的概率,所以GPT-3應(yīng)該是指那個(gè)開源的版本。
3)積極性:也是轉(zhuǎn)成了分類任務(wù),可以用RoBERTa分類器進(jìn)行情感分析。
4)同情度:用分類器給同情心分級(jí)。
5)行動(dòng)力:把它變成一個(gè)二分類問題,一類是有明確行動(dòng)的,一類是沒有的。利用了語言模型的prompt,給出下一個(gè)動(dòng)作的候選集合,如果給出的候選集合的動(dòng)作更多樣化,則說明是模糊的。
6)明確度:利用embedding判斷R跟S,T的相似度。
7)可讀性:用已有的CLI指標(biāo)評(píng)估。
Q: 這里有好幾個(gè)都是利用了語言模型的能力自動(dòng)生成并用embedding評(píng)估它們的相似度。可以看到這也是LLM成為熱點(diǎn)之后經(jīng)常出現(xiàn)的方法(生成樣例+embedding)。方法是比較簡(jiǎn)單,但是也依賴于語言模型的能力,一定程度上削減了可復(fù)現(xiàn)性。
5.2節(jié)內(nèi)容:

這一節(jié)講了如何生成reframe的場(chǎng)景和想法。作者指出他們直接利用上下文學(xué)習(xí)無法達(dá)到很好的reframe生成質(zhì)量,因此他們采用了基于檢索的上下文學(xué)習(xí)方法。(簡(jiǎn)單來講這個(gè)就是生成多個(gè)采用一個(gè)最好的)這個(gè)是可以理解的,其實(shí)就是生成多個(gè)取前k個(gè)并用相似度找到最匹配的結(jié)果。但是這里似乎沒有說明是怎么評(píng)估reframe的生成質(zhì)量的,直接用了最簡(jiǎn)單的cosine相似度,并不能很讓人信服。也許這是一個(gè)約定俗成的方法,但是這里并沒有給出解釋。
5.3節(jié)講的是利用控制變量法生成reframe。根據(jù)之前生成的S,T對(duì),可以給GPT-3一些指定樣例的提示,讓GPT-3自己學(xué)習(xí)在某個(gè)屬性上的高低的區(qū)別,然后讓GPT-3根據(jù)輸入R生成變化的R。
也就是說如果已經(jīng)有了一個(gè)想法,我們想把它轉(zhuǎn)換成一個(gè)更加消極,但是其他指標(biāo)保持不變的想法;或者更加有行動(dòng)力而其他指標(biāo)不變,可以通過GPT-3直接生成樣例R。這也是一個(gè)神奇的應(yīng)用,前提是語言模型的能力
真的可以通過簡(jiǎn)單的prompt做到學(xué)習(xí)到一個(gè)簡(jiǎn)單的樣例中蘊(yùn)含的語義。
問題:盡管從直覺上看,GPT-3可以學(xué)到兩個(gè)樣例的差別,但是語言模型是否真的能根據(jù)這個(gè)差別生成合適的樣例,也值得懷疑。另外,如果每個(gè)屬性只有兩種類別的樣例,那是否意味著沒有辦法生成更多樣的數(shù)據(jù)?
6節(jié)講了評(píng)測(cè)指標(biāo)。用了BLEU指標(biāo),但是沒有說明為什么要用這個(gè)指標(biāo)。它是想評(píng)估語言還是這個(gè)生成模型的功能?BLEU是語言翻譯的指標(biāo),在這里使用是不是意味著作者把這個(gè)任務(wù)當(dāng)作是一個(gè)翻譯任務(wù)呢?也就是換句話說,文章的開頭所講是為了把描述生成為積極的想法。但是到了后面,先不說數(shù)據(jù)集正確答案的來源和可靠性,任務(wù)似乎就變成了一個(gè)翻譯模型,但是又沒有解釋這個(gè)指標(biāo)的意義。
7節(jié)標(biāo)題是Randomized Field Study。在大型心理健康平臺(tái)上部署了模型。
從上文可以看到,每個(gè)屬性都用到了一個(gè)模型,部署到一個(gè)平臺(tái)上的意思,應(yīng)該是指這個(gè)平臺(tái)用了他們的算法并且在線上驗(yàn)證了。根據(jù)文章所說,參與者樣本有2000多名。
問題:這里的Randomized Field Study起名似乎有點(diǎn)隨意了,可能讓人誤解為條件隨機(jī)場(chǎng)(CRF)。從下文可以看到,這里的含義應(yīng)該是指在隨機(jī)樣本下一些指標(biāo)對(duì)評(píng)估指標(biāo)的影響。
7.2節(jié) 哪種語言的屬性在認(rèn)知重建上的作用最好。
從圖表來看,平均而言的,更理性的想法跟相關(guān)性呈正相關(guān);更有行動(dòng)力和明確性的想法跟有幫助呈現(xiàn)正相關(guān),等等。
這里的疑問是,似乎跟我們的認(rèn)知是一樣的。但是如果以平均值作為度量,是不是意味著不同的人的差異會(huì)被抹掉?如果不想被抹掉,做多分類,那么是否可能會(huì)錯(cuò)誤的使用一個(gè)群體的平均值去評(píng)估個(gè)人對(duì)不同指標(biāo)的偏好?
8節(jié),解釋了數(shù)據(jù)集的來源,包括100個(gè)手寫的場(chǎng)景和想法。本文的研究方法是人類-語言模型交互工具,并且作者宣稱它是可擴(kuò)展的。當(dāng)然作者在這里并沒有說明是哪方面的scalable。如果是微調(diào)語言模型以產(chǎn)生不同指標(biāo),那么在指標(biāo)變多的情況下,是不是還能產(chǎn)生比較精準(zhǔn)的生成效果,還是有疑問的。而且手工設(shè)計(jì)prompt本身可能也不是很scalable。
9節(jié),倫理研究
主要就是介紹了進(jìn)行這項(xiàng)研究需要的許可,以及防止生成有害內(nèi)容的方式。跟一般的技術(shù)文章不太一樣。
3.優(yōu)點(diǎn)
盡管內(nèi)容可能不是很硬核,但是在社會(huì)效益上還是比較有意義的。而且分析和度量的工作量也是足夠的(個(gè)人感覺)。
4.關(guān)聯(lián)論文
LEFT BLANK
Reference
Cognitive Reframing of Negative Thoughts through Human-Language Model Interaction. In Proceedings of the 61st ACL (Volume 1: Long Papers), pages 9977–10000, Toronto, Canada. Association for Computational Linguistics.

 浙公網(wǎng)安備 33010602011771號(hào)
浙公網(wǎng)安備 33010602011771號(hào)