
大數據基礎原理
1. 背景
在各行各業的發展中,無論來源、記錄方式如何,人們必然會積累各種各樣的數據,并且傾向于通過統計數據分析現實情況,以此作為指導行動方向的依據。因此,統計學中一直圍繞著數據進行建模與問題分析,給出對數據背后反映問題的判斷。
由于計算機的發展,承載數據統計和分析的實體自然而然地變成了各式各樣的計算機。在計算機和互聯網的發展下,在數據分析領域也催生了一些新的計算形態。而且盡管各種行業的數據模型不同, 但是不同需求之間是有共性的。
如今已經為人熟知的大數據的概念,包括規模的增長,異構多樣的數據帶來的各種處理需求,其實在計算機領域是可以預見到的。在小數據,單機的情況下可以良好工作的算法,在數據規模激增的情況下不一定行得通,需要以各種新的設計來解決相應的問題。
在硬件上,表現為多核處理器和多機系統的發展;在軟件層面,有對應高性能并行計算的MPI,當然也有以Google的MapReduce為濫觴的一系列集群式ETL的數據處理框架。
Hadoop是大數據處理框架在開源社區的先驅,下文僅討論Hadoop生態相關的計算框架。
發展歷程
由于提升單臺計算機的成本曲線讓人望而生畏, 由相對廉價的計算機集群執行的分布式計算成為了一種現實的選擇。
因為互聯網業務的特點,處理大量的文檔,網絡請求日志來生成報告乃至進行機器學習,大規模圖學習成為其常見的場景。伴隨著這些場景,Google的工程師實踐并提出了MapReduce計算模型,同時貢獻了GFS,Big Table。之后, 業界逐漸出現并演化了一批用于大數據處理的框架和組件,Hadoop即是其中的早期代表。
Hadoop的組成至少包含以下部分:
yarn是計算集群任務調度的服務中心;map reduce計算引擎;hdfs的文件系統。
MapReduce本身的概念其實并不難理解,但是其面對真實場景需要解決大量的工程問題。
以Hadoop為例,其本身就要處理很多異常情況。典型問題,如在集群中出現節點異常是家常便飯,每一步都可能出錯或者被意外中斷;mapreduce的數據分片經歷了大量的基準測試和優化,在不同場景下要達到高性能的配置也相當復雜。hadoop的實現也沒有達到一個完美的地步。hadoop只能處理批量離線數據,而且為了使用它執行一個操作經常需要做很多的MapReduce組合。由于其數據在處理過程中大部分都需要落盤,因此hadoop在性能上并沒有優勢,直接使用map reduce的方式到今天為止已經完全淡出工業界了。
盡管如此,入門大數據領域的時候了解MapReduce仍然是有其意義的。
2. MapReduce計算模型
我們了解一下MapReduce的計算模型。
MapReduce是一個在多個節點的集群中處理數據的計算框架/過程。一個MapReduce的系統通常由map、shuffle和reduce組成。數據的流向是從master節點發送數據開始, 到reduce節點結束。
一個典型的map reduce包含下圖幾個階段:

map,reduce的計算形式:
map (k1, v1) -> list(k2, v2)
reduce (k2, list(v2)) -> list(v2)
map階段之前,數據會形成分片,由master節點派發給不同的worker節點;每個數據的分片中可能包含了不同的key;
map階段,每個worker節點執行map計算任務;
map階段是并行的,在worker節點計算輸出后保存(本地),傳給下一個階段;
從map到reduce,數據會經歷shuffle,其過程取決于具體的實現,并不是統一的;
reduce階段也是在worker節點完成。worker接收到master節點分配的reduce任務,拉取map階段的輸出作為輸入,計算最終的輸出。跟Map階段不同,Reduce階段不能并行。
如何容錯
master節點記錄了每個節點的任務狀態,并且通過ping來判斷worker節點是否失敗; master節點在worker任務失敗的時候會重置worker節點的狀態;整個任務的執行依賴于worker對任務處理的原子性。
combiner函數
MapReduce同時包含了combiner函數,也是針對map的輸出進行處理,跟reducer的區別是,它是處理worker本地數據的,其輸出將作為reducer的輸入;針對本來要發送給reducer的數據,做一些局部的排序或合并。而有序的數據在處理上可以取出小塊切片后reduce而不影響結果,既能減少網絡IO,也能減少reduce階段的計算量。
shuffle階段
shuffle包含map階段和reduce階段的操作,是一個統稱;
在map階段,根據key,val將數據劃分到指定的reduce任務,這個叫做partitioner,也是shuffle的一個階段;
在reduce階段,shuffle根據map輸出的結果,對內存和磁盤內的數據處理,對將由同一個reducer處理的數據進行合并。
需要注意的是,reduce階段的shuffle排序和合并的算法在使用Spark框架的時候無法定制,僅能通過comparator指定如何排序。
combiner優化
當reduce滿足結合律,可以使用reducer直接替換combiner
如果reduce不滿足結合律,無法直接用reducer替換combiner,具體問題具體分析
2.1 MapReduce combiner的實際計算樣例
計算平均值:
combiner是優化中間計算的一種方式,當使用combiner時,需要注意reducer是否滿足結合率;
不妨設兩個節點上有待執行map的數據集合,為A1,A2,顯然,列數據的平均值不能用各自平均值取平均: AVG(AVG(A1), AVG(A2)) != AVG(A1∪A2)
這種情況需要在每條數據附加一個記錄數1,最后在reduce階段以總數和記錄總數求得平均值;
計算中位數
另一個例子是計算數據的中位數: 這個目標任務的combiner函數不能是簡單的取中位數。
一種方案是將map 輸出的v2存為列表,這種方法會占用較多的內存;
在第一種方案的基礎上其實可以進行優化:不保留所有的v2,而是記錄v2的取值和對應的計數,最后得到的就是類似<k1, v1, count1>, <k2, v2, count2> ...的輸出,其中列表是排好序的,在reduce階段,遍歷key的列表,在count1+count2...超過一半的總數時得到對應的中位數;同樣可以優化內存的使用。
2.2. Spark計算框架
Spark是一個最為流行的大數據計算引擎。Spark基于hadoop的mapreduce計算模型做出抽象,并且在原有的資源調度、迭代計算的基礎上做了許多優化,同時保留了對hadoop的hdfs,yarn等依賴。盡管它跟hadoop有關聯,但是其跟hadoop并不是互為替換的關系。除此之外,伴隨著更加方便的API和程序框架誕生的其他計算組件,則構建了Spark大數據處理的生態。
2.3 Hadoop Shuffle和Spark Shuffle
從功能上看,Hadoop和Spark的Shuffle是類似的,沒有區別。從實現的細節上,兩者才有不同。map端的shuffle一般為shuffle的Write階段,reduce端的shuffle一般為shuffle的read階段。
相對于Hadoop的 MapReduce,最開始的Spark在默認的情況下不對 Shuffle 的數據進行排序,即Hash Shuffle,目的是為了減少shuffle時候的性能浪費,對不需要排序的數據忽略這一步。但是,后來Spark的Shuffle經歷了Hash、Sort、Tungsten-Sort(堆外內存)三階段發展歷程。
對于Hash Shuffle來說,在 Map Task 過程按照 Hash 的方式重組 Partition 的數據,不進行排序。每個 Map Task 為每個 Reduce Task 生成一個文件,通常會產生大量的文件(即對應為 M*R 個中間文件),伴隨大量的隨機磁盤 I/O 操作與大量的內存開銷。
在Spark 1.2以后的版本中,默認的ShuffleManager改成了SortShuffleManager。SortShuffleManager相較于HashShuffleManager來說,有了一定的改進。主要就在于,每個Task在進行shuffle操作時,雖然也會產生較多的臨時磁盤文件,但是最后會將所有的臨時文件合并(merge)成一個磁盤文件,因此每個Task就只有一個磁盤文件。在下一個stage的shuffle read task拉取自己的數據時,只要根據索引讀取每個磁盤文件中的部分數據即可[4]。而且針對不同的算子,會判斷是否啟用SortShuffle,從而避免不必要的排序。
2.4 Spark SQL, Spark Streaming, Structured Streaming
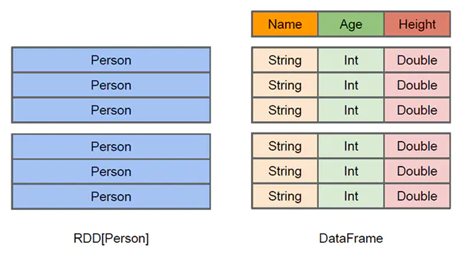
在Spark中,會用到RDD,DataFrame,DataSet(類似DataFrame)幾種核心數據結構。
RDD為resilient distributed dataset,彈性分布式數據集,其結構上是Java 或Scala對象的集合.。Spark中在其上定義了很多操作,并且其接口類似函數式編程,能夠簡潔直觀地表示一系列操作。其缺點是性能難以優化,而且會帶來使用的時候本質上要自己維護DAG的困難。
DataFrame是數據的一個不可變分布式集合,其結構是列式存儲,區別于RDD, 可以通過其列名直接訪問數據列;相較RDD,DataFrame 是高級的 API,提供類似于SQL 的 query 接口。
Spark Steaming的出現早于Structured Streaming,處理的對象是DStream, 而Structured Streaming是Spark 2.0發布帶來的特性,處理的對象是DataFrame。
兩者都是以時間劃分出微批處理,針對一定時間間隔的小批數據進行處理,以此模擬流式數據處理。
其中,Spark Steaming接近RDD對象數據結構,缺點是效率不高。而Structured Streaming同樣是微批處理的形式,但其在DataFrame基礎上的流式處理性能提升了。
簡單來說,跟Hadoop相比,Spark具有如下的優點:
基于DAG的任務執行調度機制,算子的更強表現力,降低了開發的心智負擔,更加貼近實際的開發;更加高效的計算執行模式,讓更多的數據計算直接在內存中執行減少IO開銷。
3. 設計模式、算子與流式計算
MapReduce設計模式
從MapReduce開始,其實就已經有了很多設計模式,可以參見《MapReduce設計模式》。
一些典型的設計模式如下:
數值概要設計模式 numerical summarization pattern,計算總數,最大值,最小值等都是概要模式
索引模式 indexing pattern 產生一個數據集的索引以達到快速檢索的目的,例如文本的倒排索引
過濾模式 filtering pattern 過濾掉一些不需要的數據。
Spark的算子或多或少是這些map reduce設計模式的體現。
算子的分類
(1)Transformation變換/轉換算子:這種變換不會執行真正的作業,因為一些變換不需要馬上得到結果,而且可以在多個變換后計算復合操作,減少計算量。
(2)Action行動算子:這類算子會觸發提交job作業,并將數據輸出到Spark系統。
Transformation變換/轉換算子
1. map算子
2. flatMap算子
3. mapPartitions算子
4. mapPartitionsWithIndex算子
5. cache算子、persist算子
6. union算子
7. cartesian算子
8. groupBy算子
9. filter算子
10. sample算子
11. combineByKey 算子 reduceByKey算子
12. join算子
Action類型的算子:
1.foreach
2.saveAsTextFile
3.collect
4.count
4. Hadoop生態的組件
Pig 和Hive
Pig和HiveQL是在HDFS上使用的數據查詢語言。
HBase, Cassandra, HDFS
HBase是仿照谷歌BitTable的開源實現,是面向列的開源數據庫;HDFS是GFS的開源實現,是一種文件系統;Cassandra是個分布式的key-value數據庫。
Pregel,GraphX
圖數據結構是分布式計算中一個重要的領域。圖的數據可以分為網絡、樹、類RDBMS結構、稀疏矩陣以及其它一些結構(from Spark GraphX in Action)。為了處理圖,在OLTP領域有Neo4j, NebulaGraph等組件;而在OLAP領域以Pregel,GraphX等為代表。
Pregel是一個迭代式的分布式圖計算算法和系統,在此基礎上有Spark的GraphX。到目前為止,GraphX還有一些尚未實現的特性和優化空間。
數據轉換Sqoop
sqoop 是一個數據庫轉換的工具,提供了從hadoop文件格式到關系型數據庫之間的數據互轉。
Storm,Flink
前面講到Spark可以進行流式數據的處理,然而Spark到目前為止的流式處理延遲只能達到秒級,而另外兩種流式處理框架Storm、Flink可以達到μs到ms級。
這里只講Flink。為什么Spark跟Flink會有如此大的差異,主要還是數據處理原理的差異。Spark的處理方式是將流式處理看作批處理的一種特殊形式,每收到一個間隔的數據才進行處理,在實時性上難以提升。
而Flink處理的模型是基于算子(operator)的連續數據流。Flink設計了一套高度靈活的窗口機制,從而對數據能夠執行真正的流式計算,每有一條數據就能進行期望的算子操作。

上圖中是一個Dataflow,數據src,數據sink,以及transformation算子均為節點,它們通過stream相連.數據從一個operator出發,經過stream被其他operator處理。同時,一個 stream 可以包含多個分區,一個算子可以被分成多個算子的子任務,每一個子任務是在不同的線程或者不同的機器節點中獨立執行的。
Flink也提供了跟Spark一樣的DataSet,DataStream API,下圖是Flink的架構。

5. 計算樣例
PageRank如何使用MapReduce計算
PageRank是搜索引擎中一個計算網頁重要性的算法。可以使用Map Reduce實現簡化的PageRank。在一個圖中,網頁之間通過超鏈接相連,因此可以用一個有向圖/鄰接矩陣表示。
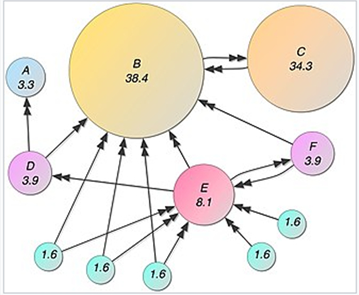
PageRank的數據結構:
矩陣F(A,B),項F(x,y)表示從A到B的出鏈關系,1為有出鏈
算法:
初始化的時候每個網頁是一個相同的均值,每次的網頁i的值為剛好其他網頁權重按比例分配給它的權重之和。
而對網頁i來說,它分配給其他網頁的權重是其已有權重的平均值。即W(u) = Σ D(v屬于Su)/Out(v)。
Map的時候,針對網頁u,計算網頁u到其他網頁的權重,每條記錄<u,W(u)>變成列表<vi,W(u)/count(vi∈Su)> (i = 1,2,...)
Reduce的時候,由vi為key,加和所有的權重,即得到網頁v的權重。(v跟u不是同一個網頁)
一次計算得到的權重不是最終結果,PageRank要經過多次迭代計算得到最終各個網頁的權重[7]。
這是一個馬爾科夫隨機過程。為了避免該過程不收斂,可以加入虛擬的節點,以及一個概率點擊系數,表示從任意節點可能跳轉到該節點的概率。
References
[1] Dean J , Ghemawat S . MapReduce: Simplified Data Processing on Large Clusters[C]// Proceedings of the 6th conference on Symposium on Opearting Systems Design & Implementation - Volume 6. USENIX Association, 2004.
[2] MapReduce-MPI Library, https://mapreduce.sandia.gov/
[3] Hadoop Map/Reduce教程, http://hadoop.apache.org/docs/r1.0.4/cn/mapred_tutorial.html
[4] MapReduce Shuffle 和 Spark Shuffle, https://cloud.tencent.com/developer/article/1651735, 2020
[5] Carbone P , Katsifodimos A , ? Kth, et al. Apache flink : Stream and batch processing in a single engine. 2015.
[6] Data Streaming Fault Tolerance, https://ci.apache.org/projects/flink/flink-docs-release-1.3/internals/stream_checkpointing.html#checkpointing
[7] PageRank in Map Reduce, https://medium.com/swlh/pagerank-on-mapreduce-55bcb76d1c99

 浙公網安備 33010602011771號
浙公網安備 33010602011771號