
atomic
atomic(原子類)
- 不可分割
- 一個操作是不可中斷的,即便是多線程的情況下也可以保證
- java.util.concurrent.atomic
- eTnrNEEOT原子類的作用和鎖類似,是為了1保證開發情況下線桂女生。個個過原子類相比于鎖,有一定的優勢:
- 粒度更細:原子變量可以把競爭范圍縮小到變量級別這是我們可以獲得的最細粒度的情況了,通常鎖的粒度都要大于原子變量的粒度
- 效率更高:通常,使用原子類的效率會比使用鎖的效率更高除了高度競爭的情況
6類原子類
Atomic*基本類型原子類 | Atomiclnteger AtomicLong AtomicBoolean |
Atomic*Array數組類型原子類 | AtomiclntegerArray、 AtomicLongArray、 AtomicReferenceArray |
Atomic*Reference引用類型原子類 | AtomicReference、 AtomicStampedReference、 AtomicMarkableReference |
Atomic*FieldUpdater升級類型原子類 | Atomiclntegerfieldupdater、 AtomicLongFieldUpdater、 AtomicReferenceFieldUpdater |
Adder累加器 | LongAdder、DoubleAdder |
Accumulator累加器 | LongAccumulator、 DoubleAccumulator |
AtomicInteger
常用方法
public final int get() //獲取當前的值
public final int getAndSet(int newValue) //獲取當前的值,并設置新的值
public final int getAndIncrement() //獲取當前的值,并自增
public final int getAndDecrement() //獲取當前值,并自減
public final int getAndAdd(int delta) //獲取當前值,并加上預期的值
bollean compareAndSet(int expect,int update) //如果輸入的數值等于預期值,則以原子方式將該值設置為輸入值
Atomic*Array
Atomic*Reference
AtomicReference:AtomicReference類的作用,和AtomicInteger并沒有本質區別,AtomicInteger可以讓一個整數保證原子性,而AtomicReference可以讓一個對象保證原子性,當然,AtomicReference的功能明顯比AtomicInteger強,因為一個對象里可以包含很多屬性。用法和AtomicInteger類似。
例子:自旋鎖
普通變量升級原子功能
AtomicIntegerFieldUpdater對變通變量進行升級
偶爾需要一個原子get-set操作,減少資源占用.
public class AtomicIntegerFieldUpdaterDemo implements Runnable{
static Candidate tom;
static Candidate peter;
public static AtomicIntegerFieldUpdater<Candidate> scoreUpdater = AtomicIntegerFieldUpdater
.newUpdater(Candidate.class, "score");
@Override
public void run() {
for (int i = 0; i < 10000; i++) {
peter.score++;
scoreUpdater.getAndIncrement(tom);
}
}
public static class Candidate {
volatile int score;
}
public static void main(String[] args) throws InterruptedException {
tom=new Candidate();
peter=new Candidate();
AtomicIntegerFieldUpdaterDemo r = new AtomicIntegerFieldUpdaterDemo();
Thread t1 = new Thread(r);
Thread t2 = new Thread(r);
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println("普通變量:"+peter.score);
System.out.println("升級后的結果"+ tom.score);
}
}
注意點:
可見范圍
不支持static
Adder累加器
高并發下LongAdder比AtomicLong效率高,不過本質是空間換時間。
競爭激烈時,LongAdder把不同線程對應到不同的Cell上進行修改,降低了沖突的概率,是多段鎖的理念,提高了并發性。
多線程下AtomicLong的性能,每一次加法,都要flush和refresh,導致很耗費資源。
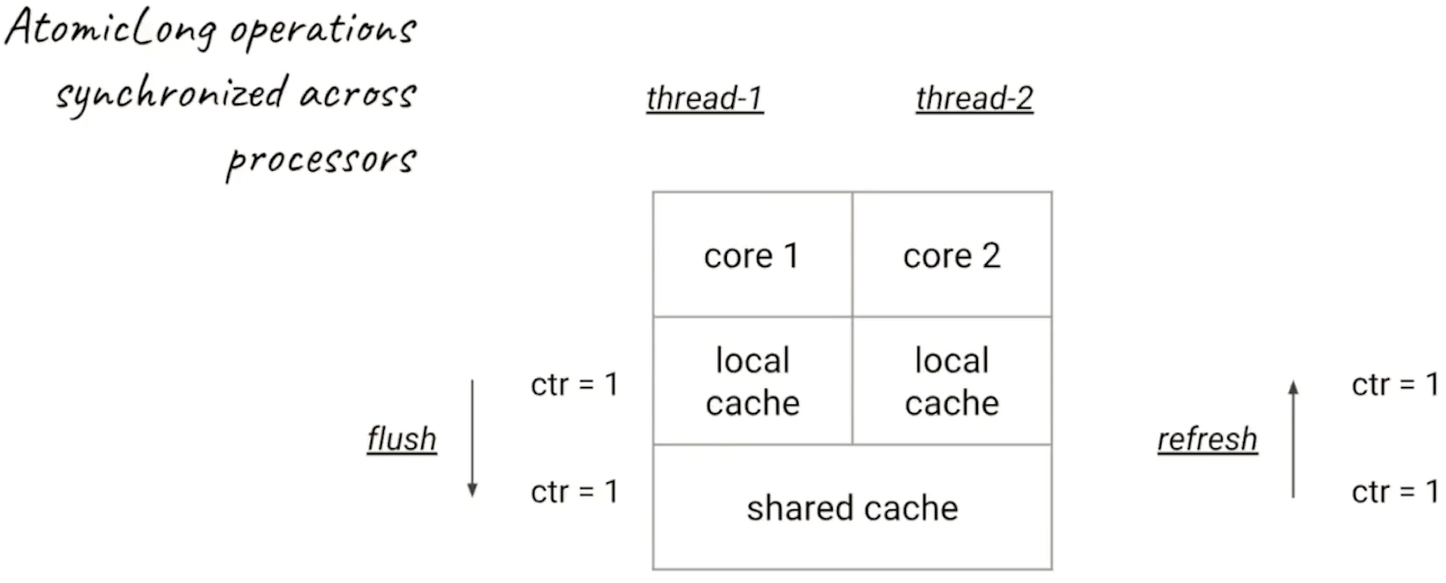
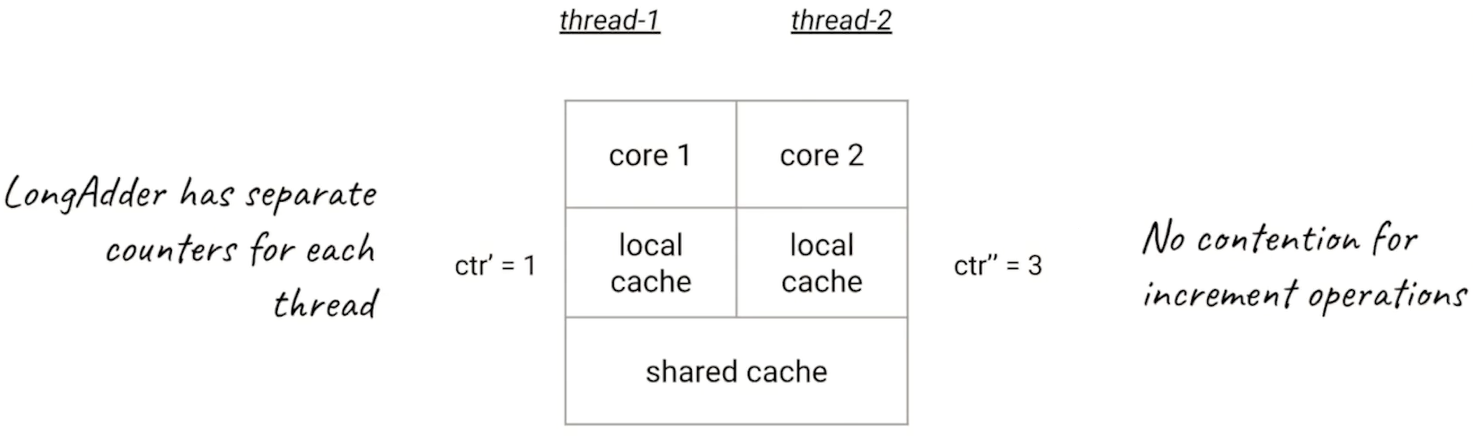
- 在內部,這個LongAdder的實現原理和剛才的AtomicLong是有不同的,剛才的AtomicLong的實現原理是,每一次加法都需要做同步,所以在高并發的時候會導致沖突比較多,也就降低了效率。
- 而此時的LongAdder,每個線程會有自己的一個計數器,僅用來在自己線程內計數,這樣一來就不會和其他線程的計數器干擾。
- 如圖中所示,第一個線程的計數器數值,也就是ctr',為1的時候,可能線程2的計數器ctr'’|的數值已經是3了,他們之間并不存在競爭關系,所以在加和的過程中,根本不需要同步機制,也不需要剛才的flush和refresh。這里也沒有一個公共的counter來給所有線程統一計數。
LongAdder引入了分段累加的概念,內部有一個base變量和一個Cell[]數組共同參與計數:
- base變量:競爭不激烈,直接累加到該變量上
- Cell[]數組:競爭激烈各個線程分散累加到自己的槽Cell[i]中
sum源碼分析
public long sum(){
Cell[] as =cells;
Cell a;
long sum =base;
if (as !=null){
for (int i=0;i<as.length;++i){
if ((a =as))!=null)
sum +=a.value;
}
` }
return sum;
}
對比AtomicLong和LongAdder
- 在低爭用下,AtomicLong和LongAdder這兩個類具有相似的特征。但是在競爭激烈的情況下,LongAdder的預期吞吐量要高得多,但要消耗更多的空間
- LongAdder適合的場景是統計求和計數的場景,而且LongAdder基本只提供了add方法,而AtomicLong還具有cas方法
Accumulator累加器
與Adder非常相似,是更通用版本的Adder
public LongAccumulator(LongBinaryOperator accumulatorFunction, long identity)
@FunctionalInterface
public interface LongBinaryOperator {
/**
* Applies this operator to the given operands.
*
* @param left the first operand
* @param right the second operand
* @return the operator result
*/
long applyAsLong(long left, long right);
}
identity 賦值到applyAsLong函數參數left
accumulator.accumulate(i); i賦值到applyAsLong函數參數left;right為上次applyAsLong返回值
LongAccumulator accumulator = new LongAccumulator(LongAccumulatorDemo::applyAsLong, 1);
private static long applyAsLong(long x, long y) {
return 2 + x * y;
}

 浙公網安備 33010602011771號
浙公網安備 33010602011771號