
基于C#的機器學習--深層信念網絡
我們都聽說過深度學習,但是有多少人知道深度信念網絡是什么?讓我們從本章開始回答這個問題。深度信念網絡是一種非常先進的機器學習形式,其意義正在迅速演變。作為一名機器學習開發人員,對這個概念有一定的了解是很重要的,這樣當您遇到它或它遇到您時就會很熟悉它!
在機器學習中,深度信念網絡在技術上是一個深度神經網絡。我們應該指出,深度的含義,當涉及到深度學習或深度信念時,意味著網絡是由多層(隱藏的單位)組成的。在深度信念網絡中,這些連接在一層內的每個神經元之間,而不是在不同的層之間。一個深度信念網絡可以被訓練成無監督學習,以概率重建網絡的輸入。這些層就像“特征檢測器”一樣,可以識別或分類圖像、字母等等。
在本章,我們將包括:
受限玻爾茲曼機
在c#中創建和培訓一個深度信念網絡
受限玻爾茲曼機
構建深度信念網絡的一種流行方法是將其作為受限玻爾茲曼機(RBMs)的分層集合。這些RMBs的功能是作為自動編碼器,每個隱藏層作為下一個可見層。深度信念網絡將為訓練前階段提供多層RBMs,然后為微調階段提供一個前饋網絡。訓練的第一步將是從可見單元中學習一層特性。下一步是從以前訓練過的特性中獲取激活,并使它們成為新的可見單元。然后我們重復這個過程,這樣我們就可以在第二個隱藏層中學習更多的特性。然后對所有隱藏層繼續執行該過程。
我們應該在這里提供兩條信息。
首先,我們應該稍微解釋一下什么是自動編碼器。自動編碼器是特征學習的核心。它們編碼輸入(輸入通常是具有重要特征的壓縮向量)和通過無監督重構的數據學習。
其次,我們應該注意到,將RBMs堆積在一個深度信念網絡中只是解決這個問題的一種方法。將限制線性單元(ReLUs)疊加起來,再加上刪除和訓練,然后再加上反向傳播,這又一次成為了最先進的技術。我再說一遍,因為30年前,監督方法是可行的。與其讓算法查看所有數據并確定感興趣的特征,有時候我們人類實際上可以更好地找到我們想要的特征。
我認為深度信念網絡的兩個最重要的特性如下:
l 有一個有效的,自上而下的逐層學習過程,生成權重。它決定了一個層中的變量如何依賴于它上面層中的變量。
l 當學習完成后,每一層變量的值都可以很容易地通過一個自底向上的單次遍歷推斷出來,該遍歷從底層的一個觀察到的數據向量開始,并使用生成權值逆向重構數據。
說到這里,我們現在來談談RBMs以及一般的玻爾茲曼機。
玻爾茲曼機是一個遞歸神經網絡,具有二進制單元和單元之間的無向邊。無向是指邊(或鏈接)是雙向的,它們沒有指向任何特定的方向。
下面是一個帶有無向邊的無向圖:
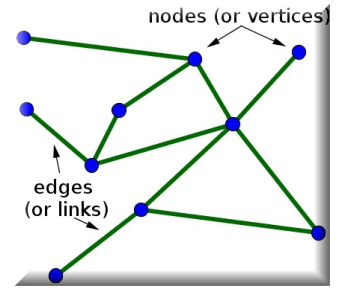
玻爾茲曼機是最早能夠學習內部表征的神經網絡之一,只要有足夠的時間,它們就能解決難題。但是,它們不擅長伸縮,這就引出了我們的下一個主題,RBMs。
引入RBMs是為了解決玻爾茲曼機器無法伸縮的問題。它們有隱藏層,每個隱藏單元之間的連接受到限制,但不在這些單元之外,這有助于提高學習效率。更正式地說,我們必須深入研究一些圖論來正確地解釋這一點。
RBMs的神經元必須形成二分圖,這是圖論的一種更高級的形式;來自這兩組單元(可見層和隱藏層)中的每一組的一對節點之間可能具有對稱連接。任何組中的節點之間都不能有連接。二分圖,有時稱為生物圖,是將一組圖頂點分解為兩個不相交的集合,使同一集合內沒有兩個頂點相鄰。
這里有一個很好的例子,它將有助于可視化這個主題。
注意同一組內沒有連接(左邊是紅色的,右邊是黑色的),但兩組之間有連接:
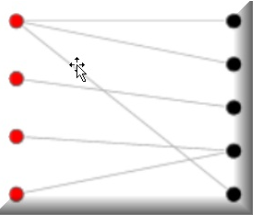
更正式地說,RBM是所謂的對稱二分圖。這是因為所有可見節點的輸入都傳遞給所有隱藏節點。我們說對稱是因為每個可見節點都與一個隱藏節點相關。
假設我們的RBM顯示了貓和狗的圖像,我們有兩個輸出節點,每個動物一個。在我們向前通過學習,我們的RBM問自己:“對于我看到的像素,我應該向貓或狗發送更強的權重信號嗎?”在它想知道“作為一只狗,我應該看到哪個像素分布?”我的朋友們,這就是今天關于聯合概率的課: 在給定A和給定X的情況下X的同時概率。在我們的例子中,這個聯合概率表示為兩層之間的權重,是RBMs的一個重要方面。
我們現在來談談重構,這是rbms的一個重要部分。在我們所討論的示例中,我們正在學習一組圖像出現哪些像素組(即打開)。當一個隱藏層節點被一個重要的權重激活時(無論決定打開它的權重是什么),它表示正在發生的事情的共同發生,在我們的例子中,是狗還是貓。如果這是一只貓,尖耳朵、圓臉、小眼睛可能就是我們要找的。大耳朵+長尾巴+大鼻子可能會讓你的形象變成一只狗。這些激活表示RBM“認為”原始數據的樣子。實際上,我們正在重建原始數據。
我們還應該迅速指出,RBM有兩個偏見,而不是一個。這是非常重要的,因為這是區別于其他自動編碼算法。隱藏的偏差幫助我們的RBM在向前傳遞時產生我們需要的激活,而可見的層偏差幫助我們在向后傳遞時學習正確的重構。隱藏的偏差很重要,因為它的主要工作是確保無論我們的數據有多么稀疏,一些節點都會被觸發。稍后您將看到這將如何影響一個深層信仰網絡的夢想。
分層
一旦我們的RBM了解了輸入數據的結構,它與在第一個隱藏層中進行的激活相關,數據就會傳遞到下一個隱藏層。第一個隱藏層然后成為新的可見層。我們在隱藏層中創建的激活現在成為我們的輸入。它們將乘以新隱藏層中的權重,以產生另一組激活。
這個過程在我們的網絡的所有隱藏層中繼續進行。隱藏層變成可見層,我們有另一個隱藏層,我們將使用它的權重,然后重復。每個新的隱藏層都會產生調整后的權重,直到我們能夠識別來自前一層的輸入為止。
為了更詳細地說明,這在技術上被稱為無監督的、貪婪的、分層的培訓。改進每一層的權值不需要輸入,這意味著不涉及任何類型的外部影響。這進一步意味著我們應該能夠使用我們的算法來訓練以前沒有見過的無監督數據。
正如我們一直強調的,我們擁有的數據越多,我們的結果就越好!隨著每一層圖像的質量越來越好,也越來越準確,我們就可以更好地通過每一個隱藏層來提高我們的學習能力,而權重的作用就是引導我們在學習的過程中進行正確的圖像分類。
但是在討論重構時,我們應該指出,每次重構工作中的一個數字(權重)都是非零的,這表明我們的RBM從數據中學到了一些東西。在某種意義上,您可以像處理百分比指標一樣處理返回的數字。數字越大,算法對它所看到的東西就越有信心。記住,我們有我們要返回的主數據集,我們有一個參考數據集用于我們的重建工作。當我們的RBM遍歷每個圖像時,它還不知道它在處理什么圖像;這就是它想要確定的。
讓我們花一點時間來澄清一些事情。當我們說我們使用貪婪算法時,我們真正的意思是我們的RBM將采用最短路徑來獲得最佳結果。我們將從所看到的圖像中隨機抽取像素,并測試哪些像素引導我們找到正確答案。
RBM將根據主數據集(測試集)測試每個假設,這是我們的正確最終目標。請記住,每個圖像只是我們試圖分類的一組像素。這些像素包含了數據的特征和特征。例如,一個像素可以有不同的亮度,其中深色像素可能表示邊框,淺色像素可能表示數字,等等。
但如果事情不像我們想的那樣,會發生什么呢?如果我們在給定步驟中學到的東西不正確會發生什么?如果出現這種情況,就意味著我們的算法猜錯了。我們要做的就是回去再試一次。這并不像看上去那么糟糕,也不像看上去那么耗時。
當然,錯誤的假設會帶來時間上的代價,但最終的目標是我們必須提高學習效率,并在每個階段減少錯誤。每一個錯誤的加權連接都會受到懲罰,就像我們在強化學習中所做的那樣。這些連接會減少重量,不再那么強。希望下一個遍歷可以在減少誤差的同時提高精度,并且權重越大,影響就越大。
假設我們對數字圖像進行分類,也就是數字。有些圖像會有曲線,比如2、3、6、8、9等等。其他數字,如1、4和7,則不會。這樣的知識是非常重要的,因為我們的RBM,會用它來不斷提高自己的學習,減少錯誤。如果我們認為我們處理的是數字2,那么這個路徑的權值就會比其他路徑的權值更重。這是一個極端的過度簡化,但希望它足以幫助你理解我們將要開始的內容。
當我們把所有這些放在一起,我們現在有了一個深層信仰網絡的理論框架。雖然我們比其他章節更深入地研究了理論,但是正如您所看到的我們的示例程序所工作的那樣,它將開始變得有意義。您將更好地準備在應用程序中使用它,了解幕后發生的事情。
為了展示深度信念網絡和RBMs,我們將使用Mattia Fagerlund編寫的出色的開源軟件SharpRBM。這個軟件對開源社區做出了不可思議的貢獻,我毫不懷疑您將花費數小時甚至數天的時間來使用它。這個軟件附帶了一些令人難以置信的演示。在本章中,我們將使用字母分類演示。
下面的截圖是我們的深度信念測試應用程序。有沒有想過電腦睡覺時會夢到什么?
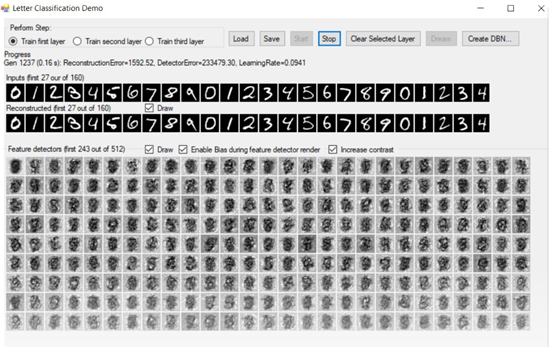
程序的左上角是我們指定要訓練的圖層的區域。我們有三個隱藏層,它們都需要在測試之前進行適當的訓練。我們可以一次訓練一層,從第一層開始。訓練得越多,你的系統就會越好:

訓練選項之后的下一部分是我們的進展。當我們在訓練時,所有相關的信息,如生成,重構誤差,檢測器誤差,學習率,都顯示在這里:

下一個是我們的特性檢測器的繪圖,如果選中Draw復選框,它將在整個訓練過程中更新自己:

當開始訓練一個層時,我們將注意到重構和特征檢測器基本上是空的。他們會隨著我們的訓練不斷完善自己。記住,我們正在重建我們已經知道是真實的東西!隨著訓練的繼續,重構的數字變得越來越清晰,我們的特征檢測器也越來越清晰:
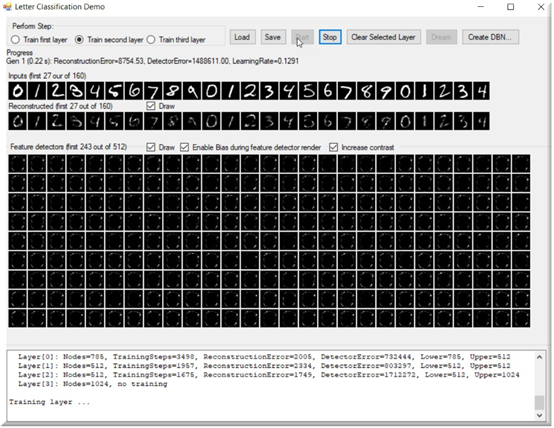
下面是訓練期間應用程序的快照。如圖所示,這是在第31代,重建的數字是非常明確的。
它們仍然不完整或不正確,但可以看到我們取得了多大的進步:

電腦在做夢?
電腦做夢時會夢到什么?對我們來說,直覺是一個特征,它允許我們看到計算機在重構階段在想什么。當程序試圖重建我們的數字時,特征檢測器本身將在整個過程中以各種形式出現。我們在dream window中顯示的就是這些形式(紅色圓圈表示):

我們花了很多時間查看應用程序的屏幕截圖。我想是時候看看代碼了。讓我們先看看如何創建DeepBeliefNetwork對象本身:
DeepBeliefNetwork = new DeepBeliefNetwork(28 * 29, 500, 500, 1000);
一旦創建了這個,我們需要創建我們的網絡訓練器,我們根據我們正在訓練的層的權重來做這件事:
DeepBeliefNetworkTrainer trainer = new DeepBeliefNetworkTrainer(DeepBeliefNetwork, DeepBeliefNetwork?.LayerWeights?[layerId], inputs);
這兩個對象都在我們的主TrainNetwork循環中使用,這是應用程序中大部分活動發生的部分。這個循環將繼續,直到被告知停止。
private void TrainNetwork(DeepBeliefNetworkTrainer trainer) { try { Stopping = false; ClearBoxes(); _unsavedChanges = true; int generation = 0; SetThreadExecutionState(EXECUTION_STATE.ES_CONTINUOUS | EXECUTION_STATE.ES_SYSTEM_REQUIRED);
while (Stopping == false) { Stopwatch stopwatch = Stopwatch.StartNew(); TrainingError error = trainer?.Train(); label1.Text = string.Format( "Gen {0} ({4:0.00} s): ReconstructionError= {1:0.00}, DetectorError={2:0.00}, LearningRate={3:0.0000}", generation, error.ReconstructionError, error.FeatureDetectorError, trainer.TrainingWeights.AdjustedLearningRate, stopwatch.ElapsedMilliseconds / 1000.0); Application.DoEvents(); ShowReconstructed(trainer); ShowFeatureDetectors(trainer); Application.DoEvents(); if (Stopping) { break; }
generation++; }
DocumentDeepBeliefNetwork(); }
finally { SetThreadExecutionState(EXECUTION_STATE.ES_CONTINUOUS); } }
在前面的代碼中,我們突出顯示了trainer.Train()方法,它是一個基于數組的學習算法,如下所示:
public TrainingError Train() { TrainingError trainingError = null; if (_weights != null) { ClearDetectorErrors(_weights.LowerLayerSize, _weights.UpperLayerSize); float reconstructionError = 0; ParallelFor(MultiThreaded, 0, _testCount, testCase => { float errorPart = TrainOnSingleCase(_rawTestCases,_weights?.Weights, _detectorError,testCase,
_weights.LowerLayerSize,_weights.UpperLayerSize, _testCount); lock (_locks?[testCase % _weights.LowerLayerSize]) { reconstructionError += errorPart; } }
); float epsilon = _weights.GetAdjustedAndScaledTrainingRate(_testCount); UpdateWeights(_weights.Weights,_weights.LowerLayerSize, _weights.UpperLayerSize,_detectorError, epsilon); trainingError = new TrainingError(_detectorError.Sum(val =>Math.Abs(val)), reconstructionError); _weights?.RegisterLastTrainingError(trainingError); return trainingError; }
return trainingError; }
此代碼使用并行處理(突出顯示的部分)并行地訓練單個案例。這個函數負責處理輸入層和隱藏層的更改,正如我們在本章開頭所討論的。它使用TrainOnSingleCase函數,如下圖所示:
private float TrainOnSingleCase(float[] rawTestCases, float[] weights, float[] detectorErrors, int testCase, int lowerCount, int upperCount, int testCaseCount) { float[] model = new float[upperCount]; float[] reconstructed = new float[lowerCount]; float[] reconstructedModel = new float[upperCount]; int rawTestCaseOffset = testCase * lowerCount; ActivateLowerToUpperBinary(rawTestCases, lowerCount, rawTestCaseOffset, model, upperCount, weights); // Model ActivateUpperToLower(reconstructed, lowerCount, model,upperCount, weights); // Reconstruction ActivateLowerToUpper(reconstructed, lowerCount, 0, reconstructedModel, upperCount, weights); // Reconstruction model return AccumulateErrors(rawTestCases, lowerCount,rawTestCaseOffset, model, upperCount, reconstructed, reconstructedModel, detectorErrors); // Accumulate detector errors }
最后,我們在處理過程中積累錯誤,這就是我們的模型應該相信的和它實際做的之間的區別。
顯然,錯誤率越低越好,對于我們的圖像重建最準確。AccumulateErrors函數如下所示:
private float AccumulateErrors(float[] rawTestCases, int lowerCount, int rawTestCaseOffset, float[] model, int upperCount, float[] reconstructed, float[] reconstructedModel, float[] detectorErrors) { float reconstructedError = 0; float[] errorRow = new float[upperCount]; for (int lower = 0; lower < lowerCount; lower++) { int errorOffset = upperCount * lower; for (int upper = 0; upper < upperCount; upper++) { errorRow[upper] = rawTestCases[rawTestCaseOffset + lower] * model[upper] + // 模型應該相信什么 -reconstructed[lower] * reconstructedModel[upper]; // 模型真正相信什么 } lock (_locks[lower]) { for (int upper = 0; upper < upperCount; upper++) { detectorErrors[errorOffset + upper] -= errorRow[upper]; } } reconstructedError += Math.Abs(rawTestCases[rawTestCaseOffset + lower] - reconstructed[lower]); } return reconstructedError; }
總結
在本章中,我們學習了RBMs、一些圖論,以及如何在c#中創建和訓練一個深入的信念網絡。我建議你對代碼進行試驗,將網絡層訓練到不同的閾值,并觀察計算機在重構時是如何做夢的。記住,你訓練得越多越好,所以花時間在每一層上,以確保它有足夠的數據來進行準確的重建工作。
警告:如果啟用特性檢測器和重構輸入的繪圖功能,性能將會極速下降。
如果你正在嘗試訓練你的圖層,你可能希望先在沒有可視化的情況下訓練它們,以減少所需的時間。相信我,如果你把每一個關卡都訓練成高迭代,那么可視化會讓你感覺像一個永恒的過程!在你前進的過程中,隨時保存你的網絡。
在下一章中,我們將學習微基準測試,并使用有史以來最強大的開源微基準測試工具包之一!

 浙公網安備 33010602011771號
浙公網安備 33010602011771號