
基于C#的機器學習--我應該接受這份工作嗎-使用決策樹
決策樹
要使決策樹完整而有效,它必須包含所有的可能性。事件序列也必須提供,并且是互斥的,這意味著如果一個事件發生,另一個就不能發生。
決策樹是監督機器學習的一種形式,因為我們必須解釋輸入和輸出應該是什么。有決策節點和葉子。葉子是決策,不管是否是最終決策,節點是決策分裂發生的地方。
雖然有很多算法可供我們使用,但我們將使用迭代二分法(ID3)算法。
在每個遞歸步驟中,根據一個標準(信息增益、增益比等)選擇對我們正在處理的輸入集進行最佳分類的屬性。
這里必須指出的是,無論我們使用什么算法,都不能保證生成盡可能小的樹。因為這直接影響到算法的性能。
請記住,對于決策樹,學習僅僅基于啟發式,而不是真正的優化標準。讓我們用一個例子來進一步解釋這一點。
下面的示例來自http://jmlr.csail.mit.edu/papers/volume8/esmeir07a/esmeir07a.pdf,它演示了XOR學習概念,我們所有的開發人員都(或應該)熟悉這個概念。稍后的例子中也會出現這種情況,但現在a3和a4與我們要解決的問題完全無關。它們對我們的答案沒有影響。也就是說,ID3算法將選擇其中一個構建樹,事實上,它將使用a4作為根節點!記住,這是算法的啟發式學習,而不是優化結果:
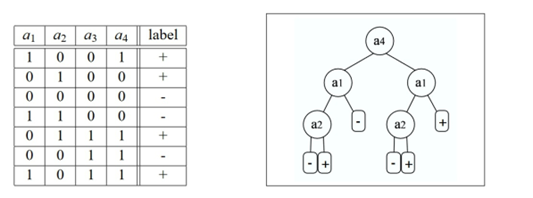
希望這張圖能讓大家更容易理解剛剛所說的內容。我們的目標并不是深入研究決策樹機制和理論。而是如何使用它,盡管存在很多問題,但決策樹仍然是許多算法的基礎,尤其是那些需要對結果進行人工描述的算法。這也是我們前面試試人臉檢測算法的基礎。
決策節點
決策樹的一個節點。每個節點可能有關聯的子節點,也可能沒有關聯的子節點
決策的變量
此對象定義樹和節點可以處理的每個決策變量的性質。值可以是范圍,連續的,也可以是離散的。
決策分支節點的集合
此集合包含將一個或多個決策節點組,以及關于決策變量的附加信息,以便進行比較。
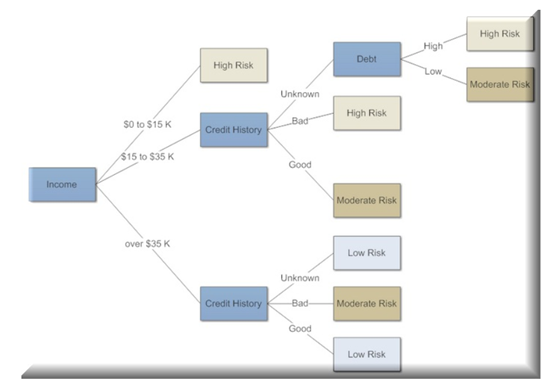
下面是一個用于確定金融風險的決策樹示例。我們只需要在節點之間導航,就可以很容易地跟隨它,決定要走哪條路,直到得到最終的答案。在這種情況下,當有人正在申請貸款,而我們需要對他們的信用價值做出決定。這時決策樹就是解決這個問題的一個很好的方法:
我應該接受這份工作嗎?
你剛剛得到一份新工作,你需要決定是否接受它。有一些重要的事情需要考慮,所以我們將它們作為輸入變量或特性,用于決策樹。
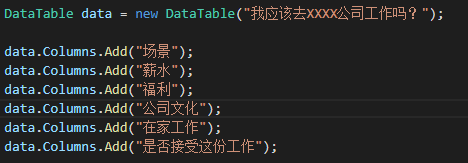
對你來說最重要的是:薪水、福利、公司文化,當然還有,我能在家工作嗎?
我們將創建一個內存數據庫并以這種方式添加特性,而不是從磁盤存儲中加載數據。我們將創建DataTable并創建列,如下圖所示:
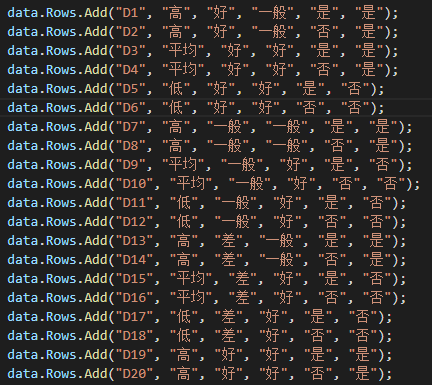
在這之后,我們將加載幾行數據,每一行都有一組不同的特性,最后一列應該是Yes或No,作為我們的最終決定:
一旦所有的數據都創建好并放入表中,我們就需要將之前的特性轉換成計算機能夠理解的表示形式。
由于數字更簡單,我們將通過一個稱為編碼的過程將我們的特性(類別)轉換為一本代碼本。該代碼本有效地將每個值轉換為整數。
注意,我們將傳遞我們的數據類別作為輸入:

接下來,我們需要為決策樹創建要使用的決策變量。
這棵樹會幫助我們決定是否接受新的工作邀請。對于這個決策,將有幾類輸入,我們將在決策變量數組中指定它們,以及兩個可能的決策,是或者否。
DecisionVariable數組將保存每個類別的名稱以及該類別可能的屬性的總數。例如,薪水類別有三個可能的值,高、平均或低。我們指定類別名和數字3。然后,除了最后一個類別(即我們的決定)之外,我們對所有其他類別都重復這個步驟:
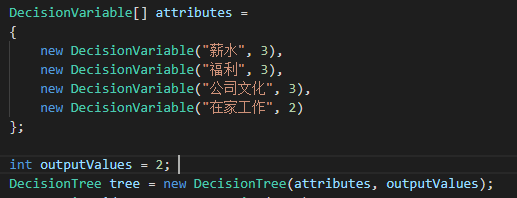
現在我們已經創建了決策樹,我們必須教它如何解決我們要解決的問題。為了做到這一點,我們必須為這棵樹創建一個學習算法。由于我們只有這個示例的分類值,所以ID3算法是最簡單的選擇。

一旦學習算法被運行,它就會被訓練并可供使用。我們簡單地為算法提供一個樣本數據集,這樣它就可以給我們一個答案。在這種情況下,薪水不錯,公司文化不錯,福利也不錯,我可以在家工作。如果正確地訓練決策樹,答案將會是是:

Numl
numl是一個非常著名的開源機器學習工具包。與大多數機器學習框架一樣,它的許多示例也使用Iris數據集,包括我們將用于決策樹的那個。
下面是我們的numl輸出的一個例子:
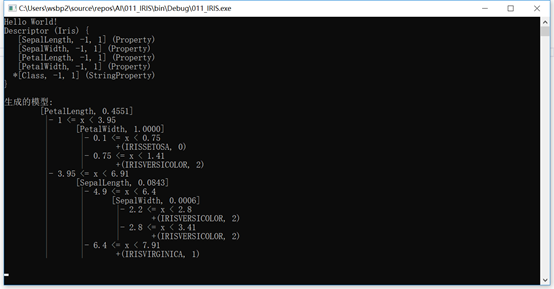
讓我們看一下這個例子背后的代碼:
static void Main(string[] args) { Console.WriteLine("Hello World!"); var description = Descriptor.Create<Iris>(); Console.WriteLine(description); var generator = new DecisionTreeGenerator(); var data = Iris.Load(); var model = generator.Generate(description, data); Console.WriteLine("生成的模型:"); Console.WriteLine(model); Console.ReadKey(); }
這個方法并不復雜,對吧?這就是在應用程序中使用numl的好處;它非常容易使用和集成。
上述代碼創建描述符和DecisionTreeGenerator,加載Iris數據集,然后生成模型。這里只是正在加載的數據的一個示例:
public static Iris[] Load() { return new Iris[] { new Iris { SepalLength = 5.1m, SepalWidth = 3.5m, PetalLength = 1.4m, PetalWidth = 0.2m, Class = "Iris-setosa" }, new Iris { SepalLength = 4.9m, SepalWidth = 3m, PetalLength = 1.4m, PetalWidth = 0.2m, Class = "Iris-setosa" }, new Iris { SepalLength = 4.7m, SepalWidth = 3.2m, PetalLength = 1.3m, PetalWidth = 0.2m, Class = "Iris-setosa" }, new Iris { SepalLength = 4.6m, SepalWidth = 3.1m, PetalLength = 1.5m, PetalWidth = 0.2m, Class = "Iris-setosa" }, new Iris { SepalLength = 5m, SepalWidth = 3.6m, PetalLength = 1.4m, PetalWidth = 0.2m, Class = "Iris-setosa" }, new Iris { SepalLength = 5.4m, SepalWidth = 3.9m, PetalLength = 1.7m, PetalWidth = 0.4m, Class = "Iris-setosa" } }; }
Accord.NET 決策樹
Accord.NET framework也有自己的決策樹例子。它采用了一種不同的、更圖形化的方法來處理決策樹,但是您可以通過調用來決定您喜歡哪個決策樹,并且最習慣使用哪個決策樹。
一旦數據被加載,您就可以創建決策樹并為學習做好準備。您將看到與這里類似的數據圖,使用了X和Y兩個類別:
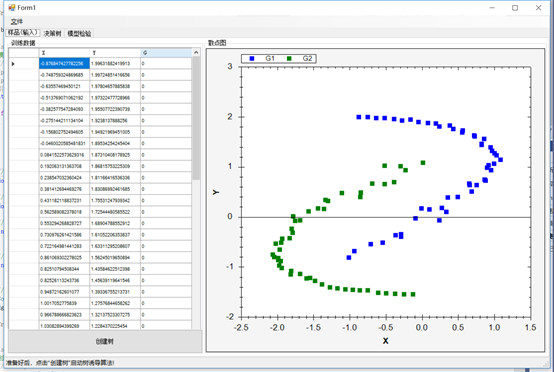
下一個選項卡將讓您看到樹節點、葉子和決策。右邊還有一個自頂向下的樹的圖形視圖。最有用的信息在左邊的樹形視圖中,你可以看到節點,它們的值,以及做出的決策:
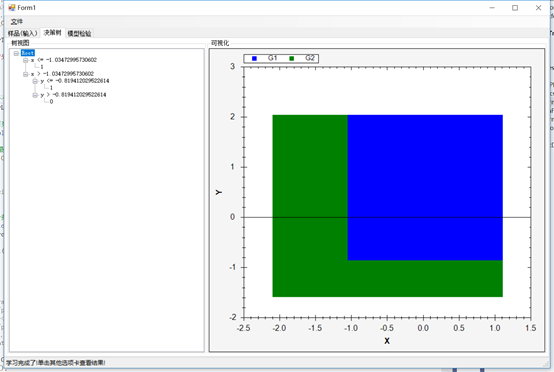
最后,最后一個選項卡將允許您執行模型測試:
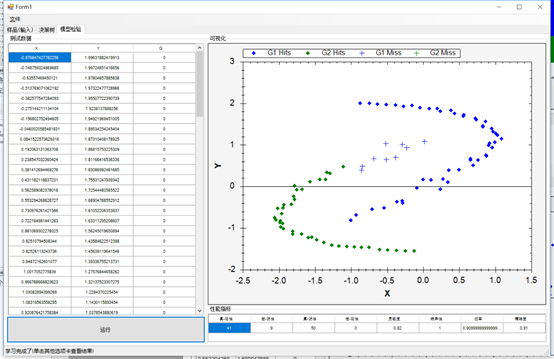
代碼
下面是學習代碼
// 指定輸入變量 DecisionVariable[] variables = { new DecisionVariable("x", DecisionVariableKind.Continuous), new DecisionVariable("y", DecisionVariableKind.Continuous), }; // 創建C4.5學習算法 var c45 = new C45Learning(variables); // 使用C4.5學習決策樹 tree = c45.Learn(inputs, outputs); // 在視圖中顯示學習樹 decisionTreeView1.TreeSource = tree; // 獲取每個變量(X和Y)的范圍 DoubleRange[] ranges = table.GetRange(0); // 生成一個笛卡爾坐標系 double[][] map = Matrix.Mesh(ranges[0], 200, ranges[1], 200); // 對笛卡爾坐標系中的每個點進行分類 double[,] surface = map.ToMatrix().InsertColumn(tree.Decide(map)); CreateScatterplot(zedGraphControl2, surface); //測試 // 從整個源數據表創建一個矩陣 double[][] table = (dgvLearningSource.DataSource as DataTable).ToJagged(out columnNames); //只獲取輸入向量值(前兩列) double[][] inputs = table.GetColumns(0, 1); // 獲取預期的輸出標簽(最后一列) int[] expected = table.GetColumn(2).ToInt32(); // 計算實際的樹輸出 int[] actual = tree.Decide(inputs); // 使用混淆矩陣來計算一些統計數據。 ConfusionMatrix confusionMatrix = new ConfusionMatrix(actual, expected, 1, 0); dgvPerformance.DataSource = new[] { confusionMatrix }; CreateResultScatterplot(zedGraphControl1, inputs, expected.ToDouble(), actual.ToDouble());
然后他的值被輸入一個混淆矩陣。對于不熟悉這一點的同學,讓我簡單解釋一下.
混淆矩陣
混淆矩陣是用來描述分類模型性能的表。它在已知真值的測試數據集上運行。這就是我們如何得出如下結論的。
真-陽性
在這個例子中,我們預測是,這是事實。
真-陰性
在這種情況下,我們預測否,這是事實。
假-陽性
在這種情況下,我們預測是,但事實并非如此。有時您可能會看到這被稱為type 1錯誤。
假-陰性
在這種情況下,我們預測“否”,但事實是“是”。有時您可能會看到這被type 2類錯誤。
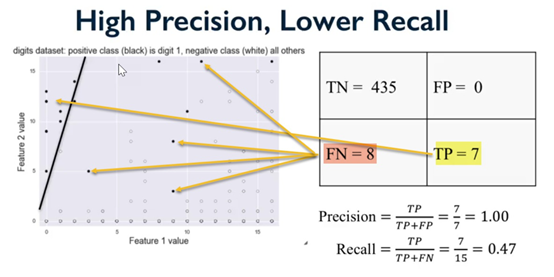
現在,說了這么多,我們需要談談另外兩個重要的術語,精確度和回憶。
讓我們這樣來描述它們。在過去的一個星期里,每天都下雨。這是7天中的7天。很簡單。一周后,你被問到上周多久下一次雨?
回憶
它是你正確回憶下雨的天數與正確事件總數的比值。如果你說下了7天雨,那就是100%。如果你說下了四天雨,那么57%的人記得。在這種情況下,它的意思是你的回憶不是那么精確,所以我們有精確度來識別。
精確度
它是你正確回憶將要下雨的次數與那一周總天數的比值。
對我們來說,如果我們的機器學習算法擅長回憶,并不一定意味著它擅長精確。有道理嗎?這就涉及到其他的事情,比如F1的分數,我們會留到以后再講。
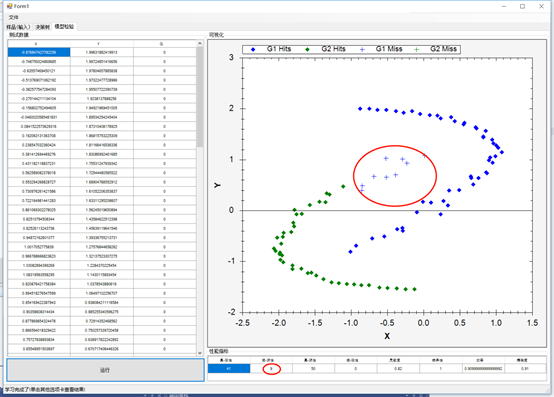
可視化錯誤類型
以下是一些可能會有幫助的可視化:

識別真陽性和假陰性:
使用混淆矩陣計算統計量后,創建散點圖,識別出所有內容:
總結
在這一章中,我們花了很多時間來研究決策樹;它們是什么,我們如何使用它們,以及它們如何使我們在應用程序中受益。在下一章中,我們將進入深度信念網絡(DBNs)的世界,它們是什么,以及我們如何使用它們。
我們甚至會談論一下計算機的夢,當它做夢的時候!

 浙公網安備 33010602011771號
浙公網安備 33010602011771號