
基于C#的機器學習--顏色混合-自組織映射和彈性神經網絡
自組織映射和彈性神經網絡
自組織映射(SOM),或者你們可能聽說過的Kohonen映射,是自組織神經網絡的基本類型之一。自組織的能力提供了對以前不可見的輸入數據的適應性。它被理論化為最自然的學習方式之一,就像我們的大腦所使用的學習方式一樣,在我們的大腦中,沒有預先定義的模式被認為是存在的。這些模式是在學習過程中形成的,并且在以更低的維度(如二維或一維)表示多維數據方面具有不可思議的天賦。此外,該網絡以這樣一種方式存儲信息,即在訓練集中保持任何拓撲關系。
更正式地說,SOM是一種集群技術,它將幫助我們發現大型數據集中有趣的數據類別。它是一種無監督的神經網絡,神經元被排列在一個單一的二維網格中。網格必須是矩形的,例如,純矩形或六邊形。在整個迭代過程中,網格中的神經元將逐漸合并到數據點密度更高的區域。當神經元移動時,它們會彎曲和扭曲網格,直到它們更靠近感興趣的點,并反映出數據的形狀。
在這一章中,我們將討論以下主題:
- Kohonen SOM(自組織映射)
- 使用AForge.NET
SOM引擎
簡而言之,我們網格上的神經元,通過迭代,它們逐漸適應數據的形狀(在我們的示例中,如下面的圖所示,位于點面板左側)。我們再來討論一下迭代過程本身。
1.第一步是在網格上隨機放置數據。我們將隨機將網格的神經元放在數據空間中,如下圖所示:
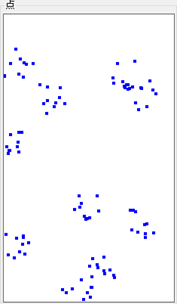
2.第二步是算法將選擇單個數據點。
3.在第三步中,我們需要找到最接近所選數據點的神經元(數據點)。這就成了我們最匹配的單元。
4.第四步是將最匹配的單元移向該數據點。我們移動的距離是由我們的學習率決定的,每次迭代后學習率都會下降。
5.第五,我們將把最匹配單元的鄰居移得更近,距離越遠的神經元移動得越少。你在屏幕上看到的初始半徑變量是我們用來識別鄰居的。這個值,就像初始學習率一樣,會隨著時間的推移而降低。如果您已經啟動并運行了監視器,您可以看到初始學習率隨著時間的推移而降低,如下面的屏幕截圖所示:
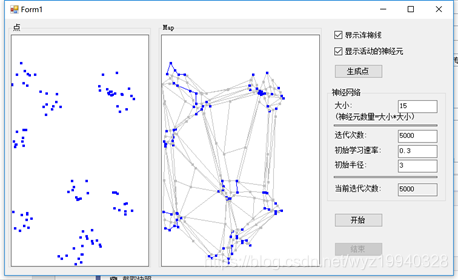
6.我們的第六步也是最后一步,是更新初始學習速率和初始半徑,就像我們目前描述的那樣,然后重復它。我們將繼續這一進程,直到我們的數據點穩定下來并處于正確的位置。
現在我們已經有了了一些關于SOMs的直觀的認識,我們再來討論一下我們這一章要做的事情。我們選擇了一個非常常見的機制來教我們的程序,那就是顏色的映射。
顏色本身是由紅色、綠色和藍色表示的三維對象,但是我們將把它們組織成二維。顏色的組織有兩個關鍵點。首先,顏色被聚集成不同的區域,其次,具有相似屬性的區域通常彼此相鄰。
第二個例子更高級一些,它將使用ANN(人工神經網絡);這是機器學習的一種高級形式,用于創建與呈現給它的映射相匹配的組織映射。
讓我們看第一個例子。下面是我們示例的屏幕截圖。正如所看到的,我們有一個隨機的顏色圖案,當完成時,它由一組相似的顏色組成:

如果我們成功了,我們的結果應該是這樣的:

讓我們從以下步驟開始:
1.我們將首先進行500次迭代來實現我們的目標。使用較小的數字可能不會產生我們最終想要的混合。例如,如果我們進行500次迭代,下面是我們的結果:
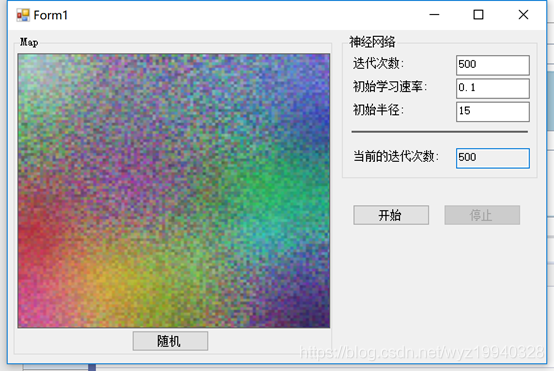
2.正如所看到的,我們離我們需要達到的目標還很遠。但是我們能夠更改迭代,以允許使用完全正確的設置進行試驗。到了這里我們必須承認,500次的迭代遠遠不夠,所以我把它留作練習,讓你自己算出進展到哪里停止,才會讓你感到滿意(所以這個迭代次數是因人而異的,但可以肯定的是500次,肯定是不符合絕大多數人的要求的)
3.在設置了迭代次數之后,我們所要做的就是確保程序擁有我們想要的隨機顏色模式,這可以通過單擊隨機按鈕來實現。有了想要的模式后,只需單擊Start按鈕并查看結果。
4.一旦你點擊開始,停止按鈕將被激活,你可以隨時停止進程。一旦達到指定的迭代次數,程序將自動停止。
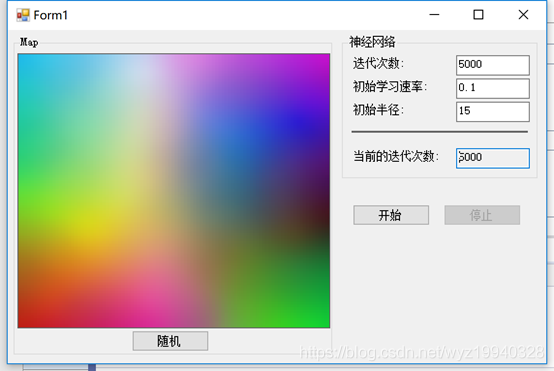
在我們進入實際代碼之前,讓我們看一些組織模式的屏幕截圖。我們可以通過簡單地更改不同的參數來實現出色的結果,我們將在后面詳細描述這些參數。
在下面的截圖中,我們將迭代次數設置為3000次,初始半徑為10:
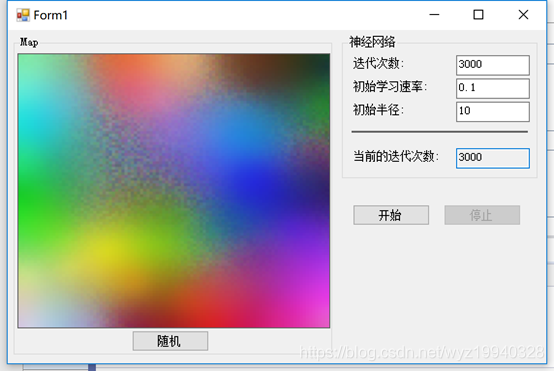
在下面的截圖中,我們將迭代次數設置為4000次,初始半徑為18:

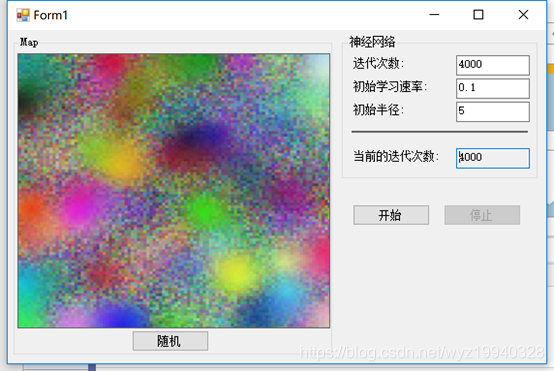
在下面的截圖中,我們將迭代次數設置為4000次,初始半徑為5:
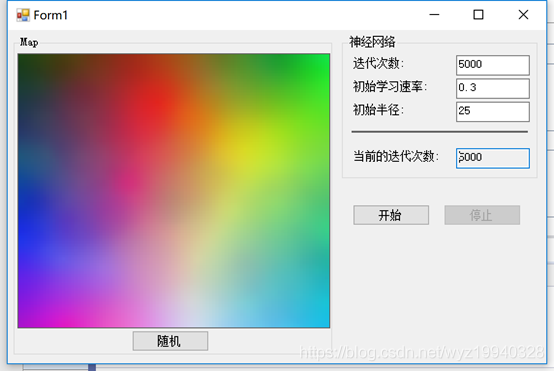
這里我們將迭代次數設為5000次,初始學習率設為0.3,初始半徑設為25,如下截圖所示,得到了期望的結果:
現在讓我們深入研究代碼。
在本例中,我們將使用AForge并使用DistanceNetwork對象。距離網絡是只有一個距離的神經網絡。除了用于SOM之外,它還用于一個彈性網絡操作,這就是我們將要使用的來展示進程中對象之間的彈性連接。
我們將使用三個輸入神經元和10000個神經元來創建我們的距離網絡:
// 創建網絡 network = new DistanceNetwork(3, 100 * 100);
當我們點擊隨機化顏色按鈕來隨機化顏色時:
/// <summary> /// 賦予網絡隨機權重 /// </summary> private void RandomizeNetwork() { if (network != null) { foreach (var neuron in (network?.Layers.SelectMany(layer => layer?.Neurons)).Where(neuron => neuron != null)) neuron.RandGenerator = new UniformContinuousDistribution(new Range(0, 255)); network?.Randomize(); } UpdateMap(); }
這里需要注意的是,我們處理的隨機化范圍保持在任何顏色的紅、綠色或藍色特征的范圍內,即0-255之間(包含0,包含255)。
接下來,我們來看看我們的學習循環,就像這樣。我們一會兒會深入研究它:
/// <summary> /// 工作內容 /// </summary> private void SearchSolution() { SOMLearning trainer = new SOMLearning(network); double[] input = new double[3]; double fixedLearningRate = learningRate / 10; double driftingLearningRate = fixedLearningRate * 9; int i = 0; while (!needToStop) { trainer.LearningRate = driftingLearningRate * (iterations - i) / iterations + fixedLearningRate; trainer.LearningRadius = radius * (iterations - i) / iterations; if (rand != null) { input[0] = rand.Next(256); input[1] = rand.Next(256); input[2] = rand.Next(256); } trainer.Run(input); // 每50次迭代更新一次map if ((i % 10) == 9) { UpdateMap(); } i++; SetText(currentIterationBox, i.ToString()); if (i >= iterations) break; } EnableControls(true); }
如果仔細觀察,會發現我們創建的第一個對象是SOMLearning對象。這個對象是為正方形空間學習而優化的,這意味著它期望它所處理的網絡具有與其寬度相同的高度。這使得計算網絡神經元數量的平方根變得更加容易:
SOMLearning trainer = new SOMLearning(network);
接下來,我們需要創建變量來保存紅色、綠色和藍色的輸入顏色,從中我們將不斷地隨機化輸入顏色,以實現我們的目標:
if (rand != null) { input[0] = rand.Next(256); input[1] = rand.Next(256); input[2] = rand.Next(256); }
一旦我們進入while循環,我們將不斷地更新變量,直到我們達到所選擇的迭代總數。在這個更新循環中,會發生一些事情。首先,我們將更新學習速率和學習半徑,并將其存儲在我們的SOMLearning對象:
trainer.LearningRate = driftingLearningRate * (iterations - i) / iterations + fixedLearningRate;
trainer.LearningRadius = radius * (iterations - i) / iterations;
學習率決定了我們的學習速度。學習半徑會對視覺輸出產生非常顯著的影響,它決定了相對于獲勝神經元多少距離,需要更新的神經元數量。指定半徑的圓由神經元組成,神經元在學習過程中不斷更新。一個神經元離獲勝神經元越近,它接收到的更新信息就越多。請注意,如果在實驗中,將該值設置為零,那么只能更新獲勝神經元的權重,而不能更新其他神經元的權重。
現在我們對這個迭代進行一次訓練,并將Input數組傳遞給它:
trainer.Run(input);
讓我們談一下學習。正如我們所提到的,每次迭代都將嘗試和學習越來越多的信息。這個學習迭代返回一個學習偏差,即神經元的權重和輸入向量Input的差值。如前所述,距離是根據與獲勝神經元之間的距離來測量的。過程如下。
訓練器運行一次學習迭代,找到獲勝的神經元(權重值與Input中提供的值最接近的神經元),并更新其權重。它還會更新相鄰神經元的權重。隨著每次學習迭代的進行,網絡越來越接近最優解。
接下來是運行應用程序的屏幕截圖。在實時調試和診斷工具中,可以看到我們是如何記錄每次迭代的,更新地圖時使用的顏色值,以及學習速率和學習半徑。
由于SOM是自組織的,我們的第二個例子會更加形象。它能幫助我們更好地理解幕后所發生的事情。
在本例中,我們將再次使用AForge。并構建一個二維平面的對象,組織成幾個組。我們將從一個單獨的位置開始,直觀地得到這些形狀的位置。這與我們的顏色示例在概念上是相同的,它使用了三維空間中的點,只是這次,我們的點是二維的。可視化在map面板中,這是一個自頂向下的視圖,用于查看二維空間中發生的事情,從而獲得一個一維圖形視圖。
起初,SOM網格中的神經元從隨機位置開始,但它們逐漸被揉捏成我們數據形狀的輪廓。這是一個迭代的過程,我已經在迭代過程的不同地方截屏,向大家展示了發生了什么。當然你也可以自己運行這個示例來實時查看它。
我們將運行500次迭代來展示演進。我們將從一個空白的白色面板得到一個類似的點的面板:
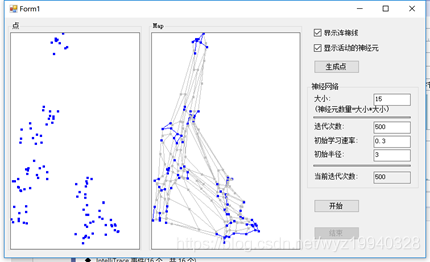
在我們點擊開始按鈕,我們將看到這些點開始通過移動到正確的位置來組織自己,希望這將反映出我們所指定的點:
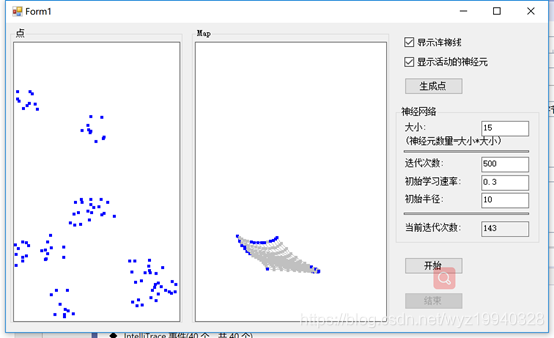
經過262次迭代:
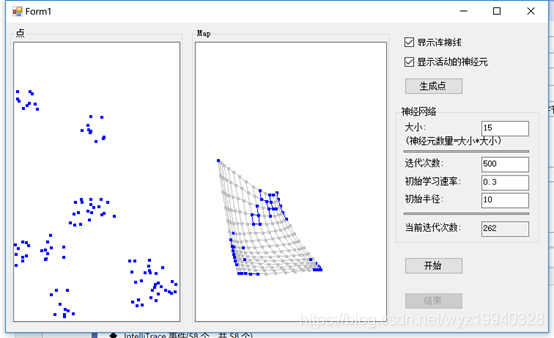
經過343次迭代:
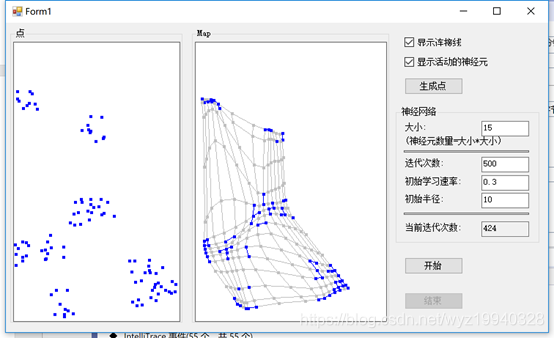
在完成之后,我們可以看到對象已經像我們最初創建的模式那樣組織了它們自己。藍色的點是活躍的神經元,淺灰色的點是不活躍的神經元,畫的線是神經元之間的彈性連接。嗯,這有些像《黑客帝國》中的那個綠色的數據流。如果你看到足夠仔細,是能夠看到3D效果的。
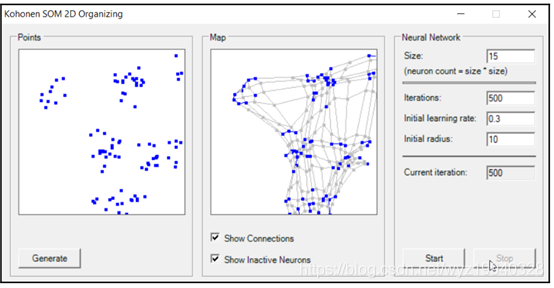
如果你窗體中沒有顯示連接和不活躍的神經元,你會看到map中的組織模式與我們的目標達到了相同的集群,對我們來說這意味著成功:

那么這一切究竟是如何工作的呢。像往常一樣,讓我們來看看我們的主執行循環。正如我們所看到的,我們將使用與前面討論的相同的DistanceNetwork和SOMLearning對象:
/// <summary> /// 工作內容 /// </summary> private void SearchSolution() { // 創建網絡 DistanceNetwork network = new DistanceNetwork(2, networkSize * networkSize); // 設置隨機生成器范圍 foreach (var neuron in network.Layers.SelectMany(layer => layer.Neurons)) neuron.RandGenerator = new UniformContinuousDistribution( new Range(0, Math.Max(pointsPanel.ClientRectangle.Width, pointsPanel.ClientRectangle.Height))); // 創建學習算法 SOMLearning trainer = new SOMLearning(network, networkSize, networkSize); // 創建map map = new int[networkSize, networkSize, 3]; double fixedLearningRate = learningRate / 10; double driftingLearningRate = fixedLearningRate * 9; // 迭代次數 int i = 0; while (!needToStop) { trainer.LearningRate = driftingLearningRate * (iterations - i) / iterations + fixedLearningRate; trainer.LearningRadius = (double)learningRadius * (iterations - i) / iterations; // 開始紀元的訓練 trainer.RunEpoch(trainingSet); UpdateMap(network); i++; // 設置當前迭代的信息 SetText(currentIterationBox, i.ToString()); // stop ? if (i >= iterations) break; } // 啟用設置控件 EnableControls(true); }
正如我們前面提到的,LearningRate和LearningRadius在每次迭代中都在不斷發展。這一次,讓我們來談談訓練器的RunEpoch方法。這個方法雖然非常簡單,但其設計目的是獲取一個輸入值向量,然后為該迭代返回一個學習偏差(正如我們現在看到的,有時也稱為epoch)。它通過計算向量中的每個輸入樣本來實現這一點。學習誤差是神經元的權值和輸入之間的絕對差。這種差異是根據獲勝神經元之間的距離來測量的。如前所述,我們針對一個學習迭代/歷元運行此計算,找到獲勝者,并更新其權重(以及鄰居權重)。應該指出的是,當說贏家時,指的是權重值與指定輸入向量最接近的神經元,也就是給網絡輸入的最小距離。
接下來,將重點介紹如何更新映射本身;我們計算的項目應該與初始輸入向量(點)匹配:
private void UpdateMap(DistanceNetwork network) { // 得到第一層 Layer layer = network.Layers[0]; // 加鎖 Monitor.Enter(this); // 遍歷所有神經元 for (int i = 0; i < layer.Neurons.Length; i++) { Neuron neuron = layer.Neurons[i]; int x = i % networkSize; int y = i / networkSize; map[y, x, 0] = (int)neuron.Weights[0]; map[y, x, 1] = (int)neuron.Weights[1]; map[y, x, 2] = 0; } // 收集活動的神經元 for (int i = 0; i < pointsCount; i++) { network.Compute(trainingSet[i]); int w = network.GetWinner(); map[w / networkSize, w % networkSize, 2] = 1; } // 解鎖 Monitor.Exit(this); mapPanel.Invalidate(); }
從這段代碼中可以看到,我們得到了第一層,計算了所有神經元的map,收集了活動神經元,這樣我們就可以確定獲勝者,然后更新map。
我們確定獲勝者的過程,實際上就是尋找權重與網絡輸入距離最小的神經元,就是這么簡單,一定不要把簡單的問題復雜化,就好像那個雨滴與碩士博士教授的笑話一樣。
總結
在這一章中,我們學習了如何利用SOMs和彈性神經網絡的力量。現在我們已經正式從機器學習跨入了神經網絡的階段。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號