
基于C#的機器學習--懲罰與獎勵-強化學習
強化學習概況
正如在前面所提到的,強化學習是指一種計算機以“試錯”的方式進行學習,通過與環境進行交互獲得的獎賞指導行為,目標是使程序獲得最大的獎賞,強化學習不同于連督學習,區別主要表現在強化信號上,強化學習中由環境提供的強化信號是對產生動作的好壞作一種評價(通常為標量信號),而不是告訴強化學習系統如何去產生正確的動作。唯一的目的是最大化效率和/或性能。算法對正確的決策給予獎勵,對錯誤的決策給予懲罰,如下圖所示:
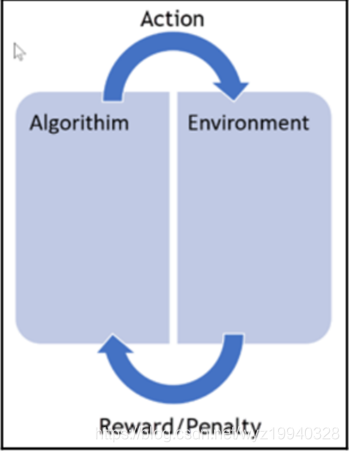
持續的訓練是為了不斷提高效率。這里的重點是性能,這意味著我們需要,在看不見的數據和算法已經學過的東西,之間找到一種平衡。該算法將一個操作應用到它的環境中,根據它所做的行為接受獎勵或懲罰,不斷的重復這個過程,等等。
接下來讓我們看一個程序,概念是相似的,盡管它的規模和復雜性很低。想象一下,是什么讓自動駕駛的車輛從一個地點移動到了另一個點。
讓我們看看我們的應用程序:
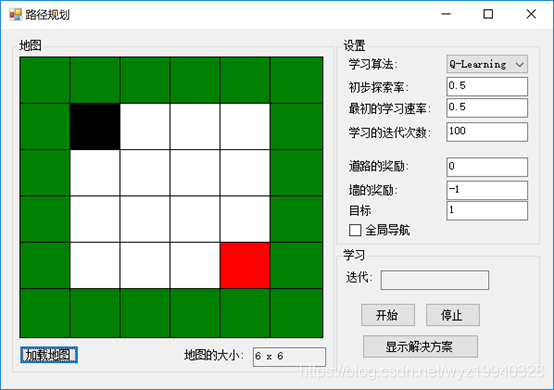
在這里,可以看到我們有一個非常基本的地圖,一個沒有障礙,但有外部限制的墻。黑色塊(start)是我們的對象,紅色塊(stop)是我們的目標。在這個應用程序中,我們的目標是讓我們的對象在墻壁以內到達目標位置。如果我們的下一步把我們的對象放在一個白色的方塊上,我們的算法將得到獎勵。如果我們的下一步行動超出墻壁的圍地范圍,我們將受到懲罰。在這個例子中,它的路徑上絕對沒有障礙,所以我們的對象應該能夠到達它的目的地。問題是:它能多快學會?
下面是另一個比較復雜的地圖示例:
學習類型
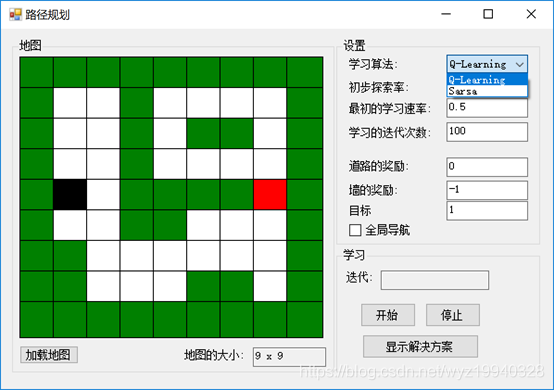
在應用程序的右邊是我們的設置,如下面的屏幕截圖所示。我們首先看到的是學習算法。在這個應用中,我們將處理兩種不同的學習算法,Q-learning和state-action-reward-state-action (SARSA)。讓我們簡要討論一下這兩種算法。
Q-learning
Q-learning可以在沒有完全定義的環境模型的情況下,識別給定狀態下的最優行為(在每個狀態中值最高的行為)。它還擅長處理隨機轉換和獎勵的問題,而不需要調整或適應。
以下是Q-learning的數學表達式:

如果我們提供一個非常高級的抽象示例,可能更容易理解。
程序從狀態1開始。然后它執行動作1并獲得獎勵1。接下來,它四處尋找狀態2中某個行為的最大可能獎勵是多少;然后使用它來更新動作1的值等等。
SARSA
SARSA的工作原理是這樣的:
1. 程序從狀態1開始。
2. 然后它執行動作1并獲得獎勵1。
3. 接下來,它進入狀態2,執行動作2,并獲得獎勵2。
4. 然后,程序返回并更新動作1的值。
這Q-learning算法的不同之處在于找到未來獎勵的方式。
Q-learning使用狀態2中獎勵最高的動作的值,而SARSA使用實際動作的值。
這是SARSA的數學表達式:
![]()
運行我們的應用程序
現在,讓我們開始使用帶有默認參數的應用程序。只需點擊開始按鈕,學習就開始了。完成后,您將能夠單擊Show Solution按鈕,學習路徑將從頭到尾播放。
點擊Start開始學習階段,一直到黑色物體達到目標:
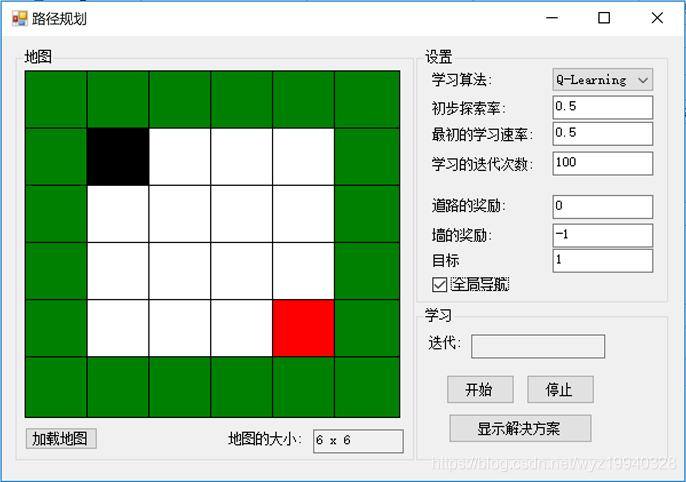
對于每個迭代,將評估不同的對象位置,以及它們的操作和獎勵。一旦學習完成,我們可以單擊Show Solution按鈕來重播最終的解決方案。完成后,黑色對象將位于紅色對象之上:
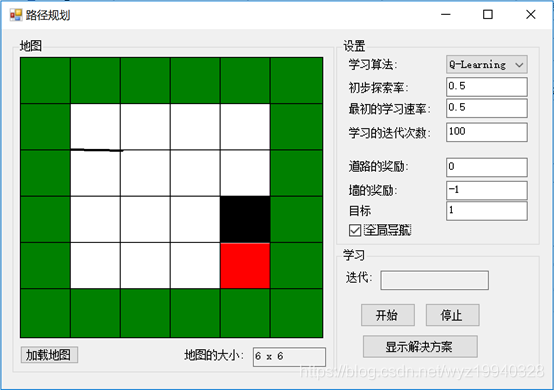
現在讓我們看看應用程序中的代碼。有兩種我們之前強調過的學習方法。
Q-learning是這樣的:
/// <summary> /// Q-Learning 線程 /// </summary> private void QLearningThread() { //迭代次數 int iteration = 0; TabuSearchExploration tabuPolicy = (TabuSearchExploration)qLearning.ExplorationPolicy; EpsilonGreedyExploration explorationPolicy = (EpsilonGreedyExploration)tabuPolicy.BasePolicy; while ((!needToStop)&&(iteration<learningIterations)) { explorationPolicy.Epsilon = explorationRate - ((double)iteration / learningIterations) * explorationRate; qLearning.LearningRate = learningRate - ((double)iteration / learningIterations) * learningRate; tabuPolicy.ResetTabuList(); var agentCurrentX = agentStartX; var agentCurrentY = agentStartY; int steps = 0; while ((!needToStop)&& ((agentCurrentX != agentStopX) || (agentCurrentY != agentStopY))) { steps++; int currentState= GetStateNumber(agentCurrentX, agentCurrentY); int action = qLearning.GetAction(currentState); double reward = UpdateAgentPosition(ref agentCurrentX, ref agentCurrentY, action); int nextState = GetStateNumber(agentCurrentX, agentCurrentY); // 更新對象的qLearning以設置禁忌行為 qLearning.UpdateState(currentState, action, reward, nextState); tabuPolicy.SetTabuAction((action + 2) % 4, 1); } System.Diagnostics.Debug.WriteLine(steps); iteration++; SetText(iterationBox, iteration.ToString()); } EnableControls(true); }
SARSA學習有何不同?讓我們來看看SARSA學習的while循環,并理解它:
/// <summary> /// Sarsa 學習線程 /// </summary> private void SarsaThread() { int iteration = 0; TabuSearchExploration tabuPolicy = (TabuSearchExploration)sarsa.ExplorationPolicy; EpsilonGreedyExploration explorationPolicy = (EpsilonGreedyExploration)tabuPolicy.BasePolicy; while ((!needToStop) && (iteration < learningIterations)) { explorationPolicy.Epsilon = explorationRate - ((double)iteration / learningIterations) * explorationRate; sarsa.LearningRate = learningRate - ((double)iteration / learningIterations) * learningRate; tabuPolicy.ResetTabuList(); var agentCurrentX = agentStartX; var agentCurrentY = agentStartY; int steps = 1; int previousState = GetStateNumber(agentCurrentX, agentCurrentY); int previousAction = sarsa.GetAction(previousState); double reward = UpdateAgentPosition(ref agentCurrentX, ref agentCurrentY, previousAction); while ((!needToStop) && ((agentCurrentX != agentStopX) || (agentCurrentY != agentStopY))) { steps++; tabuPolicy.SetTabuAction((previousAction + 2) % 4, 1); int nextState = GetStateNumber(agentCurrentX, agentCurrentY); int nextAction = sarsa.GetAction(nextState); sarsa.UpdateState(previousState, previousAction, reward, nextState, nextAction); reward = UpdateAgentPosition(ref agentCurrentX, ref agentCurrentY, nextAction); previousState = nextState; previousAction = nextAction; } if (!needToStop) { sarsa.UpdateState(previousState, previousAction, reward); } System.Diagnostics.Debug.WriteLine(steps); iteration++; SetText(iterationBox, iteration.ToString()); } // 啟用設置控件 EnableControls(true); }
最后一步,看看如何使解決方案具有動畫效果。我們需要這樣才能看到我們的算法是否實現了它的目標。
代碼如下:
TabuSearchExploration tabuPolicy; if (qLearning != null) tabuPolicy = (TabuSearchExploration)qLearning.ExplorationPolicy; else if (sarsa != null) tabuPolicy = (TabuSearchExploration)sarsa.ExplorationPolicy; else throw new Exception(); var explorationPolicy = (EpsilonGreedyExploration)tabuPolicy?.BasePolicy; explorationPolicy.Epsilon = 0; tabuPolicy?.ResetTabuList(); int agentCurrentX = agentStartX, agentCurrentY = agentStartY; Array.Copy(map, mapToDisplay, mapWidth * mapHeight); mapToDisplay[agentStartY, agentStartX] = 2; mapToDisplay[agentStopY, agentStopX] = 3;
這是我們的while循環,所有神奇的事情都發生在這里!
while (!needToStop) { cellWorld.Map = mapToDisplay; Thread.Sleep(200); if ((agentCurrentX == agentStopX) && (agentCurrentY == agentStopY)) { mapToDisplay[agentStartY, agentStartX] = 2; mapToDisplay[agentStopY, agentStopX] = 3; agentCurrentX = agentStartX; agentCurrentY = agentStartY; cellWorld.Map = mapToDisplay; Thread.Sleep(200); } mapToDisplay[agentCurrentY, agentCurrentX] = 0; int currentState = GetStateNumber(agentCurrentX, agentCurrentY); int action = qLearning?.GetAction(currentState) ?? sarsa.GetAction(currentState); UpdateAgentPosition(ref agentCurrentX, ref agentCurrentY, action); mapToDisplay[agentCurrentY, agentCurrentX] = 2; }
讓我們把它分成更容易消化的部分。我們要做的第一件事就是建立禁忌政策。如果您不熟悉tabu搜索,請注意,它的目的是通過放松其規則來提高本地搜索的性能。在每一步中,如果沒有其他選擇(有回報的行動),有時惡化行動是可以接受的。
此外,還設置了prohibition (tabu),以確保算法不會返回到以前訪問的解決方案。
TabuSearchExploration tabuPolicy; if (qLearning != null) tabuPolicy = (TabuSearchExploration)qLearning.ExplorationPolicy; else if (sarsa != null) tabuPolicy = (TabuSearchExploration)sarsa.ExplorationPolicy; else throw new Exception(); var explorationPolicy = (EpsilonGreedyExploration)tabuPolicy?.BasePolicy; explorationPolicy.Epsilon = 0; tabuPolicy?.ResetTabuList();
接下來,我們要定位我們的對象并準備地圖。
int agentCurrentX = agentStartX, agentCurrentY = agentStartY; Array.Copy(map, mapToDisplay, mapWidth * mapHeight); mapToDisplay[agentStartY, agentStartX] = 2; mapToDisplay[agentStopY, agentStopX] = 3;
下面是我們的主執行循環,它將以動畫的方式顯示解決方案:
while (!needToStop) { cellWorld.Map = mapToDisplay; Thread.Sleep(200); if ((agentCurrentX == agentStopX) && (agentCurrentY == agentStopY)) { mapToDisplay[agentStartY, agentStartX] = 2; mapToDisplay[agentStopY, agentStopX] = 3; agentCurrentX = agentStartX; agentCurrentY = agentStartY; cellWorld.Map = mapToDisplay; Thread.Sleep(200); } mapToDisplay[agentCurrentY, agentCurrentX] = 0; int currentState = GetStateNumber(agentCurrentX, agentCurrentY); int action = qLearning?.GetAction(currentState) ?? sarsa.GetAction(currentState); UpdateAgentPosition(ref agentCurrentX, ref agentCurrentY, action); mapToDisplay[agentCurrentY, agentCurrentX] = 2; }
漢諾塔游戲
河內塔由三根桿子和最左邊的幾個按順序大小排列的圓盤組成。目標是用最少的移動次數將所有磁盤從最左邊的棒子移動到最右邊的棒子。
你必須遵守的兩條重要規則是,一次只能移動一個磁盤,不能把大磁盤放在小磁盤上;也就是說,在任何棒中,磁盤的順序必須始終是從底部最大的磁盤到頂部最小的磁盤,如下所示:

假設我們使用三個磁盤,如圖所示。在這種情況下,有33種可能的狀態,如下圖所示:
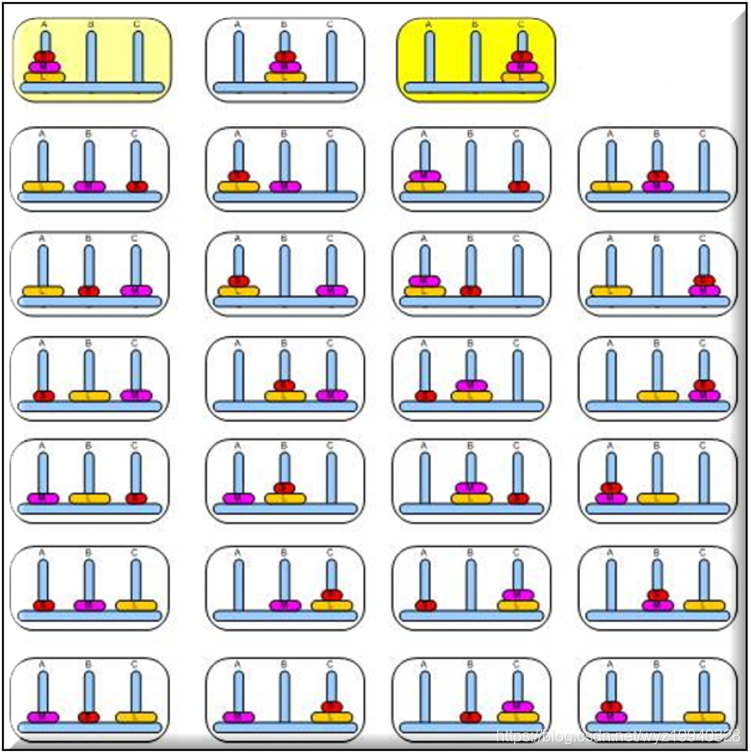
河內塔謎題中所有可能狀態的總數是3的磁盤數次冪。

其中||S||是集合狀態中的元素個數,n是磁盤的個數。
在我們的例子中,我們有3×3×3 = 27個圓盤在這三根棒上分布的唯一可能狀態,包括空棒;但是兩個空棒可以處于最大狀態。
定義了狀態總數之后,下面是我們的算法從一種狀態移動到另一種狀態的所有可能操作:
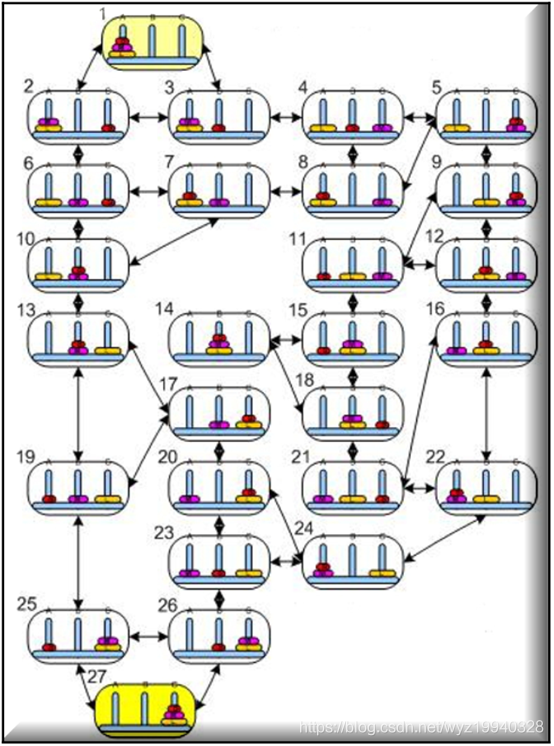
這個謎題的最小可能步數是:

磁盤的數量是n。
Q-learning算法的正式定義如下:
在這個Q-learning算法中,我們使用了以下變量:
- Q矩陣:一個二維數組,首先對所有元素填充一個固定值(通常為0),用于保存所有狀態下的計算策略;也就是說,對于每一個狀態,它持有對各自可能的行動的獎勵。
- 折扣因子:決定了對象如何處理獎勵的政策。當貼現率接近0時,只考慮當前的報酬會使對象變得貪婪,而當貼現率接近1時,會使對象變得更具策略性和前瞻性,從而在長期內獲得更好的報酬。
- R矩陣:包含初始獎勵的二維數組,允許程序確定特定狀態的可能操作列表。
我們應該簡要介紹一下Q-learning Class的一些方法:
Init:生成所有可能的狀態以及開始學習過程。
Learn:在學習過程中有順序的步驟
InitRMatrix: 這個初始化獎勵矩陣的值如下:
1. 0:在這種狀態下,我們沒有獎勵。
2. 100:這是我們在最終狀態下的最大獎勵,我們想去的地方。
3. X:在這種情況下是不可能采取這種行動的。
TrainQMatrix: 包含Q矩陣的實際迭代值更新規則。完成后,我們希望得到一個訓練有素的對象。
NormalizeQMatrix: 使Q矩陣的值標準化,使它們成為百分數。
Test: 提供來自用戶的文本輸入,并顯示解決此難題的最佳最短路徑。
讓我們更深入地研究我們的TrainQMatrix的代碼:
/// <summary> /// 訓練Q矩陣 /// </summary> /// <param name="_StatesMaxCount">所有可能移動的個數</param> private void TrainQMatrix(int _StatesMaxCount) { pickedActions = new Dictionary<int, int>(); // 可用操作列表(基于R矩陣,其中包含從某個狀態開始的允許的下一個操作,在數組中為0) List<int> nextActions = new List<int>(); int counter = 0; int rIndex = 0; // 3乘以所有可能移動的個數就有足夠的集來訓練Q矩陣 while (counter < 3 * _StatesMaxCount) { var init = Utility.GetRandomNumber(0, _StatesMaxCount); do { // 獲得可用的動作 nextActions = GetNextActions(_StatesMaxCount, init); // 從可用動作中隨機選擇一個動作 if (nextActions != null) { var nextStep = Utility.GetRandomNumber(0, nextActions.Count); nextStep = nextActions[nextStep]; // 獲得可用的動作 nextActions = GetNextActions(_StatesMaxCount, nextStep); // 設置從該狀態采取的動作的索引 for (int i = 0; i < 3; i++) { if (R != null && R[init, i, 1] == nextStep) rIndex = i; } // 這是值迭代更新規則-折現系數是0.8 Q[init, nextStep] = R[init, rIndex, 0] + 0.8 * Utility.GetMax(Q, nextStep, nextActions); // 將下一步設置為當前步驟 init = nextStep; } } while (init != FinalStateIndex); counter++; } }
使用三個磁盤運行應用程序:
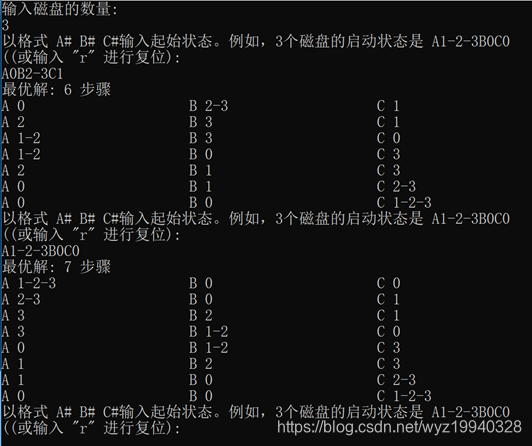
使用四個磁盤運行應用程序:
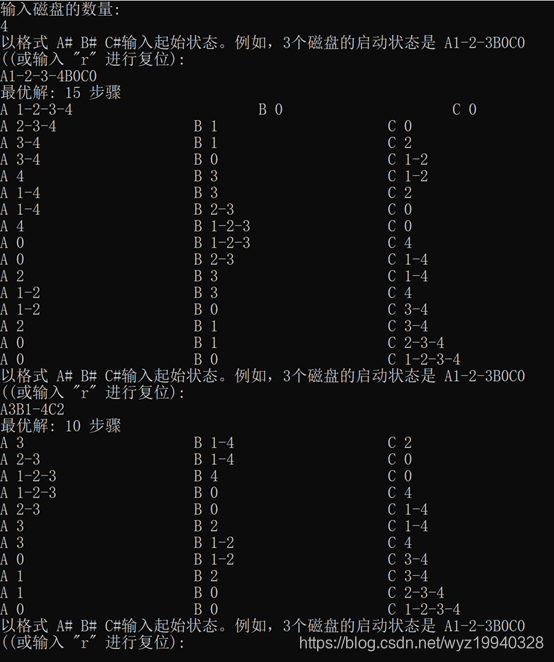
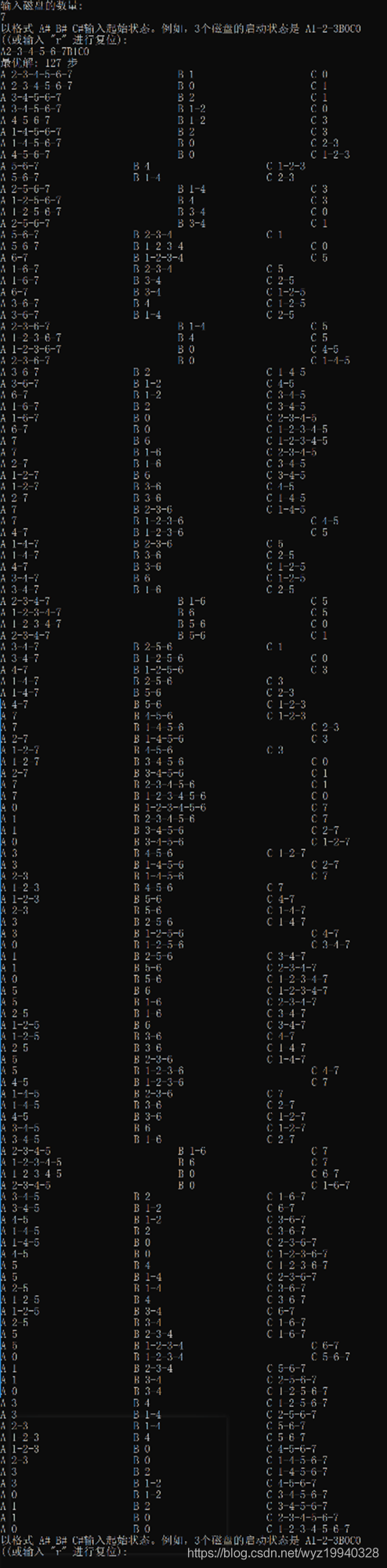
這里有7個磁盤。最佳移動步數是127,所以你可以看到解決方案可以多快地乘以可能的組合:
總結
這種形式的強化學習更正式地稱為馬爾可夫決策過程(Markov Decision Process, MDP)。MDP是一個離散時間隨機控制的過程,這意味著在每個時間步,在狀態x下,決策者可以選擇任何可用的行動狀態,這個過程將在下一步反應,隨機移動到一個新的狀態,給決策者一個獎勵。進程進入新狀態的概率由所選動作決定。因此,下一個狀態取決于當前狀態和決策者的行為。給定狀態和操作,下一步完全獨立于之前的所有狀態和操作。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號