
2 數(shù)據(jù)類型、字符編碼、文件處理
一 引子
1 什么是數(shù)據(jù)?
x=10,10是我們要存儲(chǔ)的數(shù)據(jù)
2 為何數(shù)據(jù)要分不同的類型
數(shù)據(jù)是用來(lái)表示狀態(tài)的,不同的狀態(tài)就應(yīng)該用不同的類型的數(shù)據(jù)去表示
3 數(shù)據(jù)類型
數(shù)字(整形,長(zhǎng)整形,浮點(diǎn)型,復(fù)數(shù))
字符串
字節(jié)串:在介紹字符編碼時(shí)介紹字節(jié)bytes類型
列表
元組
字典
集合
4 按照以下幾個(gè)點(diǎn)展開數(shù)據(jù)類型的學(xué)習(xí)
#======================================基本使用======================================
#1、用途
#2、定義方式
#3、常用操作+內(nèi)置的方法
#======================================該類型總結(jié)====================================
#存一個(gè)值or存多個(gè)值
#有序or無(wú)序
#可變or不可變(1、可變:值變,id不變。可變==不可hash 2、不可變:值變,id就變。不可變==可hash)
二 數(shù)字
整型與浮點(diǎn)型
#整型int 作用:年紀(jì),等級(jí),身份證號(hào),qq號(hào)等整型數(shù)字相關(guān) 定義: age=10 #本質(zhì)age=int(10) #浮點(diǎn)型float 作用:薪資,身高,體重,體質(zhì)參數(shù)等浮點(diǎn)數(shù)相關(guān) salary=3000.3 #本質(zhì)salary=float(3000.3) #二進(jìn)制,十進(jìn)制,八進(jìn)制,十六進(jìn)制
其他數(shù)字類型(了解)
#長(zhǎng)整形(了解) 在python2中(python3中沒(méi)有長(zhǎng)整形的概念): >>> num=2L >>> type(num) <type 'long'> #復(fù)數(shù)(了解) >>> x=1-2j >>> x.real 1.0 >>> x.imag -2.0
三 字符串
#作用:名字,性別,國(guó)籍,地址等描述信息 #定義:在單引號(hào)\雙引號(hào)\三引號(hào)內(nèi),由一串字符組成 name='elton' #優(yōu)先掌握的操作: #1、按索引取值(正向取+反向取) :只能取 #2、切片(顧頭不顧尾,步長(zhǎng)) #3、長(zhǎng)度len #4、成員運(yùn)算in和not in #5、移除空白strip #6、切分split #7、循環(huán)
需要掌握的操作
#1、strip,lstrip,rstrip
#2、lower,upper
#3、startswith,endswith
#4、format的三種玩法
#5、split,rsplit
#6、join
#7、replace
#8、isdigit


#strip name='*elton**' print(name.strip('*')) print(name.lstrip('*')) print(name.rstrip('*')) #lower,upper name='elton' print(name.lower()) print(name.upper()) #startswith,endswith name='alex_SB' print(name.endswith('SB')) print(name.startswith('alex')) #format的三種玩法 res='{} {} {}'.format('elton',18,'male') res='{1} {0} {1}'.format('elton',18,'male') res='{name} {age} {sex}'.format(sex='male',name='elton',age=18) #split name='root:x:0:0::/root:/bin/bash' print(name.split(':')) #默認(rèn)分隔符為空格 name='C:/a/b/c/d.txt' #只想拿到頂級(jí)目錄 print(name.split('/',1)) name='a|b|c' print(name.rsplit('|',1)) #從右開始切分 #join tag=' ' print(tag.join(['elton','say','hello','world'])) #可迭代對(duì)象必須都是字符串 #replace name='alex say :i have one tesla,my name is alex' print(name.replace('alex','SB',1)) #isdigit:可以判斷bytes和unicode類型,是最常用的用于于判斷字符是否為"數(shù)字"的方法 age=input('>>: ') print(age.isdigit())
其他操作(了解即可)
#1、find,rfind,index,rindex,count #2、center,ljust,rjust,zfill #3、expandtabs #4、captalize,swapcase,title #5、is數(shù)字系列 #6、is其他
#find,rfind,index,rindex,count name='elton say hello' print(name.find('o',1,3)) #顧頭不顧尾,找不到則返回-1不會(huì)報(bào)錯(cuò),找到了則顯示索引 # print(name.index('e',2,4)) #同上,但是找不到會(huì)報(bào)錯(cuò) print(name.count('e',1,3)) #顧頭不顧尾,如果不指定范圍則查找所有 #center,ljust,rjust,zfill name='elton' print(name.center(30,'-')) print(name.ljust(30,'*')) print(name.rjust(30,'*')) print(name.zfill(50)) #用0填充 #expandtabs name='elton\thello' print(name) print(name.expandtabs(1)) #captalize,swapcase,title print(name.capitalize()) #首字母大寫 print(name.swapcase()) #大小寫翻轉(zhuǎn) msg='elton say hi' print(msg.title()) #每個(gè)單詞的首字母大寫 #is數(shù)字系列 #在python3中 num1=b'4' #bytes num2=u'4' #unicode,python3中無(wú)需加u就是unicode num3='四' #中文數(shù)字 num4='Ⅳ' #羅馬數(shù)字 #isdigt:bytes,unicode print(num1.isdigit()) #True print(num2.isdigit()) #True print(num3.isdigit()) #False print(num4.isdigit()) #False #isdecimal:uncicode #bytes類型無(wú)isdecimal方法 print(num2.isdecimal()) #True print(num3.isdecimal()) #False print(num4.isdecimal()) #False #isnumberic:unicode,中文數(shù)字,羅馬數(shù)字 #bytes類型無(wú)isnumberic方法 print(num2.isnumeric()) #True print(num3.isnumeric()) #True print(num4.isnumeric()) #True #三者不能判斷浮點(diǎn)數(shù) num5='4.3' print(num5.isdigit()) print(num5.isdecimal()) print(num5.isnumeric()) ''' 總結(jié): 最常用的是isdigit,可以判斷bytes和unicode類型,這也是最常見的數(shù)字應(yīng)用場(chǎng)景 如果要判斷中文數(shù)字或羅馬數(shù)字,則需要用到isnumeric ''' #is其他 print('===>') name='elton123' print(name.isalnum()) #字符串由字母或數(shù)字組成 print(name.isalpha()) #字符串只由字母組成 print(name.isidentifier()) print(name.islower()) print(name.isupper()) print(name.isspace()) print(name.istitle())
練習(xí)
# 寫代碼,有如下變量,請(qǐng)按照要求實(shí)現(xiàn)每個(gè)功能 (共6分,每小題各0.5分)
name = " aleX"
# 1) 移除 name 變量對(duì)應(yīng)的值兩邊的空格,并輸出處理結(jié)果
# 2) 判斷 name 變量對(duì)應(yīng)的值是否以 "al" 開頭,并輸出結(jié)果?
# 3) 判斷 name 變量對(duì)應(yīng)的值是否以 "X" 結(jié)尾,并輸出結(jié)果?
# 4) 將 name 變量對(duì)應(yīng)的值中的 “l(fā)” 替換為 “p”,并輸出結(jié)果
# 5) 將 name 變量對(duì)應(yīng)的值根據(jù) “l(fā)” 分割,并輸出結(jié)果。
# 6) 將 name 變量對(duì)應(yīng)的值變大寫,并輸出結(jié)果?
# 7) 將 name 變量對(duì)應(yīng)的值變小寫,并輸出結(jié)果?
# 8) 請(qǐng)輸出 name 變量對(duì)應(yīng)的值的第 2 個(gè)字符?
# 9) 請(qǐng)輸出 name 變量對(duì)應(yīng)的值的前 3 個(gè)字符?
# 10) 請(qǐng)輸出 name 變量對(duì)應(yīng)的值的后 2 個(gè)字符??
# 11) 請(qǐng)輸出 name 變量對(duì)應(yīng)的值中 “e” 所在索引位置??
# 12) 獲取子序列,去掉最后一個(gè)字符。如: oldboy 則獲取 oldbo。
# 寫代碼,有如下變量,請(qǐng)按照要求實(shí)現(xiàn)每個(gè)功能 (共6分,每小題各0.5分) name = " aleX" # 1) 移除 name 變量對(duì)應(yīng)的值兩邊的空格,并輸出處理結(jié)果 name = ' aleX' a=name.strip() print(a) # 2) 判斷 name 變量對(duì)應(yīng)的值是否以 "al" 開頭,并輸出結(jié)果? name=' aleX' if name.startswith(name): print(name) else: print('no') # 3) 判斷 name 變量對(duì)應(yīng)的值是否以 "X" 結(jié)尾,并輸出結(jié)果? name=' aleX' if name.endswith(name): print(name) else: print('no') # 4) 將 name 變量對(duì)應(yīng)的值中的 “l(fā)” 替換為 “p”,并輸出結(jié)果 name=' aleX' print(name.replace('l','p')) # 5) 將 name 變量對(duì)應(yīng)的值根據(jù) “l(fā)” 分割,并輸出結(jié)果。 name=' aleX' print(name.split('l')) # 6) 將 name 變量對(duì)應(yīng)的值變大寫,并輸出結(jié)果? name=' aleX' print(name.upper()) # 7) 將 name 變量對(duì)應(yīng)的值變小寫,并輸出結(jié)果? name=' aleX' print(name.lower()) # 8) 請(qǐng)輸出 name 變量對(duì)應(yīng)的值的第 2 個(gè)字符? name=' aleX' print(name[1]) # 9) 請(qǐng)輸出 name 變量對(duì)應(yīng)的值的前 3 個(gè)字符? name=' aleX' print(name[:3]) # 10) 請(qǐng)輸出 name 變量對(duì)應(yīng)的值的后 2 個(gè)字符?? name=' aleX' print(name[-2:]) # 11) 請(qǐng)輸出 name 變量對(duì)應(yīng)的值中 “e” 所在索引位置?? name=' aleX' print(name.index('e')) # 12) 獲取子序列,去掉最后一個(gè)字符。如: oldboy 則獲取 oldbo。 name=' aleX' a=name[:-1] print(a)
四 列表
#作用:多個(gè)裝備,多個(gè)愛(ài)好,多門課程,多個(gè)女朋友等 #定義:[]內(nèi)可以有多個(gè)任意類型的值,逗號(hào)分隔 my_girl_friends=['alex','elton','boss',4,5] #本質(zhì)my_girl_friends=list([...]) 或 l=list('abc') #優(yōu)先掌握的操作: #1、按索引存取值(正向存取+反向存取):即可存也可以取 #2、切片(顧頭不顧尾,步長(zhǎng)) #3、長(zhǎng)度 #4、成員運(yùn)算in和not in #5、追加 #6、刪除 #7、循環(huán)
#ps:反向步長(zhǎng) l=[1,2,3,4,5,6] #正向步長(zhǎng) l[0:3:1] #[1, 2, 3] #反向步長(zhǎng) l[2::-1] #[3, 2, 1] #列表翻轉(zhuǎn) l[::-1] #[6, 5, 4, 3, 2, 1]
練習(xí):
1. 有列表data=['alex',49,[1900,3,18]],分別取出列表中的名字,年齡,出生的年,月,日賦值給不同的變量
2. 用列表模擬隊(duì)列
3. 用列表模擬堆棧
4. 有如下列表,請(qǐng)按照年齡排序(涉及到匿名函數(shù))
l=[
{'name':'alex','age':84},
{'name':'boss','age':73},
{'name':'elton','age':18},
]
答案:
l.sort(key=lambda item:item['age'])
print(l)
五 元組
#作用:存多個(gè)值,對(duì)比列表來(lái)說(shuō),元組不可變(是可以當(dāng)做字典的key的),主要是用來(lái)讀 #定義:與列表類型比,只不過(guò)[]換成() age=(11,22,33,44,55)本質(zhì)age=tuple((11,22,33,44,55)) #優(yōu)先掌握的操作: #1、按索引取值(正向取+反向取):只能取 #2、切片(顧頭不顧尾,步長(zhǎng)) #3、長(zhǎng)度 #4、成員運(yùn)算in和not in #5、循環(huán)
練習(xí)
#簡(jiǎn)單購(gòu)物車,要求如下:
實(shí)現(xiàn)打印商品詳細(xì)信息,用戶輸入商品名和購(gòu)買個(gè)數(shù),則將商品名,價(jià)格,購(gòu)買個(gè)數(shù)加入購(gòu)物列表,如果輸入為空或其他非法輸入則要求用戶重新輸入
msg_dic={
'apple':10,
'tesla':100000,
'mac':3000,
'lenovo':30000,
'chicken':10,
}
1 msg_dic={ 2 'apple':10, 3 'tesla':100000, 4 'mac':3000, 5 'lenovo':30000, 6 'chicken':10, 7 } 8 goods_l=[] 9 while True: 10 for key,item in msg_dic.items(): 11 print('name:{name} price:{price}'.format(price=item,name=key)) 12 choice=input('商品>>: ').strip() 13 if not choice or choice not in msg_dic:continue 14 count=input('購(gòu)買個(gè)數(shù)>>: ').strip() 15 if not count.isdigit():continue 16 goods_l.append((choice,msg_dic[choice],count)) 17 18 print(goods_l)
六 字典
#作用:存多個(gè)值,key-value存取,取值速度快 #定義:key必須是不可變類型,value可以是任意類型 info={'name':'elton','age':18,'sex':'male'} #本質(zhì)info=dict({....}) 或 info=dict(name='elton',age=18,sex='male') 或 info=dict([['name','elton'],('age',18)]) 或 {}.fromkeys(('name','age','sex'),None) #優(yōu)先掌握的操作: #1、按key存取值:可存可取 #2、長(zhǎng)度len #3、成員運(yùn)算in和not in #4、刪除 #5、鍵keys(),值values(),鍵值對(duì)items() #6、循環(huán)
練習(xí)
1 有如下值集合 [11,22,33,44,55,66,77,88,99,90...],將所有大于 66 的值保存至字典的第一個(gè)key中,將小于 66 的值保存至第二個(gè)key的值中
即: {'k1': 大于66的所有值, 'k2': 小于66的所有值}
a={'k1':[],'k2':[]}
c=[11,22,33,44,55,66,77,88,99,90]
for i in c:
if i>66:
a['k1'].append(i)
else:
a['k2'].append(i)
print(a)
2 統(tǒng)計(jì)s='hello alex alex say hello sb sb'中每個(gè)單詞的個(gè)數(shù) 結(jié)果如:{'hello': 2, 'alex': 2, 'say': 1, 'sb': 2}
s='hello alex alex say hello sb sb' l=s.split() dic={} for item in l: if item in dic: dic[item]+=1 else: dic[item]=1 print(dic)
s='hello alex alex say hello sb sb' dic={} words=s.split() print(words) for word in words: #word='alex' dic[word]=s.count(word) print(dic) #利用setdefault解決重復(fù)賦值 ''' setdefault的功能 1:key存在,則不賦值,key不存在則設(shè)置默認(rèn)值 2:key存在,返回的是key對(duì)應(yīng)的已有的值,key不存在,返回的則是要設(shè)置的默認(rèn)值 d={} print(d.setdefault('a',1)) #返回1 d={'a':2222} print(d.setdefault('a',1)) #返回2222 ''' s='hello alex alex say hello sb sb' dic={} words=s.split() for word in words: #word='alex' dic.setdefault(word,s.count(word)) print(dic) #利用集合,去掉重復(fù),減少循環(huán)次數(shù) s='hello alex alex say hello sb sb' dic={} words=s.split() words_set=set(words) for word in words_set: dic[word]=s.count(word) print(dic)
七 集合
#作用:去重,關(guān)系運(yùn)算, #定義: 知識(shí)點(diǎn)回顧 可變類型是不可hash類型 不可變類型是可hash類型 #定義集合: 集合:可以包含多個(gè)元素,用逗號(hào)分割, 集合的元素遵循三個(gè)原則: 1:每個(gè)元素必須是不可變類型(可hash,可作為字典的key) 2:沒(méi)有重復(fù)的元素 3:無(wú)序 注意集合的目的是將不同的值存放到一起,不同的集合間用來(lái)做關(guān)系運(yùn)算,無(wú)需糾結(jié)于集合中單個(gè)值 #優(yōu)先掌握的操作: #1、長(zhǎng)度len #2、成員運(yùn)算in和not in #3、|合集 #4、&交集 #5、-差集 #6、^對(duì)稱差集 #7、== #8、父集:>,>=
#9、子集:<,<=
練習(xí)
一.關(guān)系運(yùn)算
有如下兩個(gè)集合,pythons是報(bào)名python課程的學(xué)員名字集合,linuxs是報(bào)名linux課程的學(xué)員名字集合
pythons={'alex','egon','yuanhao','wupeiqi','gangdan','biubiu'}
linuxs={'wupeiqi','oldboy','gangdan'}
1. 求出即報(bào)名python又報(bào)名linux課程的學(xué)員名字集合
2. 求出所有報(bào)名的學(xué)生名字集合
3. 求出只報(bào)名python課程的學(xué)員名字
4. 求出沒(méi)有同時(shí)這兩門課程的學(xué)員名字集合
# 有如下兩個(gè)集合,pythons是報(bào)名python課程的學(xué)員名字集合,linuxs是報(bào)名linux課程的學(xué)員名字集合 pythons={'alex','elton','boss','tony','gangdan','biubiu'} linuxs={'wupeiqi','oldboy','gangdan'} # 求出即報(bào)名python又報(bào)名linux課程的學(xué)員名字集合 print(pythons & linuxs) # 求出所有報(bào)名的學(xué)生名字集合 print(pythons | linuxs) # 求出只報(bào)名python課程的學(xué)員名字 print(pythons - linuxs) # 求出沒(méi)有同時(shí)這兩門課程的學(xué)員名字集合 print(pythons ^ linuxs)
二.去重 1. 有列表l=['a','b',1,'a','a'],列表元素均為可hash類型,去重,得到新列表,且新列表無(wú)需保持列表原來(lái)的順序 2.在上題的基礎(chǔ)上,保存列表原來(lái)的順序 3.去除文件中重復(fù)的行,肯定要保持文件內(nèi)容的順序不變 4.有如下列表,列表元素為不可hash類型,去重,得到新列表,且新列表一定要保持列表原來(lái)的順序 l=[ {'name':'elton','age':18,'sex':'male'}, {'name':'alex','age':73,'sex':'male'}, {'name':'elton','age':20,'sex':'female'}, {'name':'elton','age':18,'sex':'male'}, {'name':'elton','age':18,'sex':'male'}, ]
#去重,無(wú)需保持原來(lái)的順序 l=['a','b',1,'a','a'] print(set(l)) #去重,并保持原來(lái)的順序 #方法一:不用集合 l=[1,'a','b',1,'a'] l1=[] for i in l: if i not in l1: l1.append(i) print(l1) #方法二:借助集合 l1=[] s=set() for i in l: if i not in s: s.add(i) l1.append(i) print(l1) #同上方法二,去除文件中重復(fù)的行 import os with open('db.txt','r',encoding='utf-8') as read_f,\ open('.db.txt.swap','w',encoding='utf-8') as write_f: s=set() for line in read_f: if line not in s: s.add(line) write_f.write(line) os.remove('db.txt') os.rename('.db.txt.swap','db.txt') #列表中元素為可變類型時(shí),去重,并且保持原來(lái)順序 l=[ {'name':'egon','age':18,'sex':'male'}, {'name':'alex','age':73,'sex':'male'}, {'name':'egon','age':20,'sex':'female'}, {'name':'egon','age':18,'sex':'male'}, {'name':'egon','age':18,'sex':'male'}, ] # print(set(l)) #報(bào)錯(cuò):unhashable type: 'dict' s=set() l1=[] for item in l: val=(item['name'],item['age'],item['sex']) if val not in s: s.add(val) l1.append(item) print(l1) #定義函數(shù),既可以針對(duì)可以hash類型又可以針對(duì)不可hash類型 def func(items,key=None): s=set() for item in items: val=item if key is None else key(item) if val not in s: s.add(val) yield item print(list(func(l,key=lambda dic:(dic['name'],dic['age'],dic['sex']))))
八 數(shù)據(jù)類型總結(jié)
按存儲(chǔ)空間的占用分(從低到高)
數(shù)字 字符串 集合:無(wú)序,即無(wú)序存索引相關(guān)信息 元組:有序,需要存索引相關(guān)信息,不可變 列表:有序,需要存索引相關(guān)信息,可變,需要處理數(shù)據(jù)的增刪改 字典:無(wú)序,需要存key與value映射的相關(guān)信息,可變,需要處理數(shù)據(jù)的增刪改
按存值個(gè)數(shù)區(qū)分
| 標(biāo)量/原子類型 | 數(shù)字,字符串 |
| 容器類型 | 列表,元組,字典 |
按可變不可變區(qū)分
| 可變 | 列表,字典 |
| 不可變 | 數(shù)字,字符串,元組 |
按訪問(wèn)順序區(qū)分
| 直接訪問(wèn) | 數(shù)字 |
| 順序訪問(wèn)(序列類型) | 字符串,列表,元組 |
| key值訪問(wèn)(映射類型) | 字典 |
九 運(yùn)算符
#身份運(yùn)算(is ,is not)
is比較的是id,而雙等號(hào)比較的是值
毫無(wú)疑問(wèn),id若相同則值肯定相同,而值相同id則不一定相同
>>> x=1234567890
>>> y=1234567890
>>> x == y
True
>>> id(x),id(y)
(3581040, 31550448)
>>> x is y
False
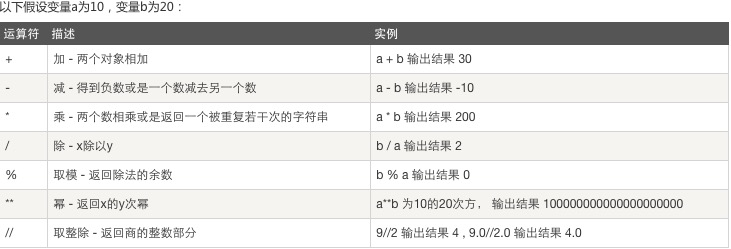
2、比較運(yùn)算:

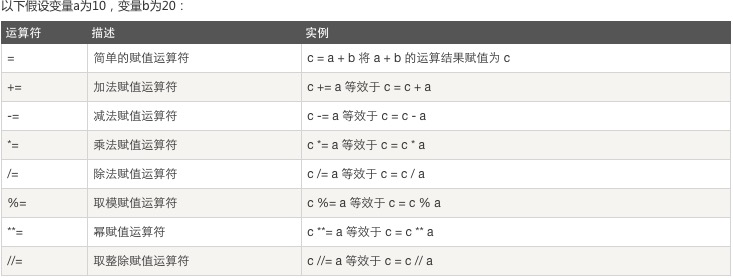
3、賦值運(yùn)算:
4、位運(yùn)算:
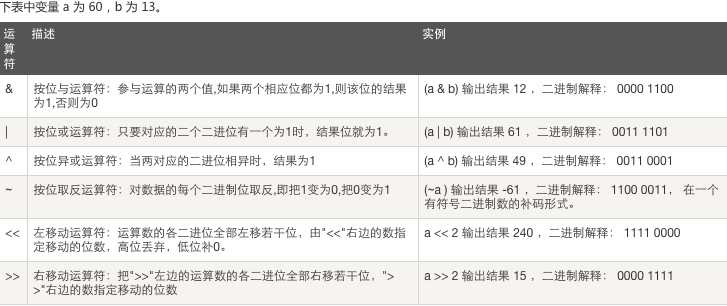
注: ~ 舉例: ~5 = -6 解釋: 將二進(jìn)制數(shù)+1之后乘以-1,即~x = -(x+1),-(101 + 1) = -110
按位反轉(zhuǎn)僅能用在數(shù)字前面。所以寫成 3+~5 可以得到結(jié)果-3,寫成3~5就出錯(cuò)了
5、邏輯運(yùn)算:

and注解:
- 在Python 中,and 和 or 執(zhí)行布爾邏輯演算,如你所期待的一樣,但是它們并不返回布爾值;而是,返回它們實(shí)際進(jìn)行比較的值之一。
- 在布爾上下文中從左到右演算表達(dá)式的值,如果布爾上下文中的所有值都為真,那么 and 返回最后一個(gè)值。
- 如果布爾上下文中的某個(gè)值為假,則 and 返回第一個(gè)假值
or注解:
- 使用 or 時(shí),在布爾上下文中從左到右演算值,就像 and 一樣。如果有一個(gè)值為真,or 立刻返回該值
- 如果所有的值都為假,or 返回最后一個(gè)假值
- 注意 or 在布爾上下文中會(huì)一直進(jìn)行表達(dá)式演算直到找到第一個(gè)真值,然后就會(huì)忽略剩余的比較值
and-or結(jié)合使用:
- 結(jié)合了前面的兩種語(yǔ)法,推理即可。
- 為加強(qiáng)程序可讀性,最好與括號(hào)連用,例如:
(1 and 'x') or 'y'
6、成員運(yùn)算:

7.身份運(yùn)算

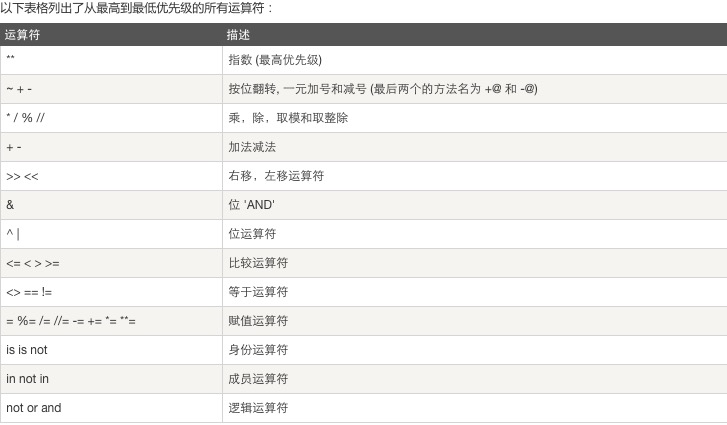
8.運(yùn)算符優(yōu)先級(jí):自上而下,優(yōu)先級(jí)從高到低
十 字符編碼
http://www.rzrgm.cn/wangcheng9418/p/9117955.html
十一 文件處理
http://www.rzrgm.cn/wangcheng9418/p/9117967.html

 浙公網(wǎng)安備 33010602011771號(hào)
浙公網(wǎng)安備 33010602011771號(hào)