

我所理解的機器學習

(2017年寫的博客,搬過來)
斷斷續續看了幾個月的機器學習,我覺得是時候總結一下了。正如題目講的那樣,我只說我所理解的機器學習,我不能保證我理解的都對,很多東西可能是我的誤解,但無論說錯了什么,我都認。如果有人發現錯誤,懇請指正,不勝感激。
我不講算法也不講公式推導,因為,我從頭到尾都沒看懂。
我所能講的就只有:“是什么”和“怎么用”的問題。至于“為什么”的問題,讓機器學習的專家和算法科學家們去解決吧…
什么是機器學習
“使計算機能夠在不經過明確編程的情況下進行學習的研究領域。”這是亞瑟·塞繆爾給機器學習的定義。
"what is machine learning" [1]<--這個是斯坦福機器學習課程里講機器學習定義的部分。
要我說,我覺得機器學習也是一個歸納和演繹的過程,先用數據和算法訓練出一個模型(歸納),然后用這個模型去做預測(演繹)。你的準備的數據越豐富,選用的算法越合理,訓練出的模型就越強大,最后做出的預測可能就越準確。
換個角度看,學習過程,其實也是一個從現象發現本質的過程。我們相信現象和本質有著某種聯系,我們試著用算法在現象和本質之間建立聯系。
《機器學習》[2]這本書里講了個挑西瓜的例子:瓜皮的深淺,敲瓜聲的沉悶清脆,瓜蒂的直蜷…這些是現象,瓜的生熟是本質。作為一個瓜農,我們見過成千上萬的瓜,經歷了無數次訓練以后,我們掌握了挑瓜的技能,實際上就是建立的模型,當一個新瓜放到我們面前的時候,我們就能判斷這個瓜是生的還是熟的,而且有超高的成功率。
但是給挑西瓜用程序建立個模型還是很困難的,因為瓜皮的深淺,聲音的很悶,瓜蒂的值蜷…這些都很難量化。我們來換個例子,換個可以用解方程來解決的問題:我們來預測房價(這個是斯坦福機器學習課程里將線性回歸時提到的例子,我們要講的比他簡單)。影響房價的因素有很多,地段,戶型,開發商,面積,房間數…但是,我們簡化,我們只看面積,我告訴你一條數據,一套100平米的房子房價是100萬,請問:一套200平米的房子房價是多少?你會說:200萬。因為你想:總價=面積 * 單價,100=100 * 單價,單價=1萬,所以200平的房子總價是200萬。你看,這就是“人工機器學習”,哈哈哈。
好的,現在問題來了,我再多給一條數據:一套150平的房子總價是140萬。請問:一套200平的房子總價是多少?懵逼了吧?多給一條:一套300平的房子總價是200萬。請問:一套200平的房子總價是多少?你可能會綜合考慮已知數據之后,給一個140萬到200萬之間的值。
我想,機器學習的過程大概就是這樣吧。
怎么用機器學習
請問:把大象關進冰箱里總共分幾步?
答:分三步:
-
把冰箱門打開
-
把大象放進冰箱里
-
把冰箱門撂上
好了,怎么用機器學習,講完了,哈哈哈
不開玩笑,就是這么簡單,不信看這篇文章–>量化機器學習簡易入門[3]
從實踐的角度看,使用機器學習的確就這么幾步:
-
準備數據
-
選擇算法
-
訓練模型
-
預測結果
-
評估結果,調整模型參數,從頭來過
這就是機器學習嗎?我也不知道,可能是吧。可能這跟你想的有點不同,坦白說,和我起初想的也不太一樣…

為期一周的機器學習[4]<–這是個較完整的介紹,可以讓你對機器學習有個大體的概念。
真正用的時候,可能會發現,大多數時間都是在準備數據,接著調用個函數就完了,讓人覺得,這機器學習聽起來高端,結果也不過是換個姿勢搬磚…
似乎所有的介紹機器學習的文章,都有現成的數據,大家都不太愿意在采集數據和整理數據上花費筆墨。這也的確是不好講的東西,無論你是爬蟲爬到的數據,還是業務數據庫導出的數據,默認你都會有自己的解決辦法,總之祝你好運。
下面是選擇算法。
機器學習的分類:
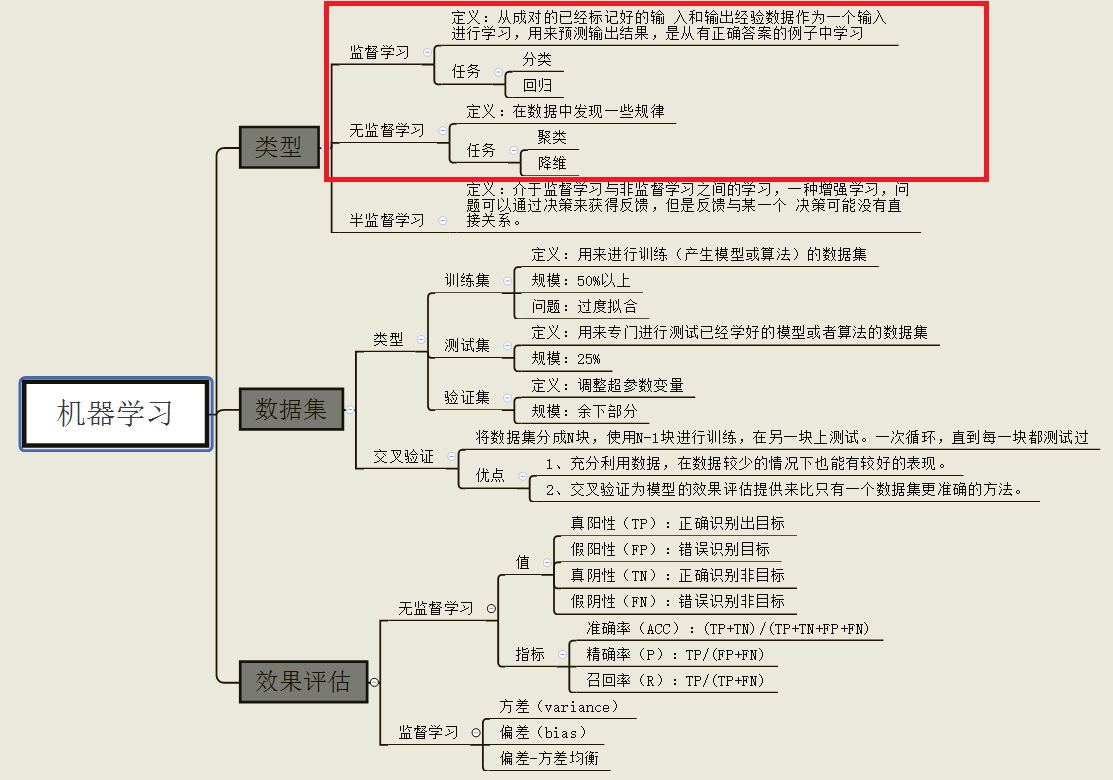
我們只看監督學習(分類與回歸)與非監督學習(聚類與降維)。
下面是一張scikit-learn官網上的一張圖,教你怎么選擇算法。
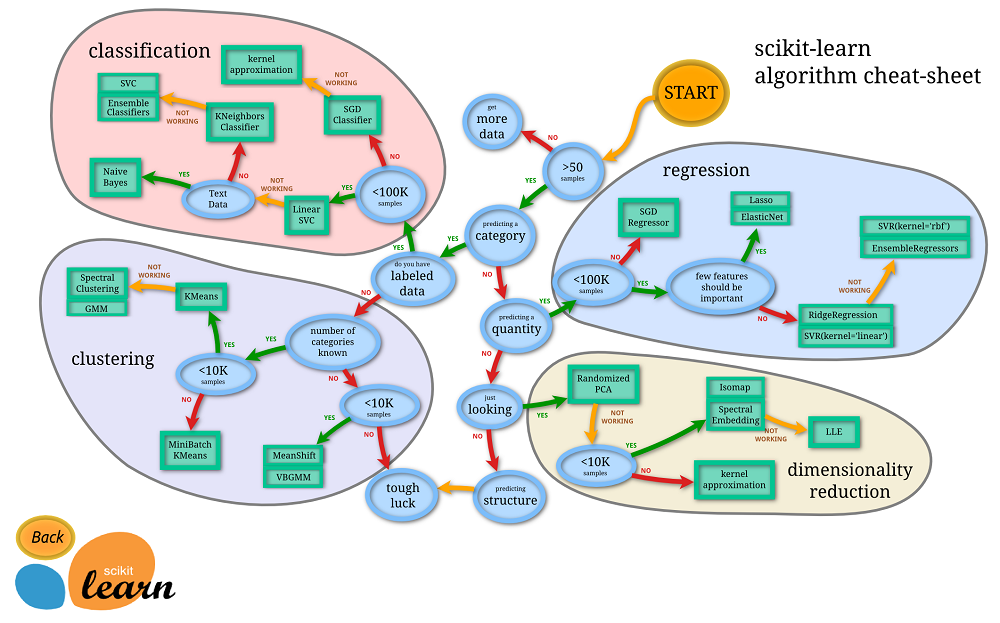
從圖上可以看出,你選什么算法,有時候是由你擁有什么樣的數據決定的…
當然,你也可以整理你的數據,讓數據符合你想要選擇的算法。
舉個例子:
就拿上面預測房價的例子來說吧,假設我有很多數據,我可能想預測的是房子的價格,這是個量化的目標,也有可能我想要預測的是這個房子是否會升值,而這就是個分類的目標。如果我要的是價格(量化目標),可能我要選的就是個回歸的算法,比如線性回歸(Linear Regression),嶺回歸(Ridge Regression);如果我想知道房子是否會升值(分類目標),可能我要選的就是個分類的算法,與此同時,數據也要做處理,我要對已知每條數據給個升值或者貶值的標簽,就是圖中說的labeled data。如果你想知道哪個開發商的房子升值概率大或者哪個版塊的房子有什么相同點,可能就需要選個聚合的算法,去挖掘一些意想不到的信息。如果你的數據非常復雜,比如房子外觀什么顏色,用的什么牌子的鋼筋水泥都有,你想抓住影響房價的主要因素,降低復雜度,可能就要去選一個降維的算法。
接下來把你的數據放到,算法模型里訓練。
完成后就可以拿模型去做預測了。
來一個完整的例子,通過支持向量機識別圖片中的數字:
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn import svm
# 準備數據,這個是sklearn內置的一個 圖形識別數字的數據
digits = datasets.load_digits()
# 選擇一個支持向量機的算法,后面是參數
clf = svm.SVC(gamma=0.001,C=100)
X,y = digits.data[:-10], digits.target[:-10]
# 訓練模型
clf.fit(X, y)
# 預測
print(clf.predict(digits.data[-7]))
plt.imshow(digits.images[-7], cmap=plt.cm.gray_r, interpolation='nearest')
plt.show()
可以在優礦上直接看運行結果
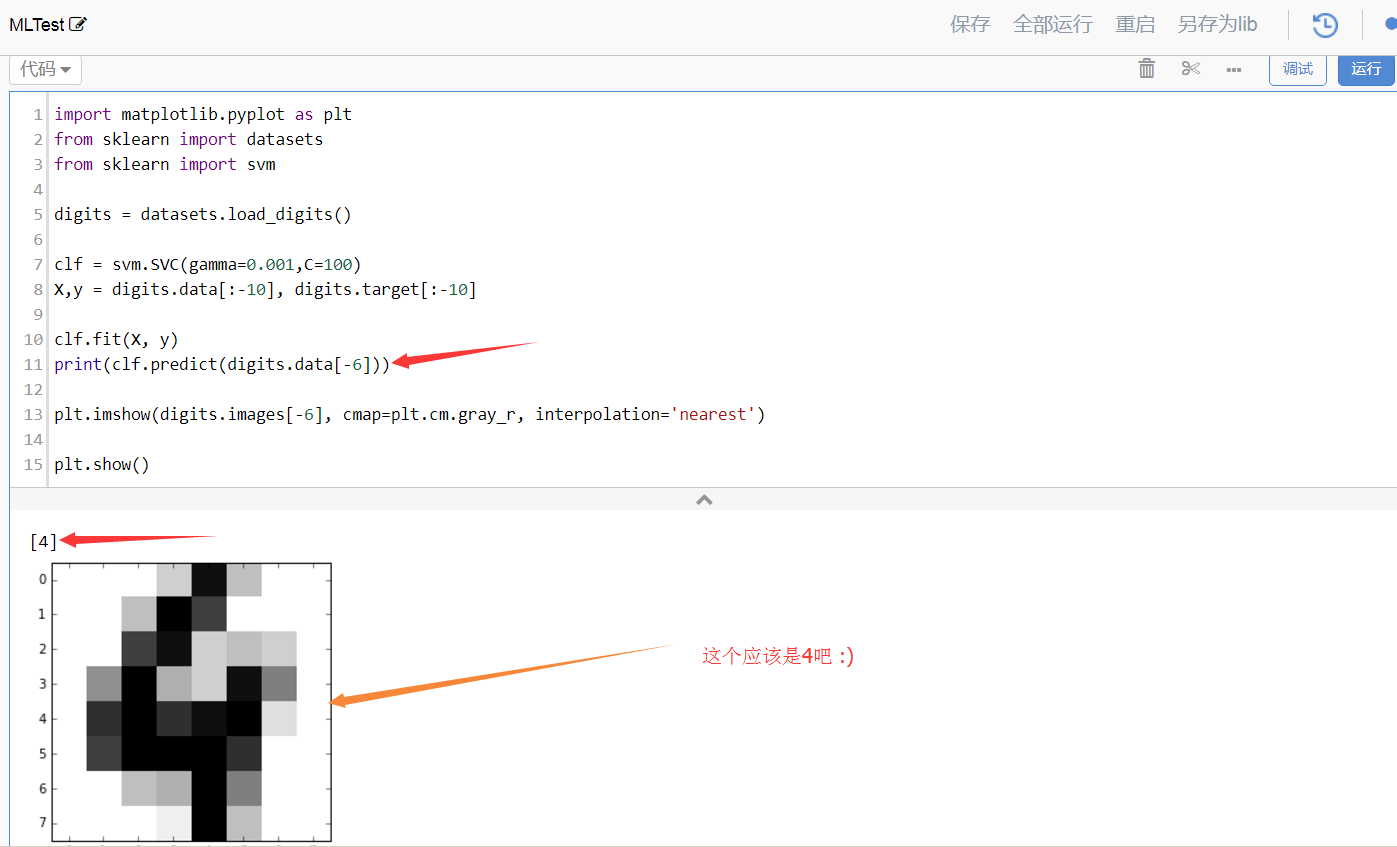
這是我通過優礦Uqer.io分享給你的量化策略研究,鏈接:https://uqer.datayes.com/v3/community/share/nQ1rPigotzvmewcxFJokuIWe0vE0?private;
密碼:4760
我想說的,講完了,接下來給兩篇文章:
使用Python編寫機器學習入門教程[5] <–這篇里面有一個信用卡欺詐的例子,從頭到尾都非常棒。
機器學習簡易入門(三) - 聚類 [6]<–這篇用共和黨民主黨投票的例子講聚類非常生動。
注:
[1]https://www.coursera.org/learn/machine-learning/lecture/PNeuX/what-is-machine-learning
[2] https://book.douban.com/subject/26708119/
[3] https://uqer.datayes.com/v3/community/share/58f48343271e3b0054da05e8
[4]http://blog.jobbole.com/110684/
[5]http://www.infoq.com/cn/articles/ml-intro-python
[6]http://www.rzrgm.cn/kylinlin/p/5299078.html
-------------------------------
著作權歸作者所有。商業轉載請聯系作者獲得授權,非商業轉載請注明出處。
原文: https://wangxuan.me/tech/2017/07/04/machine-learning-in-my-opinion.html

 浙公網安備 33010602011771號
浙公網安備 33010602011771號