
EMNLP 2025|vivo 等提出 DiMo-GUI:模態分治+動態聚焦,GUI 智能體推理時擴展的新范式
作者:vivo 互聯網算法團隊
本文入選 EMNLP 2025 Main Conference
EMNLP會議全稱為Conference on Empirical Methods in Natural Language Processing,由國際計算語言學協會ACL舉辦,是自然語言處理和人工智能領域最重要的學術會議之一。EMNLP 2025會議共有8174篇投稿,Main Conference接收率僅為22.16%。

項目主頁:
https://github.com/vivo/DiMo-GUI
摘要:
本文介紹了一種無需額外訓練的GUI定位框架DiMo-GUI,針對多模態大語言模型(MLLMs)在復雜圖形用戶界面(GUI)定位任務中的挑戰,通過動態視覺推理與模態感知優化顯著提升性能。DiMo-GUI采用逐級縮放的動態定位機制,迭代裁剪聚焦目標區域,減少視覺冗余;同時分離文本與圖標模態,獨立推理后結合指令評估確定最終目標,有效平衡多模態處理能力。在GUI定位任務最新的基準數據集上,DiMo-GUI相較基線展現顯著性能提升。作為即插即用框架,DiMo-GUI適用于網頁導航、移動應用自動化等場景,未來可通過回溯機制進一步提升魯棒性。
該工作由vivo互聯網算法團隊、加州大學默塞德分校、昆士蘭大學共同完成。
一、引言
隨著圖形用戶界面(Graphical User Interface, GUI)在自動化導航和操作系統控制等領域的廣泛應用,基于自然語言查詢的GUI 定位(GUI Grounding)成為多模態大語言模型(multimodal large language models, MLLMs)的重要研究方向。然而,GUI 環境的視覺復雜性、語言歧義以及空間雜亂等問題為精準定位帶來了顯著挑戰。
本文基于最新研究《DiMo-GUI: Advancing Test-time Scaling in GUI Grounding via Modality-Aware Visual Reasoning》,介紹了一種無需額外訓練的 GUI 定位框架——DiMo-GUI,通過動態視覺推理和模態感知優化顯著提升了多模態大模型在復雜 GUI 環境中的定位性能,推動了推理時擴展(test-time scaling)在該領域的發展。
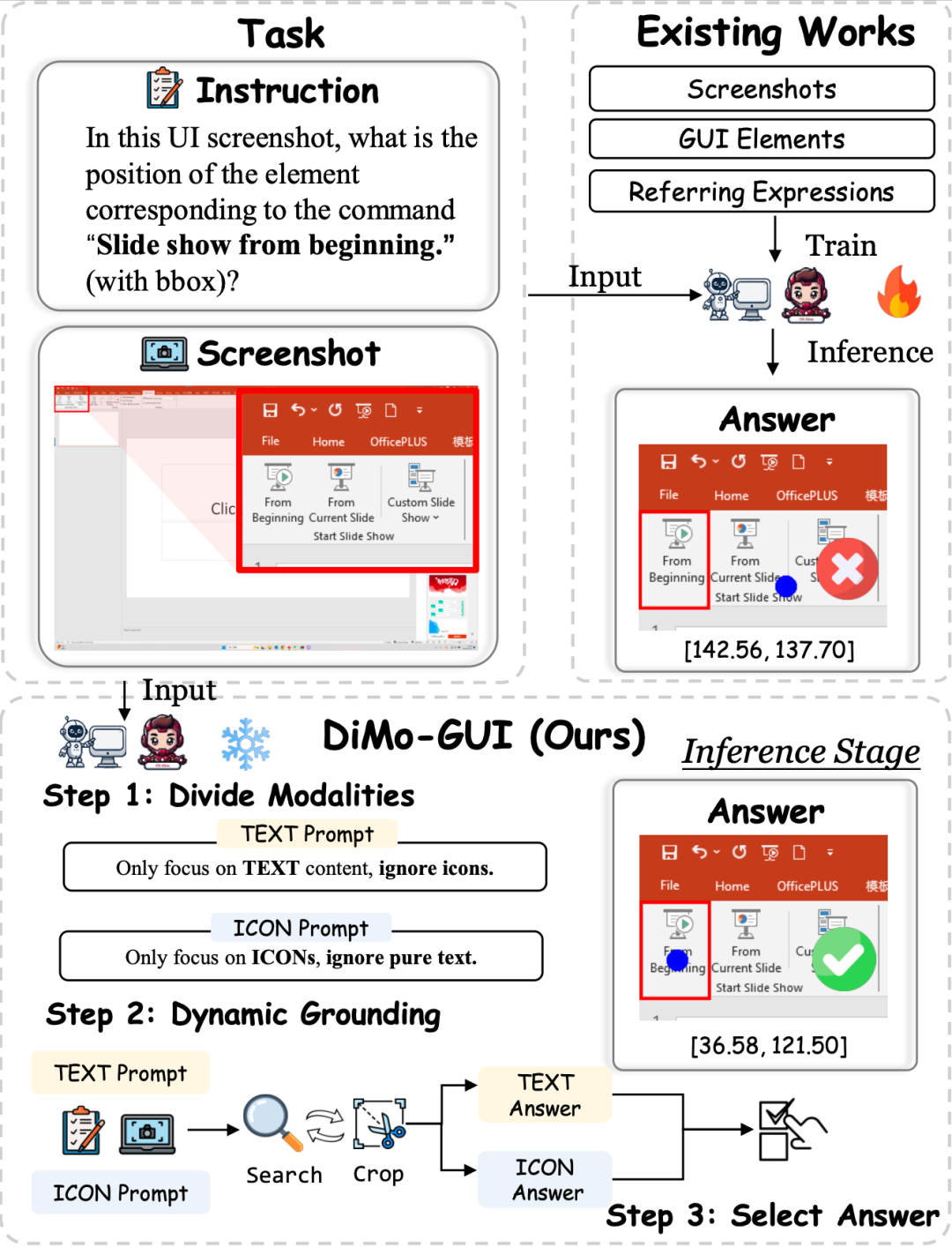
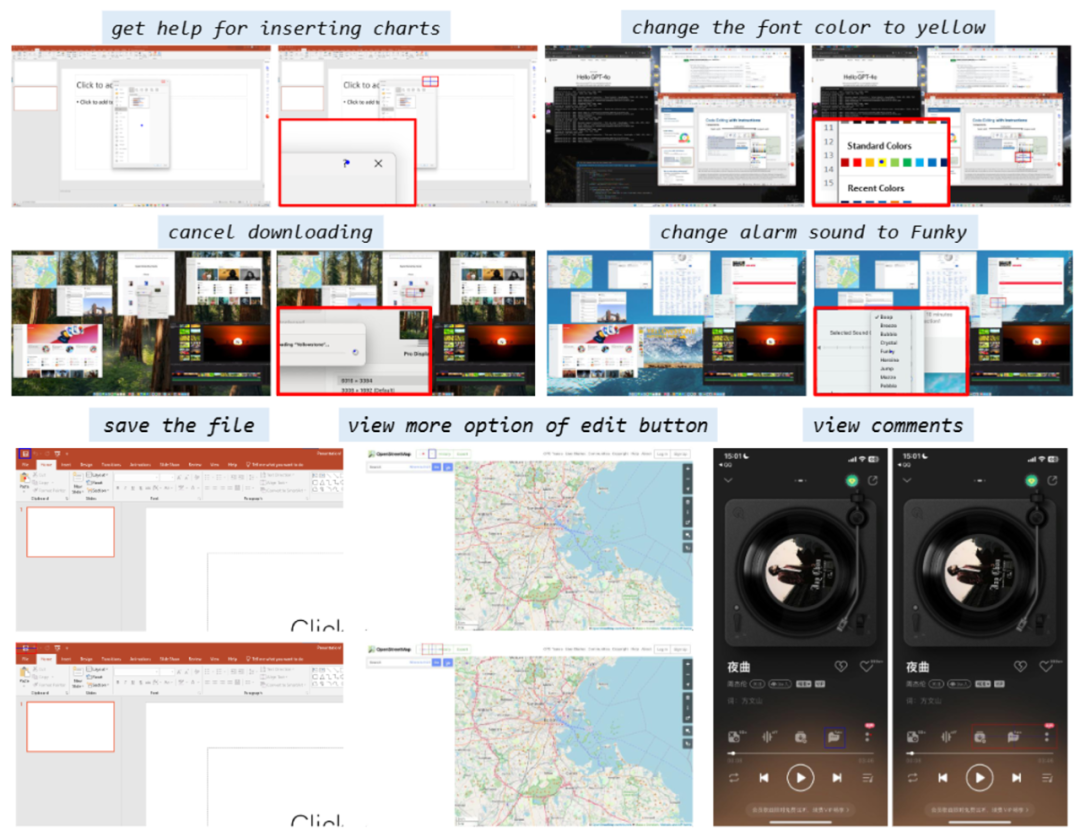
日常生活中,我們與電腦、手機的交互離不開圖形用戶界面。小到點贊、大到數據分析,我們都希望AI能像人一樣,理解屏幕上的每一個按鈕、每一段文字,并準確執行指令。然而,對于飛速發展中的多模態大模型來說,這卻是前所未有的艱巨挑戰。在一個復雜的App、網頁或桌面軟件中,用戶可能隨手一句“點擊開始播放”,但對于AI來說,準確找到這個指令對應的圖標/按鈕并不簡單:
模態混雜:用戶界面同時包含文本、圖標、背景、裝飾性元素等,干擾多;并且大多數VLM對文字理解更強,圖標處理卻弱,造成嚴重偏差;
冗余信息:高分辨率UI中,重要區域可能只占整體的幾十分之一,模型容易定位錯誤區域。
研究發現,傳統方法如基于文本推理或單次視覺定位的管道在高分辨率、視覺擁擠的 GUI 中表現不佳。例如在最新的 ScreenSpot-Pro 數據集上,大多數通用模型如GPT-4o, Qwen2-VL等只有1%左右的正確率, 即使是針對于GUI定位任務的ShowUI, Aria-UI等智能體也只有10%左右的正確率。
二、關鍵改進:模態分離 + 動態定位
從上述問題出發,該研究推出零訓練成本的DiMo-GUI,通過模態感知的視覺推理推進訓練時擴展,顯著提升多模態大模型的圖形界面(GUI)理解能力。主要的改進方式包括以下兩點:
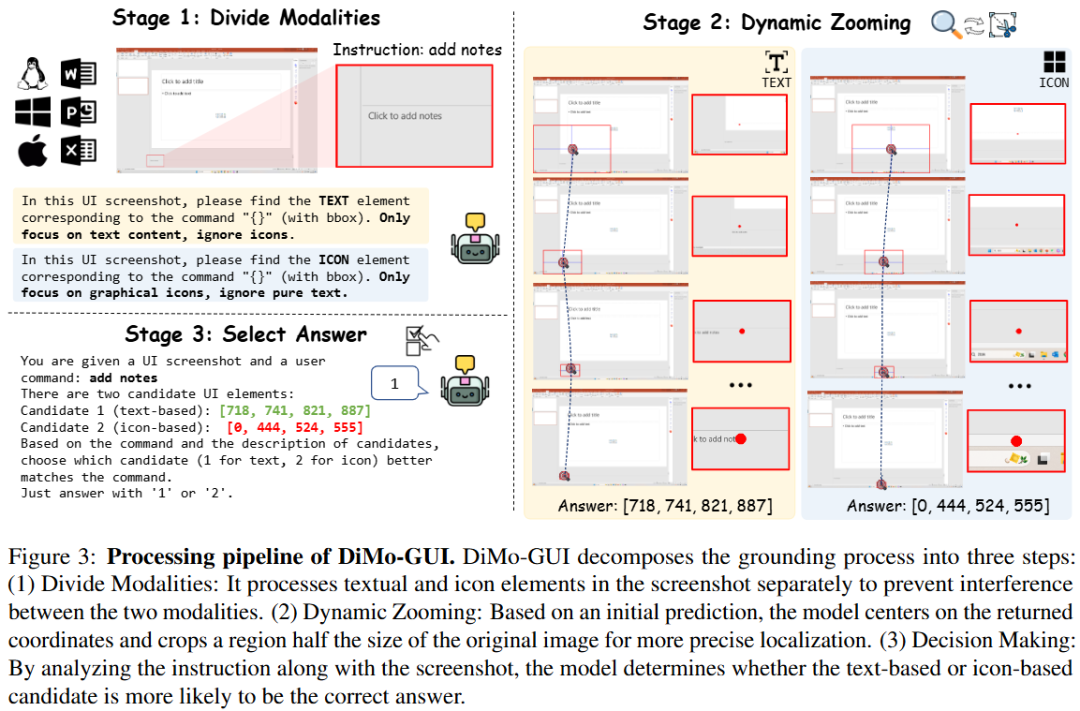
動態視覺定位:DiMo-GUI 采用逐級縮放機制,從粗略預測開始,基于初始坐標生成候選焦點區域,并通過迭代裁剪逐步聚焦目標。例如,首次推理后,模型以預測坐標為中心裁剪半個圖像大小的區域作為下一輪輸入,顯著減少視覺冗余。動態迭代機制根據前后預測的坐標距離(小于圖像對角線六分之一時停止)實現自適應停止,避免“過度思考”。
模態感知優化:DiMo-GUI 將 GUI 元素分為文本和圖標兩類,分別進行獨立的定位推理,生成文本坐標(C_text)和圖標坐標(C_icon)。隨后,模型結合原始指令和全分辨率圖像評估兩個候選坐標,確定最終目標 (C*),有效平衡文本和圖標的處理能力。
這樣的方式推動了推理時拓展(Test-time Scaling)在GUI定位這一領域的發展,提供了新的思路和方式。
三、實驗結果:無需訓練和任何額外數據,只在推理階段就可以大幅提升性能
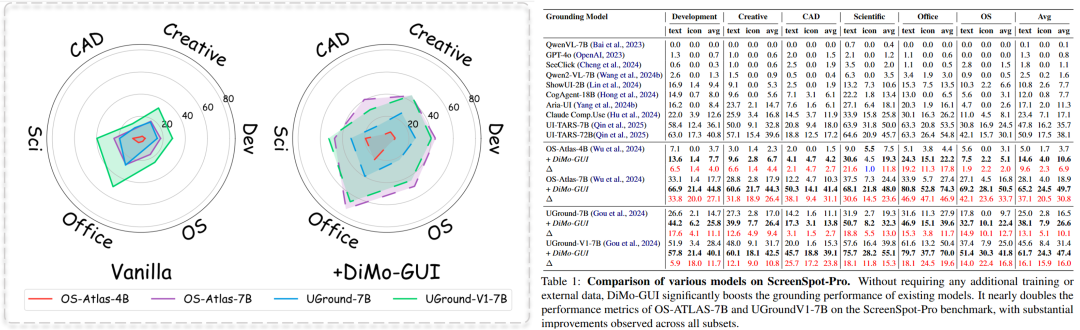
團隊在最新的高分辨率GUI數據集 ScreenSpot-Pro 上驗證發現:
DiMo-GUI可以作為即插即用的框架大幅提升多個GUI模型的性能。
其中OS-Atlas-7B在引入DiMo-GUI之后獲得了超過兩倍的指標提升(18.9% -- 49.7%), UGround-7B和UGround-V1-7B也均獲得了超過10%的指標提升。
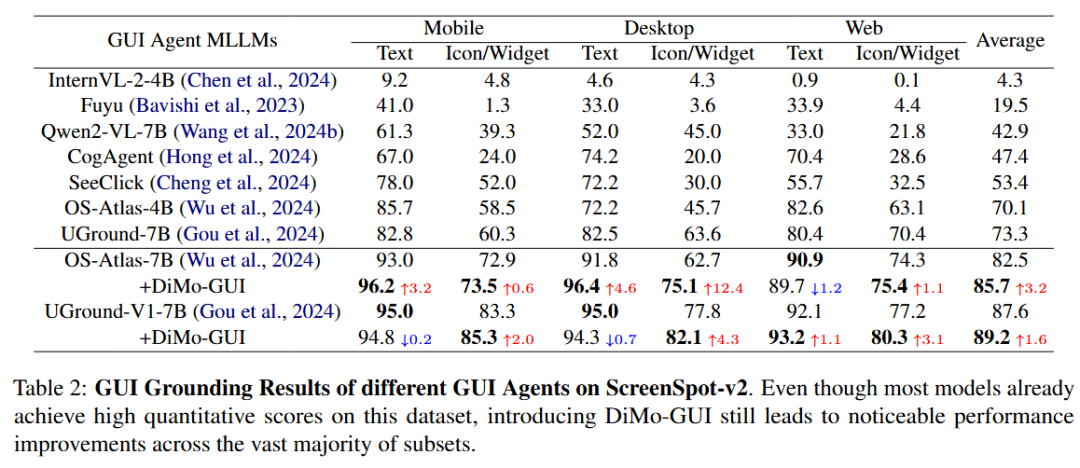
在相對簡單的ScreenSpot數據集上,DiMo-GUI同樣可以提升多個模型的性能。
定性結果表示,模型加入DiMo-GUI之后可以通過動態定位逐步逼近正確結果。
四、總結
DiMo-GUI 提供了一種高效、通用且無需訓練的GUI定位框架,通過動態視覺推理和模態感知優化顯著提升了多模態大語言模型在復雜 GUI 環境中的表現。其“即插即用”特性使其可無縫集成到現有GUI Agent中,適用于網頁導航、移動應用自動化等場景。未來研究可探索引入回溯機制以糾正早期錯誤,進一步提升定位魯棒性。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號