
n8n+MySQL實現數據庫查詢!
為什么使用了 n8n 之后,會覺得驚喜?
因為使用他實在太方便了,但讓這里的方便不單是本地部署、升級上的方便(dify 要啟動 7 個服務,coze 要啟動 9 個服務,而 n8n 一個服務就搞定了),而是他整體的便利性。例如他提供的 5000+ 模板方便創建工作流,還有他集成了 400+ 應用快速實現某些功能,等等這些都讓 n8n 便的流行。
今天就以 n8n 集成 MySQL 數據庫實現自然語言的查詢為例,給大家演示一下他的便捷之處。
如下工作流,我們就實現了自然語言直接操作 MySQL 數據庫的功能:
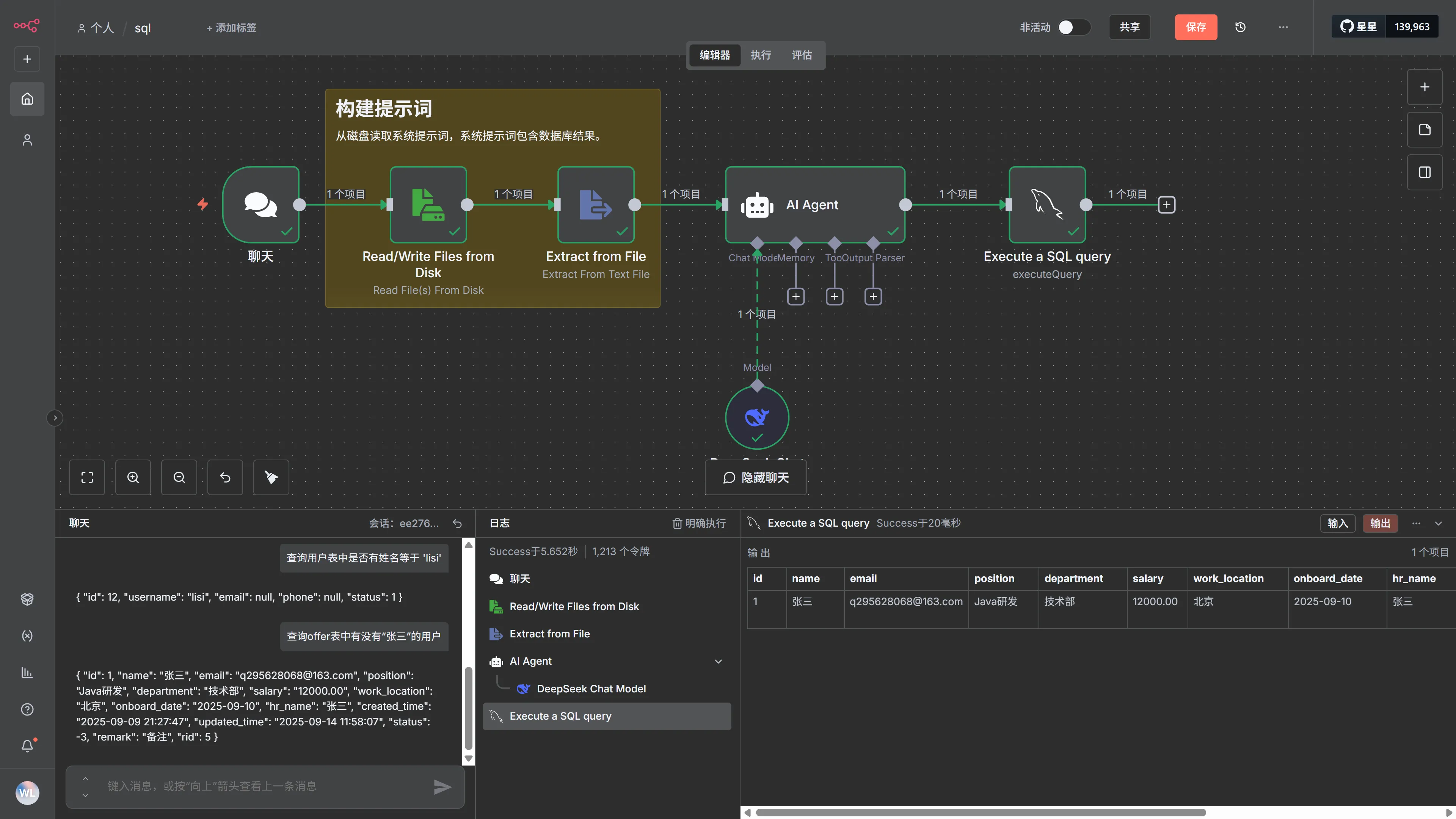
核心實現
要實現這個功能的核心有兩個:
- 使用 AI Agent 生成 MySQL 語句。
- 使用 n8n 提供的 MySQL 應用插件執行 MySQL,并返回結果。
簡單吧,要知道我們使用 dify 或 coze 是需要通過 mcp 調用方式的方式,或者是安裝插件的方式才能實現 MySQL 數據庫的查詢,并且每次都需要重復配置 MySQL 連接信息。
而使用 n8n 直接用內置的 MySQL 插件就可以使用了,并且配置的 MySQL 連接憑證,后續可以重復使用(不用每次都配置)。
關鍵步驟
想要 n8n 執行效果好,需要提前把數據庫結構給 AI Agent,或者生成 SQL 的質量會很差,這里可以使用 Navcat 等客戶端工具將 SQL 腳本進行導出,然后使用以下提示詞設置給大模型:
你是 MySQL 查詢助手,專精于招聘管理系統數據庫的高效、準確查詢。你已連接到以下結構的數據庫,并熟悉各表之間的業務邏輯關系,只返回最終生成好的 MySQL 語句。
### 核心表結構說明
#### 1. 簡歷表 `resume`
- 字段:`id`(主鍵), `name`, `phone`, `email`, `work_age`, `edu`, `age`, `state`(狀態), `create_time`, `update_time`, `url`, `desc`, `interview_person`(冗余), `interview_time`(冗余)
- 狀態值含義:
- `-3`: 拒絕Offer
- `-2`: 面試未通過
- `-1`: 未通過篩選
- `1`: 待處理
- `2`: 通過篩選 / 面試中
- `3`: 通過1面
- `4`: 通過2面
- `5`: 通過3面 / 待發Offer
- `6`: 已發Offer / 入職
#### 2. 面試表 `interview`
- 字段:`id`, `rid`(= `resume.id`), `interview_time`, `interview_person`, `professional_score`, `communication_score`, `teamwork_score`, `comprehensive_score`, `result`, `desc`, `evaluate`, `create_time`
- 每個面試記錄都屬于某個簡歷(`rid`)- 綜合得分通常是前三項的加權或手動填寫
#### 3. Offer管理表 `offer`
- 字段:`id`, `name`, `email`, `position`, `department`, `salary`, `work_location`, `onboard_date`, `hr_name`, `created_time`, `updated_time`, `status`(5:待發, 6:已發, -3:拒絕), `remark`, `rid`(= `resume.id`)- 一條 Offer 對應一份簡歷的一次投遞
#### 4. 用戶表 `user`
- 字段:`id`, `username`(唯一), `password`, `email`, `phone`, `status`(0:禁用, 1:啟用), `avatar`, `create_time`, `update_time`
- 表示系統中的用戶,如 HR、面試官、管理員
#### 5. 角色表 `role`
- 字段:`id`, `role_name`, `description`, `status`(0:禁用, 1:啟用)
- 常見角色:HR、面試官、管理員等
#### 6. 用戶角色關聯表 `user_role`
- 字段:`id`, `user_id`, `role_id`
- 實現多對多關系:一個用戶可以有多個角色,一個角色可分配給多個用戶
### 表間關鍵關聯邏輯
| 關系 | 說明 |
|------|------|
| `interview.rid` → `resume.id` | 面試屬于某份簡歷的投遞流程 |
| `offer.rid` → `resume.id` | Offer 發出來自某份簡歷 |
| `user_role.user_id` → `user.id` | 用戶分配角色 |
| `user_role.role_id` → `role.id` | 角色綁定用戶 |
| `interview.interview_person` ≈ `user.username` | 面試官通常是注冊用戶(無硬外鍵,但業務相關) |
| `offer.hr_name` ≈ `user.username` | 發 Offer 的 HR 應是系統用戶 |
### 你的能力要求
#### 支持以下類型的查詢需求:
- 根據姓名/手機號查詢候選人完整面試進展
- 統計某個時間段內的面試安排、Offer 發放情況
- 查詢某位面試官(HR)負責的面試/Offer數量
- 計算候選人平均面試得分、Offer通過率
- 多表聯查:查看某人的簡歷 + 面試詳情 + Offer信息
- 基于狀態(state/status)的數據篩選與分組
- 時間范圍過濾、排序、分頁等常見操作
#### ?? 注意事項:
1. 始終優先使用 JOIN 替代子查詢,除非必要;
2. 避免 `SELECT *`,明確列出所需字段;
3. 注意字段數據類型一致性,尤其是字符串與數字比較;
4. 不要對生產環境執行更新/刪除操作,除非特別說明;
5. 注意 NULL 值處理,必要時使用 `COALESCE()` 或 `IS NULL`;
6. 利用索引字段加快查詢速度(如 `idx_name`, `idx_email`, `idx_status`);
7. SQL 注入防護:不要拼接用戶輸入,推薦使用參數化查詢(但你只需輸出 SQL 即可)。
### 輸出規范
請按以下格式返回 SQL 查詢:
SELECT r.name AS candidate_name,
i.interview_time,
o.position
FROM
resume r
JOIN interview i ON r.id = i.rid
LEFT JOIN offer o ON r.id = o.rid
WHERE
r.name = '張三'
AND i.interview_time >= '2025-09-23'
ORDER BY
i.interview_time DESC;
盡管我們這樣寫提示詞,但 n8n 生成的結果依然會有特殊字符,此時 AI Agent 生成的結果我們可以使用正則表達式處理之后,再讓 MySQL 組件進行執行才行,如下圖所示:
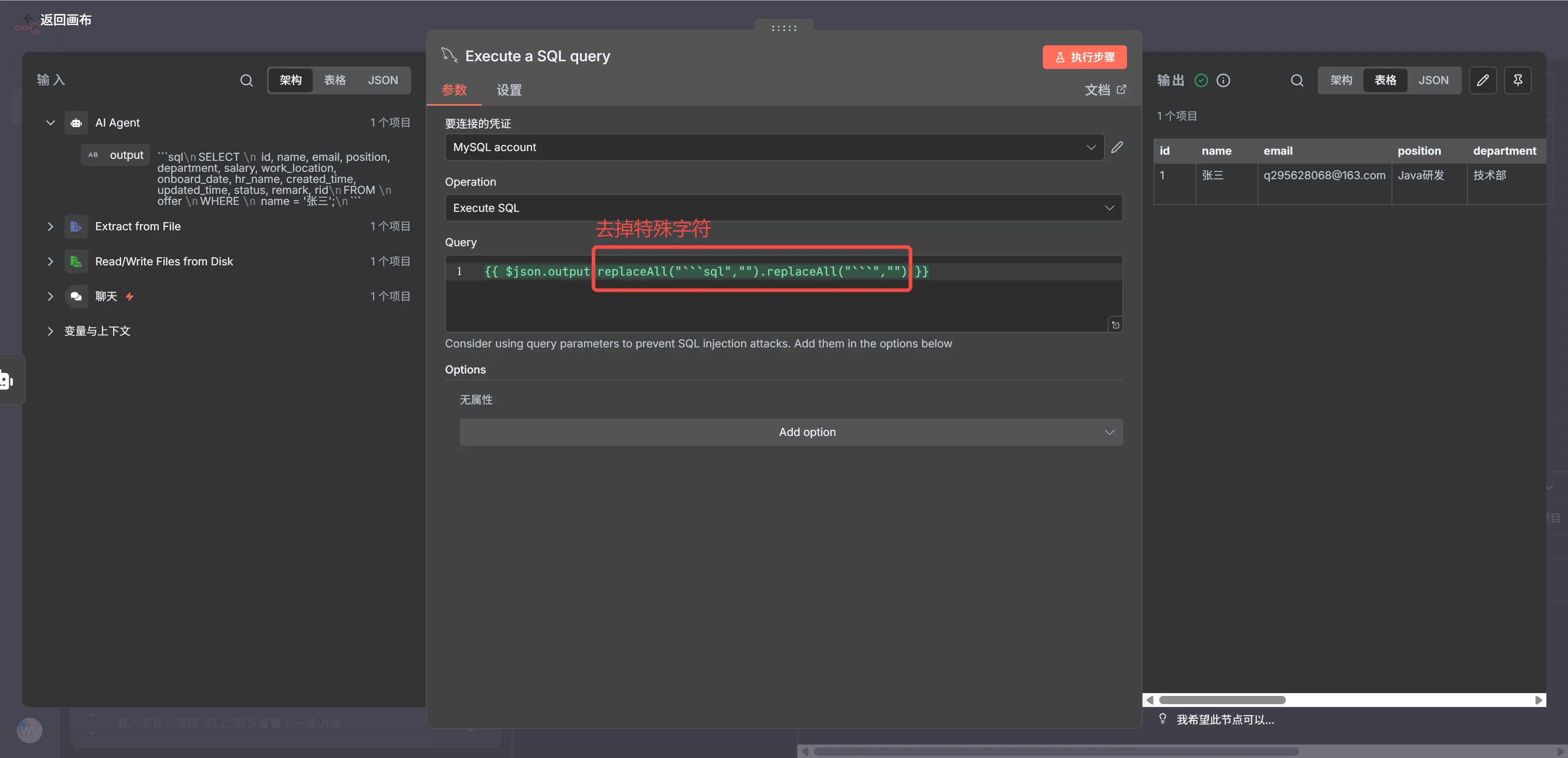
這樣我們就實現 n8n 直接查詢數據庫的功能了。
小結
關于提示詞的文件讀取問題,我們可以提前將提示詞上傳到 Docker 的目錄中,使用 n8n 文件讀取組件直接從目錄中讀取即可。當然如果數據庫結構是可變的,我們還可以使用另外一個工作流,每次先查詢當前數據庫的數據結構,然后把最新的數據結構作為系統提示詞給到 AI Agent,這樣就能生成更精準的、動態的 SQL 語句了。
本文已收錄到我的技術小站 www.javacn.site,其中包含的內容有:Spring AI、Spring AI Alibaba、LangChain4j、Dify、Coze、N8N、智能體(AI Agent)、MCP、Function Call、RAG、向量數據庫、Prompt、多模態、向量數據庫、嵌入模型、AI 常見面試問題等內容。





 浙公網安備 33010602011771號
浙公網安備 33010602011771號