
分布式文件快速搜索-設(shè)計與實現(xiàn)(開源/并行)
2010-07-20 08:50 靈感之源 閱讀(5483) 評論(16) 收藏 舉報
系列文章
2.分布式文件快速搜索的設(shè)計與實現(xiàn)(開源/分布式計算/并行)
3.分布式文件快速搜索-技術(shù)細(xì)節(jié)分析(開源/并行)
特點
1.分布式:支持通過互聯(lián)網(wǎng)查找任意多計算機,支持TCP/HTTP;
2.訪問安全:基于角色的訪問控制(RBAC),支持定義遠程訪問的賬戶、允許訪問的目錄等;
3.快速:
a).充分發(fā)揮多核CPU的性能,自動進行并行計算;
b).自動使用NTFS特性快速檢索文件,比普通檢索速度提升10倍以上;
4.智能:自動識別同一部機器上的不同物理磁盤,自動加速;
5.高效:哈希值、全文索引快速存取,網(wǎng)絡(luò)壓縮傳輸;
6.可擴展性內(nèi)容搜索:內(nèi)容匹配、全文索引,支持接口;
前世
這個程序的靈感,可以參考這里詳細(xì)的說明:分布式文件快速搜索(多計算機并行/多種算法)
原來的目的只是查找本計算機的重復(fù)文件,因為3TB的磁盤空間,放了太多電影、圖片、音樂,有不少是重復(fù)。剛開始,對每個文件內(nèi)容都進行哈希值計算,速度非常慢。后來改成先用文件大小碰撞,碰撞后重復(fù)的幾率就極大地減少了,然后再進行文件內(nèi)容哈希,速度就有了巨大的提升。再后來,支持了文件名、文件時間和屬性等過濾條件,可用性也增大了。
但是我不滿足現(xiàn)有的速度,覺得現(xiàn)在的CPU都是多核的,我們可以使用多線程來充分利用多核的威力。單純的多線程處理容易,new Thread就能跑了,但我們的目的是把大量的查找任務(wù)切割,分而治之,然后同時執(zhí)行,并等待所有任務(wù)都完成再繼續(xù)下一步工作,這就是并行計算的目的。
.NET 3.5 SP1開始有了Parallel Extensions,4.0內(nèi)置了Parallel Processing Library(PPL),當(dāng)然還有一系列的相關(guān)類,如ConcurrentDictionary等(終于解決了2.0引入的Dictionary不是線程安全需要自己手工封裝的問題了)。有了這些,我們就可以進行并行計算了。
在引入了多線程檢索文件之后,我還不滿足現(xiàn)有的速度。經(jīng)過分析,可以判斷檢索的文件是否在不同的物理磁盤(不是一個磁盤的不同分區(qū)),則可以在本機動態(tài)使用并行計算。
我還不滿足目前的功能:局限于現(xiàn)有計算機,作為不大。日常工作,我們需要對不同的計算機進行搜索,當(dāng)然,都是局域網(wǎng)內(nèi),我們可以映射網(wǎng)絡(luò)磁盤。但如果是互聯(lián)網(wǎng)上的計算機,你就無能為力了。所以就有了現(xiàn)在的網(wǎng)格文件快速搜索。
必須說明的是,網(wǎng)格文件快速搜索不是一個完整的軟件,只是閑得頭痛而拿來練手的實驗性程序,目前能做的只是檢索、刪除相同/不同計算機上的文件。
今生
所謂網(wǎng)格,就是分布式,跟Web2.0所謂Tag就是分類一樣,互聯(lián)網(wǎng)包裝的概念層出不窮。
要實現(xiàn)在不同的計算機之間檢索文件,并聚合結(jié)果,我們需要做的工作頗多。首先,我參考了google的MapReduce。MapReduce,實際就是2個步驟,分配工作,然后聚合結(jié)果。在對多個計算機進行檢索,就是分配多個任務(wù),每個任務(wù)檢索指定的計算機,等待所有檢索任務(wù)完成,再聚合結(jié)果。
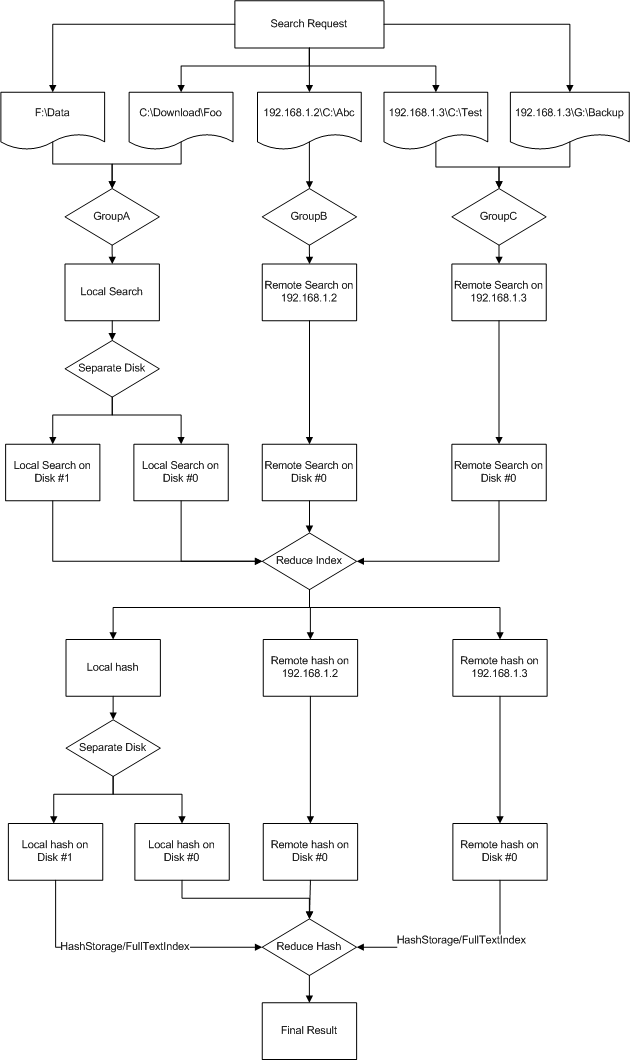
接著,我們需要對任務(wù)進行分配。分配的原則是遠程按機器分組,本地按磁盤分組。在分配好任務(wù)之后,我們需要在每個計算機運行一個監(jiān)聽程序接受其它機器的請求。監(jiān)聽使用的是異步TCP,使用事件來通知程序進行業(yè)務(wù)處理。在監(jiān)聽程序運行后,客戶端判斷要檢索的文件夾位于遠程計算機,使用異步TCP連接,連接成功后,發(fā)送要檢索的文件夾以及身份信息,在通過身份認(rèn)證之后,便可以進行文件檢索。當(dāng)檢索完成后,返回結(jié)果給請求端,請求端在所有計算機的檢索都完成后,對結(jié)果進行組合。
如果遠程計算機HTTP無法連接(如監(jiān)聽程序沒有啟動),會自動嘗試TCP鏈接,如果仍然失敗會自動容錯并忽略。
現(xiàn)在,網(wǎng)格文件快速搜索正式成為了文件搜索,而不是以前的重復(fù)文件查找了。
搜索流程
上述的步驟只是大概的過程,實際搜索流程要更復(fù)雜。整個搜索過程分2大步:第一步是根據(jù)文件的大小/名稱/時間/屬性等進行過濾,然后對存在相同的文件再進行文件內(nèi)容哈希值判斷。
對于互聯(lián)網(wǎng)上的機器搜索,第一步必須返回所有搜索內(nèi)容,而不是僅僅返回重復(fù)的內(nèi)容,因為我們現(xiàn)在檢索不是本地計算機,是多個互聯(lián)網(wǎng)計算機,譬如計算機A存在文件1.jpg,計算機B也存在同樣的1.jpg,但你必須把計算機A和B的結(jié)果聚合了才知道2個jpg文件相同,所以檢索各個計算機的文件,第一次回返回所有文件信息,在結(jié)果返回聚合后,得出大小/名稱/時間/屬性相同的結(jié)果,再對這些文件進行文件內(nèi)容哈希值處理。文件內(nèi)容哈希值的處理過程跟文件屬性檢索類似,但是哈希值是以磁盤文件形式緩存了,每次獲取文件內(nèi)容哈希值之前,先判斷文件的基本屬性(文件名、大小、修改時間)是否與哈希數(shù)據(jù)庫一致,如果匹配,使用數(shù)據(jù)庫中的值,否則計算新的哈希值。
對于文件內(nèi)容匹配,分3種情況:
1.完全匹配:使用哈希值判斷,哈希值會在本地緩存;
2.內(nèi)容包含:運行時判斷;
3.全文索引:對可以抽取內(nèi)容的文件進行動態(tài)索引,本地緩存;
全文索引支持接口擴展,目前內(nèi)置了對微軟的IFilter接口的實現(xiàn),即將添加對lucene.net和hubbledotnet的支持。
具體流程看下圖:
將來
你可以充分發(fā)揮想象力,把它應(yīng)用到不同的領(lǐng)域。如果你應(yīng)用了,記得告訴我,我會很高興它能被別人使用。
TODO
使用
參看分布式文件快速搜索(多計算機并行/多種算法) 和下面的代碼。
代碼下載
點擊這里下載:Filio.zip
實際使用,不需要V1*-V5*這些類,現(xiàn)在只是用來對比測試速度的,如果不測試,可以刪除這些類。
項目地址
本項目已經(jīng)在http://filio.codeplex.com/ 開源

 浙公網(wǎng)安備 33010602011771號
浙公網(wǎng)安備 33010602011771號