
夜鶯監控設計思考(五)告警原理和處理流程深度剖析
這將是一個系列,講解 夜鶯監控 的設計思考,可以理解為原理+最佳實踐+產品設計時的折中取舍。
本系列其他文章:
- 夜鶯監控設計思考(一)項目定位、組件思考、單進程多進程選擇、高可用設計
- 夜鶯監控設計思考(二)邊緣架構的緣起和設計
- 夜鶯監控設計思考(三)時序庫、agent 的一些設計考量
- 夜鶯監控設計思考(四)關于機器那些事兒
本篇聊聊夜鶯最核心的邏輯:告警。涉及告警事件的產生、告警事件的后續處理、告警事件的通知。
夜鶯的告警邏輯整體是追隨 Prometheus 的邏輯,本文默認你已經對 Prometheus 的告警邏輯比較清楚。
前置知識
夜鶯有兩個進程:
n9e部署在中心,既是告警引擎,又是 webapin9e-edge部署在邊緣機房,作為告警引擎
夜鶯作為告警引擎,可以對接多種數據源,哪些告警引擎負責哪些數據源的告警判定,是需要用戶告知夜鶯的。
所以,
- 啟動夜鶯的進程的時候,要做好規則,在 config.toml 配置文件里指定 EngineName,即引擎的名字,相同名字的引擎會當做一個引擎集群
- 要在夜鶯里配置數據源的信息,包括連接地址,以及和告警引擎集群的關聯關系
然后,告警引擎就開始干活了,對自己負責的那些數據源,做告警判定。
告警判定是需要有告警規則的,即:哪些監控指標閾值是多少,需要用戶給出。所以,需要用戶在夜鶯頁面上配置告警規則(可以導入內置的現成的一些告警規則,然后二次修改)。
OK,進入正題。
告警處理流程概述
我們來看整個告警流程示意圖:
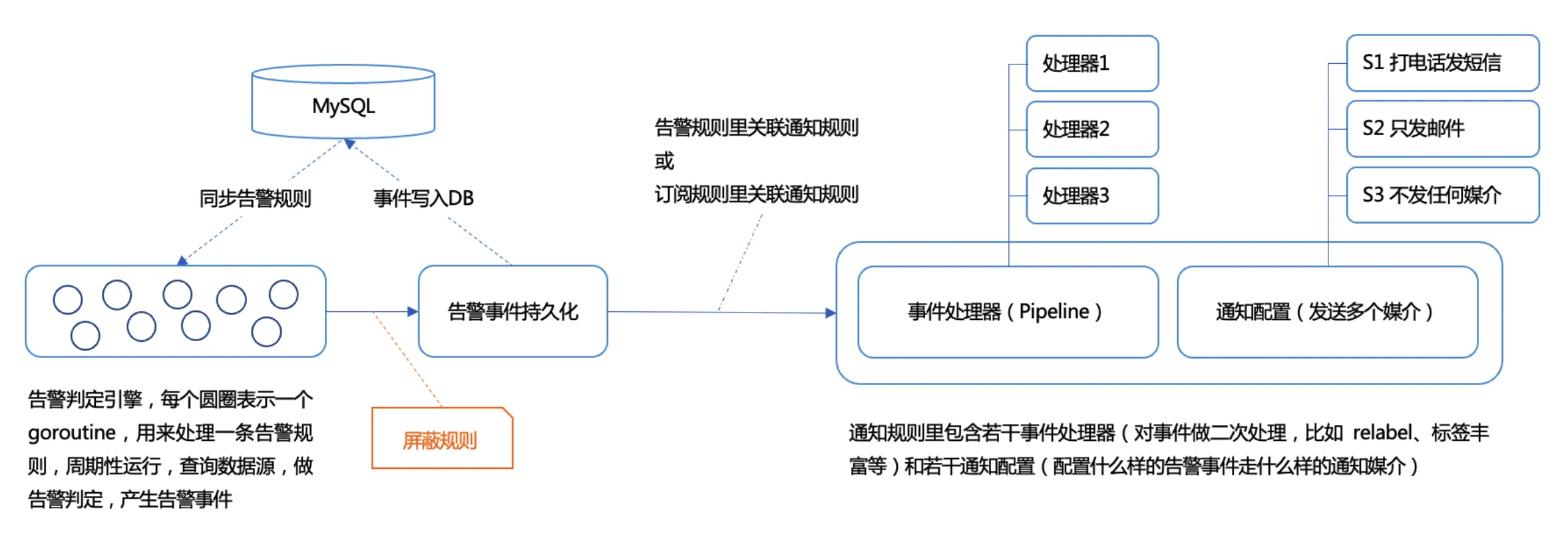
- 用戶在 Web UI 配置告警規則,規則保存在 DB 中(通常是 MySQL)。
- 告警引擎(n9e 進程內置一個告警引擎,邊緣模式下 n9e-edge 進程里也內置告警引擎)從 DB 同步告警規則到內存中(通常 n9e-edge 無法直接讀 DB,是調用的中心端 n9e 的接口獲取的告警規則)。
- 告警引擎會為每條告警規則創建一個 goroutine(協程,姑且可以理解為輕量級線程),按照用戶在告警規則里配置的頻率,周期性查詢存儲,對數據做異常判定,最終生成告警事件。
- 產生告警事件后,判定是否被屏蔽了,如果被屏蔽了直接丟棄事件,否則,要把事件持久化到 DB 中(通常是 MySQL),然后再走后面的通知規則。
- 通知規則包含兩部分,一個是若干事件處理器(比如 relabel、event update、event drop、ai summary 等),另一個是若干告警通知配置(比如 Critical 的告警事件打電話、發短信,Warning 的告警事件只發郵件)。
1. 生成告警事件
這塊邏輯和 Prometheus 很像,只不過 Prometheus 只支持對自身 TSDB 的數據做告警判定,夜鶯支持其他更多類型的數據源。
以 Prometheus、VictoriaMetrics 等時序數據源為例,夜鶯會根據告警規則里的 promql 查詢數據(按照執行頻率周期性查詢),查到了就認為有異常數據,就要產生告警事件,如果配置了持續時長,則要連續等待更長時間,每次都查到異常數據才產生告警事件。
產生告警之后,如果后面某次查詢查不到對應的異常數據了,就認為告警恢復。如果配置了留觀時長,則要多等待留觀時長對應的時間,這個時間內沒有再查到異常數據才算恢復。
注意:告警之后,如果新的監控數據寫入時序庫有延遲,比如數據采集鏈路出了問題或者變慢了,告警引擎查詢的時候查不到數據,也會報恢復。因為引擎分辨不出是數據不符合閾值了所以沒有返回還是數據延遲了所以沒有返回。
2. 告警事件的數據結構
告警事件是根據告警規則查詢數據源產生的。告警事件有很多屬性,以及標簽。
- 屬性:比如告警級別、規則標題、事件狀態、觸發時間、觸發時的值等,里邊很多屬性是來自事件對應的告警規則
- 標簽:事件的標簽有兩個來源,一個是查詢數據源返回的數據里的標簽,一個是告警規則的附加標簽
比如某個告警規則,其 promql 為 disk_used_percent>0,根據這個 promql 查到的數據為:
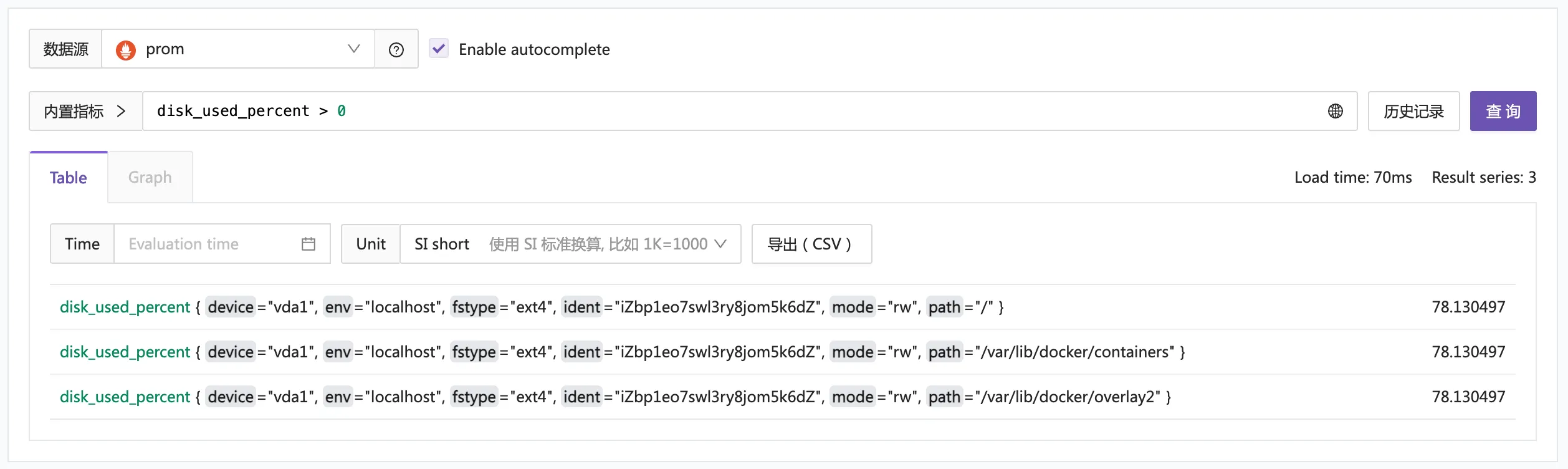
那就會產生 3 條告警事件,因為 promql 返回了 3 條數據,3 條數據的標簽不同,用于區分三個事件。
后續的各類規則,比如屏蔽規則、訂閱規則、通知配置,都要對告警事件做篩選,核心就是按照告警事件的屬性、標簽進行篩選。
3. 告警屏蔽
告警事件產生之后,會去找告警規則所屬的業務組下面是否有屏蔽規則,如果有,就拿著這個告警事件挨個去匹配屏蔽規則,如果匹配了某個屏蔽規則,則告警被屏蔽,直接丟棄告警事件,不會寫入 DB。
后面可能會修改這塊的邏輯,屏蔽的告警事件也存 DB,只是打個“已屏蔽”的標記。
注意,屏蔽規則只生效在同業務組下的告警規則產生的事件。防止某個新兵配置了一個全局屏蔽規則,把公司所有告警都屏蔽了。
屏蔽規則的多個條件之間是 AND 的關系,即 與 的關系,這點請注意。官網文檔里也有相關說明,這里不再贅述。
4. 告警事件持久化
告警事件如果沒有被屏蔽,就要入庫持久化,寫入 alert_his_event 表,這是所有歷史事件的全量存檔表,同時,也會修改 alert_cur_event 表,這是活躍告警表,即當前尚未恢復的告警事件的一個表。
如果從細節來講,其實可以把告警和事件區分開(后面版本的夜鶯可能會做這個改進)。
比如 a 機器 mem_free 指標在 10:00:00 告警了,產生了一條告警事件,其 id 是 1,hash 是 xx,告警規則里通常會配置重復通知,每隔 1h 重復產生一條新的事件。即 a 機器 mem_free 指標在 11:00:00 會再次產生一條告警事件,其 id 可能為 2,hash 仍然是 xx。
這兩條事件是在兩個時刻產生的,是兩個對象,所以 id 不同,但是確實都是說的一個事,都是 a 機器的 mem_free 告警,所以 hash 值相同,后面告警恢復的時候,會產生一個新的事件,其 id 可能為 3,hash 值仍然是 xx,這樣才能關聯起來。
有了上面的講解,alert_cur_event 表的更新邏輯就成了:
- 來了一個新的事件,根據這個事件的 hash,刪除 alert_cur_event 的記錄
- 如果這個新事件是恢復事件,就啥都不用干了,相當于:恢復告警就要從活躍告警里清理掉;如果新事件是告警事件,就把最新的事件寫入 alert_cur_event
這個設計其實不太好,在整個體系里只有 event 的概念,沒有 alert 的概念,少抽象了一個領域對象。后面的版本可能會改進。
5. 事件關聯通知規則
告警事件產生了,后面可能涉及對告警事件的二次處理,比如做 relabel、做過濾等,以及把告警事件投遞發送出去。這就涉及到“通知規則”了。
那告警事件具體和哪個通知規則關聯呢?在夜鶯里有兩種方式:
- 告警規則里直接配置通知規則:這個告警規則產生的所有告警事件,都直接走這個通知規則
- 使用訂閱規則:訂閱規則相當于是寫了一個告警事件的篩選條件,會篩選到一堆告警事件,篩到的這些事件交予訂閱規則里配置的通知規則去處理
通常走第 1 種方案就可以了,對于某些全局級別的通知規則,可以走方案 2。
6. 通知規則
通知規則最核心的是配置通知媒介和告警接收人。之前這些信息是在告警規則里直接配置的,感覺不靈活,從 V8 開始單獨提取出來了。
如果各個團隊分別收告警,通常,每個團隊要對應一個通知規則,在這個通知規則里,一次性配置好什么樣的告警發什么通知媒介,然后這個團隊的所有告警規則都綁定這個通知規則即可。
通常,根據告警級別定義不同的通知媒介,比如:
- Critical 的告警,打電話、發短信、發郵件、釘釘
- Warning 的告警,只發短信、發郵件、釘釘
- Info 的告警,只發郵件、釘釘
通知這里,還要對兩個東西做實體建模抽象,一個是通知媒介,一個是消息模板。V8 版本可以很方便對接一個企業內部的通知媒介。具體可以參考相關文檔,這里不再贅述。
7. 事件處理器
V8 還引入了一個事件處理器的概念,可以把多個處理器組成一個 Pipeline,通知規則里可以引用多個 Pipeline。
這里的思考是:告警事件產生之后,可能有各種不同的處理,比如做 relabel、filter、enrichment 等,Pipeline 相當于抽象了一個 workflow,讓用戶在事件處理的鏈路上插入一些自定義的邏輯,給用戶極大的靈活性。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號